大家好! 几个月前,我们将名为
DevOpsProdigy KubeGraf的用于监视kubernetes的新开源项目Grafana插件
投入生产 。 该插件的源代码可在
GitHub的
公共存储库中找到 。 在本文中,我们想与您分享一个有关如何创建插件,使用哪些工具以及在开发过程中遇到的陷阱的故事。 走吧
第0部分-简介:我们如何做到这一点?
为Grafan编写自己的插件的想法是偶然产生的。 十多年来,我们公司一直在监视各种复杂程度的Web项目。 在这段时间里,我们获得了大量的专业知识,有趣的案例以及使用各种监视系统的经验。 在某个时候,我们问自己:“是否有一种神奇的工具来监视Kubernetes,就像他们所说的那样,“设置并忘记”? 作为针对该堆栈的现成解决方案,有大量的各种工具集:prometheus-operator,一组仪表板kubernetes-mixin,grafana-kubernetes-app。
grafana-kubernetes-app插件对于我们来说似乎是最有趣的选择,但是一年多以来一直没有得到支持,而且,不知道如何使用新版本的node-exporter和kube-state-metrics。 在某个时候,我们决定:“但是我们不做自己的决定吗?”
我们决定在插件中实现哪些想法:
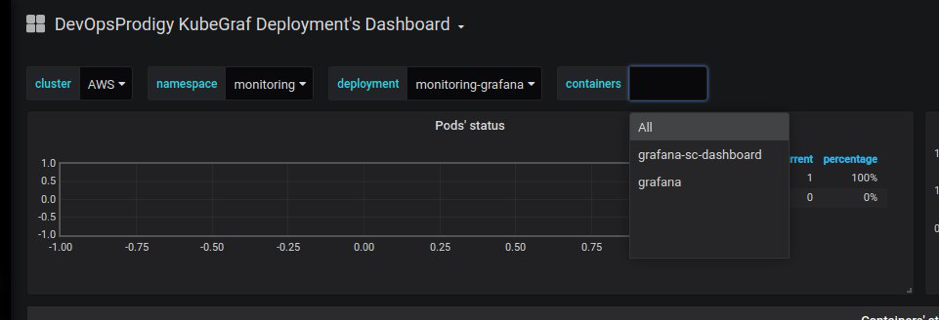
- “应用程序图”的可视化:方便地在集群中呈现应用程序,按名称空间分组,进行部署...;
- 可视化形式为“部署-服务(+端口)”的连接。
- 通过集群节点可视化集群应用程序的分布。
- 从多个来源收集指标和信息:Prometheus和k8s api服务器。
- 监视基础结构部分(处理器时间,内存,磁盘子系统,网络的使用)和应用程序逻辑-健康状态窗格,可用副本的数量,有关活动/就绪样本通过的信息。
第1部分:什么是Grafana插件?
从技术角度来看,Grafana插件是一个角度控制器,存储在Grafana数据目录(
/var/grafana/plugins/<your_plugin_name>/dist/module.js )中,可以作为SystemJS模块加载。 此外,在此目录中还应该是一个plugin.json文件,其中包含有关您的插件的所有元信息:名称,版本,插件的类型,与存储库/站点/许可证的链接,依赖项等。
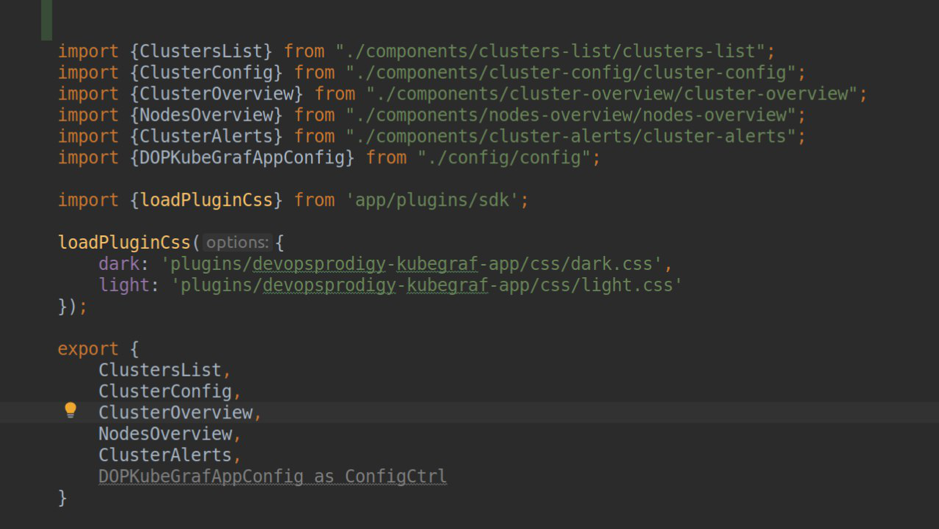 module.ts
module.ts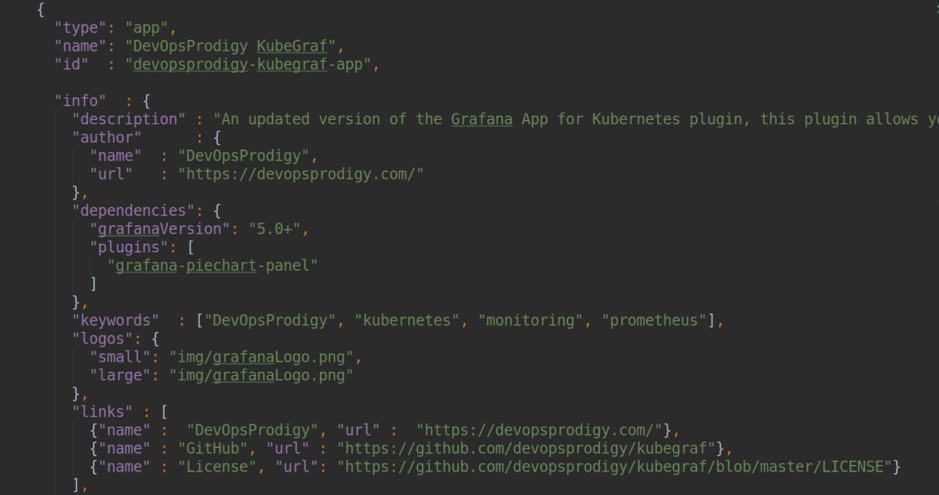 plugin.json
plugin.json如您在屏幕快照中所见,我们指定了plugin.type = app。 对于Grafana的插件,可以分为三种类型:
panel :最常见的插件类型-它是用于可视化任何指标的面板,用于构建各种仪表板。
datasource :任何数据源(例如Prometheus-datasource,ClickHouse-datasource,ElasticSearch-datasource)的插件连接器。
app :一个插件,可让您在Grafana中构建自己的前端应用程序,创建自己的html页面并手动访问数据源以可视化各种数据。 另外,其他类型的插件(数据源,面板)和各种仪表板也可以用作依赖项。
 类型= app的插件依赖关系示例
类型= app的插件依赖关系示例 。
作为一种编程语言,您可以同时使用JavaScript和TypeScript(我们选择了它)。 您可以在
这里找到任何类型的hello-world插件
的空白:在此存储库中,有大量的预装程序包(甚至在React上甚至有一个实验性的示例),这些程序包都已预先安装和配置了构建器。
第2部分:准备本地环境
要使用该插件,我们自然需要一个带有所有预装工具的kubernetes集群:prometheus,node-exporter,kube-state-metrics和grafana。 该环境应快速,轻松且自然地进行设置,并提供热重载数据,应直接从开发人员的计算机上安装Grafana目录。
我们认为,使用kubernetes在本地工作最方便的方法是
minikube 。 下一步是使用prometheus-operator建立Prometheus + Grafana捆绑包。
本文详细介绍了在minikube上安装prometheus-operator的过程。 要启用持久性,必须在图表/ grafana / values.yaml文件中设置
persistence:true参数,添加自己的PV和PVC并在persistence.existingClaim参数中指定它们
最终的minikube启动脚本如下所示:
minikube start --kubernetes-version=v1.13.4 --memory=4096 --bootstrapper=kubeadm --extra-config=scheduler.address=0.0.0.0 --extra-config=controller-manager.address=0.0.0.0 minikube mount /home/sergeisporyshev/Projects/Grafana:/var/grafana --gid=472 --uid=472 --9p-version=9p2000.L
第三部分:开发本身
对象模型在准备实现插件之前,我们决定以TypeScript类的形式描述将要使用的所有基本Kubernetes实体:pod,Deployment,daemonset,statefulset,job,cronjob,service,node,namespace。 这些类均继承自公共BaseModel类,该类描述了构造函数,析构函数,更新和切换可见性的方法。 每个类都描述与其他实体的嵌套关系,例如,类型部署实体的Pod列表。
import {Pod} from "./pod"; import {Service} from "./service"; import {BaseModel} from './traits/baseModel'; export class Deployment extends BaseModel{ pods: Array<Pod>; services: Array<Service>; constructor(data: any){ super(data); this.pods = []; this.services = []; } }
使用getter和setter,我们可以以方便且易读的方式显示或设置所需实体的度量。 例如,可分配的cpu点头的格式化输出:
get cpuAllocatableFormatted(){ let cpu = this.data.status.allocatable.cpu; if(cpu.indexOf('m') > -1){ cpu = parseInt(cpu)/1000; } return cpu; }
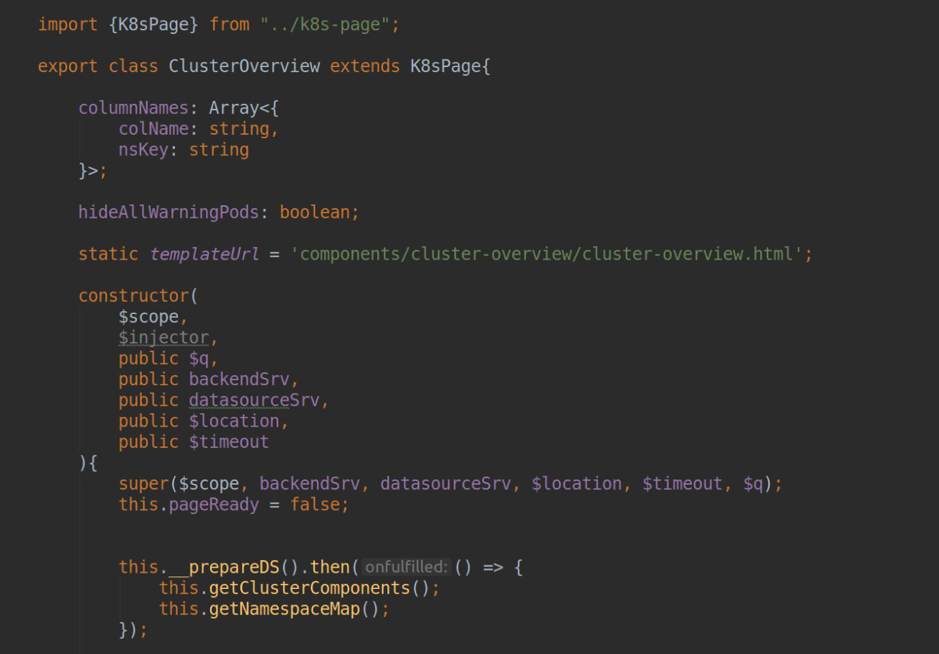
页数我们插件的所有页面的列表最初在pluing.json的依赖项部分中进行了描述:
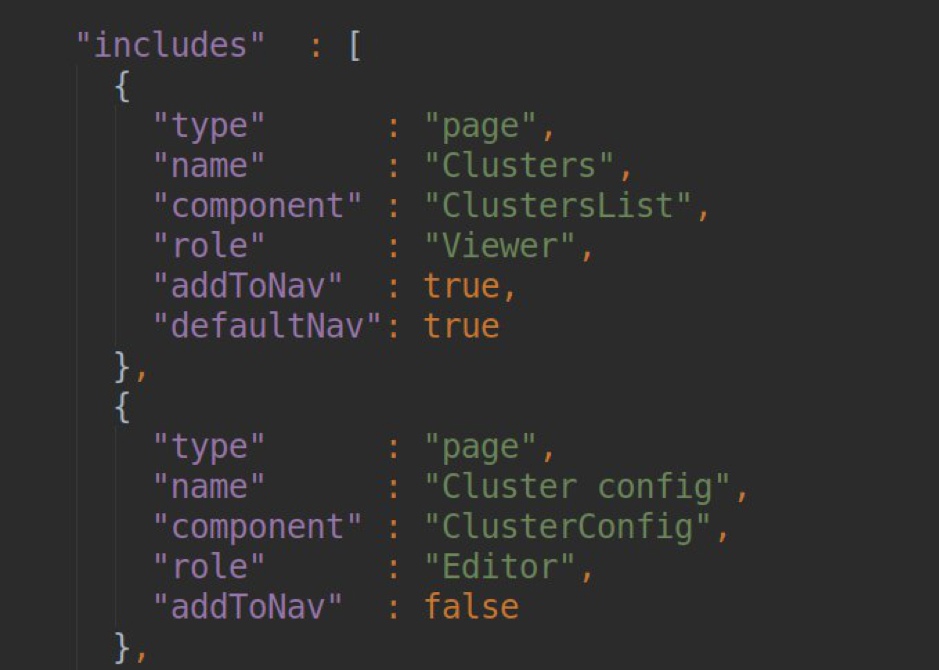
在每页的块中,我们必须指示PAGE TITLE(然后将其转换为Slug,通过该标签可使用此页面); 负责此页面操作的组件的名称(组件列表已导出到module.ts); 指定可以访问该页面的用户角色以及侧边栏的导航设置。
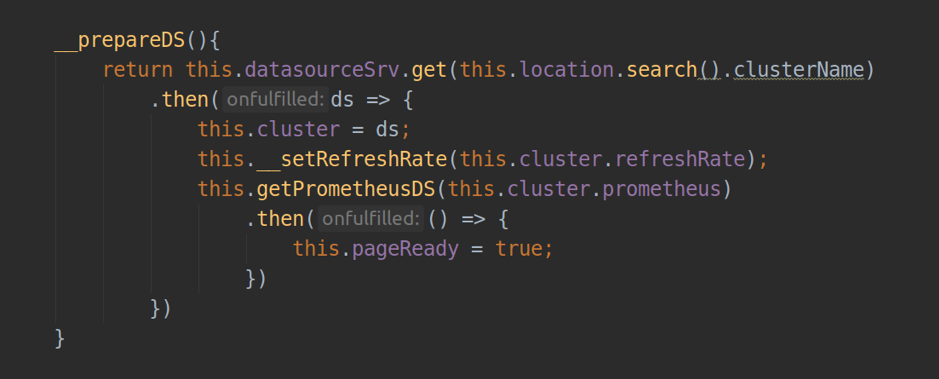
在负责页面操作的组件中,我们必须安装templateUrl,并在其中传递带有标记的html文件的路径。 在控制器内部,通过依赖注入,我们最多可以访问2个重要的角度服务:
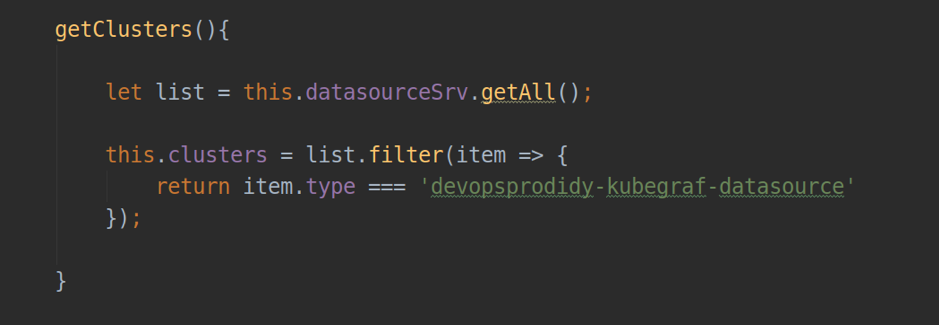
- backendSrv-提供与grafana api服务器交互的服务;
- datasourceSrv-一种提供与Grafana中安装的所有数据源的本地交互的服务(例如.getAll()方法-返回所有已安装数据源的列表; .get(<name>)-返回特定数据源的实例对象)。
第4部分:数据源
从Grafana的角度来看,数据源与其他所有人完全相同:它具有自己的入口点module.js,有一个包含元信息plugin.json的文件。 当开发类型为app的插件时,我们可以与现有数据源(例如prometheus-datasource)以及我们自己的数据源进行交互,我们可以将其直接存储在插件目录(dist / datasource / *)中或设置为依赖项。 在我们的例子中,数据源带有插件代码。 还需要有config.html模板和ConfigCtrl控制器,它们将用于数据源实例的配置页面和Datasource控制器,该控制器实现了数据源的逻辑。
从用户界面的角度来看,在KubeGraf插件中,数据源是kubernetes集群的实例,该集群中实现了以下功能(源代码可
通过参考获得 ):
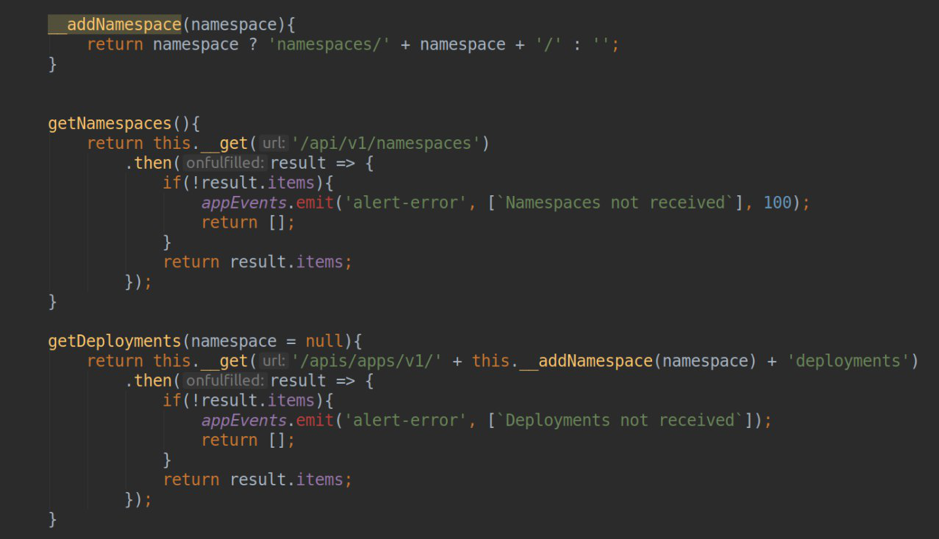
- 从k8s api服务器收集数据(获取命名空间'ov,deployment'ov ...的列表)
- 在prometheus-datasource(在每个特定集群的插件设置中选择)中代理请求,并格式化响应以在静态页面和仪表板中使用数据。
- 更新插件静态页面上的数据(设置刷新率)。
- 处理在grafana仪表盘中生成模板列表的请求(.metriFindQuery()方法)
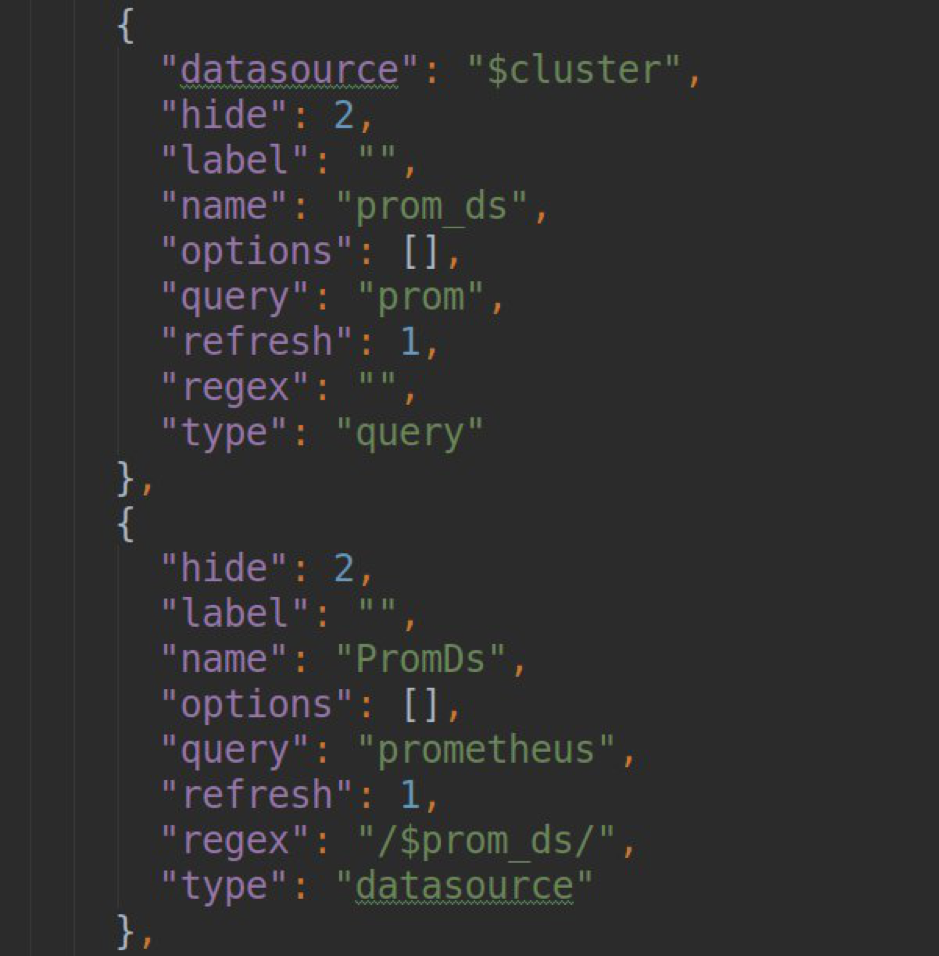
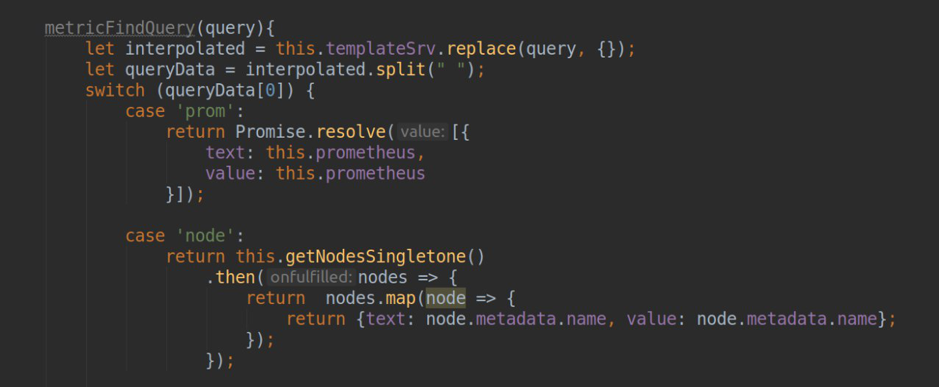
testDatasource(){ let url = '/api/v1/namespaces'; let _url = this.url; if(this.accessViaToken) _url += '/__proxy'; _url += url; return this.backendSrv.datasourceRequest({ url: _url, method: "GET", headers: {"Content-Type": 'application/json'} }) .then(response => { if (response.status === 200) { return {status: "success", message: "Data source is OK", title: "Success"}; }else{ return {status: "error", message: "Data source is not OK", title: "Error"}; } }, error => { return {status: "error", message: "Data source is not OK", title: "Error"}; }) }
我们认为,另一个有趣的问题是数据源身份验证和授权机制的实现。 通常,开箱即用地配置对最终数据源的访问,我们可以使用内置的Grafana组件-datasourceHttpSettings。 使用此组件,我们可以通过指定url和基本身份验证/授权设置(登录密码或client-cert / client-key)来配置对http数据源的访问。 为了实现使用承载令牌(实际上是k8s的标准)配置访问的能力,我不得不做一点“化学”操作。
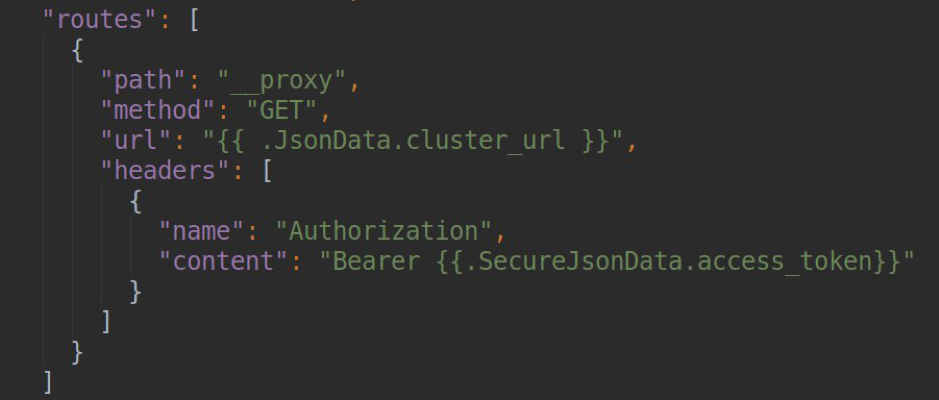
要解决此问题,您可以使用Grafana的内置“插件路由”机制(更多信息请参见
官方文档页面 )。 在数据源的设置中,我们可以声明一组路由规则,这些规则将由grafana代理服务器处理。 例如,对于每个单独的端点,都可以将标头或url附加为模板的能力,可以从jsonData和secureJsonData字段(用于以加密形式存储密码或令牌)获取数据。 在我们的示例中,形式为
/ __ proxy / api / v1 /名称空间的请求将被代理到形式的url
<your_k8s_api_url> / api / v1 /具有Authorization:Bearer标头的名称空间。
自然地,要使用k8s api服务器,我们需要一个具有只读访问权限的用户,以及用于创建清单的用户,您也可以在
插件的
源代码中找到该清单。
第5部分:发布

在为Grafana编写自己的插件之后,您自然会希望将其放入公共领域。 Grafana是一个可在
grafana.com/grafana/plugins上使用的插件库
为了使您的插件在官方商店中可用,您需要通过在repo.json文件中添加以下内容来在
此存储库中执行PR:
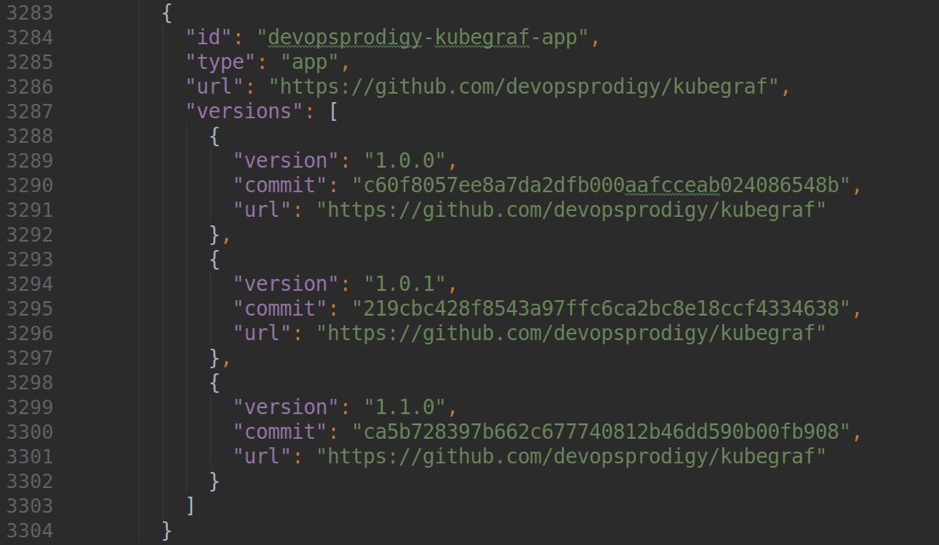
其中version是您插件的版本,url是存储库的链接,commit是提交的哈希,通过该哈希可以使用特定版本的插件。
在出口处,您将看到一张精美的表格:
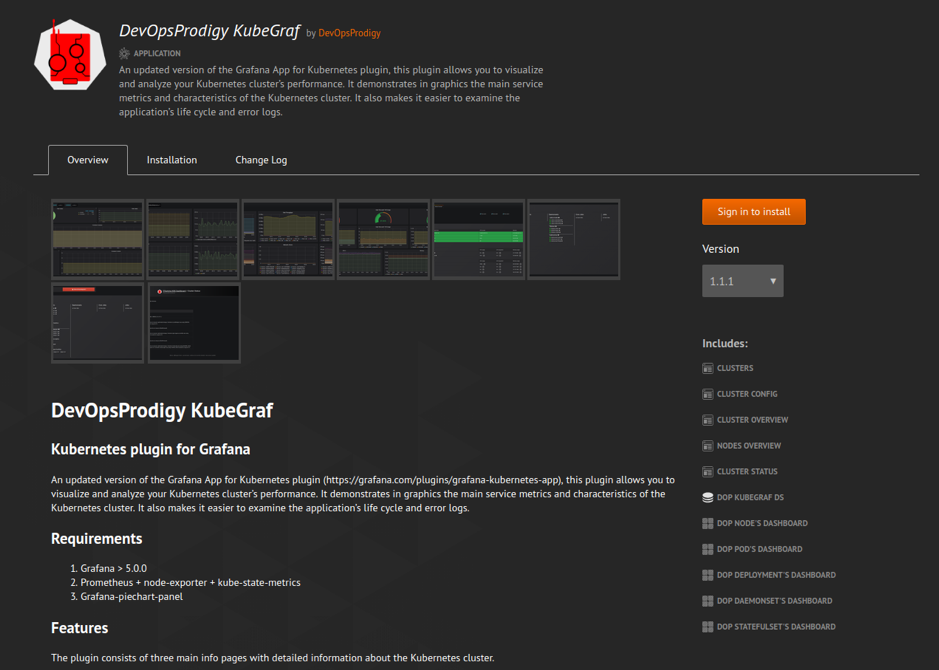
它的数据将自动从您的Readme.md,Changelog.md和带有插件说明的plugin.json文件中获取。
第六部分:代替结论
发布后,我们没有停止开发插件。 现在,我们正在努力正确监控群集节点资源的使用情况,引入新功能以增加UX,以及在安装客户端和github上的ishui插件后收到的大量反馈(如果您留下问题或请求,我我会很高兴的:-))。
我们希望本文将帮助您了解Grafana这样的出色工具,并可能编写自己的插件。
谢谢!)