长期以来,累积(累积)结果一直被视为SQL调用之一。 令人惊讶的是,即使在出现窗口功能之后,它仍然是稻草人(无论如何对于初学者而言)。 今天,我们看一下解决此问题的10个最有趣的解决方案的机制-从窗口功能到非常具体的hack。
在像Excel这样的电子表格中,运行总计的计算非常简单:第一条记录中的结果与其值匹配:
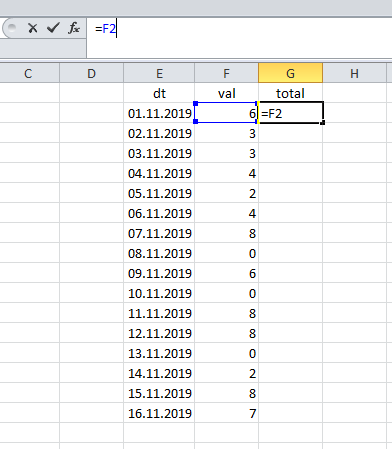
...然后总结当前值和先前的总计。

换句话说
...或:
表中两个或两个以上组的出现使任务复杂化了:现在我们计算几个结果(每个组分别)。 但是,这里的解决方案是表面上的:每次必须检查当前记录属于哪个组。
单击并拖动 ,完成工作:
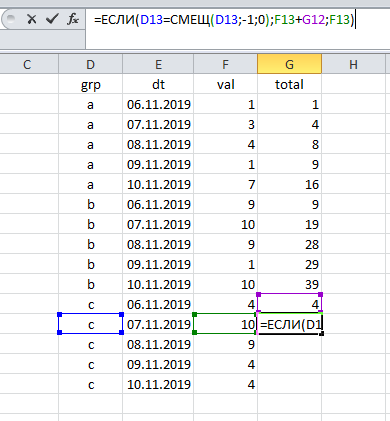
如您所见,累计总数的计算与两个不变的组件相关联:
(a)按日期对数据进行排序,以及
(b)参考上一行。
但是什么是SQL? 很长时间以来,其中没有必要的功能。 必需的工具-窗口函数-仅在
SQL:2003标准中首次出现。 此时,它们已经在Oracle(版本8i)中。 但是其他DBMS的实施被延迟了5-10年:SQL Server 2012,MySQL 8.0.2(2018),MariaDB 10.2.0(2017),PostgreSQL 8.4(2009),DB2 9 for z / OS(2007)年),甚至SQLite 3.25(2018)。
1.窗口功能
窗口函数可能是最简单的方法。 在基本情况下(不带表的表),我们考虑按日期排序的数据:
order by dt
...但是我们只对当前行之前的行感兴趣:
rows between unbounded preceding and current row
最终,我们需要具有以下参数的总和:
sum(val) over (order by dt rows between unbounded preceding and current row)
完整的请求如下所示:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
如果是组的累计总数(
grp字段),我们只需要进行一次小的编辑。 现在,我们根据组将数据分为“窗口”:

为了解决这种分离,您必须使用关键字
partition by :
partition by grp
因此,请考虑以下窗口的数量:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
然后将整个查询转换为:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
窗口函数的性能将取决于DBMS(及其版本)的细节,表的大小以及索引的可用性。 但在大多数情况下,此方法将是最有效的。 但是,窗口功能在较旧版本的DBMS(仍在使用中)中不可用。 此外,它们不在Microsoft Access和SAP / Sybase ASE之类的DBMS中。 如果需要独立于供应商的解决方案,则应考虑替代方案。
2.子查询
如上所述,窗口功能是在主要DBMS中引入得非常晚的。 这种延迟应该不足为奇:在关系理论中,数据是无序的。 关系理论的精神与通过子查询的解决方案相对应。
这样的子查询应该考虑值的总和,其日期在当前日期之前(包括当前日期):
。
代码中的内容如下所示:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
一种稍微有效的解决方案是,子查询考虑到当前日期的总计(但不包括它),然后将其与行中的值求和:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
对于多个组的累积结果,我们需要使用相关的子查询:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
条件
g.grp = t2.grp检查包含在组中的行(原则上,这类似于窗口函数中
partition by grp工作)。
3.内部连接
由于子查询和联接是可互换的,因此我们可以轻松地用另一个替换。 为此,必须使用自我连接,连接同一表的两个实例:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
如您所见,子查询
t2.dt <= s.dt的过滤条件已成为
t2.dt <= s.dt条件。 另外,为了使用聚合函数
sum()我们需要按日期分组,按值分组,
group by s.dt, s.val 。
同样,您可以针对具有不同
grp组的情况进行处理:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4.笛卡尔积
由于我们用join替换了子查询,为什么不尝试使用笛卡尔积呢? 此解决方案仅需要最少的编辑:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
或对于团体:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
列出的解决方案(子查询,内部
联接 ,笛卡尔
联接 )对应于
SQL-92和
SQL:1999 ,因此几乎在所有DBMS中都可用。 所有这些解决方案的主要问题是性能差。 如果我们将表具体化为结果,这并不是什么大麻烦(但是您仍然希望提高速度!)。 其他方法更为有效(针对特定DBMS的细节及其已指定的版本,表大小,索引进行了调整)。
5.递归请求
一种更具体的方法是在公用表表达式中进行递归查询。 为此,我们需要一个“锚”(anchor)-返回第一行的查询:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
然后,借助
union all ,将递归查询的结果添加到“锚点”中。 为此,您可以依靠
dt date字段,在其中添加一天:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
添加一天的代码部分不是通用的。 例如,对于SQL Server,这是
r.dt = dateadd(day, 1, cte.dt) ,对于Oracle,
r.dt = cte.dt + 1 。
结合“ anchor”和主要请求,我们得到最终结果:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
具有组的情况的解决方案将不会更加复杂:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6.使用row_number()函数进行递归查询
先前的决定是基于
dt date字段的连续性,连续增加1天。 我们通过使用
row_number()窗口函数(为行编号
row_number()来避免这种情况。 当然,这是不公平的-因为我们将考虑窗函数的替代方法。 但是,此解决方案可能是一种
概念证明 :实际上,可能存在一个替换行号(记录ID)的字段。 另外,在SQL Server中,在引入对窗口函数的完全支持(包括
sum() )之前,出现了
row_number()函数。
因此,对于具有
row_number()的递归查询,我们需要两个STE。 首先,我们只对行编号:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
...,如果表中已经存在行号,则可以不使用它。 在以下查询中,我们已经
cte1了
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
整个请求如下所示:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
...或针对团体:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY / LATERAL
计算运行总计的最奇特的方法之一是使用
CROSS APPLY语句(SQL Server,Oracle)或等效的
LATERAL (MySQL,PostgreSQL)。 这些运算符的出现时间很晚(例如,仅在Oracle中从12c版本开始)。 在某些DBMS(例如
MariaDB )中根本没有。 因此,此决定纯粹是出于美学目的。
从功能
LATERAL ,使用
CROSS APPLY或
LATERAL与子查询相同:我们将计算结果附加到主请求:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
...看起来像这样:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
具有组的情况的解决方案将类似:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
总计:我们研究了与平台无关的主要解决方案。 但是,有针对特定DBMS的解决方案! 由于这里有很多选择,所以让我们来谈谈一些最有趣的选择。
8. MODEL语句(Oracle)
Oracle中的
MODEL语句提供了最优雅的解决方案之一。 在本文的开头,我们检查了累计总数的一般公式:
MODEL使您可以按字面意义一对一地实现此公式! 为此,我们首先用当前行的值填充
total字段
select dt, val, val as total from test_simple
...然后,我们将行号计算为
row_number() over (order by dt) as rn并将其计算
row_number() over (order by dt) as rn (
row_number() over (order by dt) as rn (或将完成的字段与该编号一起使用,如果有的话)。 最后,我们为除第一行外的所有行引入一个规则:
total[rn >= 2] = total[cv() - 1] + val[cv()] 。
这里的
cv()函数负责当前行的值。 整个请求将如下所示:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9.游标(SQL Server)
运行总计是少数情况下的一种情况,其中SQL Server中的光标不仅有用,而且优于其他解决方案(至少直到出现窗口功能的2012版之前)。
通过游标实现非常简单。 首先,您需要创建一个临时表,并用主表中的日期和值填充它:
create table
然后,我们设置将通过其进行更新的局部变量:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
之后,我们通过游标更新临时表:
declare cur cursor local static read_only forward_only for select dt, val from
最后,我们得到了预期的结果:
select dt, val, total from
10.通过局部变量更新(SQL Server)
通过SQL Server中的局部变量进行更新是基于未记录的行为,因此不能认为它是可靠的。 但是,这可能是最快的解决方案,这很有趣。
我们创建两个变量:一个用于累计总数,另一个用于表变量:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
首先,
@tv主表中的数据填充
@tv insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
然后
@tv使用
@VarTotal更新表变量
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
...之后,我们得到最终结果:
select * from @tv order by dt;
简介:我们回顾了用SQL计算累积总数的十大方法。 如您所见,即使没有窗口功能,此问题也可以完全解决,解决方案的机制也不能称为复杂。