本文将讨论俄语文本消息的音调分类(以及使用相同技术的文本分类)。 我们将以本文为基础,其中考虑了使用Word2vec模型对CNN架构进行音调分类。 在我们的示例中,我们将解决使用
ULMFit模型在同一数据集上
将推文分为正面和负面的相同问题。 文章的结果(平均F1-分数= 0.78142)将被接受为基线。
引言
ULMFIT模型由fast.ai开发人员(Jeremy Howard,Sebastian Ruder)于2018年推出。 该方法的本质是在使用预训练的模型时在NLP任务中使用转移学习,从而减少了训练模型的时间,并减少了对标记的测试样品的大小的要求。
在我们的案例中,培训方案如下所示:

语言模型的含义是能够顺序预测下一个单词。 以这种方式获取长时间连接的文本是有问题的,但是尽管如此,语言模型仍能够捕获语言的属性,了解单词使用的上下文,因此,语言模型(而非单词的矢量显示)才是该技术的基础。 对于语言的建模任务,ULMFit使用
AWD-LSTM体系结构,该体系结构在可能且有意义的情况下积极使用dropout。 语言模型训练的类型有时称为半监督学习,因为这里的标签是下一个单词,您无需用手做任何标记。
作为一种预先训练的语言模型,我们将使用几乎所有公开
可用的语言模型。
让我们从头开始研究学习算法。
我们加载库(如果有任何不兼容,我们将检查Fast.ai的版本):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
我们准备数据进行培训
以此类推,我们将对
Yulia Rubtsova的短文本RuTweetCorp正文进行培训,该
短文本是基于Twitter的俄语消息而形成的。 正文包含CSV格式的114,991条正向推文和111,923条负向推文。 此外,还有一个未分配的推文数据库,其中有17 639 674条SQL格式的记录。 分类器的任务是确定该推文是肯定的还是负面的。
由于
在1700万条推文上重新训练语言模型已经很长时间了,并且显示迁移学习
的任务很
懒惰 ,我们将在训练数据集中的一段文本上重新训练语言模型,完全忽略未分配推文的基础。 也许,使用此基础“增强”语言模型,可以改善总体效果。
我们通过初步的文字处理形成用于训练和测试的数据集。 我们从
原始文章中获取代码:
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
我们看看发生了什么:
df_train.groupby('Label').count()
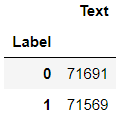
df_val.groupby('Label').count()
df_test.groupby('Label').count()

学习语言模型
加载数据:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
我们看一下内容:
data_lm.show_batch()

我们提供了链接到
预先训练的模型和字典的存储权重:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
我们创建学习者,但是在此之前-fast.ai需要一根拐杖。 预先训练的模型是在库的较旧版本上训练的,因此您需要调整神经网络隐藏层中的节点数。
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
我们正在寻找最佳的学习速度:
learn_lm.lr_find() learn_lm.recorder.plot()

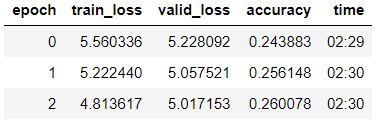
我们训练了第三个时代的模型(在模型中,只有最后一组图层是未冻结的)。
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
解冻模型,以较低的学习率教授另外5个时代:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
我们尝试在经过训练的模型上生成文本。
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
我们看到-模型所做的事情。 但是我们的主要任务是分类,对于其解决方案,我们将从模型中选取一个编码器。
learn_lm.save_encoder('ft_enc')
我们训练分类器
下载数据进行培训
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
让我们看一下数据,我们看到标签已成功计数(0表示否定,而1表示肯定注释):
data_clas.show_batch()

使用类似的拐杖创建一个学习器:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
我们加载上一阶段训练的编码器并冻结模型,最后一组权重除外:
learn.load_encoder('ft_enc') learn.freeze()
我们正在寻找最佳的学习速度:
learn.lr_find() learn.recorder.plot(skip_start=0)

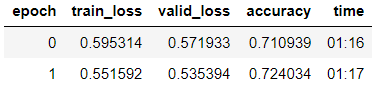
我们通过逐步解冻来训练模型。
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
我们看到,在验证样本上,它们达到了80.1%的准确度。
我们将在上一篇文章的
ZlodeiBaal评论中
测试该模型:
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
我们看到该模型将此评论归为否定:-)
在测试样本上检查模型
此阶段的主要任务是测试模型的泛化能力。 为此,我们对存储在DataFrame df_test中的数据集上的模型进行验证,直到那时该模型对于语言模型或分类器都不可用。
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
我们发现测试样品的准确性为79.7%。
看看混淆矩阵:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
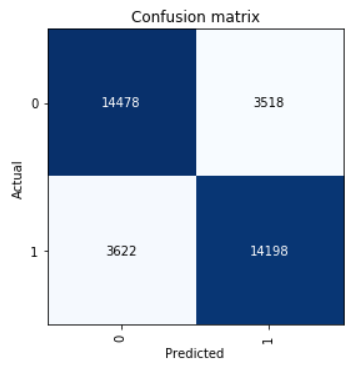
我们计算精度,召回率和f1得分参数。
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
测试样品平均F1-分数= 0.80064中显示的结果。
保存的模型权重可在
此处获取 。