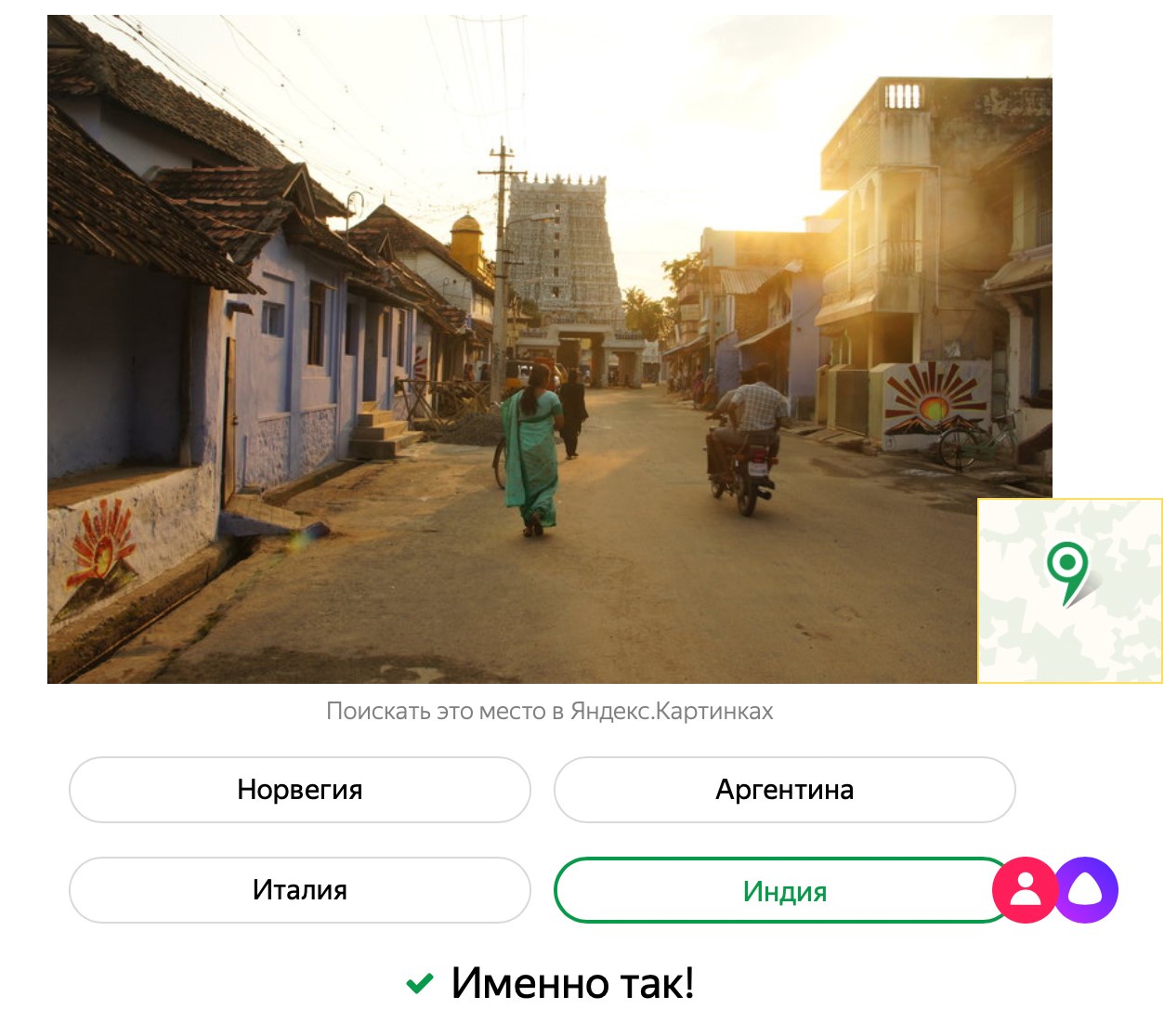
你好 我叫Evgeny Kashin,我在Yandex机器智能实验室工作。 我们最近推出了一款游戏,用户可以与爱丽丝竞争,从照片中推测出国家。
人们的行为举止是可以理解的:他们认识到自己在旅行或电影中看到的地方,依靠博学和常识。 神经网络没有这些。 我们想知道图片中的哪些细节提示她答案。 我们进行了一项研究,今天将与哈勃分享研究的结果。
对于计算机视觉领域的专家以及希望深入研究“人工智能”并了解其工作逻辑的每个人来说,这篇文章都将很有趣。

关于游戏“
用照片猜国家 ”的几句话。 简而言之,我们从Yandex.Maps拍摄了照片并将其分为两组。 第一组由神经网络显示,说明每次拍摄的地点。 在审阅了数千张照片之后,神经网络对每个国家都有一个想法-也就是说,它独立识别出可以识别的标志组合。 我们使用游戏中的第二组图片,爱丽丝在游戏过程中没有看到它们,也没有记住它们。 爱丽丝打得很好,但是人有一个优势:我们没有训练神经网络来识别机器编号,符号和符号的文本,状态标记。
在游戏中,我们训练了模型以一张照片来预测国家。 我们采用了
经过预
培训的计算机视觉
SE-ResNeXt-101模型。 使用该卷积神经网络从图像中获得的符号非常普遍,因此对于国家分类器,仅需要添加一些附加层(所谓的头部)即可。 Yandex.Mart数据用于训练:大约250万张照片。 根据美感的标准,许多图片不适合游戏,因此被过滤。 美丽被理解为多种因素的组合:照片的质量,人物,文字,森林,海洋的存在。 删除了相同位置的相似图片,因此模型不记得特定的景点。 经过所有筛选,剩余约100万张照片。 对这些数据进行模型训练后,我们得到了一个相当准确的分类器,该分类器仅通过照片即可确定国家,而无需使用其他信息。
由于分类是使用神经网络进行的,因此与简单的线性模型或决策树相比,我们无法轻松获得预测的解释。 但是我们想找出神经网络如何根据街道或房屋的常规照片确定其所在的国家。 最有趣的情况是框架中没有吸引力。
为此,我们从头开始训练神经网络,而不是提供整个图像,而只提供小块作物(这样,模型就不会记住特定的地方或大的物体)。
因此,模型的任务变得更加困难(尝试从天而降猜测国家),识别精度大大降低。 但是另一方面,神经网络必须更多地关注一些小细节:异常的砖石结构,特定的图案,屋顶的类型,植物。 应用于模型的农作物的大小发生了变化,并且获得了各种模型,这些模型以不同的抽象级别查看了照片:农作物越小,任务越困难,并且模型对细节的关注就越多。

解释预测的算法可以应用于对不同大小的作物大小进行过训练的模型。 我想解释一下原始照片中的预测。 大多数现代卷积网络在最后一层之前使用
全局平均池 (GAP),这使得可以在一种尺寸上训练网络并将其应用于另一种尺寸。 这是由于以下事实:在最后一层之前,针对每个通道(特征图)将在宽度和高度上分布的空间特征平均为一个数。 因此,可以在原始大图像(800×800)上使用经过裁剪训练的模型(例如160×160像素)。
实际上,不仅需要使用GAP层,还需要使用不同分辨率的模型或进行正则化。 它还可以帮助神经网络存储有关对象位置的信息,直到最后一层(正是我们所需要的)。
我们尝试的第一种方法是
类激活映射 (CAM)。
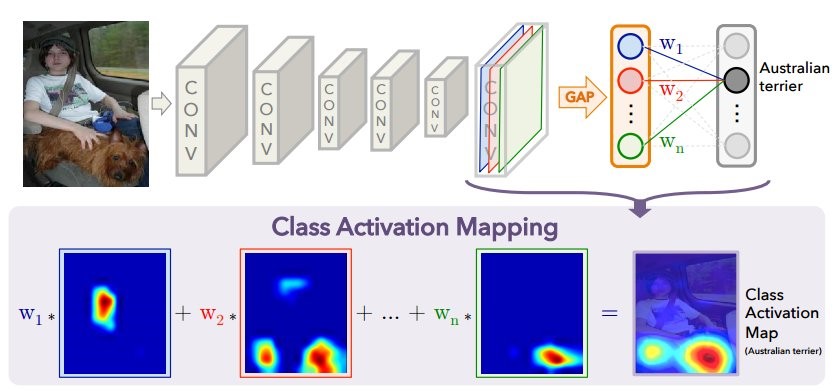
当图像被馈送到神经网络的输入端时,则在倒数第二层上,将获得缩小的“图像”(实际上是激活张量),其中每个预测类的符号都具有最重要的符号。 使用CAM方法,可以更改最后一层,以便输出是每个区域中每个类别的概率。 例如,如果您要预测60个类别(国家),则对于800×800的输入图像,最终图像将由60张25×25的激活卡组成,这在
原始出版物中已得到很好的说明。
上图显示了带有GAP的常用模型:将空间特征压缩为每个通道一个数字(特征图),然后有一个完全连接的层,该层可以预测可为每个通道找到最佳权重的类。 下面显示了如何更改体系结构以获得CAM方法:删除GAP层,并在每个点的每个通道使用在GAP训练过程中获得的最后一个完全连接的层的权重(图上方)。 对于每个图片,为所有预测的类别获得N个激活图。 对于每个国家/地区,“地图”上的区域越亮,图像的此部分对选择某个国家/地区做出的贡献就越大。 有趣的是:如果在此操作之后,我们平均每个激活图(本质上是应用GAP),那么我们只会得到每个类的初始预测。

在图像中,您可以看到最有可能(根据模型)类别的激活图。 它是通过将激活图25×25拉伸到原始图像800×800的大小而获得的。
收到每个图像的这样的地图后,我们可以汇总来自不同图像的国家最重要的农作物。 这使您可以查看农作物的收集,以最好的方式描述国家。
我们决定与第一种方法进行比较的第二种方法是简单的穷举搜索。 如果我们采用在小作物(例如160×160像素)上训练的模型,并用它预测800×800大图像上的每一块怎么办? 通过覆盖图像上每个区域的滑动窗口,我们获得了激活图的另一个版本,该图像显示图像的每个部分属于预测国家类别的可能性。

图像被切成160×160重叠的小农作物,对于每次农作物,神经网络都会做出预测,农作物上方的数字是属于模型最终预测的类别的概率。
与第一种方法一样,我们可以再次为每个国家/地区选择最可能的商品。 但是通过这两种方法获得的关于国家的图像可以是统一的(例如,来自不同角度的建筑物或纹理的一种版本)。 因此,该国的最佳农作物将被附加聚类-然后,大多数相似图像将被聚集成一个聚类。 之后,以最大的概率从每个群集中拍摄一张照片就足够了-对于每个国家,将有与指定群集一样多的图像。 我们根据从最后一个分类器层获得的特征进行了聚类。 在我们的案例中,聚集聚类被证明是最好的。

对于这两种方法,您已经收到了相当相似的管道,您可以遍历算法的参数以找到最佳组合。 例如,我们选择了裁剪的大小并确定了两个选项:160和256像素。 少于160的农作物的迹象太小,根据该迹象人们通常不理解所描绘的内容。 超过256个的作物有时会一次包含多个对象。 在聚类阶段需要选择各种参数:主要算法的选择以及进行聚类的功能。 对于许多参数组合而言,很明显,它们给出的“有趣”作物不足。 但是,为了选择最终算法,我们在Tolok上进行了并排实验,以了解哪种方法可以更好地“描述”特定国家/地区。
事实证明,在图片中查找作物的更简单方法(正常搜索)会发现更多“有趣”的对象。 这可能是由于以下事实:在第二种方法(枚举)中,神经网络看不到图像的相邻部分,而在CAM方法中,点的环境会影响结果。 结果,我们以自动模式收到了每个国家/地区特征的可视化图像。
因此,现在我们知道了框架的哪些部分对于神经网络具有决定性的重要性,并且我们可以看到它们的作用。 例如,荷兰通过深色砖墙和白色窗户轮廓的组合来识别神经网络,在阿拉伯联合酋长国(通过棕榈树为背景的特定摩天大楼)以及在伊朗(通过立面上的特征性拱门和装饰品)来识别神经网络。