Nikolay Sivko对报告“典型的监视实施”的解码。
我叫Nikolai Sivko。 我也做监控。 Okmeter是我要做的5次监控。 我决定将所有人员从监视的地狱中解救出来,并将我们从某个痛苦中解救出来。 我总是尽量不要在演示文稿中宣传测压计。 自然,图片将来自那里。 但是我想说的是,我们使监视方法与每个人通常都略有不同。 我们谈论很多。 当我们试图说服每个人时,最终他变得说服了。 我想准确地谈谈我们的方法,以便您自己进行监控,从而避免我们的抽水。

概括地说,Okmeter。 我们和您一样,但是有各种各样的筹码。 筹码:

一个典型的客户来找我们。 他有两个任务:
1)知道什么都没有,一切都从监视中分解了。
2)快速修复它。
他来监视正在发生的事情的答案。
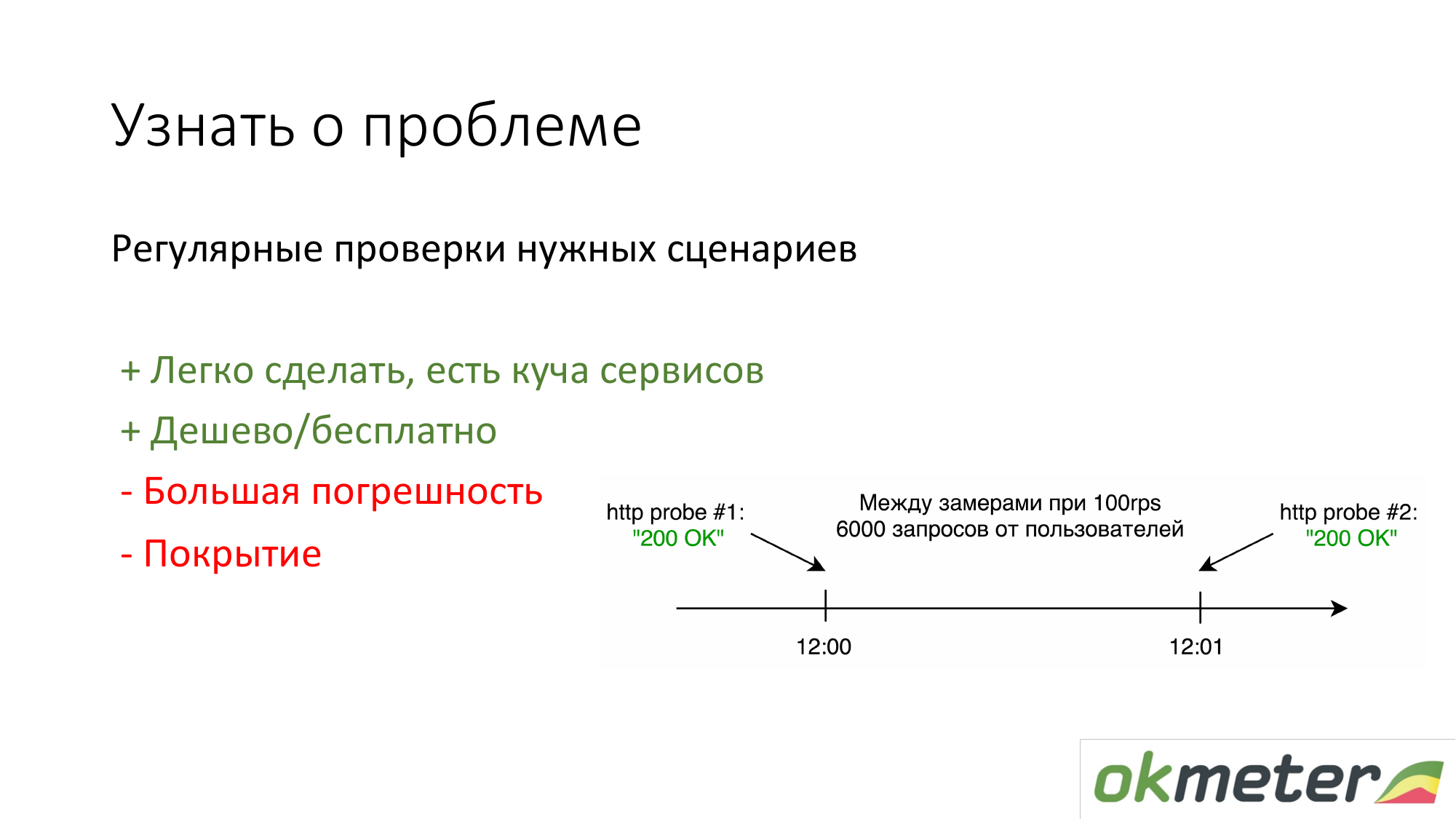
没有任何东西的人要做的第一件事就是放置https://www.pingdom.com/和其他服务进行验证。 该解决方案的优点是可以在5分钟内完成。 您将不再从客户电话中了解问题。 准确性存在问题,因此他们可以跳过问题。 但是对于简单的站点,这已足够。

我们主张的第二件事是根据实际用户的统计信息按日志计数。 那就是特定用户获得5xx错误的程度。 用户的响应时间是多少? 有缺点,但是总的来说,这样的事情是可行的。

关于nginx:我们做到了这一点,以便任何即将到来的客户端都将代理置于前端,并且它会自动拾取所有内容,它开始解析,开始出现错误,依此类推。 他几乎没有什么可配置的。

但是大多数客户端在标准nginx日志中都没有计时器。 这90%的客户不想知道他们网站的响应时间。 我们一直都面临着这个问题。 有必要扩展nginx日志。 然后,我们立即自动开始显示直方图。 这可能是必须测量时间这一事实的重要方面。

我们要从那里拉什么? 实际上,我们采用此类维度的指标。 这些不是固定指标。 该指标称为index.request.rate-每秒查询数。 详细信息如下:
- 从中删除日志的主机;
- 从中获取此数据的日志;
- http方法
- http状态;
- 缓存状态。
这不是每个带有所有参数的特定URL。 我们不想从日志中删除100,000个指标。

我们要采用1000个指标。 因此,如果可能的话,我们正在尝试标准化URL。 取得最上面的URL。 对于有意义的URL,我们将显示一个单独的条形图,分别为5xx。

这是一个简单的指标如何变成可用图形的示例。 这是我们的DSL。 我尝试使用此DSL来解释大概的逻辑。 我们每秒接收所有nginx请求,并将其布置在我们拥有的所有计算机上。 了解有关如何平衡它,总RPS(每秒请求数,每秒请求数)的知识。

另一方面,我们可以过滤该指标并仅显示4xx。 在4xx图表上,可以根据真实状态布置它们。 我提醒您,这是相同的指标。

在图形上,您可以按URL显示4xx。 这是相同的指标。

我们还从日志中拍摄直方图。 直方图是response_time.histrogram指标,它实际上是带有附加级别参数的RPS。 这只是请求在哪个存储桶中截取的时间。
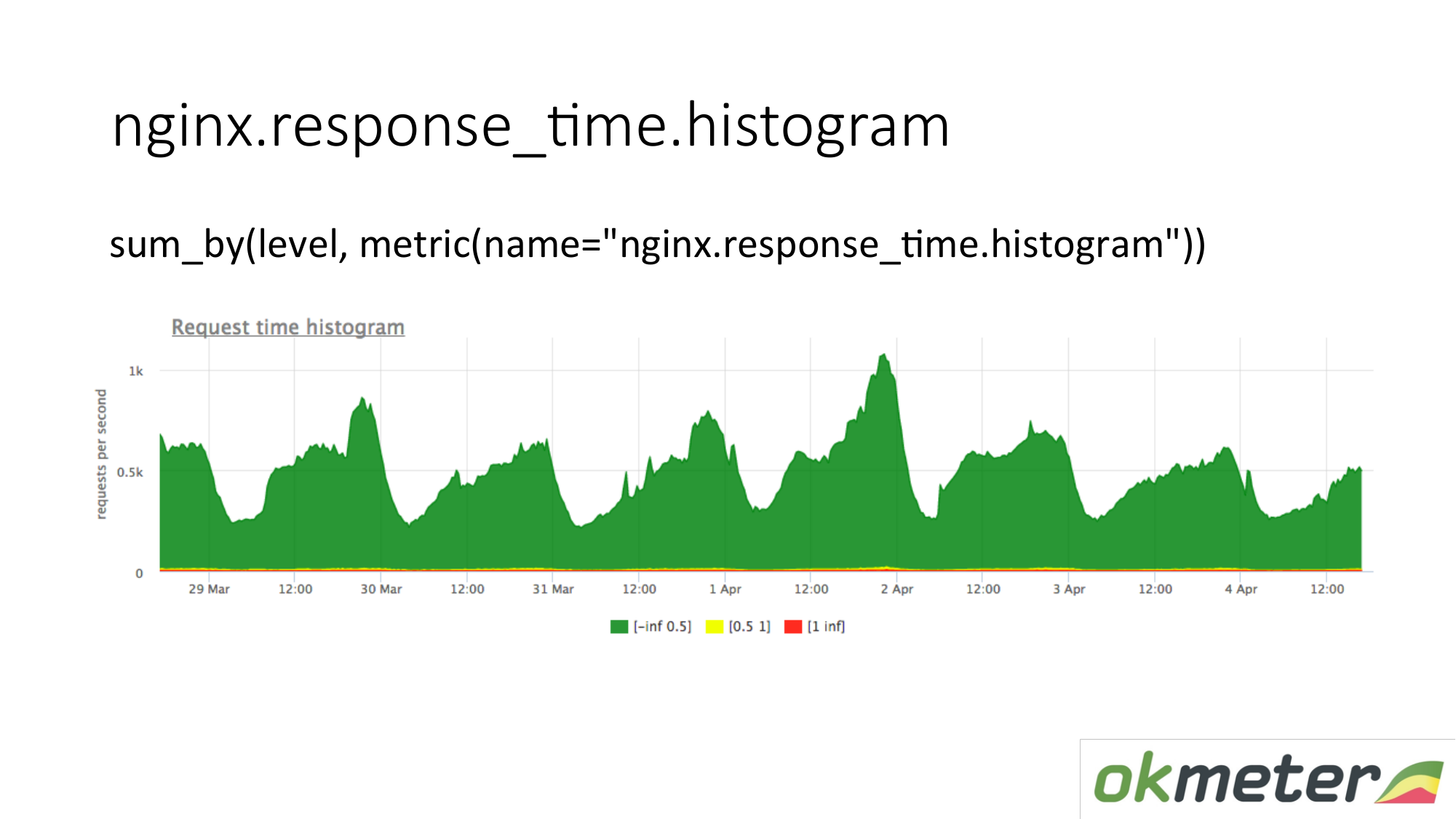
我们提出一个请求:总结整个直方图并将其分类为多个级别:
我们有一张已经由服务器汇总的图片。 指标是相同的。 它的物理意义是可以理解的。 但是我们以完全不同的方式利用它。
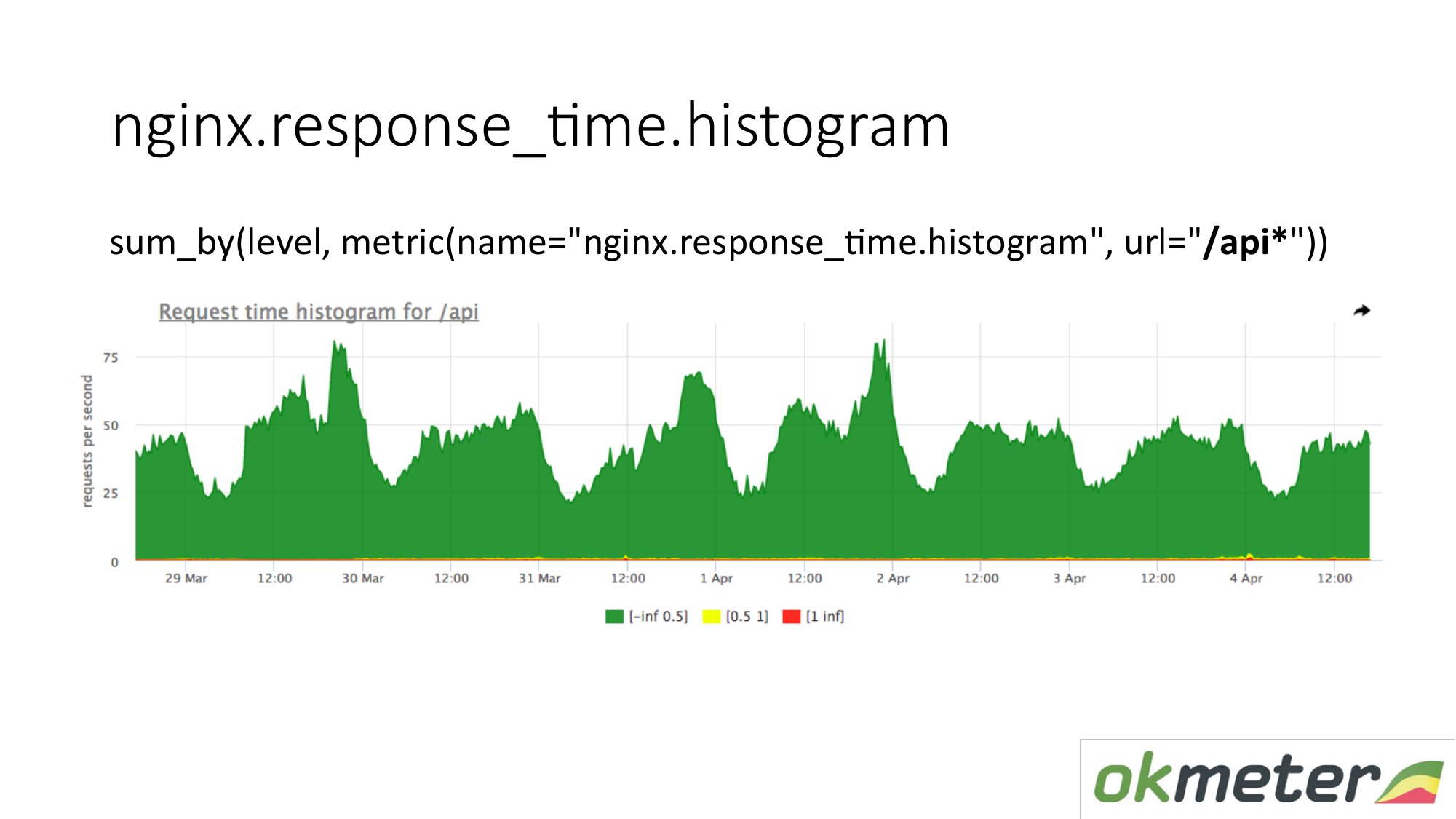
在图表上,您只能通过以“ / api”开头的URL来显示直方图。 因此,我们分别查看直方图。 我们现在看多少钱。 我们看到“ / api” URL中有多少RPS。 相同的度量标准,但应用程序不同。

关于nginx中的计时的几句话。 这里有request_time,其中包括从请求开始到将最后一个字节传输到套接字到客户端的时间。 还有上游响应时间。 它们都需要被测量。 如果我们只是删除request_time,那么您将看到由于服务器的客户端连接问题而导致的延迟,如果我们配置了限制请求c突发并且客户端处于浴池中,那么您将看到延迟。 您将不知道是否需要维修服务器或致电托管服务商。 因此,我们将两者都删除,可以很清楚地看到发生了什么。

为了了解该站点是否正常运行,我相信我们已经或多或少地对其进行了整理。 有错误。 有不正确之处。 一般原则如下。
现在有关监视多层体系结构。 因为即使最简单的在线商店也至少具有前端,然后是bitrix和base。 这已经是很多链接了。 总的来说,您需要从每个级别拍摄一些指标。 也就是说,用户正在考虑前端。 前端正在考虑后端。 后端考虑相邻的后端。 他们都在考虑基础。 因此,我们逐层,依存地进行了研究。 我们以某种指标涵盖所有内容。 我们在出口处得到东西。

为什么不限于一层? 通常,各层之间是一个网络。 负载下的大型网络是极其不稳定的物质。 因此,一切都在那里发生。 另外,您可以在哪一层进行测量。 如果在“ A”层和“ B”层上进行测量,并且它们之间通过网络相互影响,则可以比较它们的读数,发现一些异常和不一致之处。

关于后端。 我们想了解如何监视后端。 用它做什么可以快速了解正在发生的事情。 我提醒您,我们已经着手减少停机时间。 关于后端,我们通常建议您理解:
- 该资源吃了多少?
- 我们有没有遇到任何限制?
- 运行时情况如何? 例如,JVM运行时平台,Golang运行时和其他运行时。
- 当我们已经涵盖了所有这些内容之后,对我们来说,更接近我们的代码变得很有趣。 我们可以使用自动仪器(statsd,* -metric),这将向我们展示所有这些。 或通过设置计时器,计数器等来指导自己。
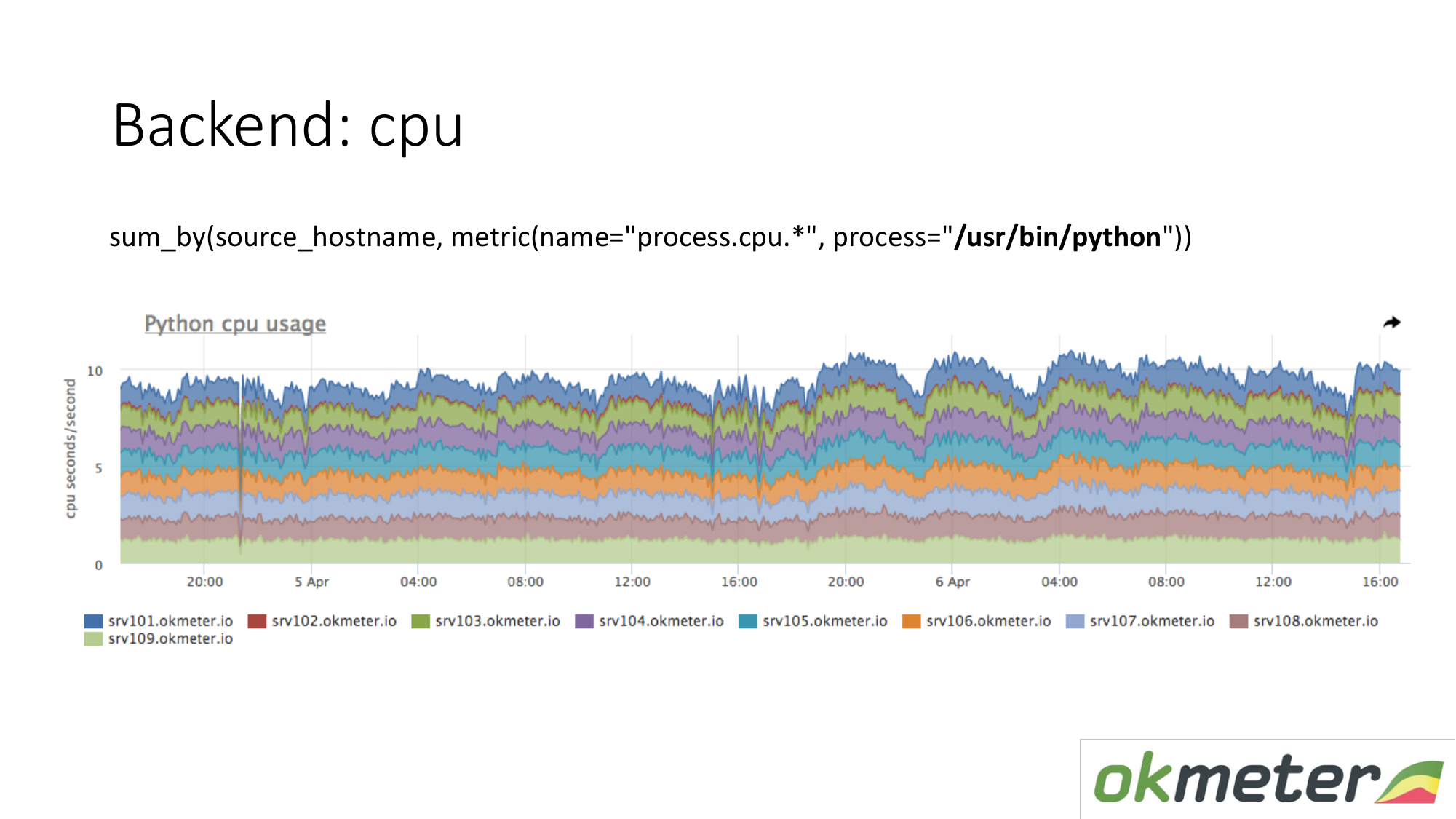
关于资源。 我们的标准代理消除了所有流程的资源消耗。 因此,对于后端,我们不需要单独捕获数据。 我们来看看有多少CPU消耗了该进程,例如被屏蔽的服务器上的Python。 我们在同一图表上显示群集中的所有服务器,因为我们想了解是否存在不平衡以及一台计算机上是否发生了爆炸。 我们看到从昨天到今天的总消费。
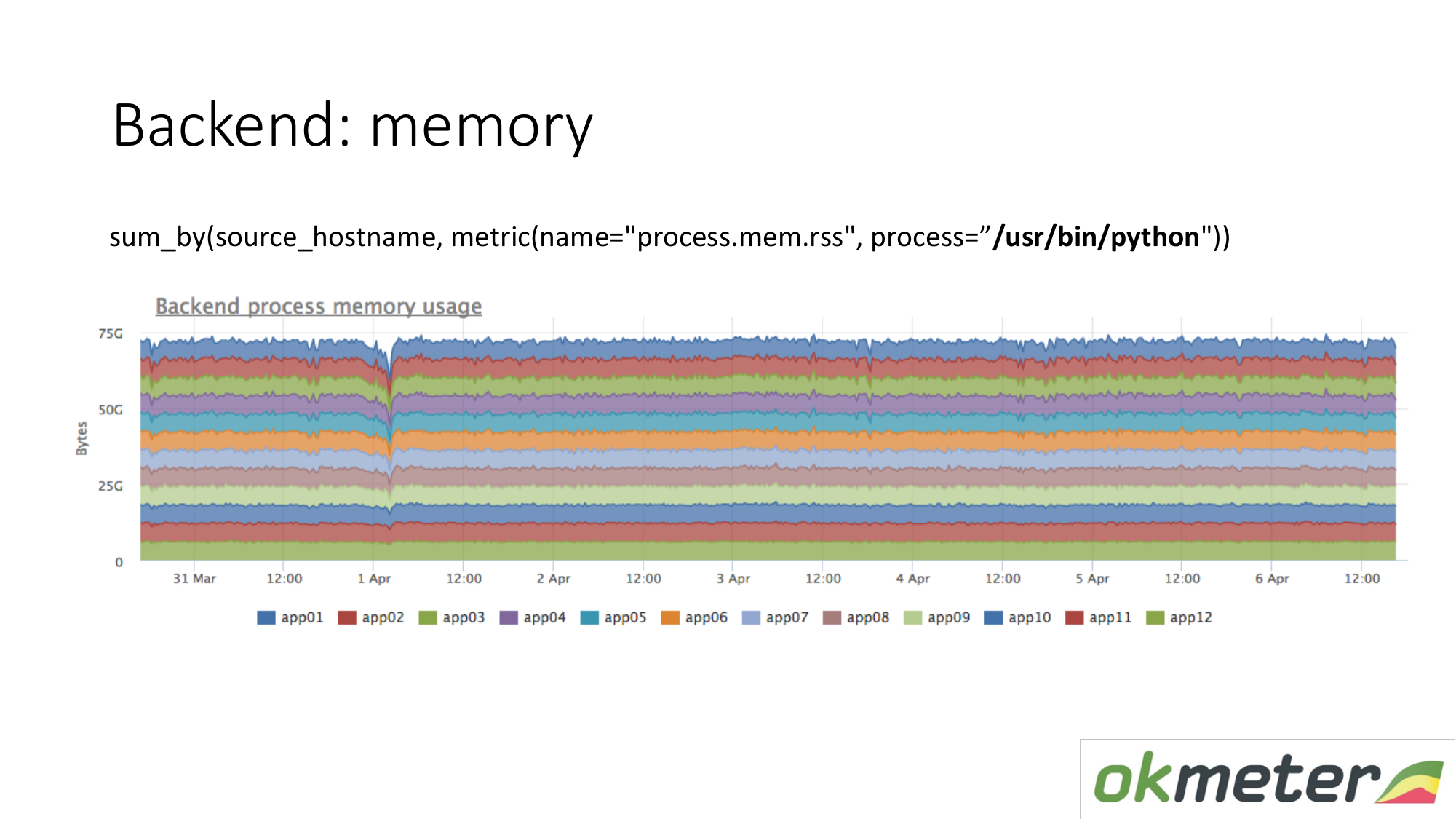
内存也一样。 当我们这样绘制时。 我们选择Python RSS(RSS是操作系统分配给进程的内存页面的大小,当前位于RAM中)。 按主机求和。 我们无处可寻。 内存均匀分布。 原则上,我们收到了我们问题的答案。
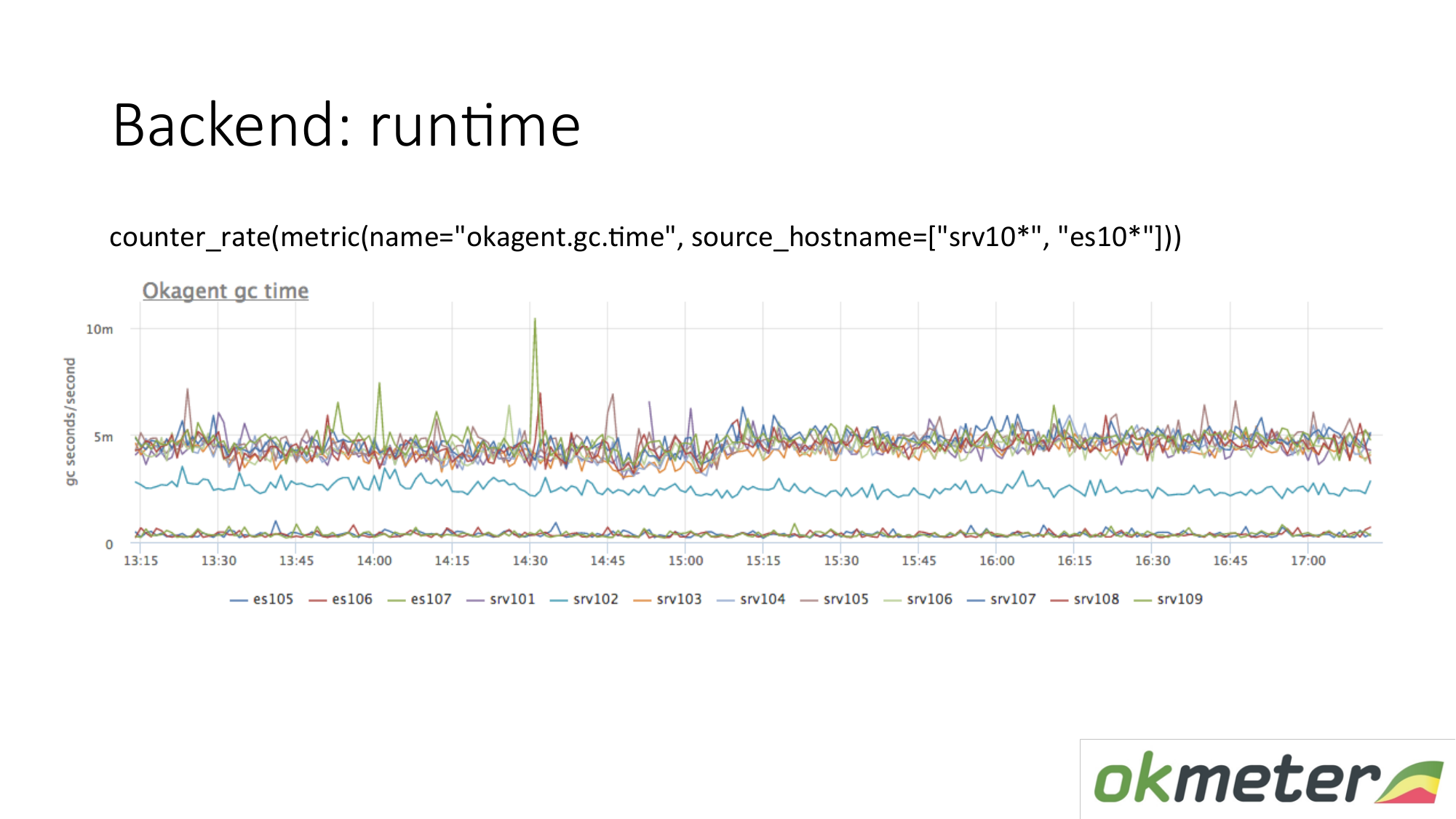
运行时示例。 我们的代理人是用Golang写的。 Golang代理将自身的运行时指标发送给自己。 特别是这是Golang垃圾收集器每秒在垃圾收集上花费的秒数。 我们在这里看到某些服务器与其他服务器具有不同的指标。 我们看到了异常情况。 我们正在尝试解释这一点。
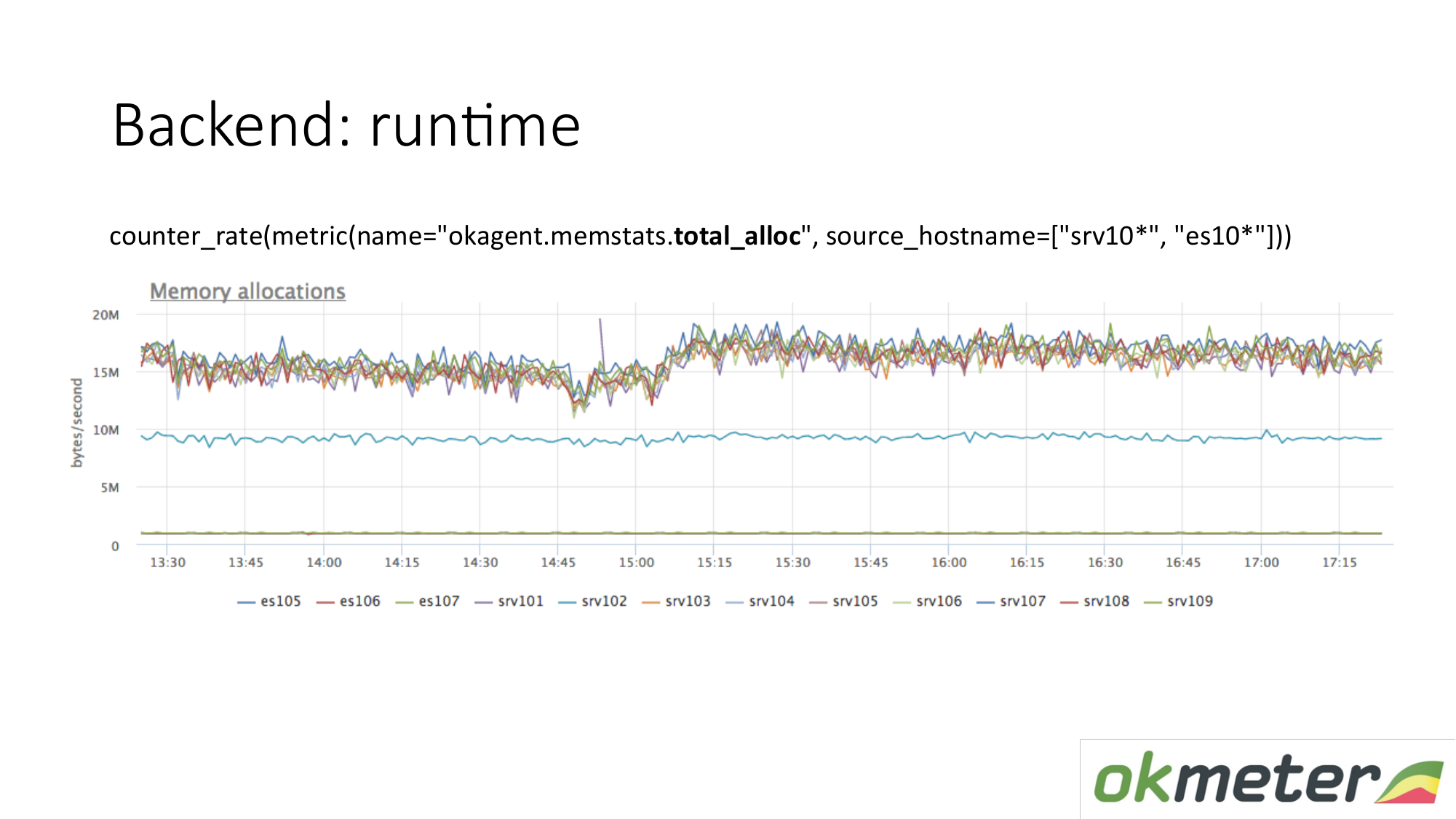
还有另一个运行时指标。 每单位时间分配多少内存。 我们看到,顶部类型的代理分配的内存要比地址较低的代理分配的内存更多。 以下是使用不那么积极的垃圾收集器的代理。 这是合乎逻辑的。 分配,释放的内存越多,垃圾收集器上的负载就越大。 此外,根据我们的内部指标,我们了解为什么我们要在这些计算机上拥有如此多的内存而在这些计算机上却拥有更少的内存。
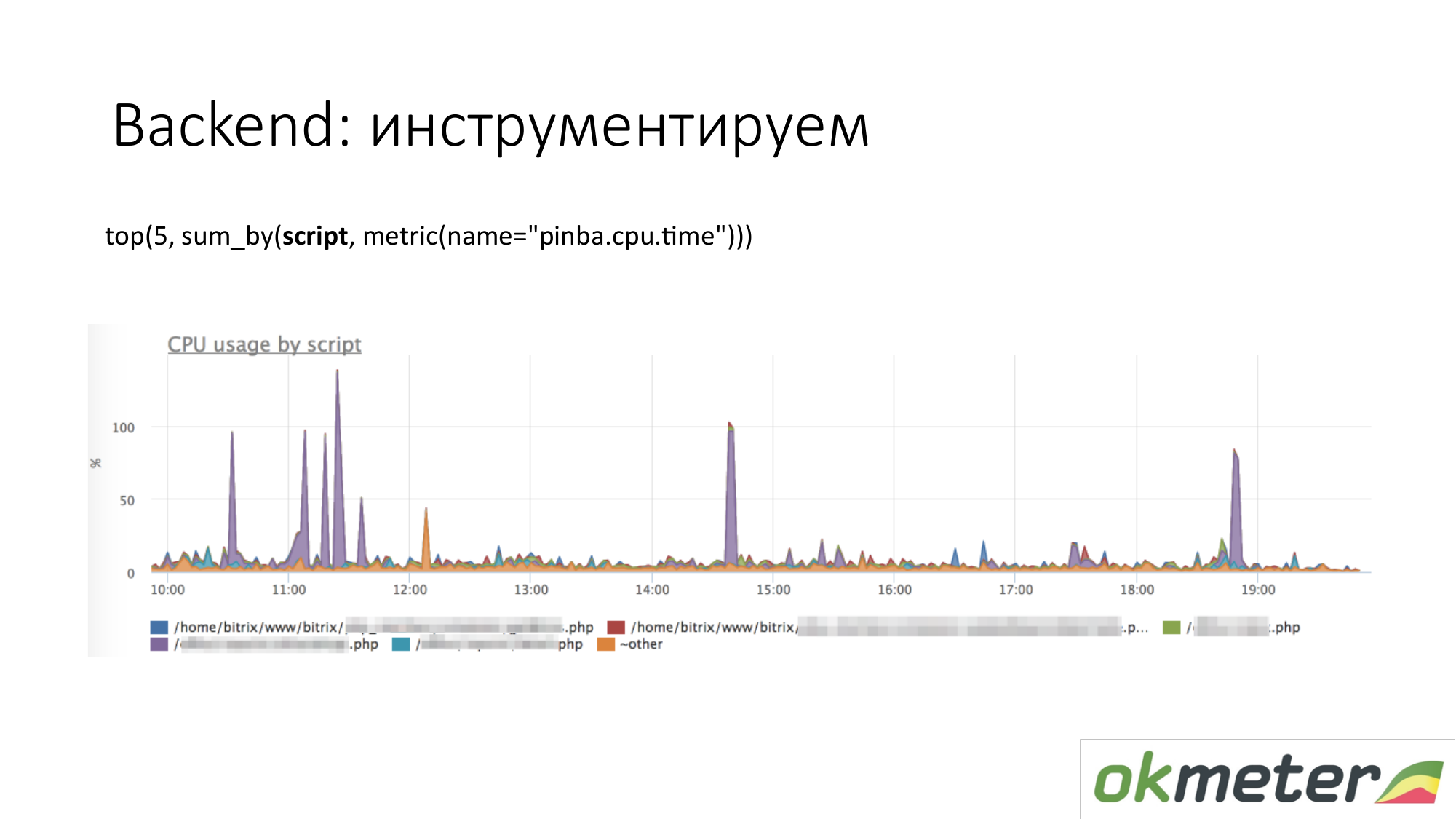
当我们谈论工具时,诸如php的http://pinba.org/之类的各种工具都会出现。 Pinba是Badoo的php扩展,您可以安装并连接到php。 它允许您立即删除并通过UDP发送protobuf。 他们有一个pinba服务器。 但是我们在代理中制作了一个嵌入式Pinba服务器。 PHP向自己发送了在这些脚本上花费了多少CPU和内存,这些脚本提供了多少流量等信息。 这是Pinba的示例。 我们显示了有关CPU消耗的前5个脚本。 我们看到一个紫色异常值,这是PHP的污点。 我们将修复PHP的污点,或者了解为什么它会占用CPU。 我们已经缩小了问题的范围,以便我们理解以下步骤。 我们去看一下代码并修复它。

交通流量也是如此。 我们来看前5个流量脚本。 如果这对我们很重要,那么我们去了解。

这是有关我们内部工具的图表。 当我们通过statsd设置计时器并测量指标时。 我们这样做是为了根据我们当前正在处理的处理程序以及您代码的重要阶段来分配在CPU或预期的某些资源上花费的总时间:它们等待cassander,等待elasticsearch。 该图显示了/指标/查询处理程序的前5个阶段。 在该图上,您可以显示CPU消耗的前5个处理程序,因此内部发生了什么。 很明显,要解决的问题。
关于后端,您可以更深入。 有些事情可以进行跟踪。 也就是说,您可以看到带有cookie之类的特定用户请求,而IP已向数据库生成了如此多的请求,他们一直在等待这么长时间。 我们无法跟踪。 我们没有追踪。 我们仍然可以相信,我们不进行应用程序和性能监视。

关于数据库。 一样 数据库是相同的过程。 他消耗资源。 如果基准对延迟非常敏感,则功能会稍有不同。 我们建议检查是否有最少的资源,资源没有退化。 理想的情况是了解,如果基础开始消耗的资源超过消耗的资源,那么请了解代码中到底发生了什么变化。
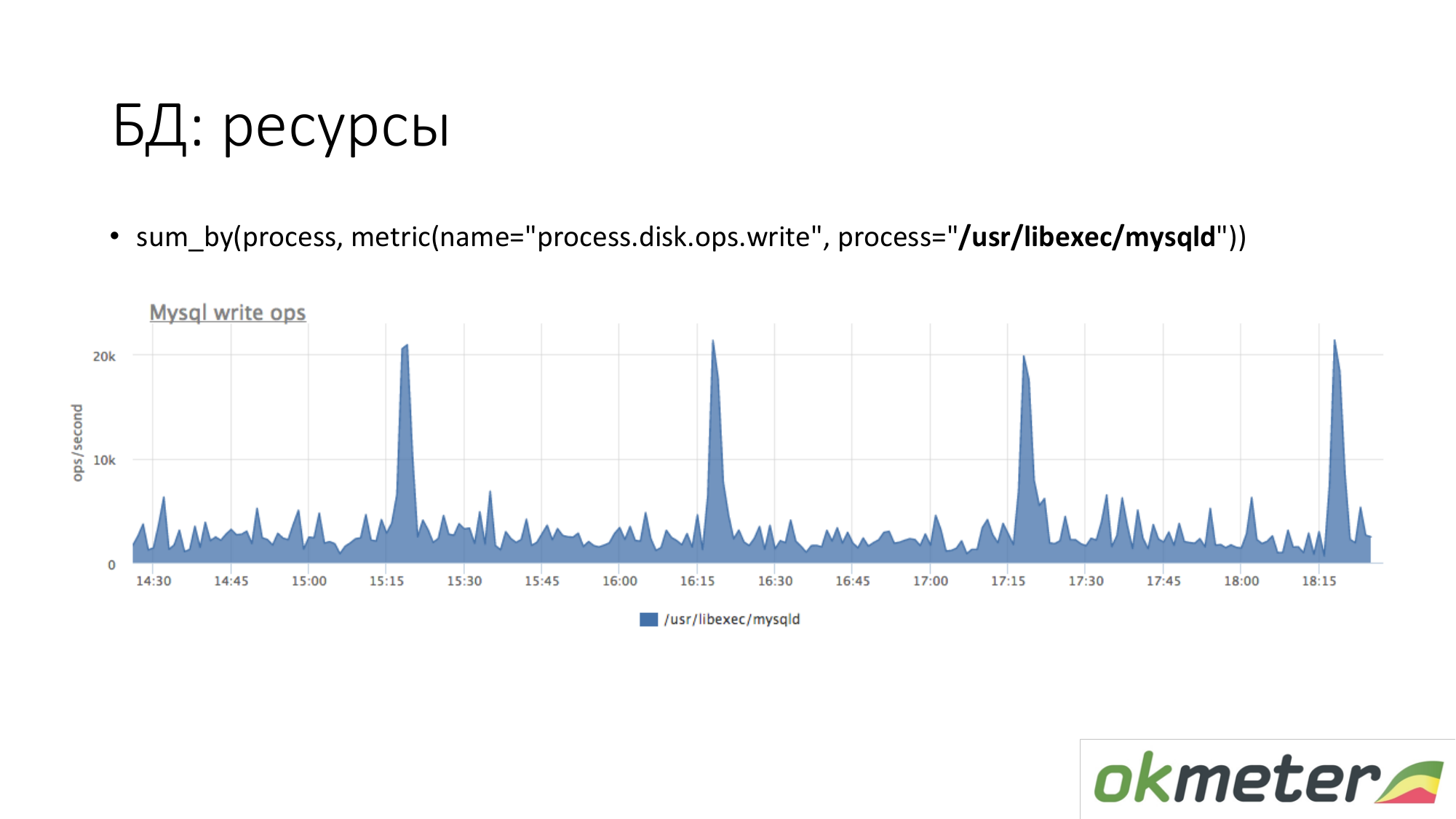
关于资源。 以同样的方式,我们查看MySQL进程在磁盘上生成了多少。 我们看到平均而言,有很多东西,但是会出现一些高峰。 例如,有很多插入插入,它开始在15.15、16.15、17.15写入磁盘。
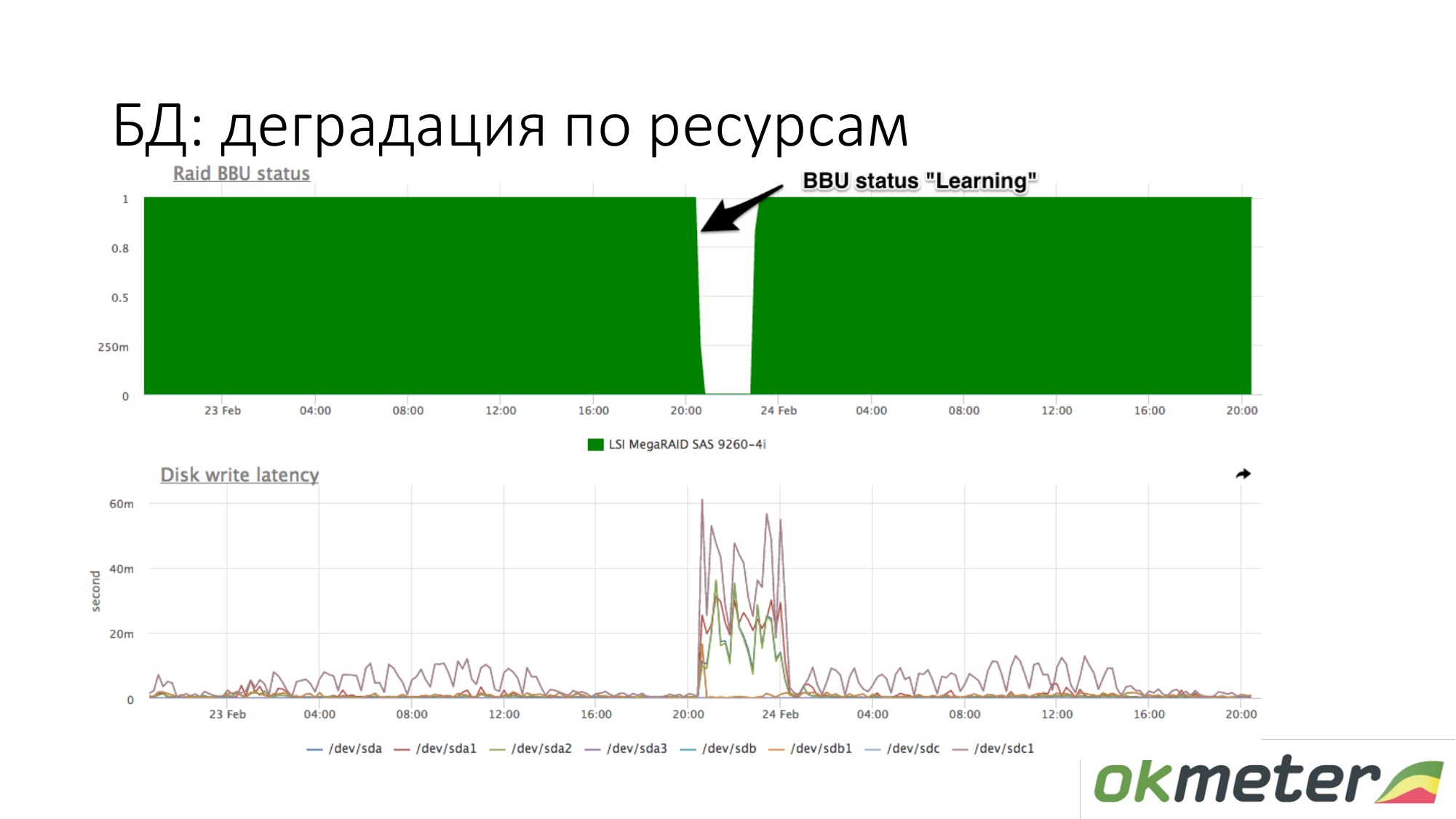
关于资源的退化。 例如,RAID电池已进入维护模式。 她不再像现场电池那样当控制器。 此时,写缓存断开,写磁盘的延迟增加。 此时,如果数据库在等待磁盘时开始变暗,并且您大概知道在写入磁盘延迟时负载相同,则检查RAID中的电池。

按需资源。 这里不是那么简单。 取决于基础。 该基地应该能够自我介绍:它在请求什么上花费资源,等等。 领导者是PostgreSQL。 他有pg_stat_statements。 您可以了解使用大量CPU,读取和写入磁盘以及流量的请求类型。
老实说,在MySQL中,一切都更糟。 它具有performance_schema。 它从5.7版开始以某种方式起作用。 与PostgreSQL中的单个视图不同,Performance_schema是MySQL中的27或23系统视图表。 有时,如果您在错误的表上(在错误的视图上)进行查询,则可以浪费MySQL。
Redis有团队统计数据。 您会看到某个命令使用了很多CPU等。
Cassandra有时间查询特定的表。 但是,由于设计了cassandra,以便对表进行一种查询,因此足以进行监视。
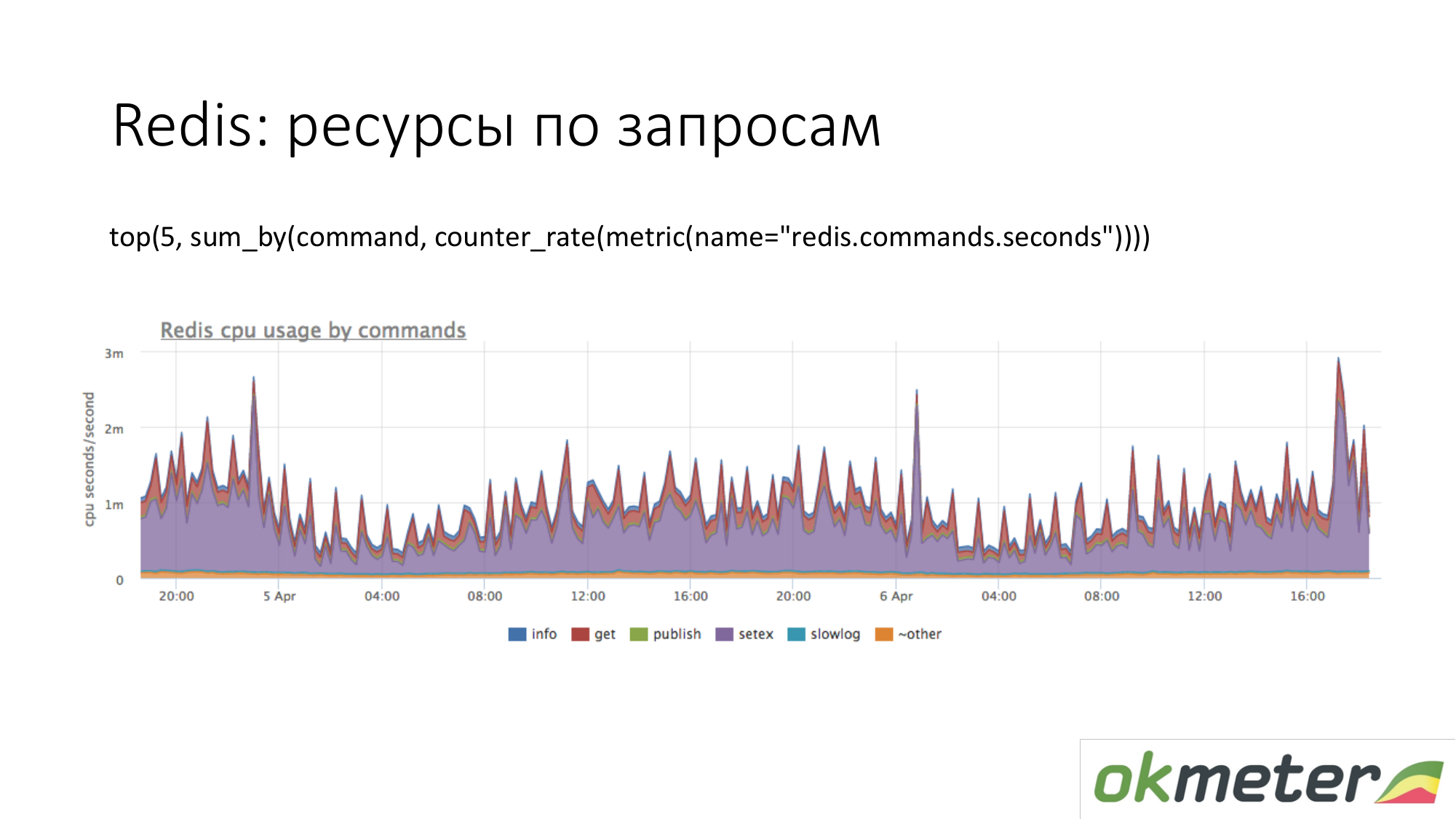
这是Redis。 我们看到紫色使用大量CPU。 紫罗兰是setex。 Setex-TTL安装的关键记录。 如果这对我们很重要,那么让我们开始吧。 如果这对我们不重要,那么我们仅知道所有资源的去向。
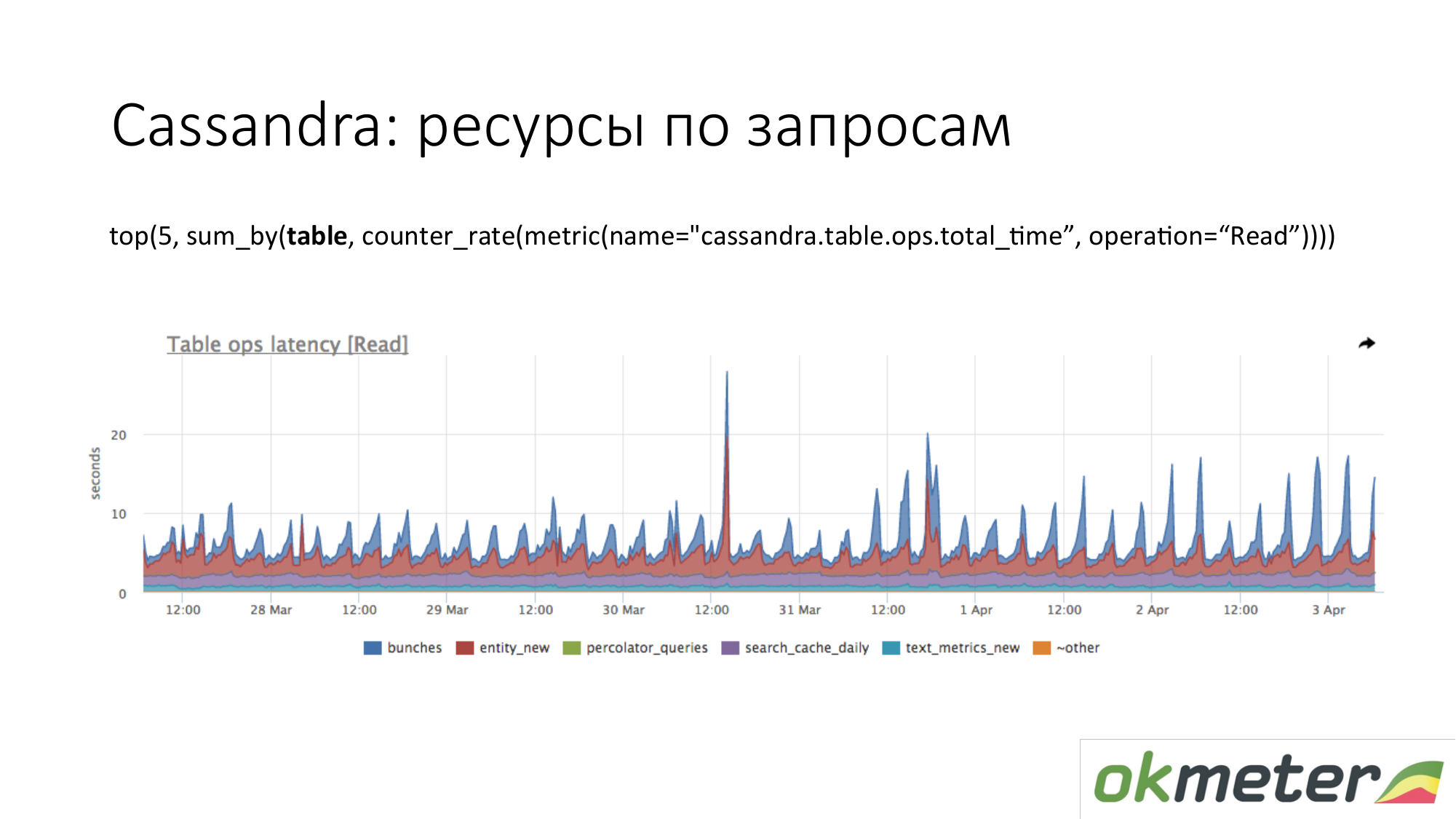
卡桑德拉。 我们以总响应时间列出了读取请求的前5个表格。 我们看到这种激增。 这些是对表的查询,我们可以粗略地理解,对该表的查询只需一段代码。 Cassandra不是可在表中进行不同查询的SQL数据库。 卡桑德拉(Cassandra)越来越令人沮丧。

关于工作流处理事件的几句话。 如我所见。
关于警报。 我们对事件工作流程的看法与普遍接受的观点不同。

严重的。 我们通过短信和所有实时通信渠道通知您。
Severy Info是一个灯泡,可以在处理事件时为您提供帮助。 信息不会在任何地方得到通知。 信息只是挂起并告诉您正在发生某些事情。
严重警告是可以通知的,也许不是。

关键示例。
该站点根本无法工作。 例如,5xx 100%或响应时间增加了,用户开始离开。
业务逻辑错误。 关键是什么。 有必要测量每秒钱。 每秒金钱是Critical的良好数据来源。 例如,订单数量,广告促销等。

具有Critical的工作流,因此无法延迟此事件。 您无法单击“确定”并回家。 如果Critical来找您并且您正在乘坐地铁,那么您必须离开地铁,出门在外,坐上长凳,然后开始维修。 否则,这不是至关重要的。 基于这些考虑,我们构造了剩余属性的剩余严重性。

警告。 警告示例。
- 磁盘空间用完。
- 内部服务可以工作很长时间,但是如果您没有Critical,则意味着您始终是有条件的。
- 网络接口上的许多错误。
- 最有争议的是服务器不可用。 实际上,如果您有多个服务器并且该服务器不可用,则为警告。 如果您没有100个后端中的1个,那么从SMS唤醒就太愚蠢了,您将使管理员感到紧张。
其他所有Severy旨在帮助您应对Critical。

警告。 我们提倡使用这种方法来处理警告。 最好是白天警告关闭。 我们的大多数客户已禁用警告通知。 因此,它们没有所谓的监控失明。 这意味着在邮件中折叠字母而无需阅读单独的目录。 客户端已禁用警告警报。
(据我了解,纯监视是不必要的警报和添加到异常中的触发器-帖子作者的注释)
如果您使用纯监视技术,并且有5个新警告,则可以在安静模式下修复它们。 他们没有时间今天修复它,但是他们将其推迟到明天,即使不是很关键的时候。 如果警告灯亮起并自行熄灭,则在监视中必须将其扭曲,以免再次打扰。 然后,您将对它们更加宽容,因此生活将得到改善。

信息示例。 许多关键的高CPU使用率值得商de。 实际上,如果没有任何影响,则可以忽略此通知。

警告(也许我看到的是Info-帖子作者的注释),这些是在您修理Critical时点亮的灯。 您会看到两个并排的警告标志(也许有一个“信息”链接-帖子作者的注释)。 他们可以通过Critical帮助您解决事件。 为什么尚不清楚SMS或字母中的CPU使用率过高。
没有意义的信息也很糟糕。 如果将它们配置为例外,那么您会非常喜欢Info。

警报设计的一般原则。 警报应显示原因。 太完美了 但这很难实现。 在这里,我们全职从事这项工作,并且取得了一定的成功。
每个人都在谈论成瘾的需要,自动魔术。 实际上,如果您没有收到您不感兴趣的东西的通知,则不会有太多。 在我的实践中,统计数据表明,在发生严重事件时,人们将以对角线的一百只灯泡的眼光注视着这一事件。 他会在那里找到合适的人,并且不会认为依赖关系已经隐藏了任何对我现在有帮助的灯泡。 实际上,这可行。 您需要做的就是清理不必要的警报。

(此处跳过了视频-帖子作者的注释)

最好将这些停机时间分类,以便您以后可以使用它们。 例如,得出组织结论。 您需要了解您为什么说谎。 我们建议分类/分为以下几类:
如果对它们进行分类,那么每个人都会很高兴。

短信已到。 我们在做什么 首先,我们要修理一切。 到目前为止,除了停机时间之外,对我们来说什么都不重要。 因为我们有动力少说谎。 然后,当事件关闭时,应该对监视系统关闭。 我们认为应该通过监视检查事件。 如果未配置监视,则足以确保问题已解决。 这必须被扭曲。 事件关闭后,它实际上并未关闭。 当您深入探究原因时,他会等待。 实际上,任何领导者首先都需要确保问题不再发生。 该问题没有再次发生,您需要深入了解原因。 弄清原因之后,我们就有了对它们进行分类的数据。 我们分析原因。 然后,当我们深入探究原因时,我们需要在将来做,以使事件不再发生:
- 将这样的逻辑写到后端需要两个人四分之一的时间。
- 需要放置更多副本。
. workflow N , .
? downtime. . , .

- , 90% - . . , . , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
问题:在什么时候确定阈值?谁在做这个?
答:您来找我们说:我们想问一些关于我们项目的批评。如果您现在每秒放10 5xx,那么一周前您会收到多少条通知。
问题:所有这些良好监视的负担是什么?
答:通常,它通常是不可见的。但是,如果解析50,000 RPS,它将是一个CPU的1%到10%。由于我们仅进行监视,因此我们优化了代理。我们评估代理商的表现。如果您没有监视服务器上的资源,则说明您做错了什么。应该始终有监视的资源。如果您不这样做,那么您将无所适从来管理您的项目。