在2015年,我写了Ruby提供的用于
检测托管内存泄漏的工具。 大多数情况下,文章都讨论了易于管理的泄漏。 这次,我将讨论可用于消除在Ruby中不易分析的泄漏的工具和技巧。 特别是,我将讨论mwrap,heaptrack,iseq_collector和chap。
非托管内存泄漏
这个小程序通过直接调用malloc引发泄漏。 它从消耗16 MB的RSS开始到以118 MB结束。 该代码将10万个1024字节的块放入内存中,并删除其中的5万个。
require 'fiddle' require 'objspace' def usage rss = `ps -p
尽管RSS为118 MB,但我们的Ruby对象仅知道3兆字节。 在分析中,我们只看到非常大的内存泄漏中的很小一部分。
Oleg Dashevsky描述了这种泄漏的真实示例,我建议阅读这篇精彩的文章。
应用Mwrap
Mwrap是Ruby的内存分析器,它通过拦截malloc和该系列的其他功能来监视内存中的所有数据分配。 它使用
LD_PRELOAD拦截该呼叫并释放内存。 它使用
liburcu进行计数,并可以使用C和Ruby代码跟踪每个调用点的分配和删除计数器。 Mwrap的大小很小,约为配置文件程序的RSS的两倍,而速度却是其两倍。
它与其他许多库的不同之处在于其很小的尺寸和对Ruby的支持。 它跟踪Ruby文件中的位置,而不仅限于valgrind + masif C级回溯和类似的探查器。 这大大简化了隔离问题的根源。
要使用事件探查器,您需要通过Mwrap外壳运行该应用程序,它将实现LD_PRELOAD环境并运行Ruby二进制文件。
让我们将Mwrap添加到脚本中:
require 'mwrap' def report_leaks results = [] Mwrap.each do |location, total, allocations, frees, age_total, max_lifespan| results << [location, ((total / allocations.to_f) * (allocations - frees)), allocations, frees] end results.sort! do |(_, growth_a), (_, growth_b)| growth_b <=> growth_a end results[0..20].each do |location, growth, allocations, frees| next if growth == 0 puts "#{location} growth: #{growth.to_i} allocs/frees (#{allocations}/#{frees})" end end GC.start Mwrap.clear leak_memory GC.start
现在使用Mwrap包装器运行脚本:
% gem install mwrap % mwrap ruby leak.rb leak.rb:12 growth: 51200000 allocs/frees (100000/50000) leak.rb:51 growth: 4008 allocs/frees (1/0)
Mwrap正确检测到脚本中的泄漏(50,000 * 1024)。 并且不仅确定,而且还隔离出特定的行(
i = Fiddle.malloc(1024) ),这导致了泄漏。 探查器将其正确绑定到对
Fiddle.free调用。
重要的是要注意,我们正在评估中。 Mwrap监视由拨号对等方分配的共享内存,然后监视内存的释放。 但是,如果您有一个呼叫点分配了不同大小的内存块,那么结果将是不准确的。 我们可以访问评估:
((total / allocations) * (allocations - frees))另外,为了简化泄漏跟踪,Mwrap跟踪
age_total ,它是每个释放的项目的寿命之和,还跟踪
max_lifespan ,即呼叫点上最旧项目的寿命。 如果
age_total / frees大,则尽管有大量垃圾回收,内存消耗仍在增加。
Mwrap有几个帮助减少噪音的助手。
Mwrap.clear将清除所有内部存储。
Mwrap.quiet {}将强制Mwrap跟踪代码块。
Mwrap的另一个显着特征是跟踪分配和释放的字节总数。 从脚本中删除
clear并运行它:
usage puts "Tracked size: #{(Mwrap.total_bytes_allocated - Mwrap.total_bytes_freed) / 1024}"
结果非常有趣,因为尽管RSS大小为130 MB,但Mwrap仅看到91 MB。 这表明我们夸大了过程。 没有Mwrap的执行表明,在正常情况下,该过程占用118 MB,在这种简单情况下,差异为12 MB。 分配/释放模式导致碎片化。 该知识可能非常有用,在某些情况下,未配置的glibc malloc进程碎片太多,以至于RSS中使用的大量内存实际上是可用的。
Mwrap可以隔离旧的红地毯泄漏吗?
奥列格(Oleg)在
他的文章中讨论了一种非常彻底的方法来隔离红地毯中非常细小的泄漏。 有很多细节。 进行测量非常重要。 如果您没有为RSS流程建立时间表,那么您不太可能摆脱任何泄漏。
让我们进入一个时间机器,演示使用Mwrap处理此类泄漏有多容易。
def red_carpet_leak 100_000.times do markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML, extensions = {}) markdown.render("hi") end end GC.start Mwrap.clear red_carpet_leak GC.start
红地毯3.3.2:
redcarpet.rb:51 growth: 22724224 allocs/frees (500048/400028) redcarpet.rb:62 growth: 4008 allocs/frees (1/0) redcarpet.rb:52 growth: 634 allocs/frees (600007/600000)
红地毯3.5.0:
redcarpet.rb:51 growth: 4433 allocs/frees (600045/600022) redcarpet.rb:52 growth: 453 allocs/frees (600005/600000)
如果您只需通过在Mwrap产品中重新启动并将结果记录到文件中就可以以一半的速度运行该进程,则可以确定各种内存泄漏。
神秘的泄漏
最近,Rails已更新到版本6。总的来说,体验非常好,性能保持大致相同。 Rails 6具有我们将要使用的一些非常好的功能(例如
Zeitwerk )。 Rails更改了模板的呈现方式,为了兼容性,需要进行一些更改。 更新后几天,我们注意到Sidekiq任务执行者的RSS有所增加。
Mwrap报告由于分配(
链接 )而导致内存消耗急剧增加:
source.encode!
起初我们很困惑。 我们试图了解为什么对Mwrap不满意? 也许他破产了? 随着内存消耗的增加,Ruby中的堆保持不变。
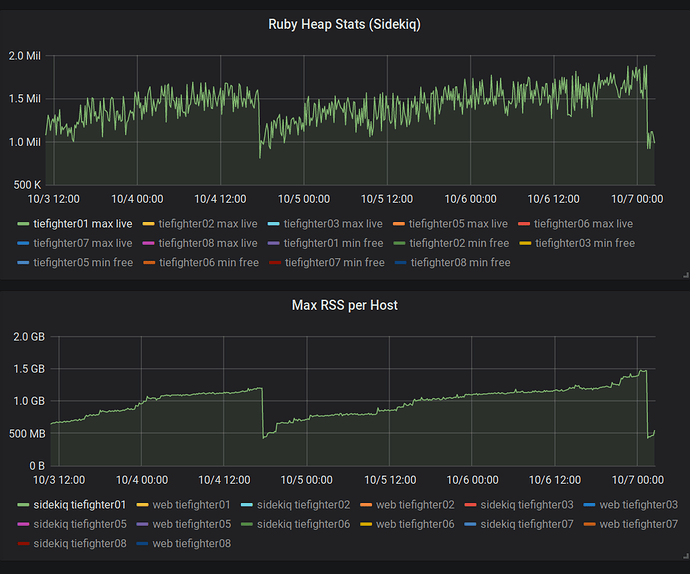
堆中的200万个插槽仅消耗78 MB(每个插槽40字节)。 行和数组可以占用更多空间,但是仍然不能解释我们观察到的异常内存消耗。 当我
rbtrace -p SIDEKIQ_PID -e ObjectSpace.memsize_of_all时,已确认这一点。
记忆去了哪里?
堆轨道
Heaptrack是Linux的堆内存分析器。
Milian Wolff完美地
解释了探查器的工作原理,并在几篇演讲(
1、2、3 )中谈到了它。 实际上,它是一个非常有效的本机堆探查器,它在
libunwind的帮助下从探查的应用程序中收集回溯。 它的工作速度明显比
Valgrind / Massif快,并且能够使其更方便地进行生产中的临时配置。 它可以附加到已经运行的进程中!
与大多数堆分析器一样,调用malloc系列中的每个函数时,Heaptrack必须计数。 此过程肯定会稍微减慢该过程。
我认为,这里的架构是所有可能中最好的。 使用
LD_PRELOAD或
GDB进行侦听以加载分析器。 他使用一个
特殊的FIFO文件,尽可能快地从概要分析过程中传输数据。
heaptrack包装器是一个简单的shell脚本,使查找问题变得更加容易。 第二个过程从FIFO读取信息,并实时压缩跟踪数据。 由于Heaptrack使用“块”进行操作,因此您可以在分析开始后几秒钟(即在会话中间)分析配置文件。 只需将配置文件复制到另一个位置,然后启动Heaptrack GUI。
这张
GitLab票告诉我有关启动Heaptrack的可能性。 如果他们可以运行它,那么我可以。
我们的应用程序在容器中运行,我需要使用
--cap-add=SYS_PTRACE重新启动它,这允许GDB使用
ptrace ,这对于Heaptrack自身注入是必需的。 我还需要一个用于Shell文件的
小技巧 ,以将
root应用于非
root进程的配置文件(我们以受限帐户在容器中启动了Discourse应用程序)。
完成所有操作后,仅执行
heaptrack -p PID并等待结果显示就可以了。 事实证明,Heaptrack是一种出色的工具,它很容易跟踪内存泄漏发生的一切。
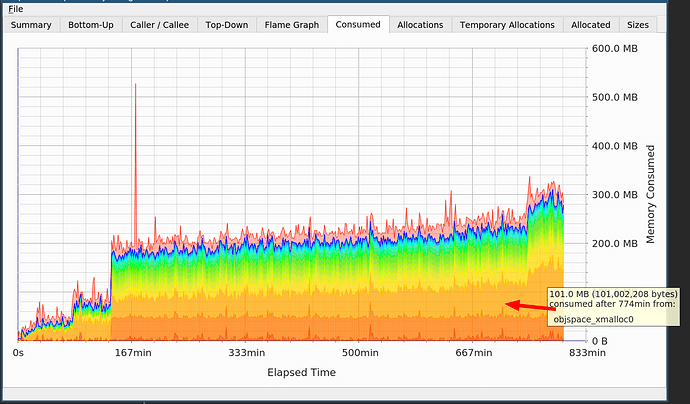
在该图上,您看到两个飞跃,一个是由于
cppjieba ,另一个是由于Ruby中的
objspace_xmalloc0引起的。
我知道
cppjieba 。 分割中文很昂贵,您需要大词典,所以这不是泄漏。 但是在Ruby中分配内存又如何呢?
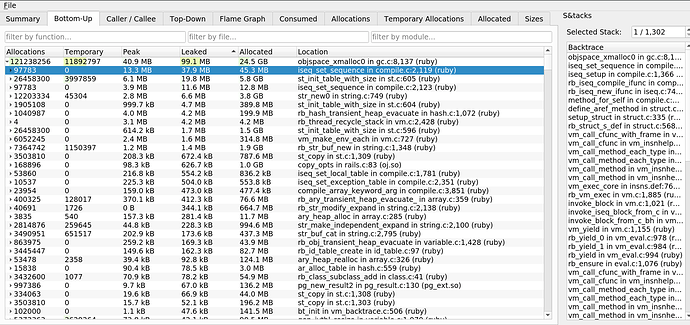
主要增益与
compile.c iseq_set_sequence有关。 事实证明,泄漏是由于指令序列引起的。 这消除了Mwrap发现的泄漏。 其原因是
mod.module_eval(source, identifier, 0) ,它创建了未从内存中删除的指令序列。
如果在回顾性分析中,我仔细考虑了Ruby的堆转储,那么我会注意到所有这些IMEMO,因为它们包含在此转储中。 在过程中诊断期间,它们只是不可见。
从这一点开始,调试非常简单。 我跟踪了对eval模块的所有调用,并转储了对它的评估。 我发现我们要一遍又一遍地向大型类添加方法。 这是我们遇到的错误的简化视图:
require 'securerandom' module BigModule; end def leak_methods 10_000.times do method = "def _#{SecureRandom.hex}; #{"sleep;" * 100}; end" BigModule.module_eval(method) end end usage # RSS: 16164 ObjectSpace size 2869 leak_methods usage
Ruby有一个用于存储
RubyVM::InstructionSequence的指令序列的类:
RubyVM::InstructionSequence 。 但是,Ruby懒于创建这些包装器对象,因为不必要地存储它们是无效的。
Sasada Koichi创建了
iseq_collector依赖项。 如果添加此代码,则可以找到我们的隐藏内存:
require 'iseq_collector' puts "#{ObjectSpace.memsize_of_all_iseq / 1024}"
实现每个指令序列,这可能会稍微增加进程的内存消耗,并使垃圾回收器多做一些工作。
例如,如果我们计算启动收集器之前和之后的ISEQ数量,我们将看到启动
ObjectSpace.memsize_of_all_iseq之后,我们的
RubyVM::InstructionSequence类的计数器将从0增加到11128(在此示例中):
def count_iseqs ObjectSpace.each_object(RubyVM::InstructionSequence).count end
这些包装器将在方法的整个生命周期中保留下来,并且需要使用完整的垃圾收集器进行访问。 通过重用负责呈现电子邮件模板的类(
修补程序1 ,
修补程序2 )解决了我们的问题。
p
在调试期间,我使用了一个非常有趣的工具。 几年前,Tim Boddy拔出了VMWare用来分析内存泄漏的内部工具,并将其代码打开。 这是我设法找到的唯一与此有关的视频:
https :
//www.youtube.com/watch?v=EZ2n3kGtVDk 。 与大多数类似工具不同,该工具对可执行过程没有影响。 它可以简单地应用于主转储文件,而glibc用作分配器(不支持jemalloc / tcmalloc等)。
使用chap,很容易检测到我的泄漏。 很少有发行版具有章二进制文件,但是您可以
从源代码轻松
编译它 。 他得到了非常积极的支持。
# 444098 is the `Process.pid` of the leaking process I had sudo gcore -p 444098 chap core.444098 chap> summarize leaked Unsigned allocations have 49974 instances taking 0x312f1b0(51,573,168) bytes. Unsigned allocations of size 0x408 have 49974 instances taking 0x312f1b0(51,573,168) bytes. 49974 allocations use 0x312f1b0 (51,573,168) bytes. chap> list leaked ... Used allocation at 562ca267cdb0 of size 408 Used allocation at 562ca267d1c0 of size 408 Used allocation at 562ca267d5d0 of size 408 ... chap> summarize anchored .... Signature 7fbe5caa0500 has 1 instances taking 0xc8(200) bytes. 23916 allocations use 0x2ad7500 (44,922,112) bytes.
Chap可以使用签名来搜索不同内存的位置,并且可以补充GDB。 在Ruby中进行调试时,它对确定进程使用的内存有很大帮助。 它显示了已使用的总内存,有时glibc malloc可能会产生很大的碎片,以致所使用的卷可能与实际的RSS有很大不同。 您可以阅读以下讨论:
功能#14759:[PATCH]为glibc malloc设置M_ARENA_MAX-Ruby master-Ruby问题跟踪系统 。 Chap能够正确计算所有已使用的内存,并提供对其分配的深入分析。
此外,chap可以集成到工作流中,以自动检测泄漏并标记此类组件。
跟进工作
这一轮调试使我提出了一些与我们的帮助程序工具包有关的问题:
总结
我们今天用于调试非常复杂的内存泄漏的工具包比4年前要好得多! Mwrap,Heaptrack和chap是非常强大的工具,用于解决开发和操作过程中出现的内存问题。
如果您正在寻找Ruby中的简单内存泄漏,建议您阅读
我的2015年文章 ,其中大部分是相关的。
我希望您下次启动调试复杂的本机内存泄漏时会发现它更容易。