大家好! 我的名字叫弗拉德(Vlad),我是Tinkoff语音技术团队的数据科学家,该语音技术用于我们的语音助手Oleg。
在本文中,我想简要概述一下行业中使用的语音合成技术,并分享我们团队在构建自己的合成引擎方面的经验。

语音合成
语音合成是基于文本的声音的创建。 今天,这个问题可以通过两种方法解决:
- 单位选择[1]或串联方法。 它基于粘贴录制的音频片段。 自90年代末以来,长期以来一直将其视为开发语音合成引擎的事实上的标准。 例如,可以在Siri [2]中找到通过单位选择方法发出的声音。
- 参数语音合成[3],其实质是建立一个概率模型,该模型预测给定文本的音频信号的声学特性。
单元选择模型的语音质量高,变异性低,并且需要大量数据进行训练。 同时,对于训练参数模型,需要的数据量要少得多,它们会产生更多的音调,但是直到最近,与单位选择方法相比,它们的总体音质仍然很差。
但是,随着深度学习技术的发展,参数综合模型在所有质量指标上均取得了显着增长,并且能够创建与人类语音几乎无法区分的语音。
质量指标
在讨论哪种语音合成模型更好之前,您需要确定比较算法的质量指标。
由于可以以多种方式阅读同一文本,因此不存在先验正确的发音特定短语的方式。 因此,语音合成质量的度量通常是主观的,并且取决于听众的感知。
标准度量标准是MOS(平均意见评分),这是评估人员针对合成音频所做的语音自然程度的平均评估,范围为1到5。一种表示完全令人难以置信的声音,五种表示与人类没有区别的语音。 真实的人记录通常约为4.5,大于4的值被认为是很高的。
语音合成如何工作
建立任何语音合成系统的第一步是收集数据进行训练。 通常,这些是高品质音频录音,播音员在其中读取特别选择的短语。 训练单元选择模型所需的数据集的大概大小是10–20小时的纯语音[2],而对于神经网络参数方法,上限大约是25小时[4,5]。
我们讨论了两种合成技术。
单位选择
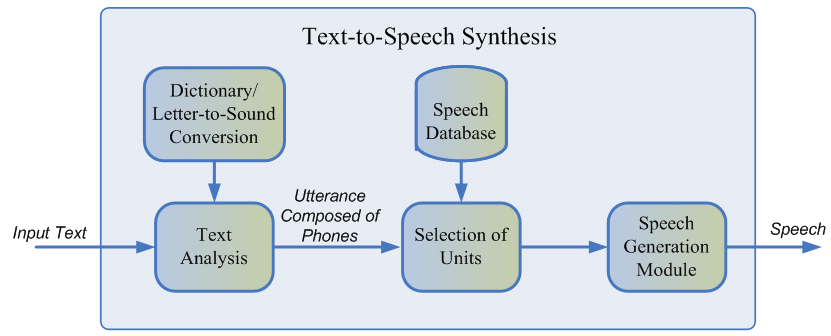
通常,说话者的录制语音无法涵盖将使用合成的所有可能情况。 因此,该方法的本质是将整个音频库分成称为单元的小片段,然后使用最少的后处理将它们粘合在一起。 单位通常是最小的声学语言单位,例如半音或双音[2]。
整个生成过程包括两个阶段:NLP前端(负责提取文本的语言表示形式)和后端(计算给定语言特征的单位惩罚函数)。 NLP前端包括:
- 规范文本的任务是将所有非字母字符(数字,百分号,货币等)翻译成它们的口头表达。 例如,“ 5%”应转换为“ 5%”。
- 从规范化的文本中提取语言特征:音素表示,重音,词性等。
通常,使用针对特定语言的手动规定规则来实现NLP前端,但是最近对使用机器学习模型的偏见有所增加[7]。
后端子系统估计的代价是目标成本或特定音素的单元声学表示与串联成本(即连接两个相邻单元的适当性)的对应关系之和。 为了评估精细函数,可以使用规则或已经训练过的参数合成声学模型[2]。 从上述罚分的角度来看,选择最佳的单位序列是使用维特比算法[1]进行的。
用于英语的MOS单位选择模型的近似值:3.7-4.1 [2、4、5]。
单位选择方法的优点:
- 自然的声音。
- 高速生成。
- 小型模型-这使您可以直接在移动设备上使用综合。
缺点:
- 合成语音是单调的,不包含情绪。
- 特征粘合工件。
- 它需要足够大的音频数据训练基础,以涵盖各种情况。
- 原则上,它不能产生训练集中找不到的声音。
参数语音合成
参数化方法基于构造一个概率模型的想法,该模型估计给定文本的声音特征的分布。
参数合成中的语音生成过程可以分为四个阶段:
- NLP前端与单元选择方法处于数据预处理的同一阶段,其结果是大量上下文相关的语言功能。
- 预测音素持续时间的持续时间模型。
- 一种声学模型,可恢复声学特征在语言特征上的分布。 声学特征包括基频值,信号的频谱表示等。
- 声码器将声学特征转换为声波。
对于训练持续时间和声学模型,可以使用隐藏的马尔可夫模型[3],深度神经网络或其递归变量[6]。 传统的声码器是基于源滤波器模型[3]的算法,它假定语音是对原始信号应用线性噪声滤波器的结果。
由于存在大量关于声音生成过程结构的独立假设,因此经典参数方法的总体语音质量非常低。
但是,随着深度学习技术的出现,训练直接通过字母预测声音符号的端到端模型成为可能。 例如,神经网络Tacotron [4]和Tacotron 2 [5]使用seq2seq算法[8]输入字母序列并返回粉笔频谱图。 因此,经典方法的步骤1-3被单个神经网络取代。 下图显示了Tacotron 2网络的架构,该架构可实现足够高的声音质量。
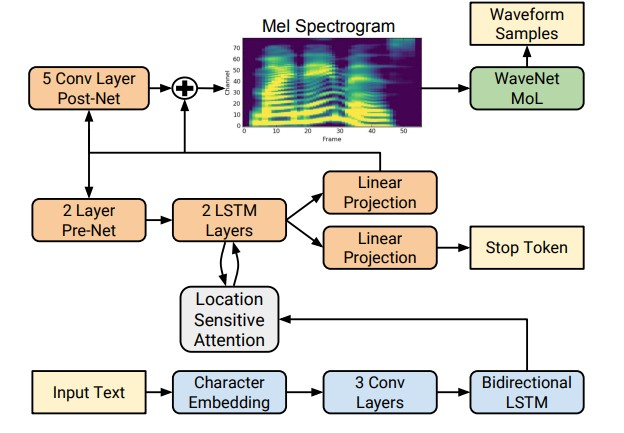
合成语音质量显着提高的另一个因素是使用神经网络声码器而不是数字信号处理算法。
第一个这样的声码器是WaveNet神经网络[9],它依次逐步地预测声波的幅度。
由于在网络体系结构中使用大量带间隙的卷积层来捕获更多上下文并跳过连接,因此与单元选择模型相比,MOS可以实现约10%的改进。 下图显示了WaveNet网络的体系结构。

WaveNet的主要缺点是与串行信号采样电路相关的低速。 这个问题可以通过对特定铁结构进行工程优化来解决,也可以通过用更快的采样方案代替采样方案来解决。
两种方法均已在业界成功实施。 第一种是在Tinkoff.ru,第二种方法是Google在2017年引入了Parallel WaveNet [10]网络,其成果已在Google Assistant中使用。
用于神经网络方法的MOS近似值:4.4–4.5 [5,11],也就是说,合成语音实际上与人类语音没有区别。
参数综合的优点:
- 使用端到端方法时,声音自然流畅。
- 语调变化更大。
- 使用的数据少于单位选择模型。
缺点:
Tinkoff语音合成的工作原理
从评论中可以看出,基于神经网络的参量语音合成方法目前在质量上明显优于单位选择方法,并且更易于开发。 因此,我们使用它们来构建自己的综合引擎。
对于训练模型,使用了大约25个小时的专业演讲者纯语音。 阅读文本是经过特别选择的,以便最全面地涵盖口语的语音。 另外,为了给语调中的合成增加更多种类,我们要求播音员根据上下文阅读带有表达式的文本。
我们的解决方案的架构在概念上看起来像这样:
- NLP前端,包括神经网络文本规范化和用于放置停顿和压力的模型。
- Tacotron 2接受字母作为输入。
- 自回归WaveNet,在CPU上实时工作。
借助这种架构,我们的引擎可以实时生成高质量的表达性语音,无需构建音素词典,并可以控制单个单词的重音。 单击链接可以听到合成音频的示例。
参考文献:
[1] AJ Hunt,AW Black。 使用大型语音数据库的级联语音合成系统中的单元选择,ICASSP,1996年。
[2] T. Capes,P。Coles,A。Conkie,L。Golipour,A。Hadjitarkhani,Q。Hu,N。Huddleston,M。Hunt,J。Li,M。Neeracher,K。Prahallad,T。Raitio R. Rasipuram,G。Townsend,B。Williamson,D。Winarsky,Z。Wu,H。Zhang。 Siri装置深度学习指导的单位选择文本转语音系统,Interspeech,2017年。
[3] H. Zen,K。Tokuda,AW Black。 统计参量语音合成,语音通信,第一卷。 51号 11页。 1039-1064,2009年。
[4]王玉轩,RJ Skerry-Ryan,黛西·斯坦顿,吴永辉,Ron J. Weiss,Navdeep Jaitly,杨宗衡,应晓,陈志峰,Samy Bengio,Quoc Le,Yannis Agiomyrgiannakis,Rob Clark,Rif A. Saurous 。 Tacotron:走向端到端语音合成。
[5]沉乔纳,庞若鸣,罗恩·韦斯,迈克·舒斯特,纳维普·杰伊特,杨宗衡,陈志峰,张宇,王玉轩,RJ Skerry-Ryan,Rif A. Saurous,Yannis Agiomyrgiannakis,Yonghui Wu。 通过基于梅尔谱图预测的WaveNet进行自然TTS合成。
[6] Heiga Zen,Andrew Senior,Mike Schuster。 使用深度神经网络的统计参数语音合成。
[7]张浩,Richard Sproat,Axel H. Ng,Felix Stahlberg,彭小昌,Kyle Gorman,Brian Roark。 用于语音应用的文本规范化的神经模型。
[8] Ilya Sutskever,Oriol Vinyals,Quoc V. Le。 使用神经网络进行序列学习。
[9]亚伦·范·登·奥尔德(Aaron van den Oord),桑德·迪勒曼(Sander Dieleman),海加·禅(Heiga Zen),凯伦·西蒙延(Karen Simonyan),奥里尔·维尼亚尔斯(Oriol Vinyals),亚历克斯·格雷夫斯(Alex Graves),纳尔·卡奇布伦纳(Nal Kalchbrenner),安德鲁·安德鲁(Andrew Senior),科雷·卡武库库鲁(Koray Kavukcuoglu)。 WaveNet:原始音频的生成模型。
[10]亚伦·范·登·奥尔德,亚兹·李,伊戈尔·巴布希金,凯伦·西蒙扬,奥利奥尔·维尼亚尔斯,科雷·卡武库库鲁,乔治·范·登·德里斯彻,爱德华·洛克哈特,路易斯·科博,弗洛里安·斯提姆伯格,诺曼·卡萨格兰德,多米尼克·格雷威,塞伯·努里,桑德·迪勒曼,埃里希·艾尔森(Erich Elsen),纳尔·卡尔奇布伦纳(Nal Kalchbrenner),海加·禅(Heiga Zen),亚历克斯·格雷夫斯(Alex Graves),海伦·金(Helen King),汤姆·沃尔特斯(Tom Walters),丹·贝洛夫(Dan Belov),黛米·哈萨比斯(Demis Hassabis) 并行WaveNet:快速的高保真语音合成。
[11]魏萍,开南,彭继同,陈Ji。 ClariNet:端到端文本到语音中的并行波生成。
[12] Dario Rethage,Jordi Pons,Xavier Serra。 语音去噪的Wavenet。