10月26日,莱茵林茨(德国)主持了有关Haxe及其相关技术的2019年HaxeUp Sessions小型会议 。 当然,它最重要的事件是Haxe 4.0.0的最终版本(在发布时,即大约一周后, 发布了4.0.1更新 )。 在本文中,我想向您介绍会议的第一份报告的译文-关于Haxe团队在2019年所做工作的报告。

关于报告作者的一些信息:
从2010年开始,Simon就一直在Haxe工作,当时他还是一名学生,并撰写了有关Flash中流体模拟的文章。 这种模拟的实现需要不断访问描述粒子状态的数据(在每个步骤中,要对数据数组进行100多次关于模拟中每个单元格状态的查询),而在ActionScript 3中使用数组的工作并不是那么快。 因此,最初的实现方式根本无法实现,需要找到解决该问题的方法。 在他的搜索中,Simon遇到了Nicolas Kannass (Haxe的创建者)的一篇文章,内容涉及当时未公开的 Alchemy操作码,这些代码无法使用ActionScript使用,但是Haxe允许使用它们。 使用操作码在Haxe上重写模拟,Simon得到了有效的模拟! 因此,由于ActionScript中的慢速数组,Simon了解了Haxe。
自2011年以来,Simon参与了Haxe的开发工作,他开始研究OCaml(在其上编写编译器)并对编译器进行了各种更正。
从2012年起,他成为主要的编译器开发人员。 同年,成立了Haxe基金会 (该组织的主要目标是开发和维护Haxe生态系统,帮助社区组织会议并提供咨询服务),Simon成为其联合创始人之一。

在2014-2015年,Simon邀请Josephine Pertosa加入了Haxe基金会,该基金会随后负责组织会议和社区关系。
在2016年,Simon首次在Haxe上发表演讲 ,并在2018年组织了第一届HaxeUp会议 。

那么在过去的2019年Haxe世界发生了什么?
在2月和3月,有2个候选发行版发布(4.0.0-rc1和4.0.0-rc2)
4月, Aurel Bili (作为实习生)和Alexander Kuzmenko (作为编译器开发人员)加入了Haxe Foundation团队。
5月, 举行了2019年Haxe美国峰会 。
6月,发布了Haxe 4.0.0-rc3。 而在9月-Haxe 4.0.0-rc4和Haxe 4.0.0-rc5。

Haxe不仅是编译器,而且还是一整套各种工具,并且在全年中,它们的工作也在不断进行:
由于Andy Lee的努力, Haxe现在使用Azure Pipelines代替Travis CI和AppVeyor。 这意味着组装和自动化测试现在要快得多。
休·桑德森 ( Hugh Sanderson)继续致力于hxcpp (Haxe中支持C ++的库)。
突然,Github terurou和takashiski的用户加入了Node.js externs的工作。
Rudy Ges致力于修复和改进,以支持C#目标。
George Corney继续支持HTML extern生成器。
Jens Fisher正在从事vshaxe (与Haxe一起使用的VS Code的扩展)以及许多其他与Haxe相关的项目。

当然,今年的主要事件当然是期待已久的Haxe 4.0.0 (以及neko 2.3.0)的发布,它偶然与HaxeUp 2019 Linz碰巧出现:)

西蒙将报告的大部分内容用于Haxe 4.0.0的新功能(您也可以从上一届Haxe US Summit 2019 的Alexander Kuzmenko的报告中了解到它们)。

新的eval宏解释器比旧的解释器快几倍。 西蒙在2017年欧洲峰会上的讲话中详细谈到了他。 但是从那时起,它改进了代码的调试功能,修复了许多错误,重新设计了字符串的实现。
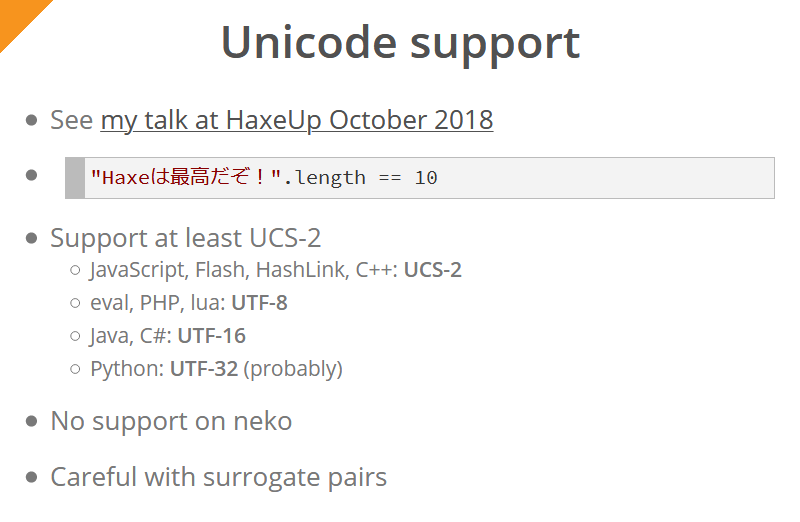
Haxe 4引入了对所有平台(Neko除外)的Unicode支持。 西蒙在去年的演讲中对此进行了详细描述。 对于编译器的最终用户,这意味着表达式"Haxeは最高だぞ!".length所有平台的"Haxeは最高だぞ!".length将始终返回10 (同样,Neko除外)。
最少支持UCS-2编码(每种平台/语言都使用本机支持的编码;在任何地方尝试支持相同的编码都是不切实际的):
- JavaScript,Flash,HashLink和C ++使用UCS-2编码
- 用于评估,PHP,Lua-UTF-8
- Java和C#的代码-UTF-16
- 适用于Python-UTF-32
主多语言平面之外的所有字符(包括表情符号)都表示为“代理对”-这些字符用两个字节表示。 例如,如果在Java / C#/ JavaScript中(即,对于UTF-16和UCS-2编码的字符串)请求由一个表情符号组成的字符串的长度,则结果将为“ 2”。 在这些平台上使用此类字符串时,必须考虑到这一事实。
Haxe 4引入了一种新型的迭代器-键值:

它可以与Map类型(字典)和字符串类型(使用StringTools类)的容器一起使用,但尚未实现对数组的支持。 也可以为自定义类实现这样的迭代器,为此,只需为它们实现keyValueIterator():KeyValueIterator<K, V>方法即可keyValueIterator():KeyValueIterator<K, V> 。
新的元标记@:using允许您在声明的静态扩展名和类型之间进行关联。
在下面的幻灯片中所示的示例中, MyOption枚举与MyOptionTools相关联,因此我们静态扩展了此枚举(在通常情况下是不可能的),并有机会调用get()方法,将其称为对象方法。

在此示例中, get()方法是内联的,这还允许编译器进一步优化代码:代替调用MyOptionTools.get(myOption)方法,编译器将替换存储的值,即12 。
如果该方法未声明为可嵌入,则程序员可以使用的另一个优化工具是将函数嵌入在调用位置(调用站点内联)。 为此,在调用函数时,还必须使用inline :

由于Daniil Korostelev的工作,Haxe现在有机会生成JavaScript的ES6类。 您只需要添加编译标志-D js-es=6 。
当前,编译器会为整个项目生成一个js文件(将来可能会为每个类生成单独的js文件,但是到目前为止,只能使用其他工具来完成此操作)。

对于抽象枚举,现在会自动生成值。
在Haxe 3中,必须为每个构造函数手动设置值。 在Haxe 4中,在Int之上创建的抽象枚举的行为与在C中的规则相同。在字符串之上创建的抽象枚举的行为相似-对于它们,生成的值将与构造函数的名称一致。

一些语法改进也值得一提:
- 抽象枚举和extern函数已成为Haxe的正式成员,现在您无需使用
@:enum和@:extern元标记来声明它们 - 4th Haxe使用一种新型的交集语法,可以更好地反映扩展结构的本质。 这样的构造在声明数据结构时最有用:表达式
typedef T = A & B表示结构T具有所有类型A和B的字段 - 同样,有四个声明类型参数约束:条目
<T:A & B>表示参数T的类型必须同时为A和B - 旧的语法将起作用(类型限制的语法除外,因为它将与用于描述函数类型的新语法冲突)

用于描述函数类型的新语法(函数类型语法)更加合乎逻辑:在函数参数类型周围使用括号在视觉上更易于阅读。 另外,新语法允许您定义参数名称,这些名称可以用作代码文档的一部分(尽管它不会影响键入本身)。

在这种情况下,旧语法将继续受支持,并且不会被弃用,因为 否则,将需要对现有代码进行太多更改(Simon自己经常会变得不习惯,并继续使用旧语法)。
Haxe 4最终具有箭头功能(或lambda表达式)!

Haxe中箭头功能的特点是:
- 隐性
return 。 如果函数主体包含一个表达式,则此函数隐式返回此表达式的值 - 可以设置函数参数的类型,因为 编译器无法始终确定所需的类型(例如
Float或Int ) - 如果函数的主体包含多个表达式,则需要用花括号将其括起来
- 但是无法显式设置函数的返回类型
通常,箭头函数的语法与Java 8中使用的语法非常相似(尽管其工作原理有所不同)。
而且,由于我们提到了Java,因此应该说在Haxe 4中可以直接生成JVM字节码。 为此,在Java下编译项目时,只需添加-D jvm标志。
生成JVM字节码意味着无需使用Java编译器,并且编译过程要快得多。

到目前为止,由于以下原因,JVM目标具有实验状态:
- 在某些情况下,字节码比在Java中翻译Haxe然后使用javac编译的结果要慢一些。 但是编译器团队已经意识到了这个问题,并且知道如何解决它,这只需要额外的工作。
- Android上的MethodHandle存在问题,这也需要额外的工作(如果西蒙帮助解决这些问题,他会很高兴)。

直接生成字节码(genjvm)和将Haxe编译为Java代码,然后将其编译为字节码(genjava)的一般比较:
- 如前所述,就编译速度而言,genjvm比genjava快
就执行速度而言,字节码genjvm仍然不如genjava - 使用类型参数和genjava时存在一些问题
- genJvm使用MethodHandle来指代函数,而genjava使用所谓的“ Waneck函数”(以纪念Kaui Vanek,以在Haxe中出现Java和C#支持)。 尽管使用Waneck函数获得的代码看起来并不漂亮,但是它可以正常工作并且足够快。
在Haxe中使用Java的一般技巧:
- 由于Java中的垃圾收集器速度很快,因此与之相关的问题很少见。 当然,不断创建新对象并不是一个好主意,但是Java很好地应付了内存管理,并且持续照顾分配的需求并不像Haxe支持的某些其他平台(例如,在HashLink中)那么紧迫。
- 如果通过结构(
typedef )完成操作,则访问jvm目标中的类的字段可能会非常缓慢-编译器无法优化此类代码 - 应避免过度使用
inline关键字-JIT编译器做得很好 - 避免使用
Null<T> ,尤其是在处理复杂的数学计算时。 否则,许多条件语句将出现在生成的代码中,这会对代码的速度产生负面影响。
Haxe 4的新功能Null安全性可以帮助避免使用Null<T> 。 亚历山大·库兹曼科(Alexander Kuzmenko) 在去年的HaxeUp上详细介绍了她。

在上一张幻灯片的示例中,static safe()方法启用了用于检查Null安全性的严格模式,并且该方法具有可选的arg参数,该参数可以为null值。 为了使该函数成功编译,程序员将需要添加对arg参数值的检查(否则,编译器将显示一条消息,提示无法在可能为null的对象上调用charAt()方法)。
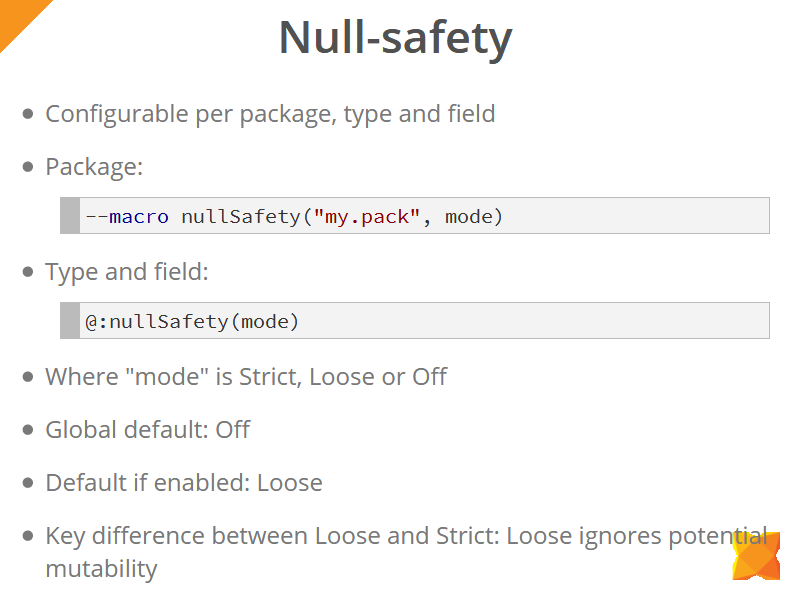
可以在包级别(使用宏),对象的类型和单个字段(使用@:nullSafety元标记)配置Null安全性。
空安全性检查的工作模式为:严格,宽松和关闭。 总体而言,这些检查处于禁用状态(关闭模式)。 启用它们时,默认情况下使用“松散”模式(除非您明确指定该模式)。 松散和严格模式之间的主要区别在于,松散模式忽略了在访问这些值的操作之间更改值的可能性。 在下面幻灯片的示例中,我们看到为变量x添加了null检查。 但是,在严格模式下,此代码不会编译,因为 在直接使用变量x ,将sideEffect()方法,该方法可能会使该变量的值无效,因此您将需要添加另一项检查或将变量的值复制到局部变量,我们将继续使用它。

Haxe 4引入了一个新的final关键字,根据上下文,其含义有所不同:
- 如果使用它而不是
var关键字,则无法为以此方式声明的字段分配新值。 您只能在声明时(对于静态字段)或在构造函数中(对于非静态字段)直接设置它 - 如果在声明类时使用它,它将禁止从其继承
- 如果将它用作访问对象属性的修饰符,则这将禁止在继承类中重新定义getter / setter。

从理论上讲,假定该字段的值没有变化,遇到了final关键字的编译器可以尝试优化代码。 但是目前,这种可能性仅在考虑中,尚未在编译器中实现。

关于Haxe的未来:
- 当前正在使用异步I / O API
协程支持已经计划好了,但是到目前为止,它们的工作还停留在计划阶段。 也许它们会出现在Haxe 4.1中,甚至以后。 - 尾部调用优化将出现在编译器中
- 以及模块级可用的功能 。 尽管此功能的优先级不断变化