让我们仔细研究一下面向协议的编程主题。 为了方便起见,将材料分为三个部分。
本材料是WWDC 2016演示文稿的评论翻译。 与“引擎盖下的东西”应该保留在那里的普遍看法相反,有时弄清楚那里发生的事情非常有用。 这将有助于正确使用该物品并将其用于预期目的。
本部分将解决面向对象编程中的关键问题以及POP如何解决它们。 一切都将以Swift语言的实际情况来考虑,细节将被视为协议的“引擎部分”。
OOP问题以及为什么我们需要POP
众所周知,在OOP中,有许多弱点可以“重载”程序执行。 考虑最明确和最常见的:
- 分配:堆栈还是堆?
- 参考计数:或多或少?
- 方法分配:静态还是动态?
1.1分配-堆栈
堆栈是一个相当简单和原始的数据结构。 我们可以放在堆栈的顶部(推动),我们可以从堆栈的顶部(弹出)取出。 简单的是,这就是我们所能做的。
为简单起见,让我们假设每个堆栈都有一个变量(堆栈指针)。 它用于跟踪堆栈的顶部并存储一个整数(Integer)。 因此,使用堆栈的操作速度等于将Integer重写为该变量的速度。
Push-放在堆栈顶部,增加堆栈指针;
弹出-减少堆栈指针。
值类型
让我们考虑一下使用结构(struct)在Swift中进行堆栈操作的原理。
在Swift中,值类型是结构(struct)和枚举(enum),引用类型是类(class)和函数/闭包(func)。 值类型存储在堆栈中,引用类型存储在堆中。
struct Point { var x, y: Double func draw() {...} } let point1 = Point(...)

- 我们将第一个结构放在堆栈上
- 复制第一个结构的内容
- 更改第二个结构的内存(第一个结构保持不变)
- 使用终止。 可用内存
1.2分配-堆
堆是树状的数据结构。 堆实现主题在这里不会受到影响,但是我们将尝试将其与堆栈进行比较。
为什么,如果可能的话,值得使用Stack而不是Heap? 原因如下:
- 参考计数
- 空闲内存管理及其寻找分配
- 重写内存以进行释放
所有这些只是使Heap正常工作的一小部分,与Stack相比,显然它要小得多。
例如,当我们需要堆栈上的可用内存时,我们只需获取堆栈指针的值并将其增加(因为堆栈中堆栈指针上方的所有内容都是可用内存)-O(1)是时间恒定的操作。
当我们在Heap上需要可用内存时,我们开始使用数据树结构中的适当搜索算法来搜索它-最佳情况下,我们有一个O(登录)操作,该操作在时间上不是恒定的,并取决于特定的实现。
实际上,堆要复杂得多:它的工作是由操作系统中其他许多机制提供的。
还要注意的是,在多线程模式下使用堆会大大加重这种情况,因为有必要确保不同线程的共享资源(内存)同步。 这可以通过使用锁(信号灯,自旋锁等)来实现。
参考类型
让我们看看使用类在Heap中Swift的工作方式。
class Point { var x, y: Double func draw() {...} } let point1 = Point(...)
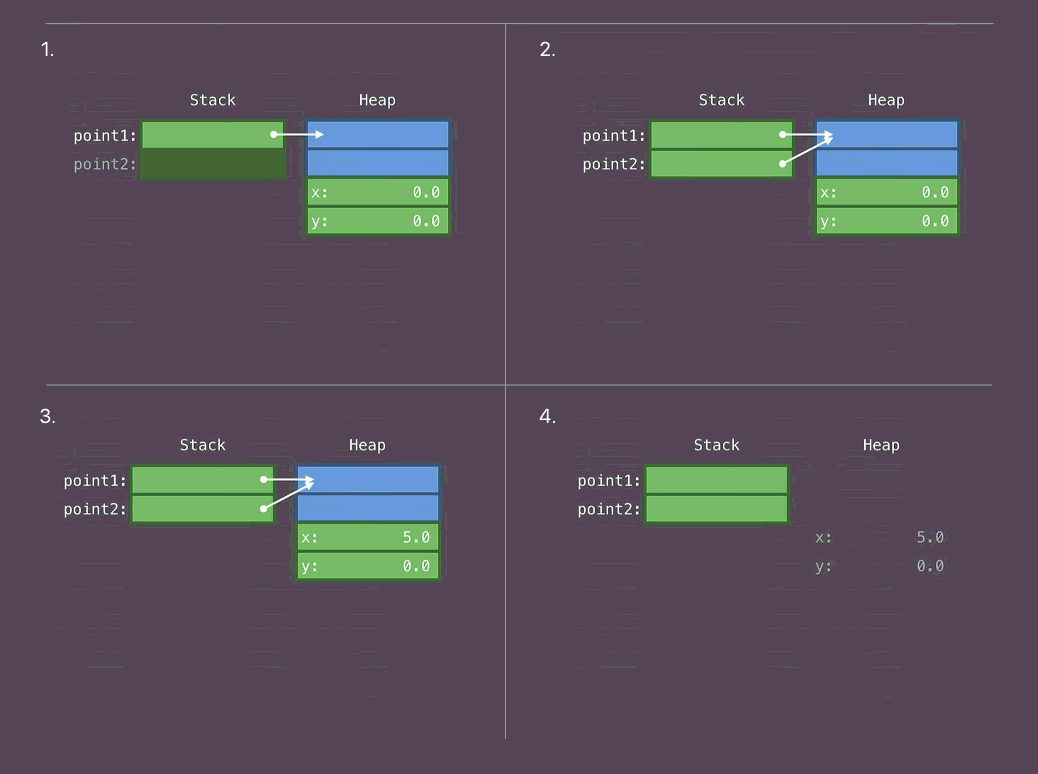
1.将班级主体放在堆上。 将指向此主体的指针放在堆栈上。
- 复制指向类主体的指针
- 我们改变一个阶级的身体
- 使用终止。 可用内存
1.3分配-一个小的“真实”示例
在某些情况下,选择堆栈不仅可以简化内存处理,而且可以提高代码质量。 考虑一个例子:
enum Color { case red, green, blue } enum Orientation { case left, right } enum Tail { case none, tail, bubble } var cache: [String: UIImage] = [] func makeBalloon(_ color: Color, _ orientation: Orientation, _ tail: Tail) -> UIImage { let key = "\(color):\(orientation):\(tail)" if let image = cache[key] { return image } ... }
如果缓存字典具有带有键key的值,则该函数将仅返回缓存的UIImage。
此代码的问题是:
最好不要使用String作为缓存中的键,因为String最终“可能是任何东西”。
字符串是写时复制结构,为了实现其动态性,它会将所有其Character-s存储在堆中。 因此,String是一种结构,并存储在Stack中,但其所有内容都存储在Heap中。
为了提供更改线的能力(删除线的一部分,向该线添加新线),这是必需的。 如果字符串的所有字符都存储在堆栈中,那么这样的操作将是不可能的。 例如,在C中,字符串是静态的,这意味着在运行时不能增加字符串的大小,因为所有内容都存储在Stack中。 有关Swift中的写时复制和更详细的行解析,请单击此处 。
解决方案:
使用非常明显的结构代替字符串:
struct Attributes: Hashable { var color: Color var orientation: Orientation var tail: Tail }
将字典更改为:
var cache: [Attributes: UIImage] = []
摆脱字符串
let key = Attributes(color: color, orientation: orientation, tail: tail)
在Attributes结构中,所有属性都存储在Stack中,因为枚举存储在Stack中。 这意味着此处没有隐式使用Heap,并且现在非常精确地定义了高速缓存字典的键,从而提高了此代码的安全性和清晰度。 我们还摆脱了对堆的隐式使用。
结论:堆栈比堆更容易,更快捷-大多数情况下的选择是显而易见的。
2.参考计数
为了什么
Swift应该知道何时可以在Heap上释放一块内存,例如由类或函数的实例占用。 这是通过链接计数机制实现的-托管在Heap上的每个实例(类或函数)都有一个变量,用于存储指向它的链接数。 当没有链接到实例时,Swift决定释放为其分配的一块内存。
应该注意的是,对于这种机制的“高质量”实施,与增加和减少堆栈指针相比,需要更多的资源。 这是由于以下事实:链接数的值可以从不同的线程增加(因为您可以从不同的线程引用类或函数)。 同样,不要忘记需要确保不同线程(自旋锁,信号灯等)的共享资源(链接数可变)同步。
堆栈:查找可用内存并释放已用内存-堆栈指针操作
堆:搜索可用内存并释放已用内存-树搜索算法和引用计数。
在Attributes结构中,所有属性都存储在Stack中,因为枚举存储在Stack中。 这意味着此处没有隐式使用Heap,并且现在非常精确地定义了高速缓存字典的键,从而提高了此代码的安全性和清晰度。 我们还摆脱了对堆的隐式使用。
伪代码
考虑一小段伪代码,以演示链接计数的工作原理:
class Point { var refCount: Int var x, y: Double func draw() {...} init(...) { ... self.refCount = 1 } } let point1 = Point(x: 0, y: 0) let point2 = point1 retain(point2)
结构
使用结构时,根本不需要诸如引用计数之类的机制:
- 结构未存储在堆上
- struct-分配时复制,因此没有参考
复制链接
同样,在赋值时复制struct和Swift中的其他任何值类型。 如果结构本身存储链接,则还将复制它们:
struct Label { let text: String let font: UIFont ... init() { ... text.refCount = 1 font.refCount = 1 } } let label = Label(text: "Hi", font: font) let label2 = label retain(label2.text._storage)
label和label2共享在Heap上托管的常见实例:
因此,如果该结构本身存储链接,则在复制此结构时,链接数将增加一倍,这在不必要的情况下会对程序的“轻松”产生负面影响。
再次是“真实的”示例:
struct Attachment { let fileUrl: URL
这种结构的问题在于:
- 3堆分配
- 因为String可以是任何字符串,所以安全性和代码清晰度会受到影响。
同时,uuid和mimeType是严格定义的东西:
uuid是格式为xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx的字符串
mimeType是类型/扩展名格式的字符串。
解决方案
let uuid: UUID
对于mimeType,枚举可以正常工作:
enum MimeType { init?(rawValue: String) { switch rawValue { case "image/jpeg": self = .jpeg case "image/png": self = .png case "image/gif": self = .gif default: return nil } } case jpeg, png, gif }
或更容易:
enum MimeType: String { case jpeg = "image/jpeg" case png = "image/png" case gif = "image/gif" }
并且不要忘记更改:
let mimeType: MimeType
3.1方法分派
在讨论此机制的实现之前,值得确定在这种情况下什么是“消息”和“方法”:
- 消息是我们发送给对象的名称。 参数仍然可以与名称一起发送。
circle.draw(in: origin)
消息是draw-方法的名称。 接收者对象是一个圆。 起源也是一个论点。
然后,方法调度是一种算法,该算法决定应为特定消息提供哪种方法。
更具体地说,关于Swift中的方法调度
由于我们可以从父类继承并覆盖其方法,因此Swift必须确切知道在特定情况下需要调用该方法的哪种实现。
class Parent { func me() { print("parent") } } class Child: Parent { override func me() { print("child") } }
创建几个实例并调用me方法:
let parent = Parent() let child = Child() parent.me()
一个相当明显和简单的例子。 如果:
let array: [Parent] = [Child(), Child(), Parent(), Child()] array.forEach { $0.me()
这并不是很明显,需要资源和某种机制来确定me方法的正确实现。 资源是处理器和RAM。 机制是方法调度。
换句话说,方法调度是程序确定要调用的方法实现的方式。
在代码中调用方法时,必须知道其实现。 如果她知道
在编译时,这就是静态调度。 如果在调用之前(在运行时,在执行代码时)确定实现,那么这就是动态调度。
3.2方法分派-静态分派
最佳,因为:
- 编译器知道将调用哪个代码块(方法实现)。 因此,他可以尽可能地优化此代码,并采用内联这样的机制。
- 同样,在执行代码时,程序将简单地执行编译器已知的该代码块。 将不会花费资源和时间来确定该方法的正确实现,这将加速程序的执行。
3.3方法分派-动态分派
不是最佳的,因为:
- 该方法的正确实现将在程序执行时确定,这需要资源和时间
- 没有编译器优化是不可能的
3.4方法分派-内联
提到了诸如内联的机制,但这是什么? 考虑一个例子:
struct Point { var x, y: Double func draw() {
- point.draw()方法和drawAPoint函数将通过“静态分派”处理,因为为编译器确定正确的实现没有困难(因为没有继承且无法重新定义)
- 由于编译器知道将要执行的操作,因此可以对其进行优化。 首先优化drawAPoint,只需将函数调用替换为其代码即可:
let point = Point(x: 0, y: 0) point.draw()
- 然后优化point.draw,因为该方法的实现也是众所周知的:
let point = Point(x: 0, y: 0)
我们创建了一个点,执行了draw方法的代码-编译器只是将必需的代码替换为这些函数,而不是调用它们。 在动态调度中,这将变得更加复杂。
3.5方法分派-基于继承的多态性
为什么需要动态调度? 没有它,就不可能定义被子类覆盖的方法。 多态是不可能的。 考虑一个例子:
class Drawable { func draw() {} } class Point: Drawable { var x, y: Double override func draw() { ... } } class Line: Drawable { var x1, y1, x2, y2: Double override func draw() { ... } } var drawables: [Drawable] for d in drawables { d.draw() }
- drawables数组可以包含Point和Line
- 从直观上讲,此处无法进行静态调度。 for循环中的d可以是Line,也可以是Point。 编译器无法确定这一点,并且每种类型都有其自己的draw实现
那么动态调度如何工作? 每个对象都有一个类型字段。 所以Point(...)。类型将等于Point,而Line(...)。类型将等于Line。 程序(静态)存储器中的某个位置还有一个表(虚拟表),其中每种类型都有一个列表及其方法实现。
在Objective-C中,类型字段称为isa字段。 它存在于每个Objective-C对象(NSObject)上。
类方法存储在虚拟表中,并且不了解自己。 为了在此方法中使用self,需要将其传递到其中(self)。
因此,编译器会将这段代码更改为:
class Point: Drawable { ... override func draw(_ self: Point) { ... } } class Line: Drawable { ... override func draw(_ self: Line) { ... } } var drawables: [Drawable] for d in drawables { vtable[d.type].draw(d) }
在执行代码时,您需要查看虚拟表,在其中找到类d,从结果列表中获取draw方法,并将其传递为类型为self的d对象。 对于简单的方法调用来说,这是一项体面的工作,但是必须确保多态性能够正常工作。 任何OOP语言都使用类似的机制。
方法分派-摘要
- 默认情况下,通过Dynamic Dispatch处理类方法。 但是,并非所有类方法都需要通过动态调度来处理。 如果该方法未被覆盖,则可以使用final关键字将其开头,然后编译器将知道该方法不能被覆盖,并将通过静态分派对其进行处理。
- 非类方法不能被覆盖(因为struct和enum不支持继承),并且可以通过静态分派来处理
OOP问题-摘要
有必要注意以下琐事:
- 创建实例时:它将位于何处?
- 使用此实例时:链接计数将如何工作?
- 调用方法时:如何处理?
如果我们为动力付出了代价却没有意识到并且不需要它,那么这将对正在实施的程序产生负面影响。
多态是非常重要和有用的事情。 目前,所有已知的是Swift中的多态性与类和引用类型直接相关。 反过来,我们说类又慢又重,结构又简单又容易。 通过结构可能实现多态吗? 面向协议的编程可以为这个问题提供答案。