
你好 我叫Askhat Nuryev,我是DINS的首席自动化工程师。
在过去的7年中,我一直在Dino Systems工作。 在这段时间里,我不得不处理各种任务:从编写自动化功能测试到测试性能和高可用性。 逐渐地,我开始更多地参与组织测试和优化流程。
在本文中,我将讲:
- 如果错误已经泄漏到生产中怎么办?
- 如果您无法用手算出错误并且不动眼,该如何竞争系统的质量?
- 自动错误处理的陷阱是什么?
- 通过分析查询统计信息,我可以获得什么好处?
DINS是RingCentral的开发中心,RingCentral是统一通信云提供商中的市场领导者。 Ringentral提供了从经典的电话,SMS,会议到联络中心和复杂团队合作产品等所有商务通信功能(la lalack)。 该云解决方案位于其自己的数据中心中,客户端仅需订阅该站点即可。
我们参与开发的该系统为200万活跃用户提供服务,每天处理超过2.75亿个请求。 我正在研究的团队正在开发API。
该系统具有相当复杂的API。 有了它,您可以发送短信,拨打电话,收集视频会议,设置帐户甚至发送传真(您好,2019年)。 以简化的形式,服务交互的方案看起来像这样。 我不是在开玩笑

显然,这样一个复杂且高负载的系统会产生大量错误。 例如,一年前,我们每周收到数以万计的错误。 这是相对于请求总数的百分之一千,但是仍然有很多错误是一团糟。 由于开发了支持服务,我们抓住了它们,但是这些错误会影响用户。 而且,系统在不断发展,客户数量在增长。 还有错误的数量。
首先,我们尝试以经典方式解决问题。
我们收集,从生产中获取日志,更正某些内容,忘记某些内容,并在Kibana和Sumologic中创建了仪表板。 但是总的来说,它没有帮助。 用户还是抱怨说漏洞一直在泄漏。 很明显,出了点问题。
自动化技术
当然,我们开始了解并看到,用于修复错误的90%的时间都花在了收集错误信息上。 确切的是:
- 从其他部门获取缺少的信息。
- 检查服务器日志。
- 研究我们系统的行为。
- 了解该系统行为是否错误。
只有剩下的10%我们直接花在开发上。
我们曾想过-但是,如果我们制作一个能够发现错误,将错误放在首位并显示解决该错误所需的所有数据的系统,该怎么办?
我必须说,这种服务的想法引起了一些关注。
有人说:“如果我们自己发现所有错误,那么为什么需要质量检查?”
其他人则相反:“您将淹没在这堆虫子中!”。
简而言之,仅了解其中哪一项是正确的,就值得提供服务。
现成的解决方案
首先,我们决定看看市场上已经有哪些类似的系统。 原来有很多。 您可以突出显示Raygun,Sentry,Airbrake,还有其他服务。
但是其中没有一个适合我们,原因如下:
- 有些服务要求我们对现有基础架构进行太大的更改,包括服务器上的更改。 Airbrake.io必须精炼数十个,数百个系统组件。
- 其他人则收集了有关我们自己的错误的数据,并将其发送到一边。 我们的安全政策不允许这样做-用户和错误数据应保留在我们手中。
- 好吧,它们也很昂贵。
我们做我们的
很明显,我们应该提供服务,尤其是因为我们已经为它建立了很好的基础架构:
- 所有服务都已将日志写入单个存储库-Elastic。 在日志中,抛出了通过所有服务的请求的统一标识符。
- 性能统计信息还记录在Hadoop中。 我们使用Impala和Metabase处理日志。
在所有服务器错误中(
根据HTTP状态代码的分类 ),就错误分析而言,最有前途的是500个代码。 响应错误502、503和504,在某些情况下,您可以在一段时间后简单地重复该请求,甚至不向用户显示答案。 并且根据RC Platform API的建议,如果用户收到响应呼叫的状态码500,则应联系支持部门。
该系统的第一个版本收集查询执行日志,所有出现的堆栈跟踪信息,用户数据,并将错误放入跟踪器中,在本例中为JIRA。
在测试运行之后,我们立即注意到系统创建了大量重复错误。 但是,在这些重复项中,许多具有几乎相同的堆栈跟踪。
必须更改识别相同错误的方法。 从分析纯统计数据开始,继续查找错误的根本原因。 堆栈跟踪很好地说明了问题,但是很难相互比较-行号因版本而异,用户数据和其他杂音也进入其中。 此外,它们并不总是进入日志-对于某些丢弃的请求,它们根本不存在。
最纯粹的形式是,堆栈跟踪不方便用于跟踪错误。
必须选择模式,堆栈跟踪的模板,并清除它们中经常更改的信息。 经过一系列实验,我们决定使用正则表达式清除数据。
结果,我们发布了一个新版本,如果可以使用堆栈跟踪,则可以通过这些唯一的模板识别错误。 如果不可用,则以旧方法,通过http方法和API组。
此后几乎没有重复。 但是,发现了许多独特的错误。
下一步是了解如何确定错误的优先级,哪些错误需要更早解决。 我们优先考虑:
基于收集到的统计信息,我们开始发布每周报告。 他们看起来像这样:
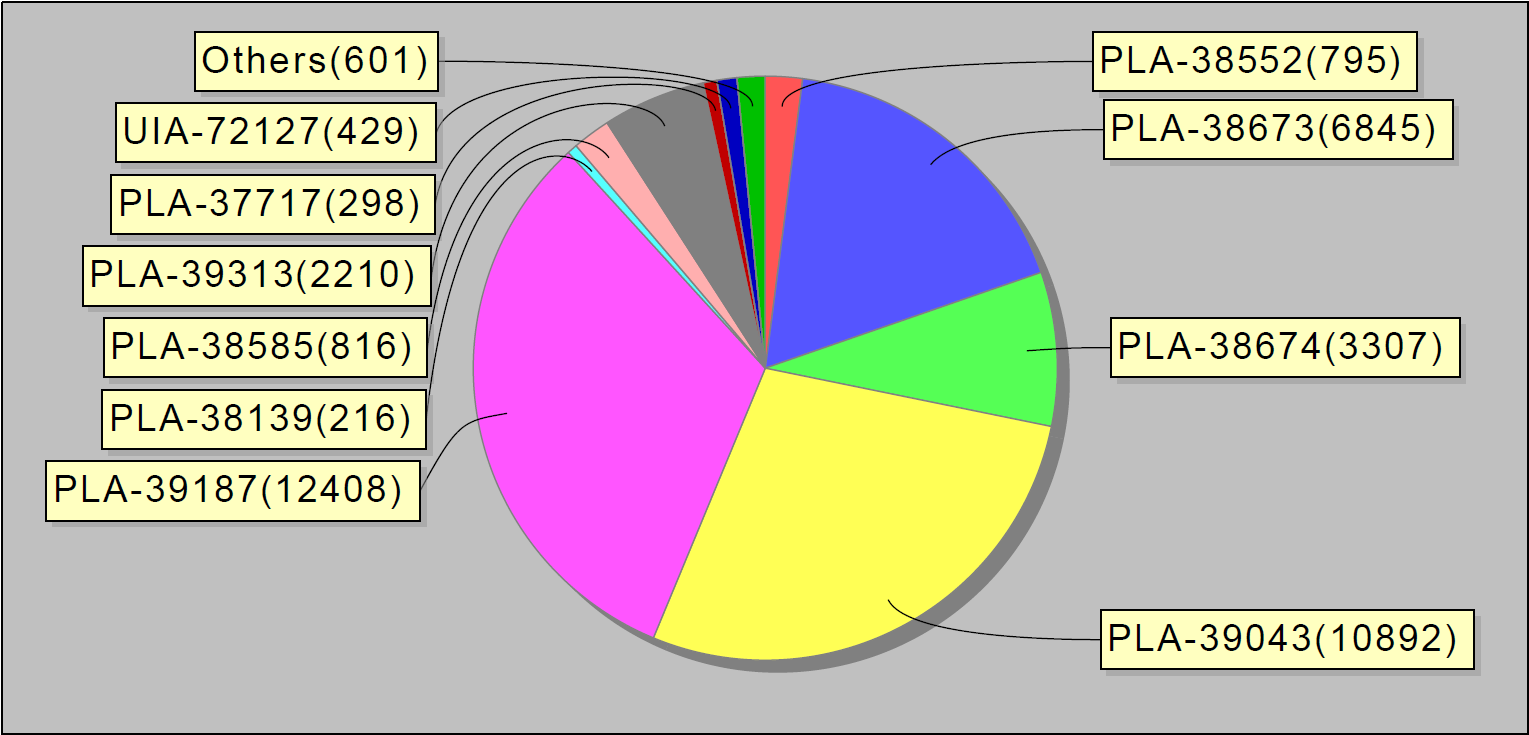
或者,例如,每周发生的前10个错误。 有趣的是,jira中的以下10个错误占服务错误的90%:
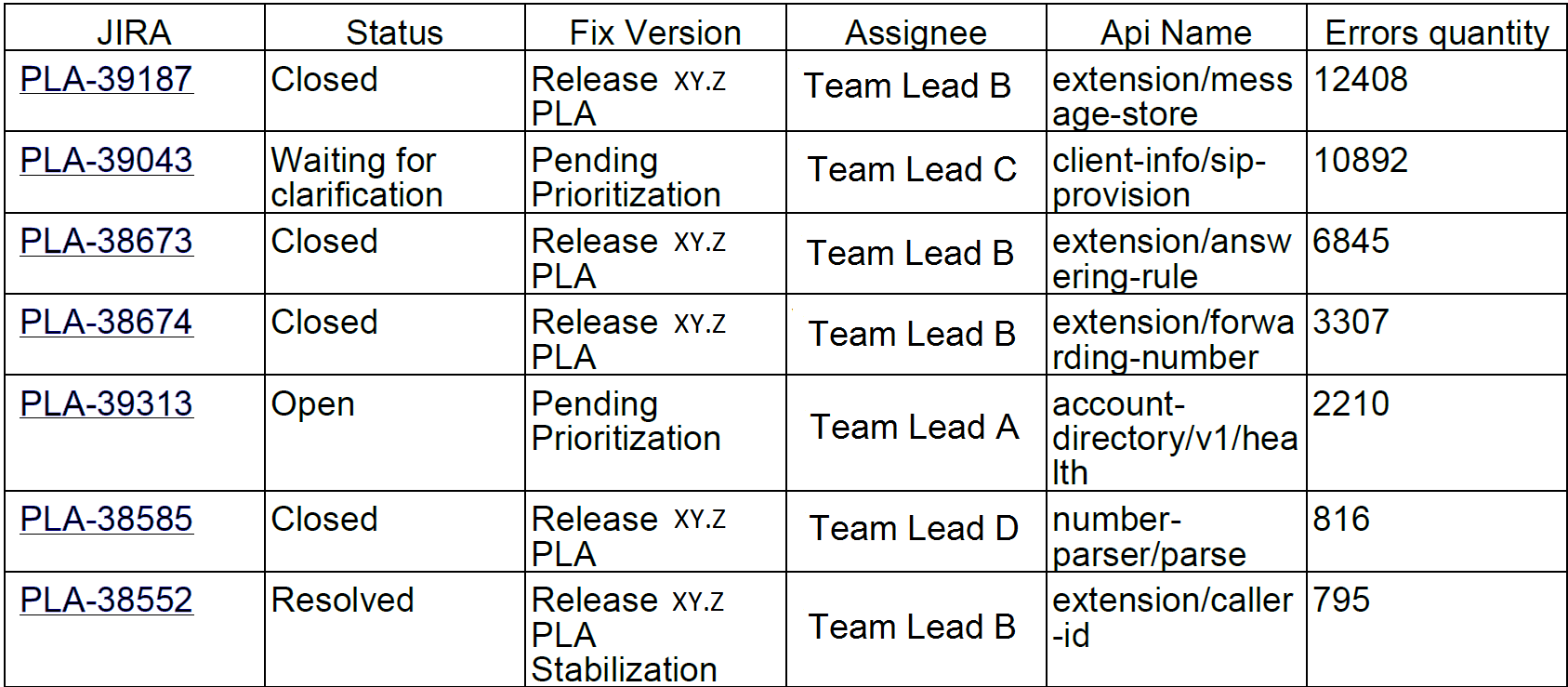
我们已将此类报告发送给开发人员和团队负责人。
在启动该系统几个月后,问题的数量明显减少了。 甚至我们小的MVP(最低可行产品)也可以帮助更好地排除错误。
问题
如果不是因为一次事故,也许我们会在这里停下来。
上班后,我发现系统像铆钉一样铆钉了一些错误:一个接一个。 经过简短的调查,很明显这些错误中有许多来自一项服务。 为了找出问题所在,我去了部署小组聊天室。 其中有些人参与了在生产中安装新版本的服务并确保它们按预期工作。
我问:“伙计,这项服务发生了什么?”。
他们回答:“一个小时前,我们在那里安装了新版本。”
我们一步一步地确定了问题,并找到了临时解决方案,换句话说,重新启动了服务器。
显然,不仅负责质量的开发人员和工程师都需要“错误的”系统。 负责生产中服务器状态的工程师以及在服务器上安装新版本的人员也对此感兴趣。 我们正在开发的服务将准确显示系统更改期间生产中发生的错误,例如安装服务器,应用新配置等。
我们决定进行另一次开发迭代。
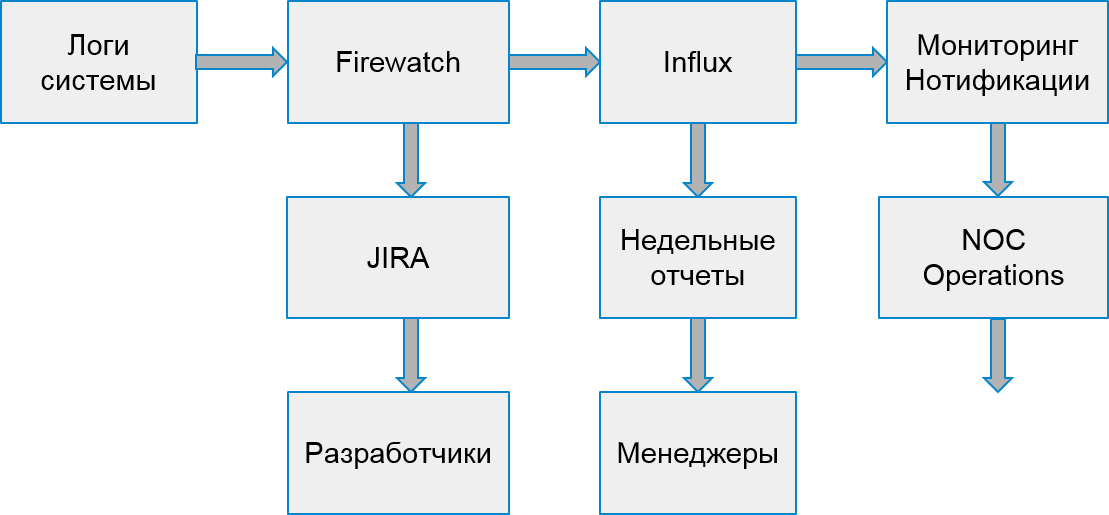
在错误处理过程中,我们将问题回放统计信息的记录添加到了Grafana中的数据库和仪表板中。 这是整个系统每天的错误图形分布,如下所示:

等等-个别服务中的错误。

我们还会将触发器与负责的工程团队逐步上报,以防万一出现很多错误。 我们还每30分钟设置一次数据收集(而不是像以前一样每天设置一次)。
我们系统的过程开始如下所示:
客户错误
但是,用户不仅遭受服务器错误的困扰。 还发生了由于客户端应用程序的实现而发生错误的情况。
为了处理客户错误,我们决定建立另一个搜索和分析过程。 为此,我们选择了两种会影响公司的错误类型:授权错误和限制错误。
节流是保护系统免受过载的一种方法。 如果应用程序或用户超出了他们的请求配额,系统将返回错误代码429和Retry-After标头,标头的值表示必须重复请求才能成功执行的时间。
如果应用程序停止发送新请求,则可以无限期地受到限制。 最终用户无法将这些错误与其他错误区分开。 结果,这导致对支持服务的投诉。
幸运的是,基础架构和统计系统甚至可以跟踪客户端错误。 我们之所以这样做,是因为使用我们的API的应用程序的开发人员必须预先注册并接收其唯一密钥。 来自客户端的每个请求必须包含一个授权令牌,否则客户端将收到一个错误。 使用此令牌,我们可以计算应用程序。
这就是节流错误监视的外观。 错误高峰对应于工作日,而周末则相反-没有错误:

与内部错误的情况相同,基于Hadoop的统计信息,我们发现了可疑应用程序。 首先,关于成功请求的数量与用代码429完成的请求的数量有关。如果我们收到的请求中有一半以上,我们认为该应用程序无法正常工作。
后来,我们开始分析具有特定用户的单个应用程序的行为。 在可疑应用程序中,我们找到了正在运行该应用程序的特定设备,并在收到第一个节流错误后观察了执行请求的频率。 如果请求频率没有降低,则应用程序未按预期处理错误。
部分应用程序是在我们公司开发的。 因此,我们能够立即找到负责任的工程师并迅速纠正错误。 我们决定将其余的错误发送给与外部开发人员联系并帮助他们修复其应用程序的团队。
对于每个此类应用程序,我们:
- 我们在JIRA中创建任务。
- 我们在Influx中记录统计数据。
- 如果错误数量急剧增加,我们将为手术干预做准备。
用于处理客户端错误的系统如下所示:
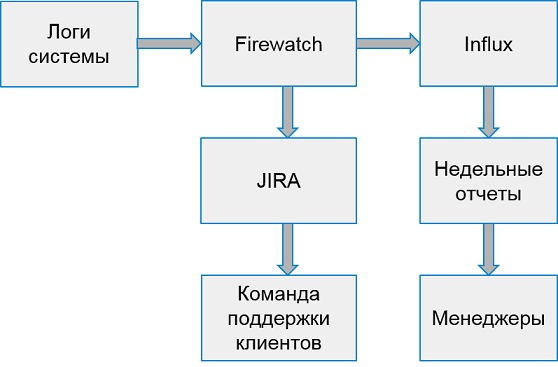
每周一次,我们会根据错误数量从前10个最差的应用程序中收集报告。
不要抓,但要警告
因此,我们学习了如何在生产系统中发现错误,学习了如何处理服务器错误和客户端错误。 一切似乎都很好,但是...
但实际上,我们做出的回应为时已晚-错误已影响用户!
为什么不尝试更早发现错误?
当然,在测试环境中找到所有内容很酷。 但是测试环境是白噪声的空间。 他们正在积极开发中,每天都有几种不同版本的服务器工作。 集中于它们的错误还为时过早。 它们中有太多错误,每件事都经常改变。
但是,该公司具有特殊的环境,其中集成了所有稳定的组件以检查性能,集中式手动回归和高可用性测试。 通常,这样的环境仍然不够稳定。 但是,有些团队对解析这些环境中的问题感兴趣。
但是还有另一个障碍-Hadoop无法从这些环境中收集数据! 我们不能使用相同的方法来检测错误;我们需要寻找不同的数据源。
经过短暂的搜索,我们决定处理统计信息流,从服务写入队列中读取数据以传输到Hadoop。 累积唯一的错误并分批处理(例如,每30分钟一次)就足够了。 建立可以传送数据的排队系统很容易-剩下的就是完善收据和处理。
我们开始观察发现后发现的错误的行为。 事实证明,发现的大多数错误并没有得到修复,这些错误会在稍后的生产中出现。 因此,我们可以正确找到它们。
因此,我们构建了系统,机构和跟踪错误的原型。 它以当前的形式提供,它使您可以提高系统的质量,在用户了解错误之前注意到并纠正错误。 如果早些时候我们每周处理成千上万个错误请求,那么现在只有2-3千个。 而且我们可以更快地纠正它们。
接下来是什么
当然,我们不会止步于此,并将继续改善搜索和跟踪错误的系统。 我们有计划:
- 分析更多API错误。
- 与功能测试集成。
- 调查系统中事件的其他功能。
但是,下次再说。