自MIT宣布发布高性能通用语言Julia以来,已经过去了一年多的时间。 从那时起,该语言就开始流行起来:它已在1,500多家大学中使用 (在某些国家被作为第一门教学语言使用),其应用领域涵盖了从医学诊断和太空任务计划到紧迫的问题,例如优化校车交通 。
不难猜测,许多项目的主要活动领域之一是机器学习,为此Julia提供了许多强大的工具 ,并且最近发布了一个相当有趣的项目- 通用概率编程系统“ GEN” 。
顾名思义,今天我们将关注Flux软件包,它提供了神经网络的所有功能。 我们将尝试从处理和研究图像集到经过训练的神经网络,以获得完整的分类器!
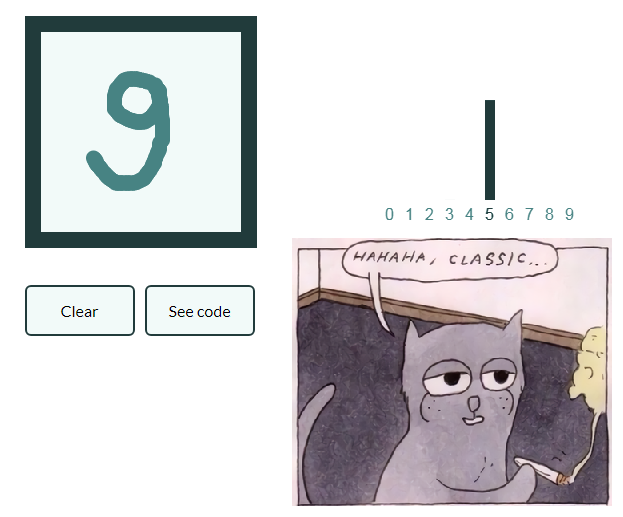
安装方式
从官方站点下载分发工具包,然后在计算机上安装Julia解释器( REPL )。
为了使程序包管理器正常工作, Windows 7 / Windows Server 2012的用户还必须安装:
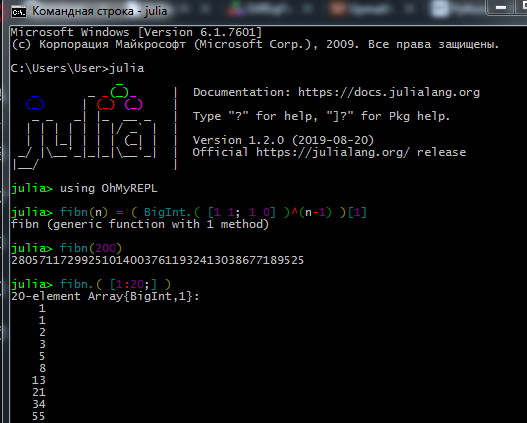
在REPL中工作的过程如下所示:
真正的数据说学家和机器语言学家喜欢Jupyter 。 在这里,您可以查看安装情况,并找到俄语独立作业的互动课程,以进行独立学习(指向原始教程的链接和该语言的指南)。
在这里,您可以了解如何使用Jupyter Notebook。
如果安装有问题- 无法建立连接-检查您的访问权限(您是否有写C:\文件夹的限制,以admin身份登录或以管理员模式启动Julia),如果使用代理,请确保不仅为浏览器配置了该代理
- 有些软件包在文件路径中不喜欢西里尔字母,因此由于俄语中的用户名,我遇到了很多问题
- 如果Interact软件包不显示结果,则可能是WebIO安装不正确,可以修复此问题。
- 为了使某些软件包在Windows上正常工作,必须在环境变量中输入Julia和Jupyter的路径。
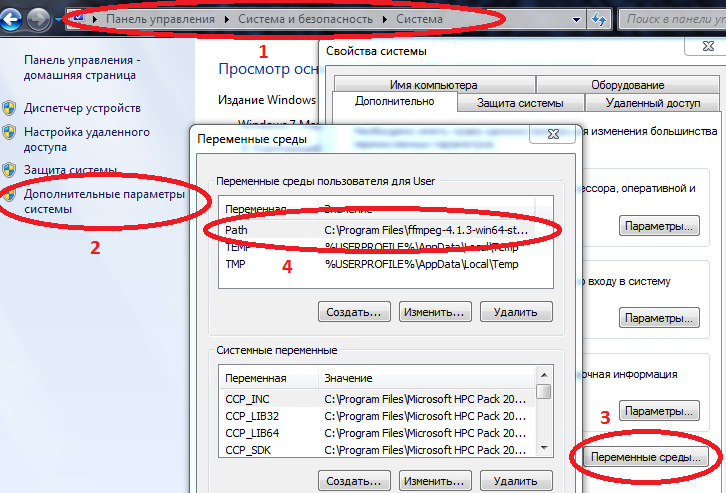
计算机/系统属性/高级系统参数/环境变量/路径 (如果未创建,则创建)并将路径添加到julia.exe
示例C:\ Users \ User \ AppData \ Local \ Julia-1.2.0 \ bin
如果Path已经有值,则用分号将它们分开。
现在,如果您将julia驱动到命令控制台( cmd ),解释器将启动。
安装完所需的一切后,您可以立即下载所需的软件包。 在REPL或Jupyter中输入命令
代号 using Pkg pkgs = ["Plots", "TextParse", "CSV", "DataFrames", "ImageMagick", "Images", "Interact", "Flux"] for p in pkgs Pkg.add(p) end for p in pkgs Pkg.build(p) end
学习了该语言的基础知识(使用数组,创建函数,下载程序包,绘制图表)之后,您可以继续阅读后续材料。
数据加载与处理
收集和组织数据是另一种艺术。 关于Julia,网络上有很多过时的资料,但是首先您可以尝试上面的教程 ,并且要进行更彻底的研究,请阅读《 Julia的数据科学》 (在公共领域)
今天,也许,我们将使用已经准备好的数据:来自大量不同角度的大量水果照片的数据集 -谁想要新鲜水果?


实际上这是任务-我们将教神经网络区分苹果和香蕉!
首先,上传一些测试图像:
using Images fnames = [ "data/10_100.jpg", "data/107_100.jpg", "data/yellow_apple_2.jpg", "data/8_100.jpg", "data/104_100.jpg", "data/3_100.jpg" ]

图片中的对象之间有何不同? 首先是形式,其次是颜色,然后是纹理和其他属性。 图像分析本身就是一个有趣的话题,不仅可以通过神经元进行分类,而且还可以通过小波进行分类 。 我们将从最简单的符号-颜色开始。
如您所知,图像以阵列的形式存储在计算机内存中,在我们的例子中,这些矩阵是矩阵,每个单元包含三个数字,表示图像每个像素中红色,绿色和蓝色的数量。 让我们看看这些图像中每种颜色的平均数量:
using Statistics: mean M1 = [ mean(float.(c.(img))) for c = [red,green,blue], img = fruits ] 3×6 Array{Float32,2}: 0.570278 0.652852 0.977111 0.835252 0.903998 0.842564 0.338118 0.468729 0.950773 0.806882 0.880692 0.755442 0.322406 0.379424 0.835212 0.707626 0.799643 0.761916
我们仔细看看第一行-麻烦您吗? 黄色的苹果和香蕉比布雷本品种的苹果要红! 怎么这样?! 来吧,补个酸味矿山,也许是小学生正在阅读本教程,或者是芭蕾舞和拖拉机学院的年轻学生。 因此,我们将努力避免遗漏。 事实是每张图片的背景都是白色,并且以RGB表示法由值(1,1,1)表示。 而且,由于3个破折号图像中还有6个背景,加上香蕉的颜色和黄色的苹果也包含红色,因此可以看出前两张照片都变成了红色。 为了清楚起见,我们将图像分为基本颜色:
function tweaking(img) R = colorview( RGB, red.(img),zeroarray,zeroarray ) G = colorview( RGB, zeroarray,green.(img),zeroarray ) B = colorview( RGB, zeroarray,zeroarray, blue.(img) ) [R; G; B] end tweaking( hcat(fruits...) )

您听说过神秘的单词“ basis”吗? 因此,可以说这些图像以RGB为基础进行布局。 越黑-某种颜色就越少,而且正如我们所期望的那样,背景及其丰富程度使得平均值计算很嘈杂。 删除它。
function remove_background(img) mtrx = copy( channelview(img) ) for i = 1:size(mtrx, 2), j = 1:size(mtrx, 3) if reduce(&, mtrx[:,i,j] .> [0.8, 0.8, 0.8])

M3 = [ mean(float.(c.(img))) for c = [red,green,blue], img = greyfruits ] 3×6 Array{Float32,2}: 0.451008 0.532696 0.578967 0.527727 0.52849 0.500276 0.218805 0.348609 0.552679 0.499192 0.505136 0.412946 0.203528 0.260142 0.439354 0.400631 0.424784 0.419291
每个物体所占面积的差异仍在影响,但总的来说,可以得出结论,香蕉是绿色( 和蓝色 )苹果。 这将是评估标准,即-一个标志。 现在,让我们看一下其余的图片:
pth = "C:\\Users\\User\\Desktop\\Banana"
对于每幅图像,我们中和背景的影响,找到每种颜色的平均数量,同时记住图像尺寸...
dataz = [] for fname in fnames img_i = load("$pth\\$fname") gbimg = remove_background(img_i) colorz = [ mean(c.(gbimg)) for c = [red,green,blue] ] inform = [size(gbimg, 1) size(gbimg, 2) colorz' ] push!(dataz, inform) end dataz
...然后您可以将我们的数据安排在便于工作的结构中-数据框:
using DataFrames, CSV banans = DataFrame( vcat(dataz...), [:height, :width, :red, :green, :blue] ) CSV.write("data/bananas.csv", banans)
apples = CSV.read("data/Apple_Braeburn.csv")
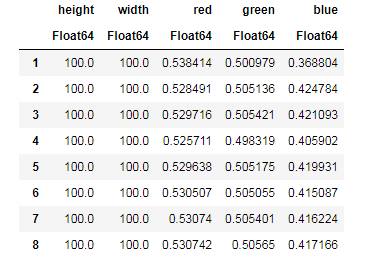
Desc = describe(apples, :all)
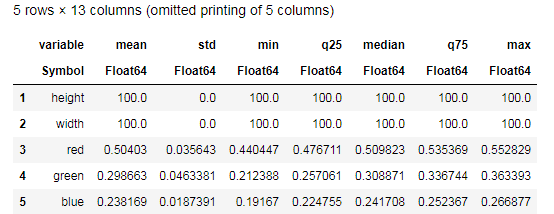
尝试理解describe()函数提供的数据,并与类似的香蕉表进行比较。 那么,没有图形可以进行什么样的数据分析?
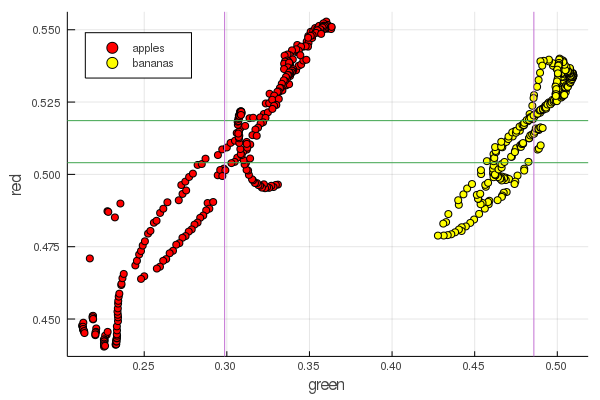
function plot2features(clr) x_apples = apples[:, :green] x_banans = banans[:, :green] y_apples = apples[:, clr] y_banans = banans[:, clr] scatter(x_apples, y_apples, lab = "apples", colour = :red) scatter!(x_banans, y_banans, lab = "bananas", legend = :topleft, colour = :yellow) hline!([mean(y_apples), mean(y_banans) ], lab = "" ) vline!([mean(x_apples), mean(x_banans) ], lab = "" ) xaxis!("green") yaxis!("$clr") end plot2features(:red)
plot2features(:blue)
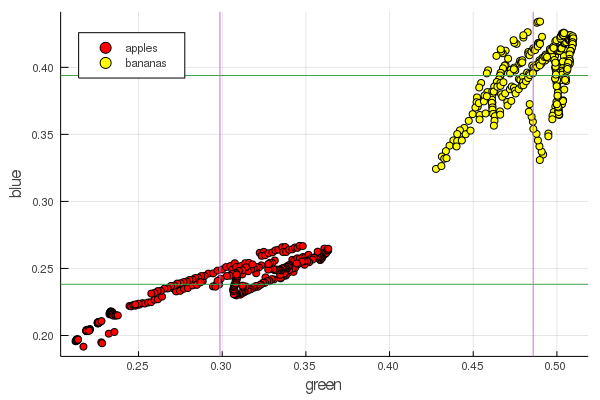
香蕉中段红色的价值与苹果中段非常接近。 但是在第二张图表上,立即通过两种颜色特征更清楚地追溯了水果的分离。 可以通过正确的重新归一化来改善分离,例如,我们的绿色值从0.2变为0.55,并且如果执行转换,
x′i= fracxi− min(x) max(x)− min(x)
然后我们将数据重新缩放为[0,1],这将增加这些之间的差距 堆 点簇。
感知器
分类任务包括定义模型和选择参数,针对这些参数,各种数据将唯一地接收对它们属于特定类别的评估。 简而言之,我们需要引入某个函数并设置其参数,以便将我们的苹果与香蕉分开。
为此目的,最著名和最受欢迎的模型是1940年代初开发的McCulloch-Pitts人工神经元。 随后,弗兰克·罗森布拉特(Frank Rosenblatt)提出了训练有素的神经网络-感知器。 不难找到关于神经网络的全面解释,包括在此资源上(例如,针对初学者 的神经网络,在图像识别中使用神经网络 , 神经网络,基本操作原理,种类和拓扑结构 )
选择S型作为激活函数并根据其输出设置分类对象(水果)的输出
sigma(x;w,b):= frac11+ exp(−wx+b)
x= mathrm数据
sigma(x;w,b)\大约0\暗含 mathrmapple
sigma(x;w,b)\大约1\暗含 mathrm香蕉
选择这样的参数 W 和 b 这样,接收到的数据的S形输出值便与上述符号相对应
using Interact sigmo(x,w,b) = 1 / (1 + exp(-w*x+b)) r_apples, g_apples, b_apples = apples[:, :red], apples[:, :green], apples[:, :blue] r_banans, g_banans, b_banans = banans[:, :red], banans[:, :green], banans[:, :blue]; @manipulate for w in 10:1:60, b in -5:1:25 plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(g_apples[1:5], zeros(10), label="Apple", colour = :red) scatter!(g_banans[1:5], ones(10), label="Banana", colour = :yellow) end
foon(x) = sigmo(x,60,24) plot(foon, 0, 1, label="Model", legend = :topleft, lw=3) scatter!(foon, g_apples, label="Apple", colour = :red) scatter!(foon, g_banans, label="Banana", colour = :yellow) xaxis!("green")
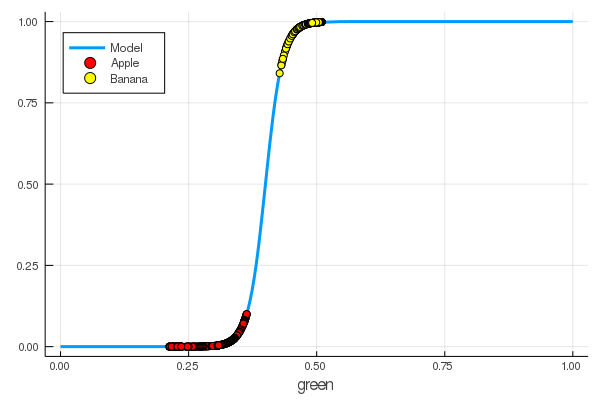
我们手动教了一个神经元,以绿色来区分苹果和香蕉。
自然,人们希望实现这一过程的自动化。 我们介绍损失函数
L(w,b)=(0−σ(x1,w,b))2+(1−σ(x2,w,b))2
现在,学习过程将包括最小化此功能:
代号 apples_mean_green = mean(g_apples) banans_mean_green = mean(g_banans) L(w, b) = (0 - sigmo(apples_mean_green,w,b))^2 + (1 - sigmo(banans_mean_green,w,b))^2 w_range = 10:0.5:30 b_range = 0:0.5:20 L_values = [L(w,b) for b in b_range, w in w_range] @manipulate for w in w_range, b in b_range p1 = surface(w_range, b_range, L_values, xlabel="b", ylabel="w", cam=(80,40), cbar=false, leg=false) scatter!(p1, [w], [b], [L(w,b)+1e-2], markersize=5, color = :blue) p2 = plot(x->sigmo(x,w,b), 0, 1, label="Model", legend = :topleft, lw=3) scatter!(p2, [apples_mean_green], [0.0], label="Apple", markersize=10) scatter!(p2, [banans_mean_green], [1.0], label="Banana", markersize=10, xlim=(0,1), ylim=(0,1)) plot(p1, p2, layout=(2,1)) end
之前我们研究了Julia的软件包,这些软件包允许通过各种方法解决优化问题。 幸运的是,基本要素已经在Flux环境中!
助焊剂
using Flux
首先,我们以易于理解的形式提供训练数据:
Y = [zeros(length(g_apples)); ones(length(g_banans)) ] |> permutedims X = [g_apples; g_banans] |> permutedims;
接下来的顺序:
- 我们通过将输入数据与有关这些数据分类的正确答案相结合来创建训练数据集
- 我们通过随机值矩阵设置参数W和b (输入处有一个符号,输出处有一个符号,所以矩阵的大小为1 x 1 )
- 作为模型,我们设置一个致密层 -具有S型激活功能的感知器
- 我们设置损失函数-平方差的总和(您仍然可以使用更流行的
Flux.crossentropy() ) - 作为一种优化方法,我们选择梯度下降 。 它需要一个参数-下降速度
- 我们设置了一个评估函数,该函数将对模型输出的值进行取整并将它们与正确答案进行比较。
- 并打印我们未经训练的模型的参数
dataz = [(X, Y)] W = param(rand(1)) b = param(rand(1)) model = Dense(W, b, σ) loss(x, y) = mse(model(x), y) opt = Descent(0.1) accuracy(x, y) = mean( round.(model(x)) .== y ) params(model) Params([[0.3372841444115968] (tracked), [0.8430399003786011] (tracked)])
让我们看看损失函数对我们的数据的输出。
loss(X, Y)
并检查评估功能的结果
accuracy(X, Y) 0.5
结果是很自然的-输出相当均匀地分布,并且一半的数据被正确分类:
代号 modeldataz(x) = x |> model |> data |> permutedims
modelX = modeldataz(X) modelapples = modeldataz(g_apples') modelbanans = modeldataz(g_banans') plot(modelX, legend = false) hline!([0.5]) p1 = yaxis!((0,1)) curv = [-1:0.01:1;]' |> modeldataz plot( [-1:0.01:1;], curv, label="Model", legend = :topleft, lw=3) scatter!(g_apples, modelapples, label="Apple", colour = :red) scatter!(g_banans, modelbanans, label="Banana",colour = :yellow) hline!([0.5], lab = "", legend = :topleft) p2 = xaxis!("green") plot(p1, p2)
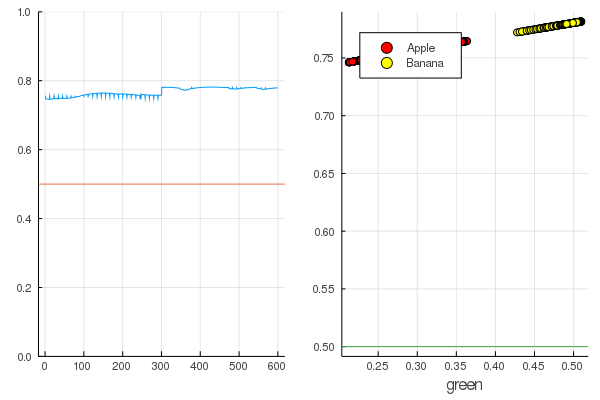
让我们开始吧:这很简单。 您只需要对神经网络大喊:“训练!”,同时指出要训练的内容和减少的内容,她将完成一个训练课程。 因此,我们将强迫她放弃一切,但不要狂热,以免再培训。
for i in 1:7000 train!(loss, params(model), dataz, opt) end model.W, model.b ([9.578663260720564] (tracked), [-3.7540362587506464] (tracked))
损失变得更少了:
loss(X, Y) 0.09152783090457564 (tracked)
评分较好:
accuracy(X, Y) 1.0
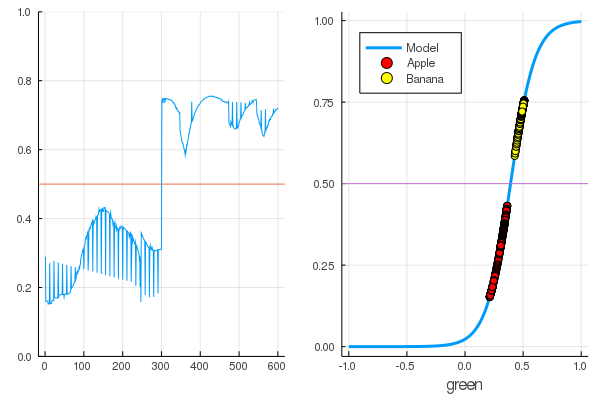
数据被分割,进一步的训练将使模型的功能更加垂直。 在第一批水果上检查经过训练的模型:
function classifier(img) gbimg = remove_background(img) greenmean = mean(float.(green.(gbimg))) answ = data( model( [ greenmean ]' ) )[1] fr = answ > 0.5 ? "Banana" : "Apple" "$fr $(round(200abs(0.5-answ)))%" end hcat(fruits...)
classifier.(fruits) 6-element Array{String,1}: "Apple 68.0%" "Apple 20.0%" "Banana 65.0%" "Banana 47.0%" "Banana 49.0%" "Banana 10.0%"
当然,不能正确地识别出特制的黄色苹果,并且红色香蕉几乎没有进入其类别。 但是神经元从图片中只得到一个数字-平均绿色。 您可以添加另一个符号,例如蓝色,这将使模型更具适应性。
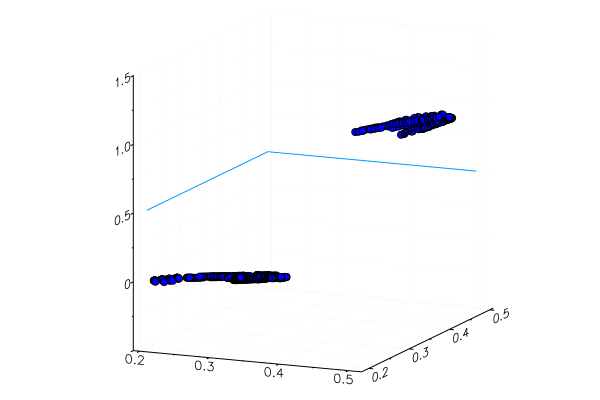
或者,您不能使用RGB表示,而可以使用HSV (色相,饱和度,值),其中色相通道将包含有关图像颜色的信息。
神经网络的全部乐趣在于它们本身可以区分有时不是很明显的特征(颜色相关性,它们的分布,轮廓和曲线...),并且您可以借助特殊的启发式方法和技术来帮助它们,从而将神经网络的工作变成真实的艺术。

这样领导才能不会增长太多 并做了一系列太懒的文章 让我们还给出一个用手写数字对图片进行分类的示例,感兴趣的读者将自己将获得的知识概括为带有水果的图像,并创建自己的神经网络,该网络能够对静物中的物体进行标记!
Mnist
using Images using Flux, Flux.Data.MNIST, Statistics using Flux: onehotbatch, onecold, crossentropy, throttle using Base.Iterators: repeated
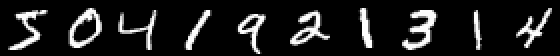
一个有趣的例子是已经有十个出口。 所谓的One-hot向量在这里派上用场。
labels = MNIST.labels()
10×60000 Flux.OneHotMatrix{Array{Flux.OneHotVector,1}}: 0 1 0 0 0 0 0 0 0 0 0 0 0 … 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 … 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0
我们将神经元链定义为模型, 交叉熵将成为损失函数,而亚当作为优化方法:
m = Chain( Dense(28^2, 32, relu), Dense(32, 10), softmax) loss(x, y) = crossentropy(m(x), y) accuracy(x, y) = mean(onecold(m(x)) .== onecold(y)) dataset = repeated((X, Y), 20) evalcb = () -> @show(loss(X, Y)) opt = ADAM()
以备用模式训练,但每10秒打印出一次损失:
for i = 1:10 Flux.train!(loss, params(m), dataset, opt, cb = throttle(evalcb, 10)) end
accuracy(X, Y) 0.64545
并检查训练中未使用的数据
Julia上的神经网络非常简单,令人兴奋! 即使没有必要在您的活动领域和机器学习之间寻找联系,您至少也应该感到这种好奇心,它从各个角度都在大声喊叫,并且不会缺少任何工具!
所有CPU热量适中!