调色板允许艺术家组织和混合不同颜色的颜料,从而在它们前面的画布上创建颜料。 类似工具的存在可以使AI能够从各种数据源(例如对话,故事,图像和知识)一起学习,这为研究人员和科学家开发更全面的AI系统打开了大门。
 调色板允许艺术家涂抹和混合不同颜色的涂料。 SpaceFusion致力于帮助AI科学家针对在不同数据集上训练的不同模型做类似的事情。
调色板允许艺术家涂抹和混合不同颜色的涂料。 SpaceFusion致力于帮助AI科学家针对在不同数据集上训练的不同模型做类似的事情。对于现代深度学习模型,数据集通常由使用不同神经网络的不同隐藏空间中的向量表示。 在我的合著者和我的文章“
神经反应生成中多样性和相关性的联合优化 ”中,我介绍了SpaceFusion,这是一种训练范式,可以“混合”各种隐藏的空间(例如调色板上的颜料),以便AI可以使用嵌入在每个空间中的模式和知识他们。 这项工作的实现在
GitHub上
可用 。
捕捉人类对话的色彩
作为首次尝试,我们将此技术应用于神经交互AI。 在我们的设置中,预期神经模型会基于对话历史或上下文生成相关且有趣的响应。 尽管在神经沟通模型中已经取得了令人鼓舞的成功,但这些模型通常尽量不要冒险,重现普遍而无聊的答案。 已经开发出使这些响应多样化并且更好地反映人类对话色彩的方法,但是
随着相关性的降低,通常
会出现妥协。 。
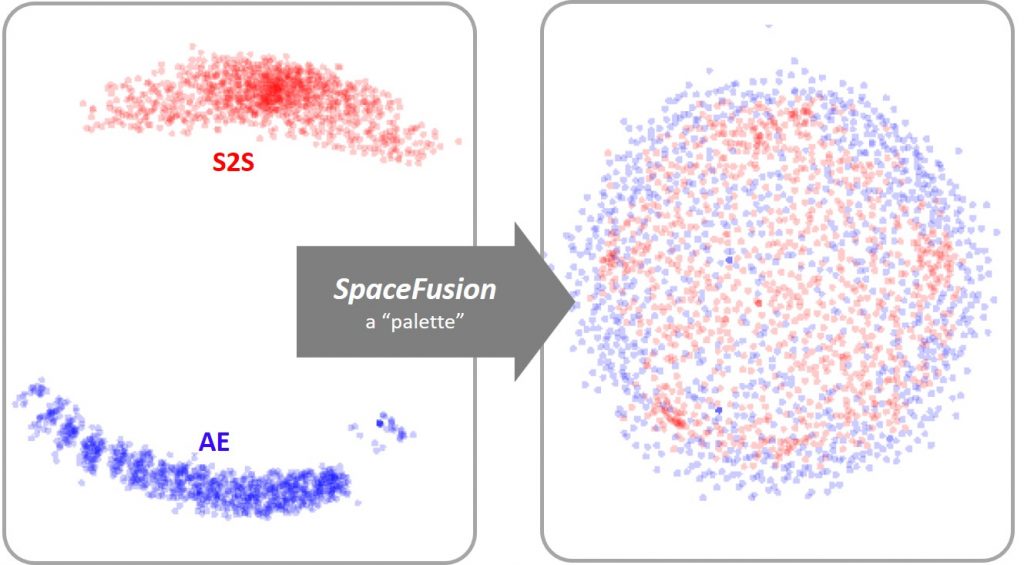 图1:就像易于组合绘画的调色板一样,SpaceFusion对齐或混合seq2seq(S2S,红点)和自动编码器(AE,蓝点)模型中的隐藏空间,以更有效地共享两个模型。
图1:就像易于组合绘画的调色板一样,SpaceFusion对齐或混合seq2seq(S2S,红点)和自动编码器(AE,蓝点)模型中的隐藏空间,以更有效地共享两个模型。SpaceFusion通过链接从两个模型中提取的隐藏空间来解决此问题(图1):
- 序列到序列(S2S)模型,旨在获得相关的答案,但可能没有多少差异; 以及
- 一个自动编码器(AE)模型,能够呈现不同的答案,但不能反映出它们与对话的关系
共同训练的模型可以利用两个模型的优势,并以更结构化的方式组织数据点。
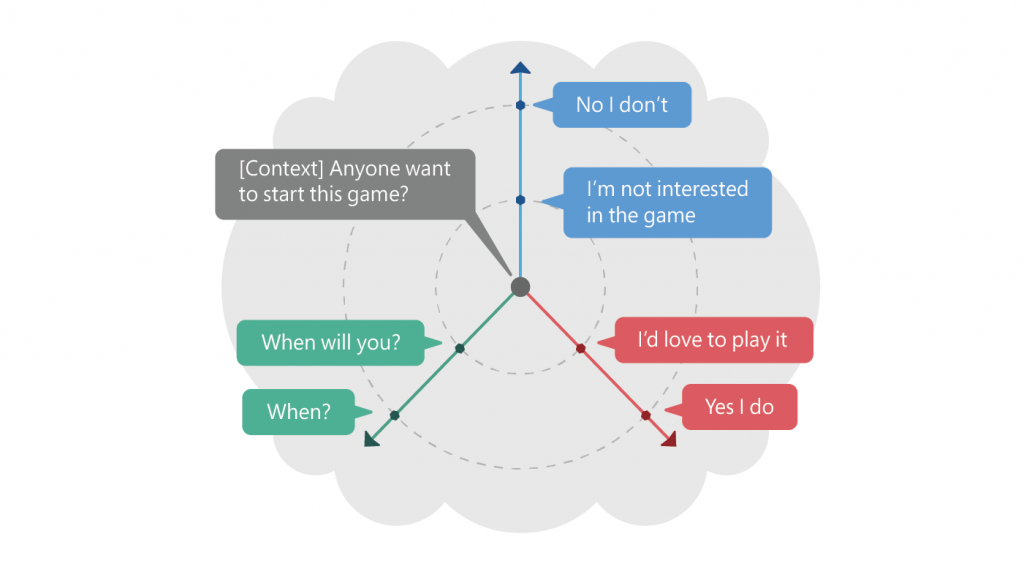 图2:上面显示了一个上下文及其在由SpaceFusion引起的隐藏空间中的许多响应。 考虑到上下文,与预测的响应向量的距离和方向分别大致对应于重要性和多样性。
图2:上面显示了一个上下文及其在由SpaceFusion引起的隐藏空间中的许多响应。 考虑到上下文,与预测的响应向量的距离和方向分别大致对应于重要性和多样性。例如,如图2所示,考虑到上下文-在这种情况下,“有人要开始玩这个游戏吗?” -肯定答案“我想玩”和“是,我玩”位于一个方向上。 否定的“我对游戏不感兴趣”和“不,我不感兴趣”-被映射到不同的方向。 通过研究不同方向的隐藏空间,可以实现答案的多样性。 此外,隐藏空间中的距离也很重要。 距离上下文较远的答案(“是,我玩”和“不,我不玩”)通常本质上是笼统的,而较接近的答案则与特定上下文更相关:“我对游戏不感兴趣”和“何时你要去玩吗?
SpaceFusion分离了相关性和多样性标准,并以两个独立的维度(方向和距离)呈现它们,从而促进了两者的联合优化。 我们在人体中进行的实验和评估表明,与竞争基准相比,SpaceFusion在这两个标准上的性能更好。
学习共享的隐藏空间
那么SpaceFusion如何精确映射不同的隐藏空间?
这个想法非常直观:对于来自两个不同隐藏空间的每对点,我们首先最小化它们在公共隐藏空间中的距离,然后保持它们之间的平滑过渡。 这是通过向目标函数添加两个新的正则化项-距离项和平滑度项来完成的。
以对话为例,距离项测量的是根据上下文显示并表示预测响应的,来自隐蔽空间S2S的点与对应于其目标答案的隐蔽空间AE的点之间的欧式距离。 最小化此距离会使S2S模型将上下文显示为一个点,并在公共隐藏空间中被其响应包围,如图2所示。
平滑度项度量从上下文映射的点和响应映射的点之间的随机插值生成目标响应的可能性。 通过最大程度地提高这种可能性,当您远离上下文时,我们鼓励所生成的响应的值平稳过渡。 这使我们能够调查S2S做出的预测点的邻域,从而生成与上下文相关的各种答案。
在目标函数中添加了这两个新的正则化之后,我们对学习隐藏空间施加了距离和均匀性限制,因此训练不仅将重点放在每个隐藏空间的性能上,还将尝试通过添加这些所需的结构来使它们对齐。 我们的工作集中在交互式模型上,但是我们希望SpaceFusion可以将其他模型训练的隐藏空间对准不同的数据集。 这将连接每个特定AI系统学习的各种能力和知识领域,这是迈向更全面AI的第一步。
另请参阅: 7个针对开发人员的免费课程