现代数据中心和其中的设备的拓扑结构使我们不再只
对白盒监视感到满意。 随着时间的流逝,我需要一个工具,该工具将根据
Clos网络中任何位置的流量(数据平面)传输的实际情况,显示特定设备的性能。 几周前,在
Next Hop会议上,Yandex网络工程师Alexander Klimenko分享了他在解决此问题上的经验。
-我在Yandex网络的运营和开发部门工作,有时我不得不解决一些问题,而不是在叶子上绘制美丽的云彩或创造光明的未来。 人们来说有些东西对他们不起作用。 如果对此事进行监视,如果我们的值班工程师发现它不起作用,那么对我自己来说将更容易。 因此,这半小时将专门用于监视。

迟早,每个人都会想到监视的想法。 也就是说,起初您可以收集用户本身的吸引力,他们会敲打您,说有些事情对他们不利。 但是很显然,这样的系统不能很好地扩展。 如果您有多个交换机,如果您的网络足够大,那么使用此监视选项将无法走得太远。
所有人迟早都会得出结论,有必要从设备中收集一些数据。 这是第一步。 它可以是日志,SNMP上的各种数据,丢包,您可以根据LLDP构建拓扑等。这里有一个明显的减号-设备本身为您提供所有这些信息。 它可能什么也没说,欺骗了你等等。
监视开发的逻辑阶段是对主机进行监视。 可以说有一个小分支。 如果您很幸运-或不是很幸运-可以在一个供应商上建立网络,那么该供应商可以为您提供一些您自己的监视选项。 但是去年在Next Hop上,Dima Ershov
说我们的工厂是由两个基本的供应商创建的,我们负担不起这样的奢侈品。 或者我们可以,但只能部分解决。
最后,最后一个选择,每个人都可以通过网络的发展获得。 这是对最终主机的监视。 Yandex具有这种监视。 它称为Netmon。

幻灯片的底部
有一个链接,其中包含有关Netmon工作原理
的详细介绍 。 我将在一张幻灯片中确切地讲。 如果有人愿意,请阅读另一个Netmon会议上的演讲。
Netmon是几乎安装在网络上每个主机上的代理。 任务到达代理:将一些数据包发送到某个网络节点。 它们可以完全不同:UDP,TCP,ICMP。 它可以作为不同的绘画,即DSCP和目标。 源端口和目标端口也可以不同。
这些数据被汇总,上传到一个单独的存储中,在这里我们得到了如右图所示的切片。 切片可以更多聚合,也可以较少聚合,具体取决于我们希望看到的内容。 例如,据我所知,在这里,我们拥有所有数据中心连接的一部分,即我们所有数据中心之间的连接。 我们可以更深入地探讨问题-查看POD之间或一个数据中心建筑物内部的连通性; 甚至更深-机架之间的POD内部; 甚至更深-甚至在机架内。

这里可能出什么问题了? 对于那些没有看过去年的下一跳音乐的人来说,这是一个小题外话。
我们每个ToR使用了400吉比特,而在该工厂实施的第一刻,我们只包含了200吉比特,因为还有更重要的任务。 不管为什么 他们打开200,服务来了,说:为什么200? 我们要400! 开始将其打开。 碰巧,工厂的第二部分(包括我们在内)在卡的记忆中发生了某种婚姻。 结果,我们打开了工厂,看到了这张图片:

这个Netmon(红色方块)着火了。 我们了解一切都丢失了。 我们像荷马一样抓住我们的头,然后疯狂地推动。 还有什么要按,什么要关,我们不了解。 也就是说,Netmon向我们显示了问题的存在,但没有显示问题实际上在网络上的何处。

我们已经完成了我们需要完成的任务。 需要做什么? 确定网络上的哪个设备存在问题,然后自动或通过值班工程师等强制使该设备停止服务。
而且,初始条件使得我们具有相当规则的拓扑,即第二级自旋之间或花托之间没有奇怪的联系。 我们拥有大部分流量-TCP,有一个中心位置,我们已经听说过,服务器或多或少是集中管理的。 我们可以来到这个中心地点并合理地声明:伙计们,我们想要这样做,请这样做。
我们考虑了哪些选择?

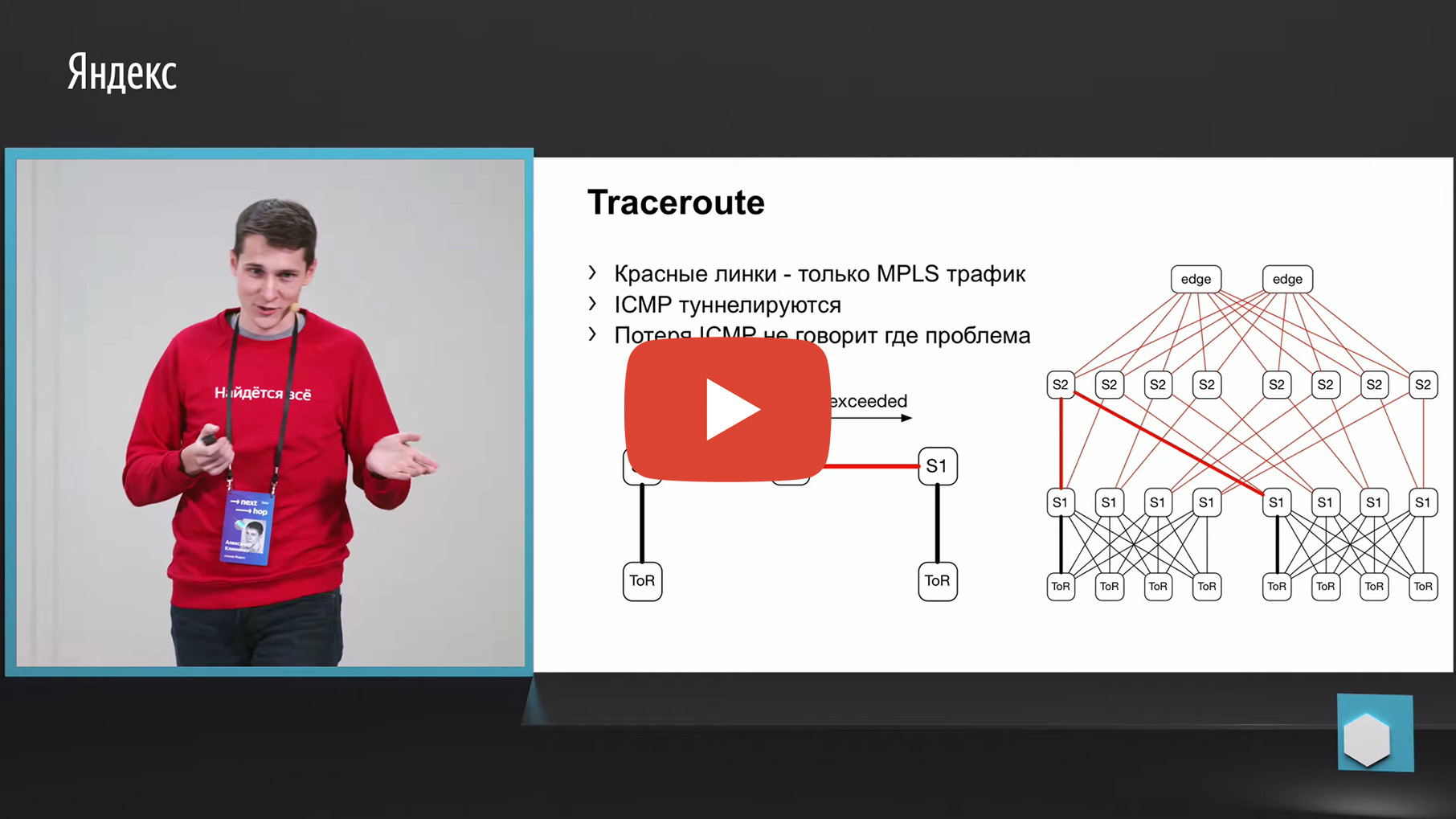
首先想到的是跟踪。 怎么了 因为同一Netmon将失败的源对和目标对卸载到单独的收集器中。 因此,我们可以将其取为5个元组,对其进行查看并使用相同的参数进行跟踪。 并汇总有关最大数量的跟踪通过哪个链路或通过哪个设备的数据。
但是不幸的是,我们的工厂使用了MPLS(现在我们正朝着与MPLS相反的方向发展,但是我们还需要以某种方式监视旧工厂,但实际上不要丢弃它们)。 我们在工厂中有MPLS,而MPLS和跟踪的问题在于它需要对TTL超出的ICMP消息进行隧道传输,这是跟踪的基础。 从入口到出口都丢失了这样一条消息,我们可能会失去监控。 也就是说,我们将不了解此消息是通过哪个节点传递的。 这不适合我们进行监视。
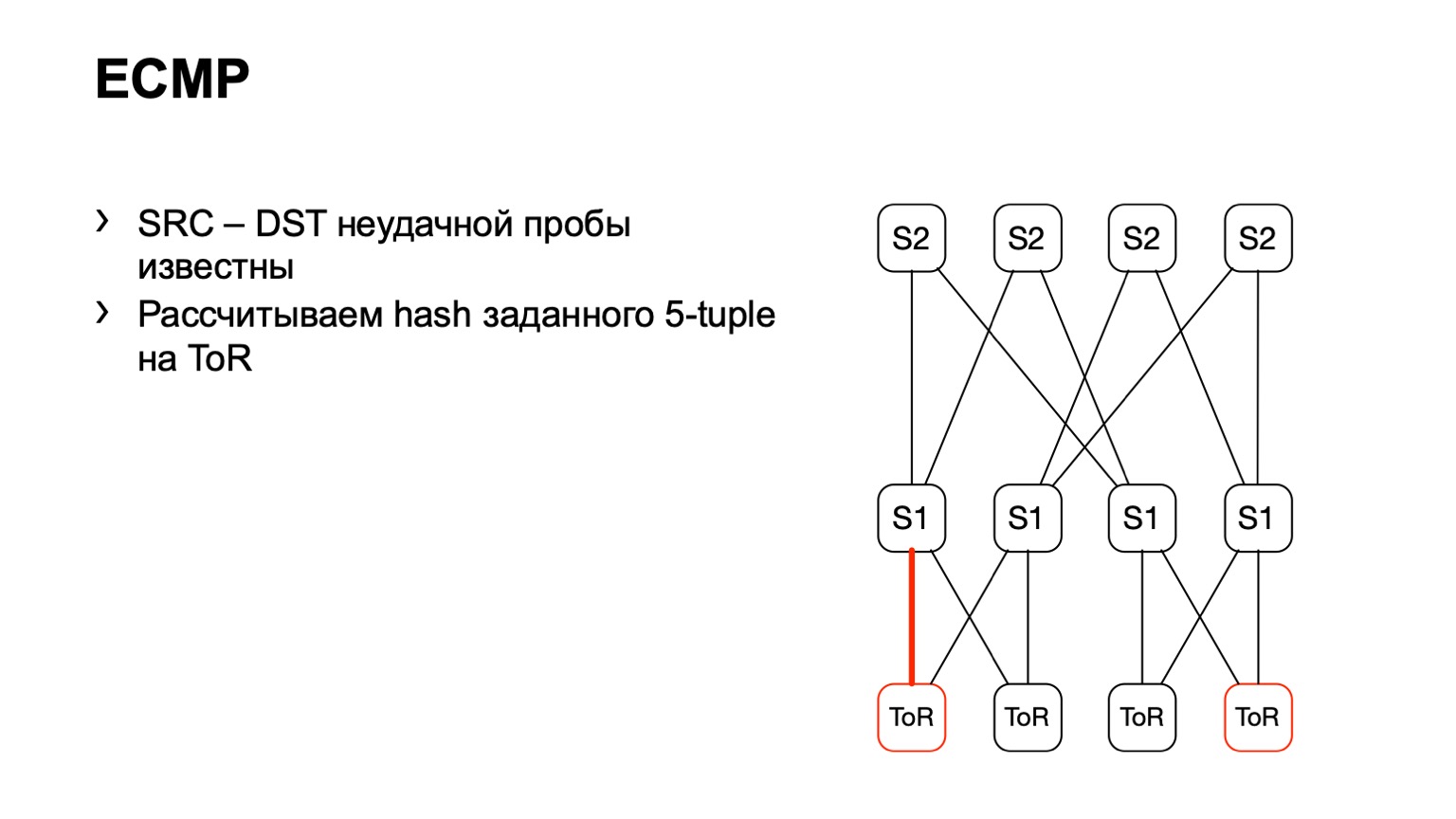
还有另一个与ECMP有关的选项。 除了source-port destination-port外,我们采用相同的源和目标对。 我们通过API或CLI来找到一块铁,将这块铁馈送到一块铁,然后得到输出接口。 许多设备都支持这种输出。
我们来到ToR,看到ToR选择了一个左或右链接。 在这种情况下,左链接朝着左S1。
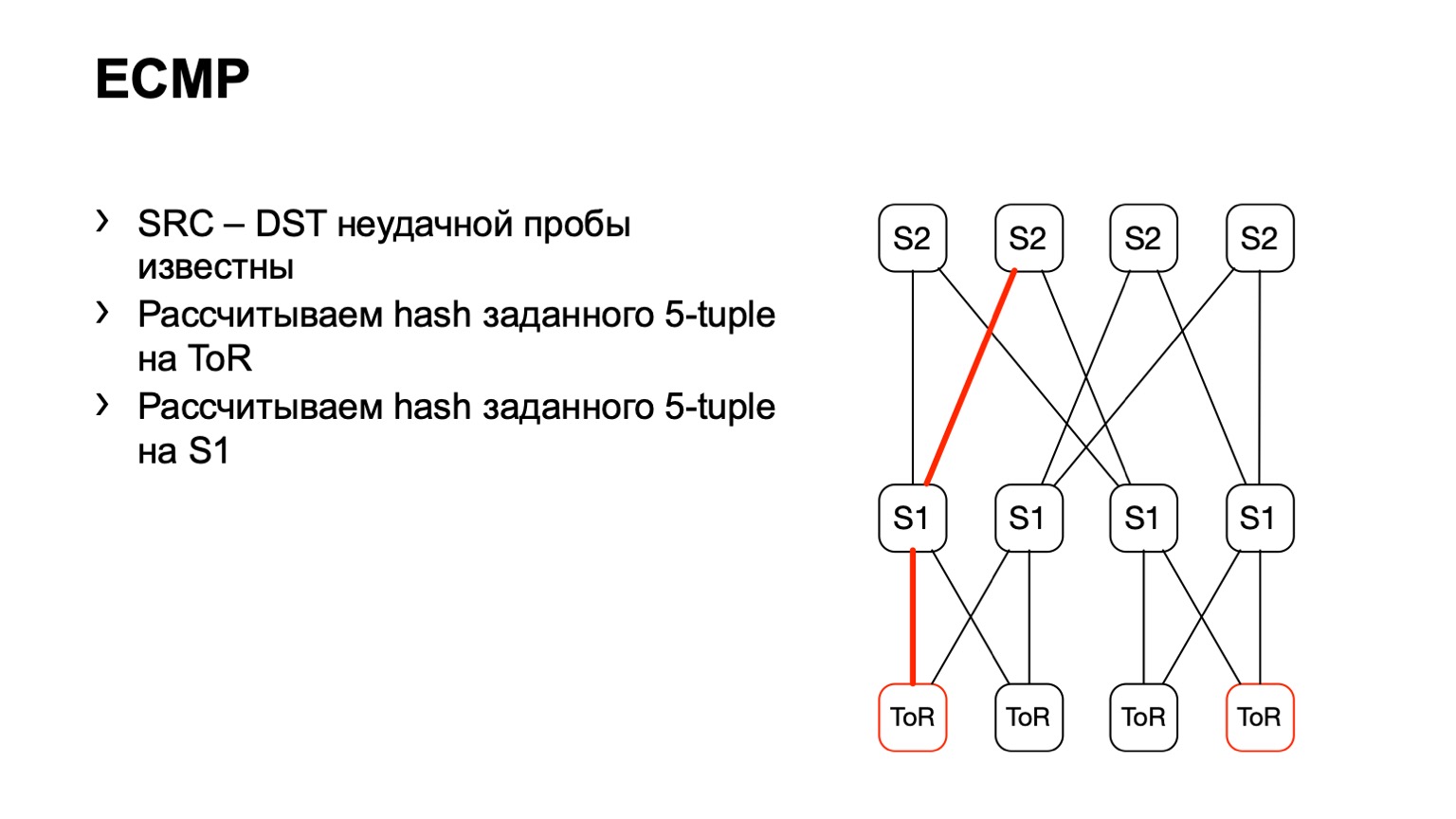
我们来到这个S1,对着S2看,这样就形成了一条准备好的路径。
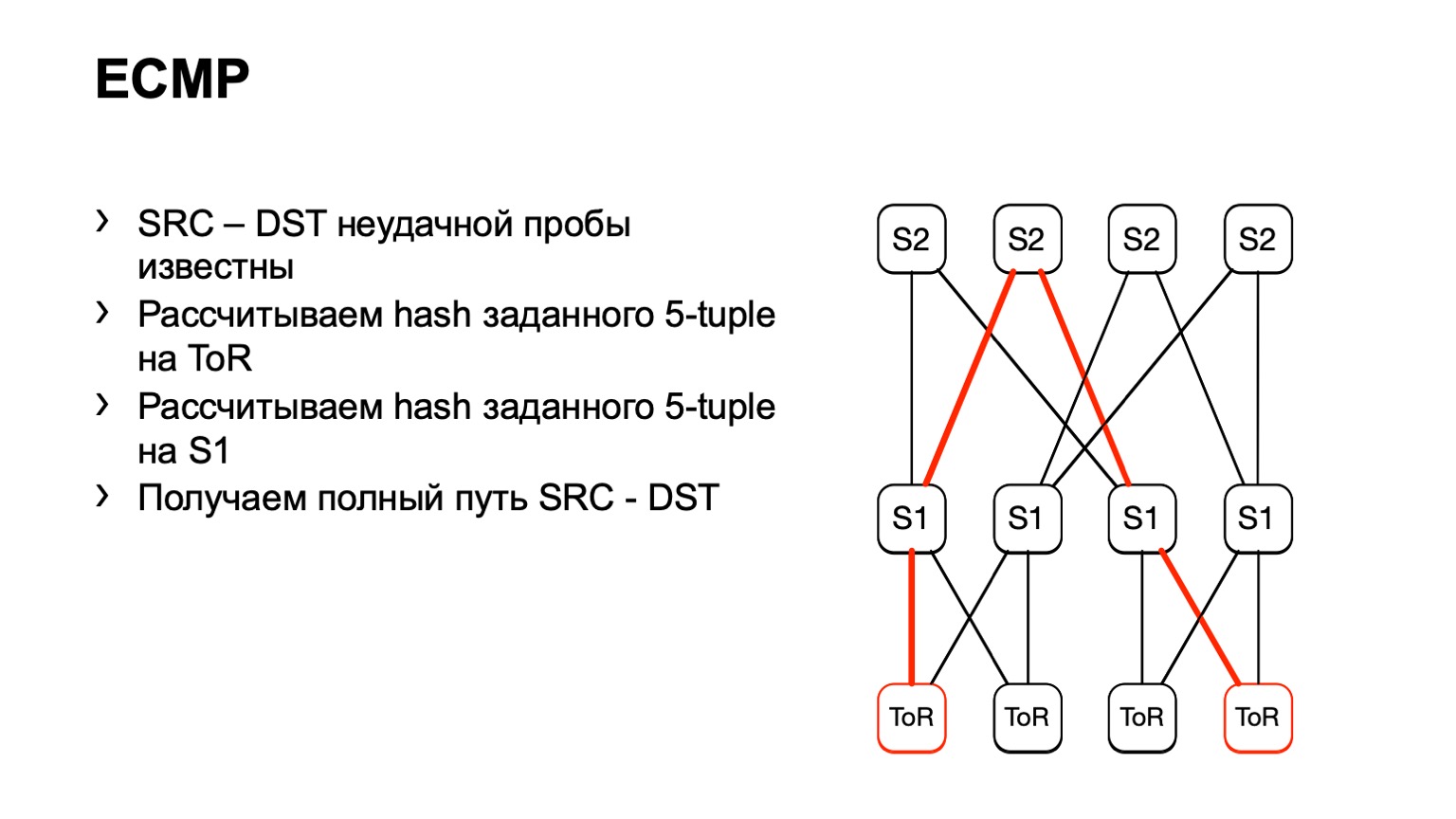
有一些缺点。 首先,并非所有设备都能正常接受我们提供给他们的这些输入数据。 这是由于我们拥有IPv6和MPLS,以及一些供应商根本没有实现这一点。 此解决方案的第二个缺点:我们依靠铁片再次告诉我们的内容,而不是查看主机上正在发生的事情。 最后,第三点-在您查看那里发生的情况时,网络上可能已经发生了变化,因此您的数据将不相关。

然后,我们遇到了Facebook进行的有趣的演示。 我们喜欢Facebook提出的想法,因此决定尝试做类似的事情。
主要思想是什么? 在主机上使用eBPF程序为TCP重新传输着色,然后计算此类数据包的数量。 不幸的是,我们无法像在Facebook上那样做,我们不得不发明自己的自行车。 我将尽力告诉您我们经历的痛苦和苦难的道路。
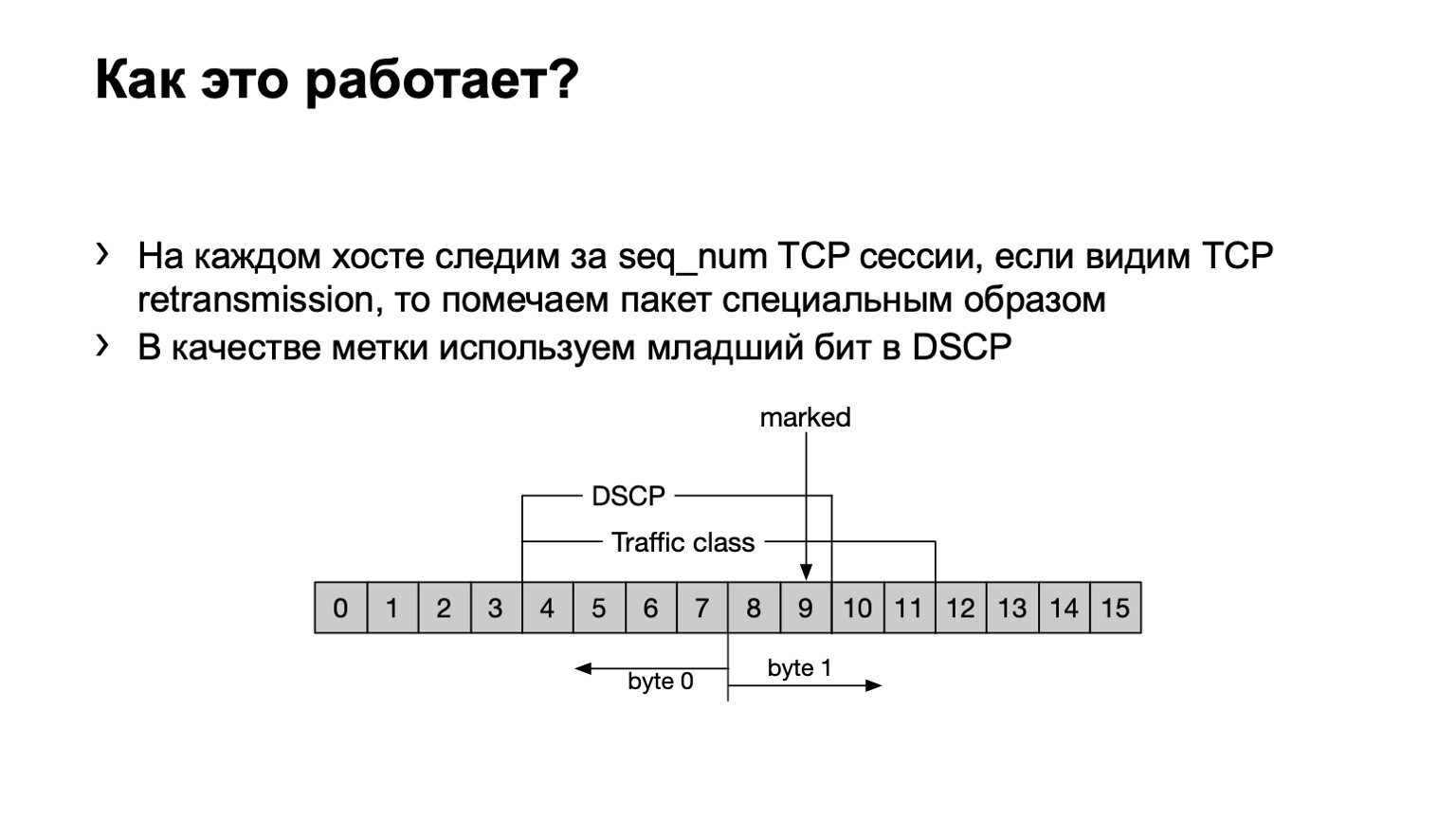
我们做了什么? 以防万一,我要指出的是,TCP重传是TCP消息,由于未确认其接收,因此会重复多次。 我们在主机上安装了一个eBPF程序,并检查此TCP消息是否被重新发送。 它很老套-按序列号。 如果在TCP会话中发送了相同的序列号,则将重新发送该序列号。
我们如何处理此类软件包? 我们将DSCP字段中的最后一位设置为1,以进一步计算整个对象。
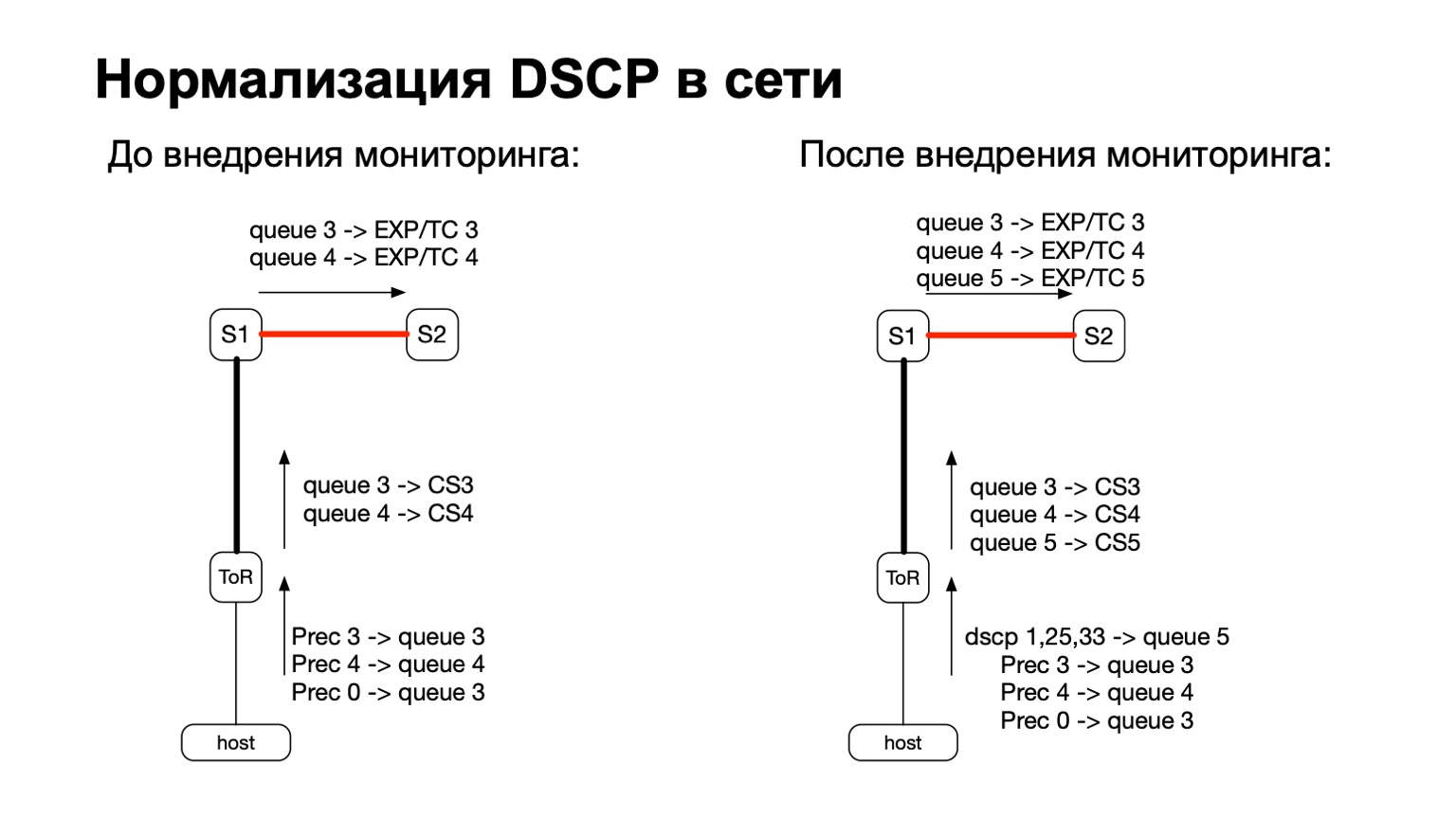
一般来说,DSCP与QoS有某种关系,对吗? 有了QoS,我们网络的历史就变得非常复杂和悠久。 我们在ToR交换机上监控某些策略。 在这些策略中,我们只是增加了对更多和这些有色数据包计数的需求。
因此,对于彩色数据包(请参阅:对于主机的TCP重传数据包),我们仅添加了另一个QoS队列。 这很容易做到,因为我们还有免费电话。 另外,这很方便,因为在工厂中IPv6和MPLS之间的过渡阶段,即在数据包从S1离开并离开我们工厂的MPLS部分的阶段,对于每个特定队列,在MPLS数据包报头中提取和重绘EXP / TC都很方便。 。
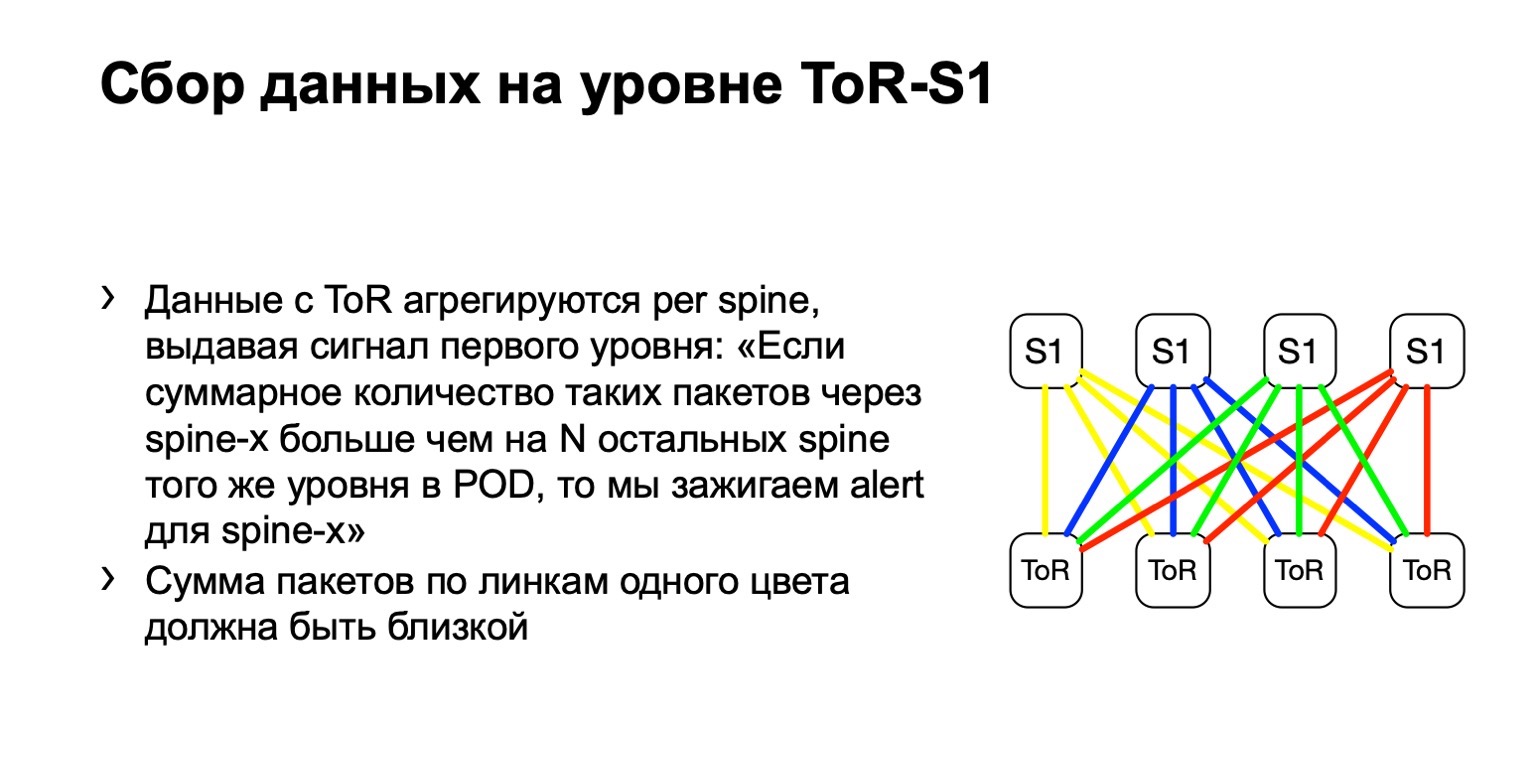
我们如何处理这些数据? 我们使用标准ACL过滤器,流量类别收集它们。 也就是说,它原则上适用于任何供应商。 我们可以在各处收集并计算此类软件包的数量。
接下来,我们查看POD上此类数据包的不均匀分布。 如图所示,其中有四个书脊。 如果黄色,蓝色,绿色和红色链接上的数据包数量相同,那么我们认为一切都差不多。 如果在某个时间点我们看到第一层的最右边的脊椎有所增加,我们就知道该设备吸引了重传,这是有问题的。 然后,我们尝试将其停用,或者至少将其租赁。 至少当我们在Netmon上看到问题时,我们会知道它们可能是由哪种设备引起的。
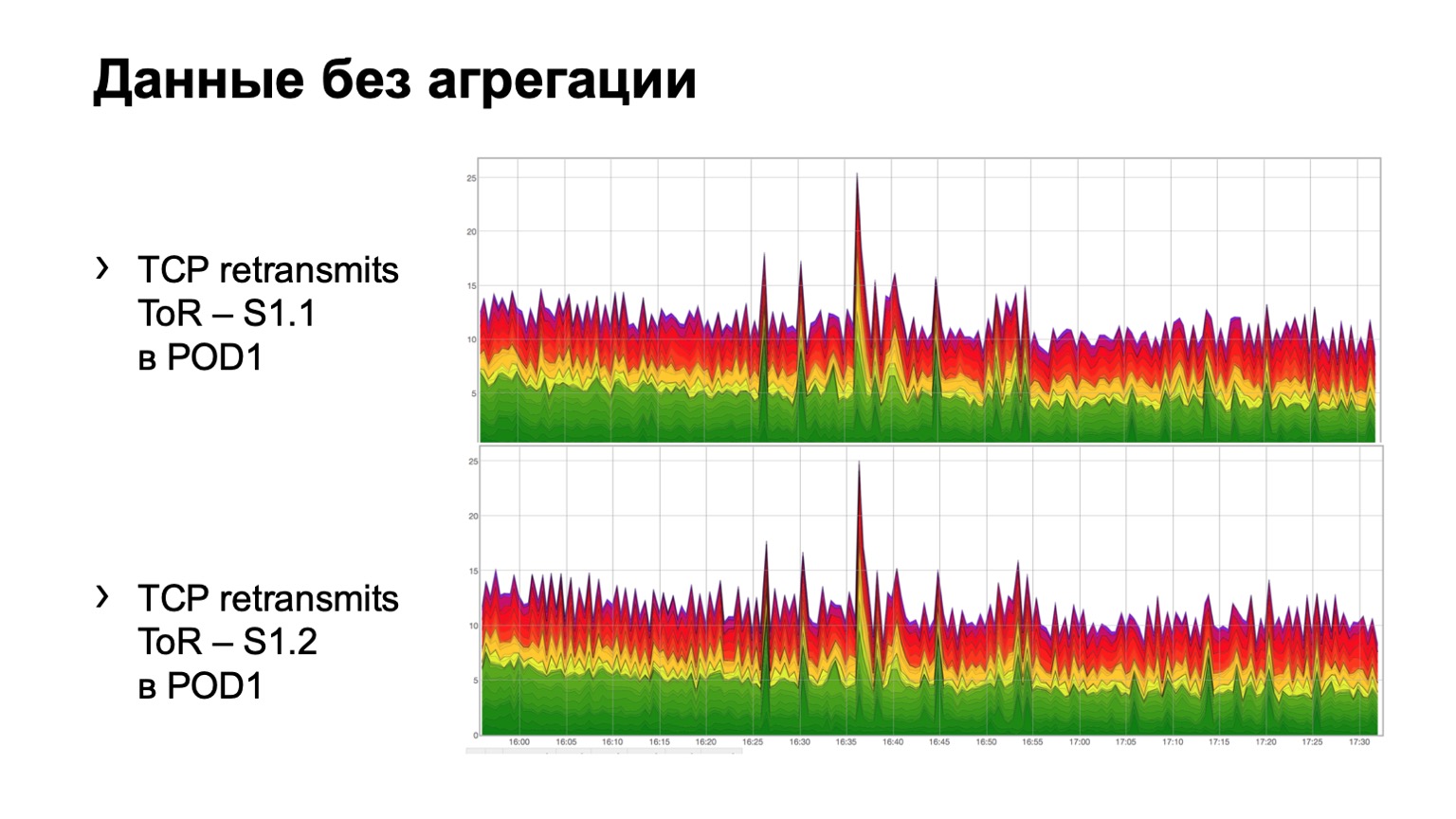
它如何看待简单的原始数据? 这是两个图表。 实际上,这些是通过ToR向第一级脊椎转发的图表。 在示例中,模块中有两个书脊。 上图是第一根脊柱的集合,下图是第二根脊柱。 以这种形式观看此消息不是很方便,因此我们添加了此信息的汇总。
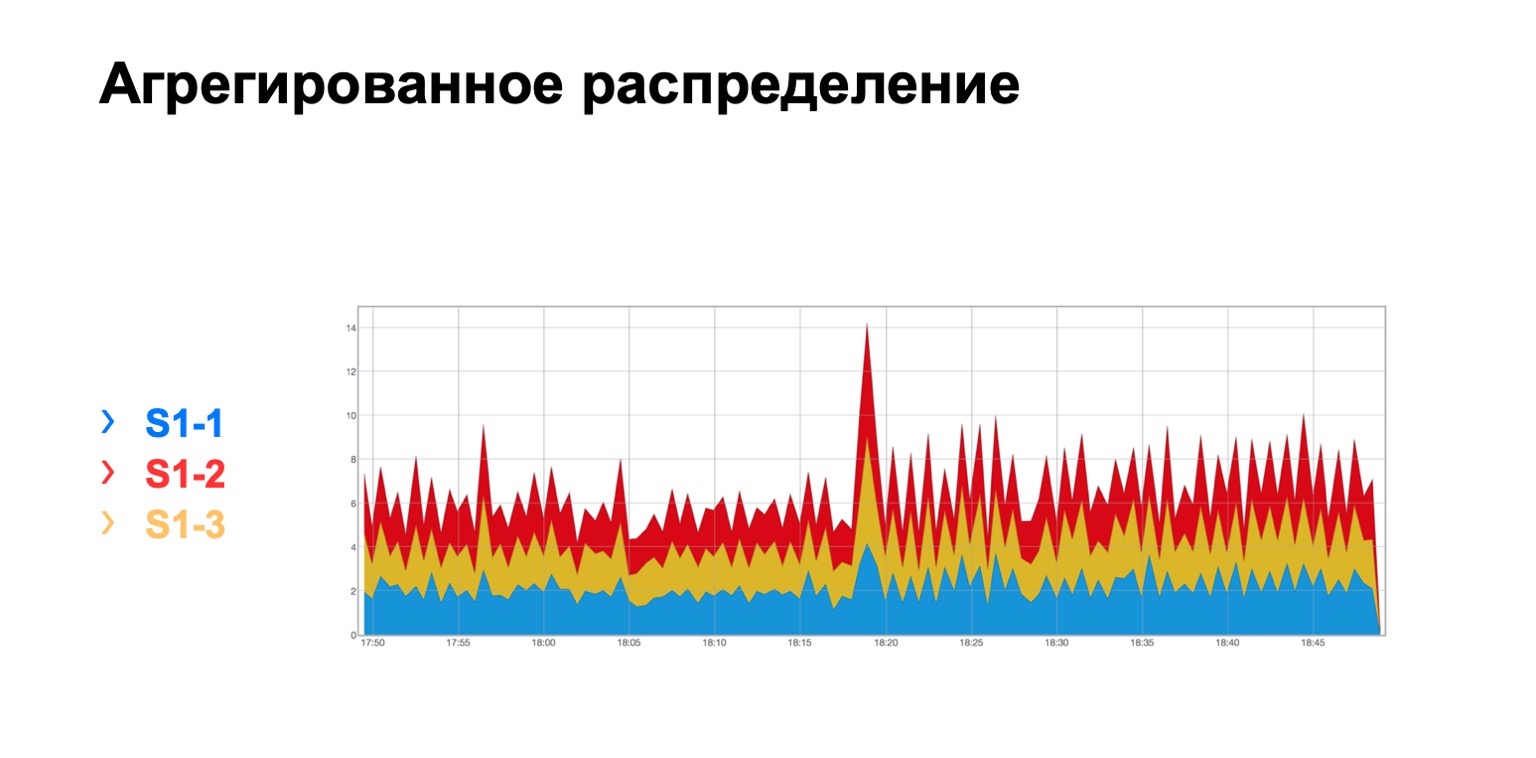
看起来像这样。 在一个模块中,由于某种原因,无论哪一个,三个棘刺都会出现,我们在这里看到这样的总重发分布到三个棘刺。 原则上,这是相当统一的。
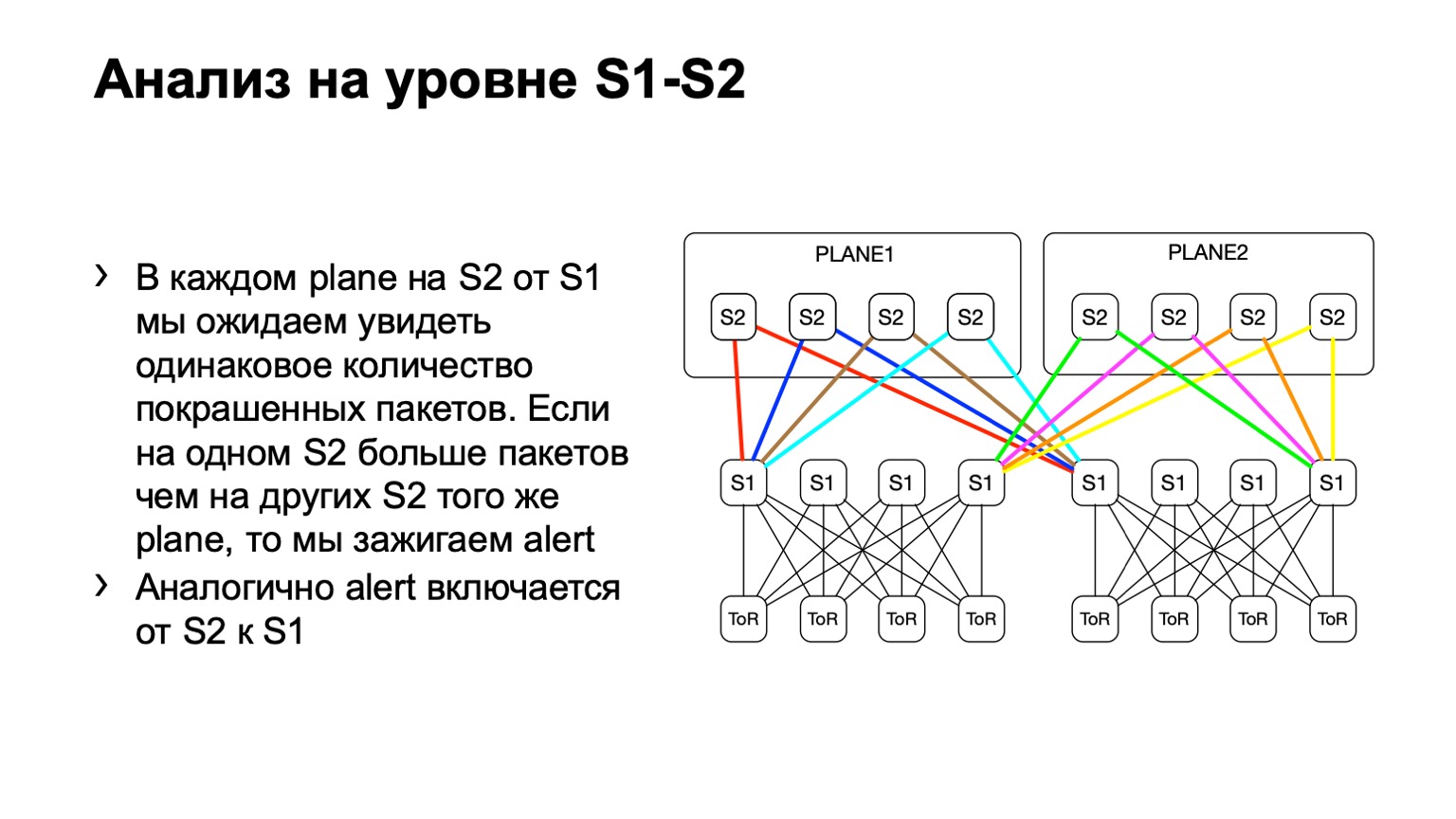
对于第二层脊椎,我们可能会有各种偏差,我们称其为“偏差”。 拓扑仍然保持规则,但是根据数据中心的不同,我们可能会或可能不会使用板状架构。 这里的要点是完全一样的。 一方面,我们应该有大致相同的彩色包装分布。
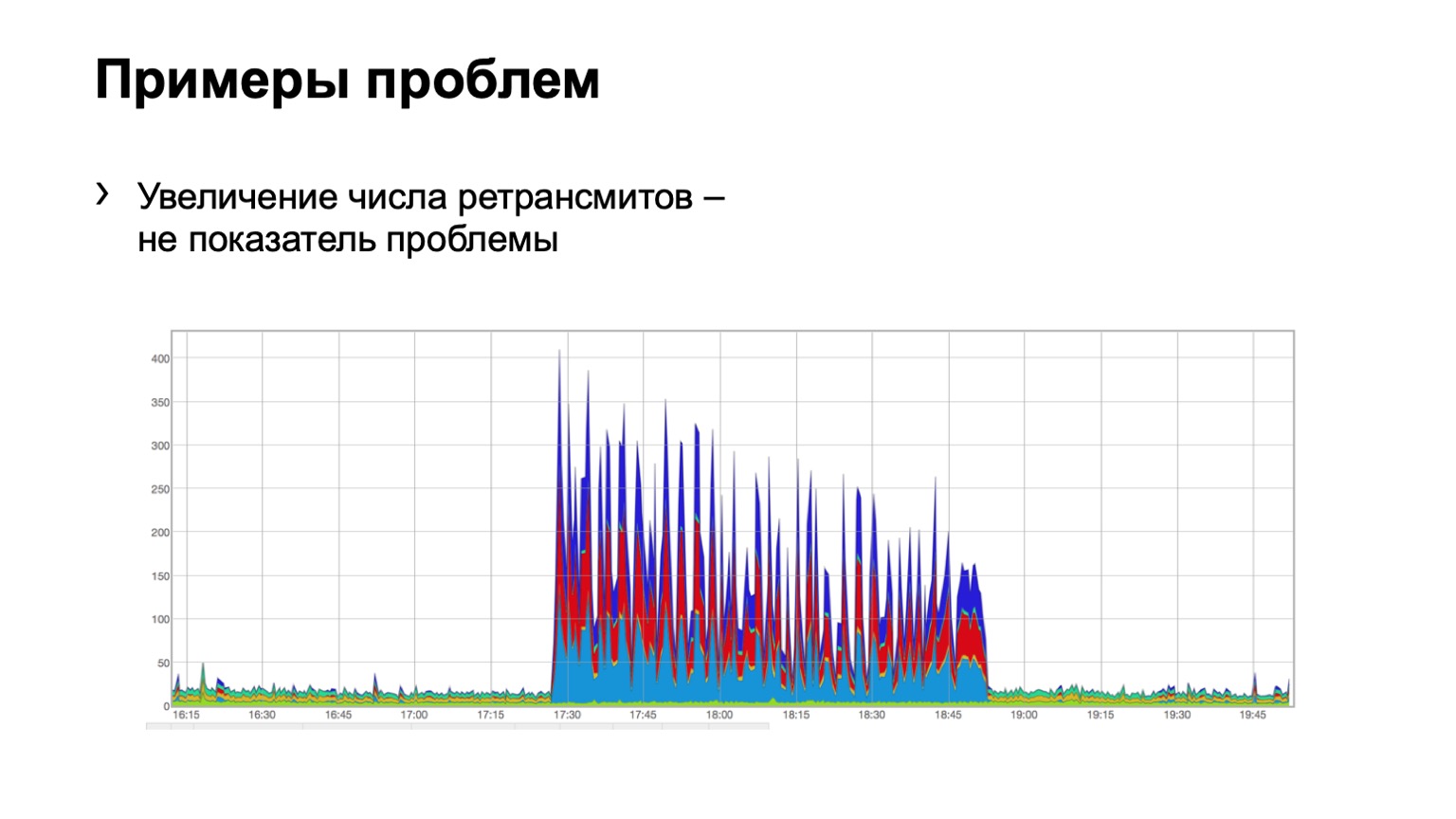
让我们看一些例子。 有人在这样的图表上看到问题吗? 这里有一个问题,但不是同时存在的。 是的,这是薛定ding的问题。 她为什么在那儿而不在那儿? 因为我们看到重传次数增加,所以很明显发生了一些事情。 但与此同时,我们看到这种增长是相当均匀的。 也就是说,三个脊柱的蓝色,红色,蓝色均匀分布在它们上面。 这是什么意思? 网络中存在某种问题,但与此级别的数据聚合无关。 她在别的地方。
也许有人关闭了防火墙上的端口,断开了某些群集的连接,即发生了某些事情。 但是,我们根本对那里的事物及其原因不感兴趣。 也就是说,我们甚至都不考虑这样的问题。
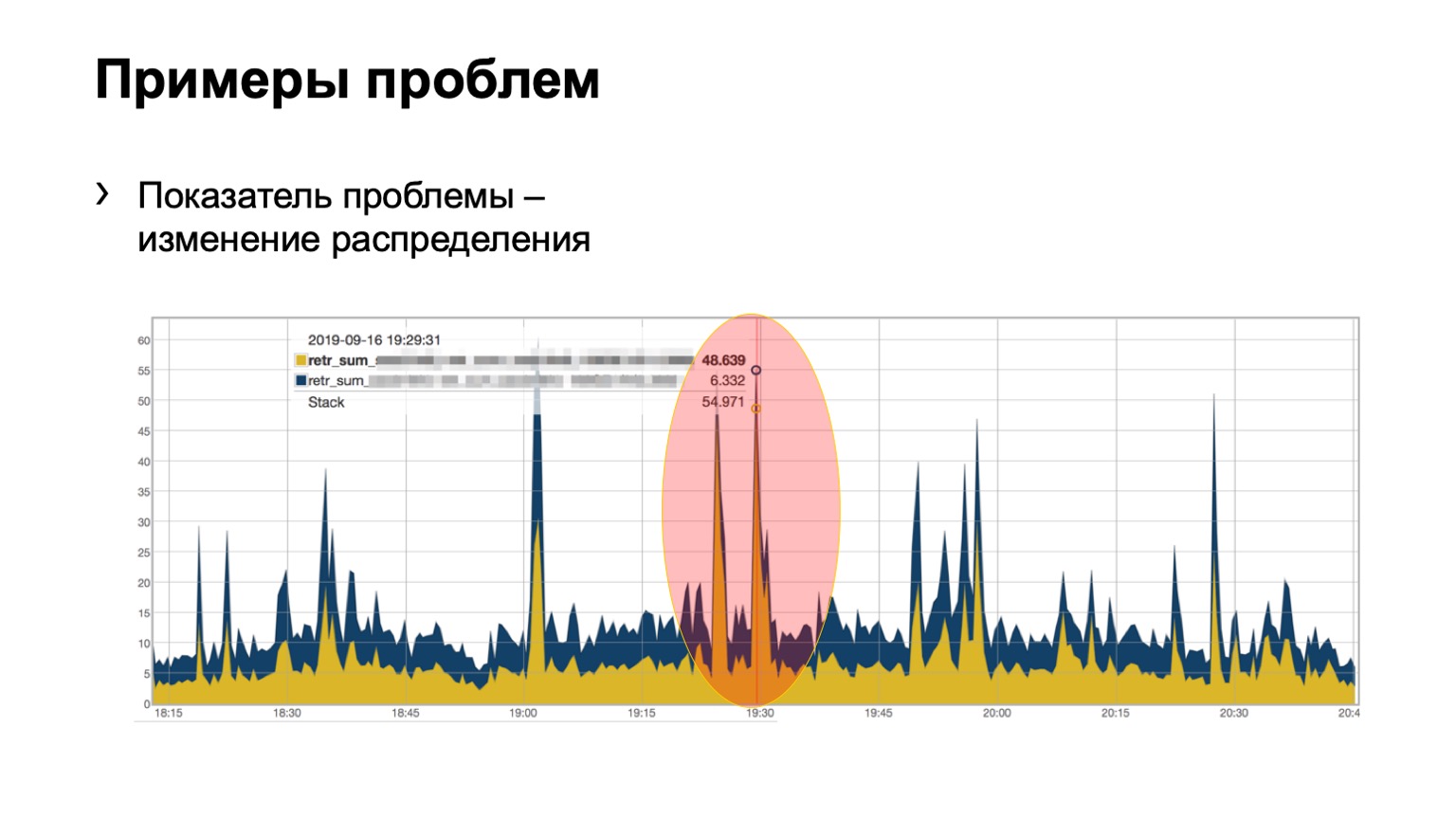
在这里,也许不是很清楚,但是问题很明显。 模块中有两个刺,一个上飞了46个彩绘小包,第二个上飞了一点。 我们了解到我们在网络上存在某种脊椎问题,因此我们必须对此采取一些措施。
为什么我首先谈论痛苦和苦难的道路? 因为这样的解决方案存在很多问题。 当然,主要问题是任何监控问题,这都是假阳性。 误报很多。 主要是由于我们使用DSCP,并且通常与QoS相关联。

我们发现其他人的包裹在我们的油漆中飞扬,并提醒我们进行监视。 也就是说,我们认为这是重传,而其他人则将其程序包放在那里,并且通常会破坏我们的形象。 自然,我们开始理解,发现了许多我们认为它起作用的地方,但实际上并没有按照我们的想法起作用。 例如,进入网络的流量似乎应该被重新粉刷,登机者上具有CS6和CS7类的流量不应进入我们的网络。 但是,有些地方存在缺陷,我们已经成功地处理了它们。
一些制造商以您在此类数据包的传出方向上计数计数器的形式给人带来了惊喜,而芯片的工作方式实际上是在处理传出访问列表时,它会重新包装自身的流量,从而减少了一半的芯片带宽。 每个芯片900吉比特,变成了原来的一半。
由于主机上的设置可以不同,因此我们进行了一些改进。 也就是说,某些主机可以发送更多的重传,某些主机可以发送更少的重发,大约两个,五个,所有这些都会提醒我们进行监视,所有这些都是误报。
首先,我们放弃了绘制每个TCP重新传输的想法。 我们意识到,原则上,我们不需要每次重传就可以了解问题所在。 我们开始只绘制SYN重传。 SYN是会话中的第一个数据包,这足以让我们接收信号。 我们也绘制SYN-ACL。
一样,这给了一些假阳性。 我们走得更远。 我们开始只绘制会话中的第一个TCP SYN重传。 也就是说,实际上已经发送了几个,我们每个都绘画了,只有一个开始被绘画。 因此,我们来到了现在的状态。
总体而言,有Netmon,主机上的代理为会话中的第一个SYN重传着色,并且我们在网络中几乎每个链路的每个设备上对这些重传进行计数。

但是用你的眼睛看我以前显示的照片不是很方便。 也就是说,您不能将其出售给值班人员,因为在每个部分中,您都必须用肉眼对其进行评估。 我们想到了我想发出警报的事实。 我要点亮:这样的设备是个问题; 另一个设备有问题。
让我们回想一下一些数学统计数据。 发出警报的想法是,每个设备本质上都是一个篮子。 我们有四个设备成功的概率和失败的概率。 重传进入篮的概率(即成功)为1/4。 结果是二项分布。
在这里发出警报有什么困难? 我们不能使阈值保持不变这一事实,我们不能说:如果十个重传到达一个设备,而九个重传到另一设备,那么就没有问题。 如果是十点和五点,那就有问题了。 因为如果将其缩放到一千个PPS,那么这些数据将不再相关。 不同设备之间的1000 PPS和800 PPS绝对是一个问题。
我们无法在PPS或字节中设置静态阈值,也无法将其设置为百分比-它们存在相同的问题。 因此,我们需要一种解决方案,使此阈值或多或少是动态的,具体取决于数据包的数量。
二项式分布的魅力在于,随着PPS的增加,它趋向于正态,对于正态分布,我们已经可以计算出期望值,方差并计算出置信区间。 我们的置信区间为3NPQ,即它取决于通过设备的数据包数量。 结果,我们有了一个动态移位阈值。
这就是我们的信号在图片中的外观。 如果某个设备从发行版中剔除,那么我们会在其上标记一个标志-它有问题。

除了打击误报的斗争之外,我们还想在哪里进一步发展?在这里我们还想改善什么? 首先,我们很想知道问题发生时发生了什么? 为此,我们在代理中有一个这样的选项-Debug。 我们可以将重传的数据(即5元组的数据包)确切地上传到单独的收集器中,然后查看它。 但这给主机带来了一定的负担,因此有时我们被禁止这样做。 我们要固定ERSPAN并将此类软件包从硬件本身卸载到收集器上,因为没有人禁止我们在硬件上这样做。
Dima Afanasyev
告诉我们我们将如何发展工厂,重点之一就是从MPLS工厂过渡到仅IPv6。 这给了我们什么? MPLS具有三个用于QoS标记的位。 在IPv6中,至少六个。 现在,我们的网络中实际上只使用了三位。 就是说,实际上我们还有3位可以放入主机的任何信息。
例如,现在我们只绘制会话中的第一个SYN重传。 例如,如果数据包到达外部网络,我们就可以为第二位着色。 我们可以重新传输,即突出显示另一个信号,然后我们将分别考虑。
此外,当我们在某个特定位置完成DCI时,过渡到使用边缘吊舱进行设计的做法威胁着我们,在此位置我们可以更精确地控制diffserv域。 就是说,重新粉刷并用涂料做一些事情以消除误报。
结果,进行上述所有操作都非常痛苦但有趣。 没什么好担心的。 , , , . , , . , . — , . , .