有许多方法可以测试API和接口。 随着对Acronis网络平台的广泛访问的开放,我们被迫寻找从各个位置测试服务“持久性”的方法。 在这篇文章中,Acronis首席软件架构师Dmitry Salomatin谈论了我们如何选择测试框架,遇到的困难以及我们必须做的改进。

我必须马上说,Acronis的我们在测试API时特别小心。 事实上,我们自己的产品通过用于连接外部系统的相同API来访问服务。 因此,需要对每个接口进行性能测试。 我们测试API的操作,并单独隔离UI的操作。 测试结果将使您能够评估API本身以及用户界面是否运行良好。 确认成功的开发或制定进一步开发的任务。
但是测试有所不同。 有时,服务不会立即显示降级。 即使我们运行的服务类似于该版本中已经发布的产品,为了进行验证,您也可以使用“在产品中”使用的相同数据加载该服务。 在这种情况下,您可以看到回归,但是绝对不可能评估透视图。 您根本不知道如果数据量急剧增加或请求频率增加,将会发生什么。
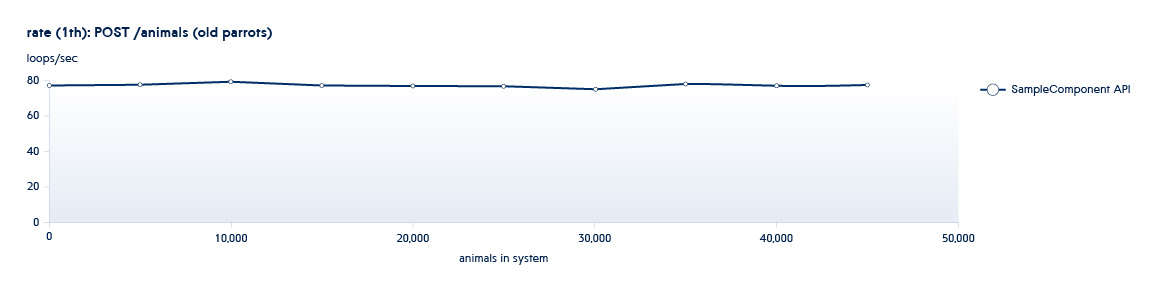
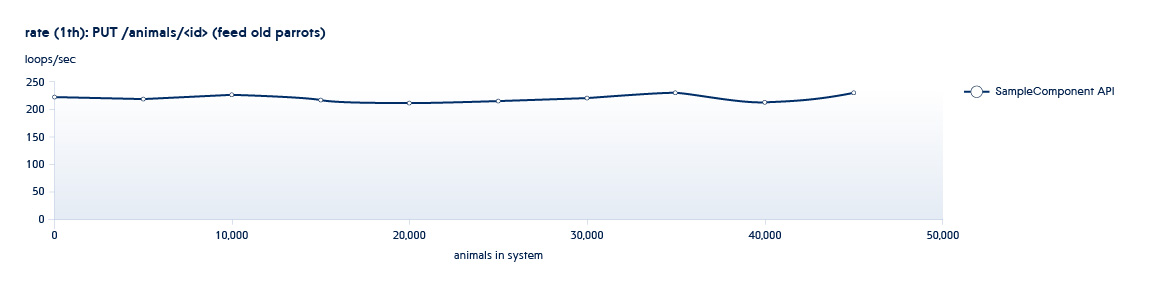
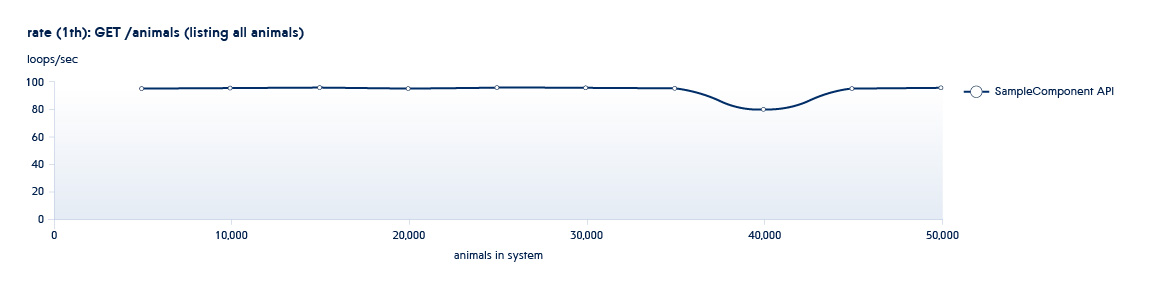
下图显示了每秒后端处理的API数量如何随着系统中数据的增长而变化

假设我们正在测试的服务处于此计划开始时的典型状态。 在这种情况下,即使系统的增长很小,该API的速度也会急剧下降。
为了排除这种情况,我们增加了数倍的数据量,增加了并行线程的数量,以了解如果负载急剧增加,服务将如何运行。
但是还有一点细微差别。 如果“熟悉的”服务的工作随着数据量的增加而改变,它的发展,新功能的出现,新服务的出现将使情况变得更加复杂。 当概念上新的服务出现在产品中时,需要从许多不同的角度来考虑它。 对于这种情况,您需要准备特殊的数据集,进行负载测试,并提出可能的用例。
Acronis中的性能测试功能
通常,我们的测试过程以“螺旋模式”进行。 测试阶段之一涉及使用API增加实体数量(调整大小),第二阶段涉及对现有数据集执行新操作(使用)。 所有测试都在不同数量的线程中运行。 例如,我们有动物服务,它具有以下API:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1和2是在大小调整测试中调用的API-它们增加了系统中新实体的数量。
3是在使用阶段调用的API。 该API有大量的过滤选项。 因此,将有不止一个测试
因此,通过运行迭代的大小调整和使用测试,我们可以了解系统性能随着其增长而发生的变化。

需要的框架...
为了对大量新服务和更新服务进行大规模测试,我们需要一个灵活的框架来允许我们运行不同的脚本。 最主要的是真正地测试API,而不仅仅是通过重复操作在服务上创建负载。
性能测试可以在合成负载上进行,也可以使用生产中记录的负载模式进行。 两种方法各有利弊。 实际负载的方法可以更严格地描述为压力测试-我们可以真实地了解这种负载下系统的性能,但是我们无法轻松识别问题区域,单独测量组件的吞吐量,也无法获得各个组件可以承受的负载的确切数字。 在综合方法的情况下,我们可以获得准确的数字,具有很大的灵活性,并且我们可以轻松地解决问题区域,并且通过并行运行多个测试脚本,我们可以重现压力负荷。 第二种方法的主要缺点是编写测试脚本的人工成本较高,并且缺少某些重要脚本的风险也越来越大。 因此,我们决定走更困难的道路。
因此,框架的选择由任务决定。 我们的任务是:
- 查找API瓶颈
- 检查对高负载的抵抗力
- 随着数据量的增长评估服务的有效性
- 确定随着时间的推移发生的累积错误
市场上有太多的性能框架可以触发大量相同的请求。 其中许多不允许更改内部任何内容(例如Apache Benchmark)或描述脚本的功能有限(例如JMeter)。
我们通常在测试中使用更复杂的脚本。 通常,API调用需要依次进行-一个接一个,或者根据某种逻辑更改请求参数。 我们想要测试以下形式的REST API的最简单示例
PUT /endpoint/resource/<id>
在这种情况下,您需要预先知道我们要更改的资源的<id>,以便测量净查询执行时间。
因此,我们需要具有创建脚本以运行复杂的测试查询的能力。
快一点
由于Acronis产品是为高负载而设计的,因此我们正在每秒处理数万个请求中的API。 事实证明,并非每个框架都可以做到这一点。 例如,Python并不总是也并非总是可以用于测试,因为由于语言的特殊性,创建大型多线程负载的能力受到限制
另一个问题是资源的使用。 例如,我们首先研究了Locust框架,该框架可以同时从多个硬件节点运行并获得良好的性能。 但是,与此同时,在测试系统的工作上花费了大量资源,并且操作成本很高。
结果,我们选择了K6框架,该框架使我们能够用成熟的Javascript描述脚本,并提供高于平均水平的性能。 这个框架是用Go编写的,并且正在迅速普及。 例如,在Github上,该项目已经获得了近5.5千颗星! K6正在积极开发中,社区已经提出了将近3000次提交,该项目有50个贡献者,他们创建了36个代码分支。 当然,K6距离理想还差得远,但是框架逐渐变得更好,您可以
在此处阅读有关它与Jmeter的比较。
难点及其解决方案
考虑到K6的“青春”,即使在合理选择框架之后,我们仍然面临许多问题。 例如,在测试/端点/之类的API之前,必须首先以某种方式找到这些端点。 我们不能使用相同的值,因为由于缓存,结果将不正确。
您可以通过不同的方式获取所需的数据:
第二种方法工作更快,并且在使用关系数据库时,它通常会变得更加方便,因为它可以使您在冗长的测试中节省大量时间。 唯一的“但是”是只有在服务代码和测试是由同一个人编写的情况下才可以使用它。 因为要遍历数据库,所以测试必须始终是最新的。 但是,对于K6,该框架没有对数据库的访问机制。 因此,我必须自己编写适当的模块。
测试非幂等API时会出现另一个问题。 在这种情况下,使用相同的参数(例如DELETE API)仅调用它们一次非常重要。 在我们的测试中,我们在系统设置和准备阶段的设置阶段预先准备测试数据。 在测试过程中,由于不再需要时间和资源来准备数据,因此测量是通过纯API调用进行的。 但是,这带来了在主测试的非同步流之间分配预先准备的数据的问题。 通过写入内部数据队列,此问题已成功解决。 但这是一个很大的话题,我们将在下一篇文章中讨论。
就绪框架
总结一下,我想指出,要找到一个完整的现成的框架并不容易,而且我仍然需要用手完成一些工作。 尽管如此,今天我们有一个适合我们的工具,考虑到这些改进,它使我们能够执行复杂的测试,创建高负载的模拟,以保证API和GUI在不同条件下的功能。
在下一篇文章中,我将讨论如何解决测试服务的问题,该服务支持使用最少的资源同时连接数十万个连接。