.NET Core的性能

大家好! 本文是最佳实践的集合,我和我的同事在从事不同的项目时已经使用了很长时间。
有关在其上执行计算的机器的信息:BenchmarkDotNet = v0.11.5,操作系统= Windows 10.0.18362
英特尔酷睿i5-8250U CPU 1.60GHz(Kaby Lake R),1个CPU,8个逻辑和4个物理核心
.NET Core SDK = 3.0.100
[主机] :. NET Core 2.2.7(CoreCLR 4.6.28008.02,CoreFX 4.6.28008.03),64位RyuJIT
核心:.NET Core 2.2.7(CoreCLR 4.6.28008.02,CoreFX 4.6.28008.03),64位RyuJIT
[主机]:.NET Core 3.0.0(CoreCLR 4.700.19.46205,CoreFX 4.700.19.46214),64位RyuJIT
核心:.NET Core 3.0.0(CoreCLR 4.700.19.46205,CoreFX 4.700.19.46214),64位RyuJIT
作业=核心运行时=核心
ToList与ToArray和循环
我计划在.NET Core 3.0发行版中准备这些信息,但是它们领先于我,我不想盗用别人的名气并复制别人的信息,因此,我只想指出一篇
指向详细比较的好文章的
链接 。
就我自己而言,我只想向您展示我的测量和结果,我为喜欢“ C ++风格”编写循环的爱好者们添加了反向循环。
代码:public class Bench { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random random = new Random(); _list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForListFromEnd() { int total = 0;t for (int i = _list.Count-1; i > 0; i--) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } [Benchmark] public int ForArrayFromEnd() { int total = 0; for (int i = _array.Length-1; i > 0; i--) { total += _array[i]; } return total; } }
.NET Core 2.2和3.0的性能几乎相同。 这是我设法在.NET Core 3.0中获得的东西:
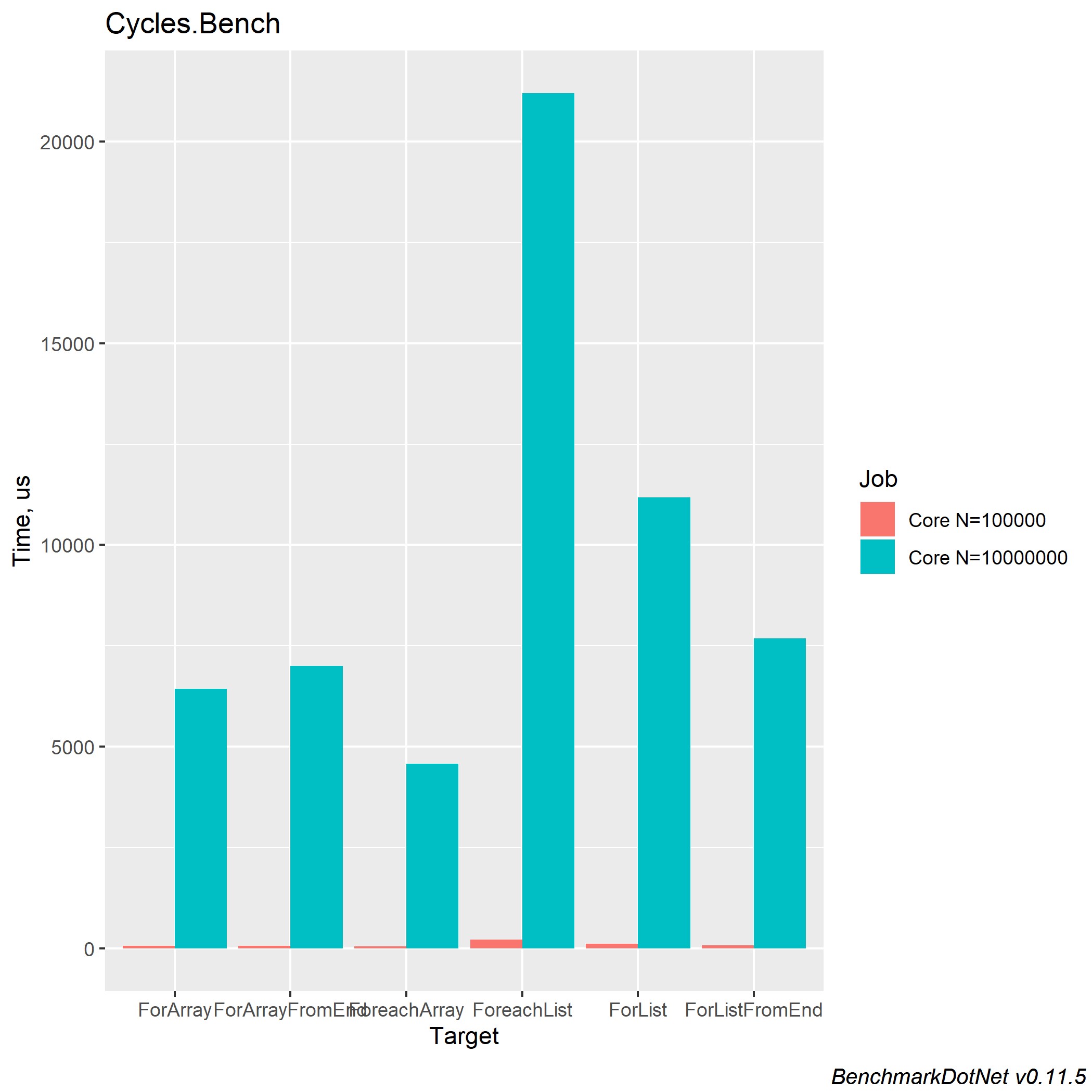
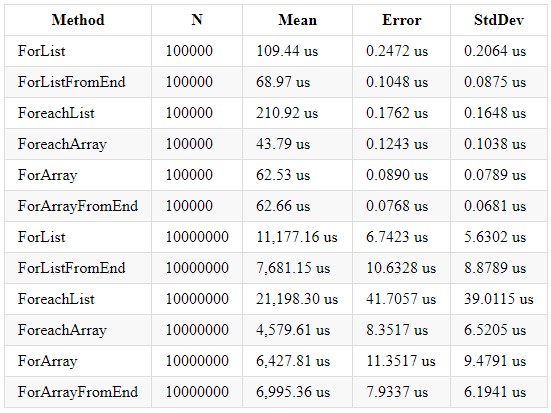
我们可以得出结论,由于Array类型的集合的内部优化和对集合大小的显式分配,因此对Array类型的集合进行循环处理的速度更快。 还值得记住的是List类型的集合有其优势,您应该根据必要的计算使用所需的集合。 即使您编写了使用循环的逻辑,也不要忘记这是一个普通的循环,并且还可能对循环进行优化。 一篇文章在habr上发表了很长时间:
https ://habr.com/en/post/124910/。 它仍然是相关的,建议阅读。
投掷
一年前,我在一家公司中处理一个旧项目,在那个项目中,通过try-catch-throw构造处理现场验证属于正常范围。 我已经知道这是该项目的不健康业务逻辑,因此我尝试尽可能不使用这种设计。 但是,让我们看看用这种设计来处理错误的不良方法是什么。 我编写了一些代码以比较这两种方法,并为每个选项拍摄了“基准”。
代码: public bool ContainsHash() { bool result = false; foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } return result; } public bool ContainsHashTryCatch() { bool result = false; try { foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } if(!result) throw new Exception("false"); } catch (Exception e) { result = false; } return result; }
.NET Core 3.0和Core 2.2中的结果具有相似的结果(.NET Core 3.0):
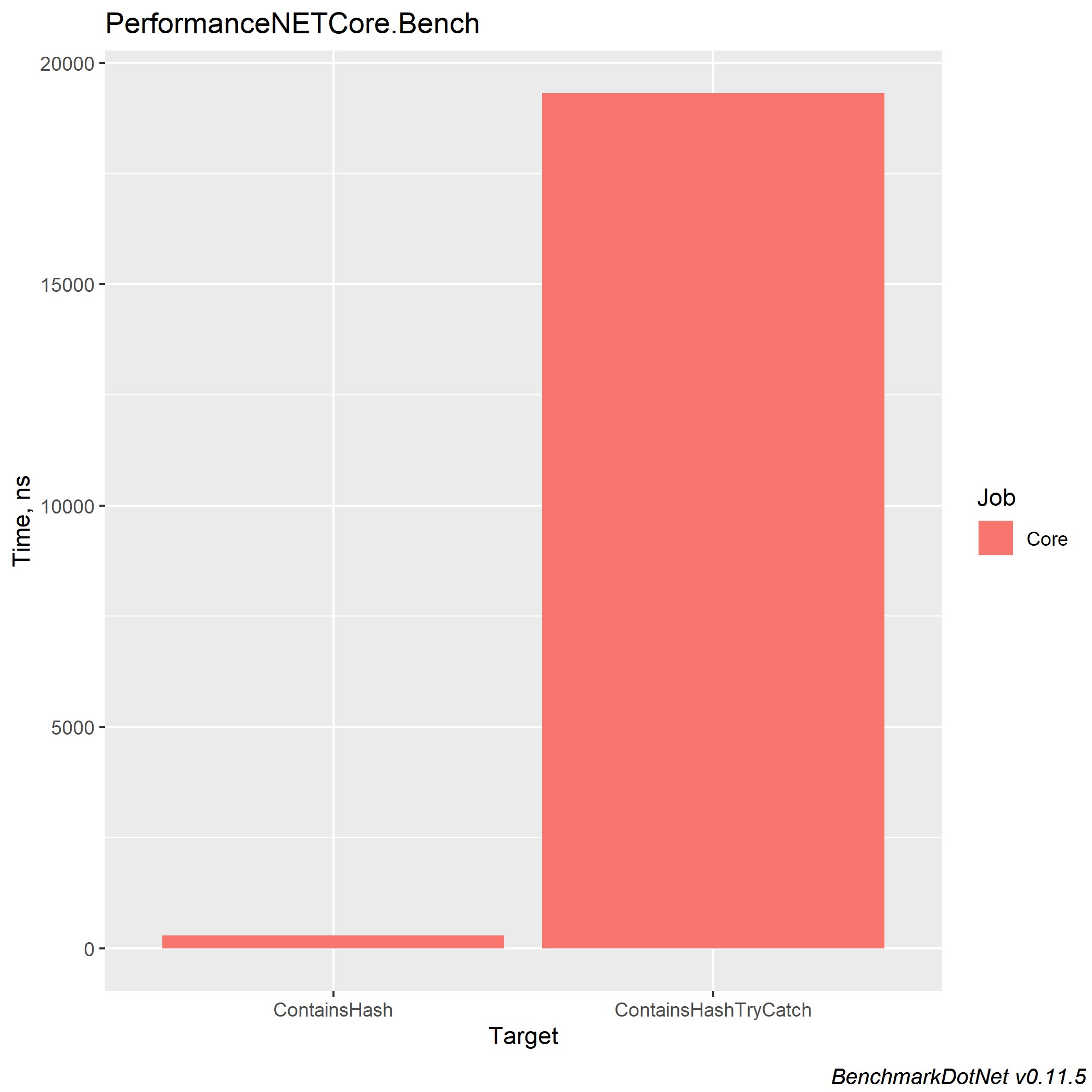
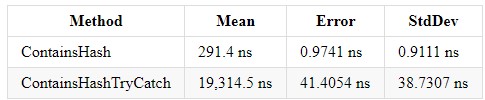
尝试catch会使对代码的理解变得复杂,并增加程序的执行时间。 但是,如果您需要这种结构,则不应插入不希望进行错误处理的代码行-这将有助于理解代码。 实际上,加载系统的不仅仅是异常处理,而是通过引发新的Exception构造本身引发错误。
引发异常比以所需格式收集错误的任何类慢。 如果您正在处理表单或任何数据,并且显然知道应该是什么错误,那么为什么不处理它呢?
如果这种情况不是特殊情况,则不应编写throw new Exception()。
处理和引发异常非常昂贵!ToLower,ToLowerInvariant,ToUpper,ToUpperInvariant
在.NET平台上的5年经验中,他遇到了许多使用字符串匹配的项目。 我还看到了下图:有一个带有许多项目的Enterprise解决方案,每个项目都以不同的方式执行字符串比较。 但是,什么值得使用以及如何统一呢? 在Richter通过C#编写的CLR中,我读到ToUpperInvariant()比ToLowerInvariant()快。
从书中剪下:

当然,我不相信,于是决定在.NET Framework上进行一些测试,结果令我震惊-性能提高了15%以上。 第二天一早到达工作地点,我就向我的上司展示了这些测量结果,并让他们访问了源。 此后,将14个项目中的2个更改为进行新的测量,并且考虑到存在这两个项目来处理巨大的excel表,结果对于该产品而言意义重大。
我还将介绍针对.NET Core不同版本的度量,以便每个人都可以朝着最佳解决方案的方向做出选择。 我只想在我工作的公司中添加,我们使用ToUpper()比较字符串。
代码: public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); } ; public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); }
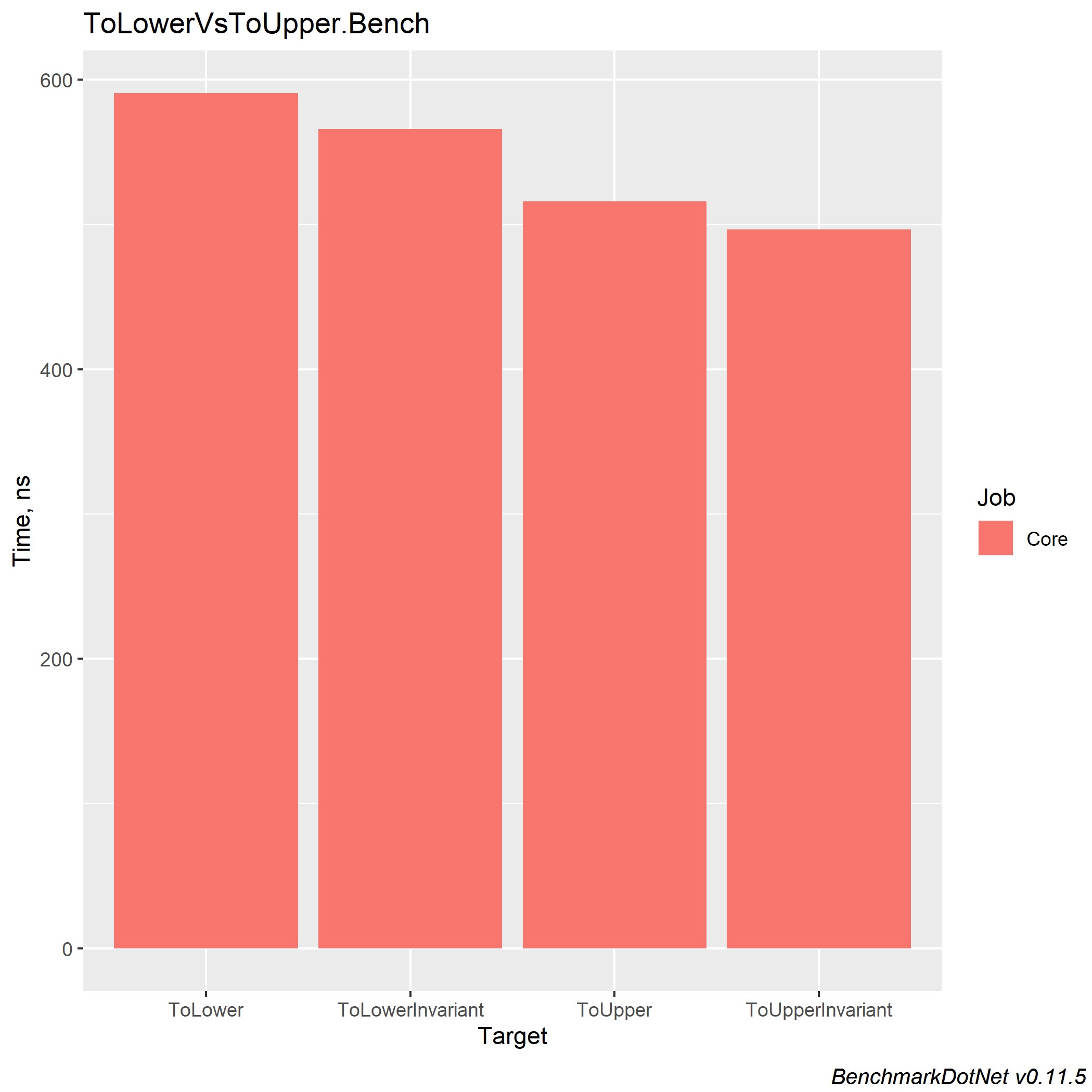
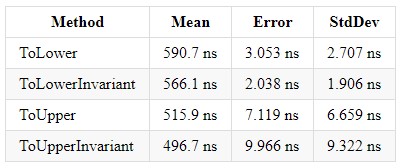
在.NET Core 3.0中,这些方法中的每种方法的收益约为x2,并且使它们之间的实现平衡。
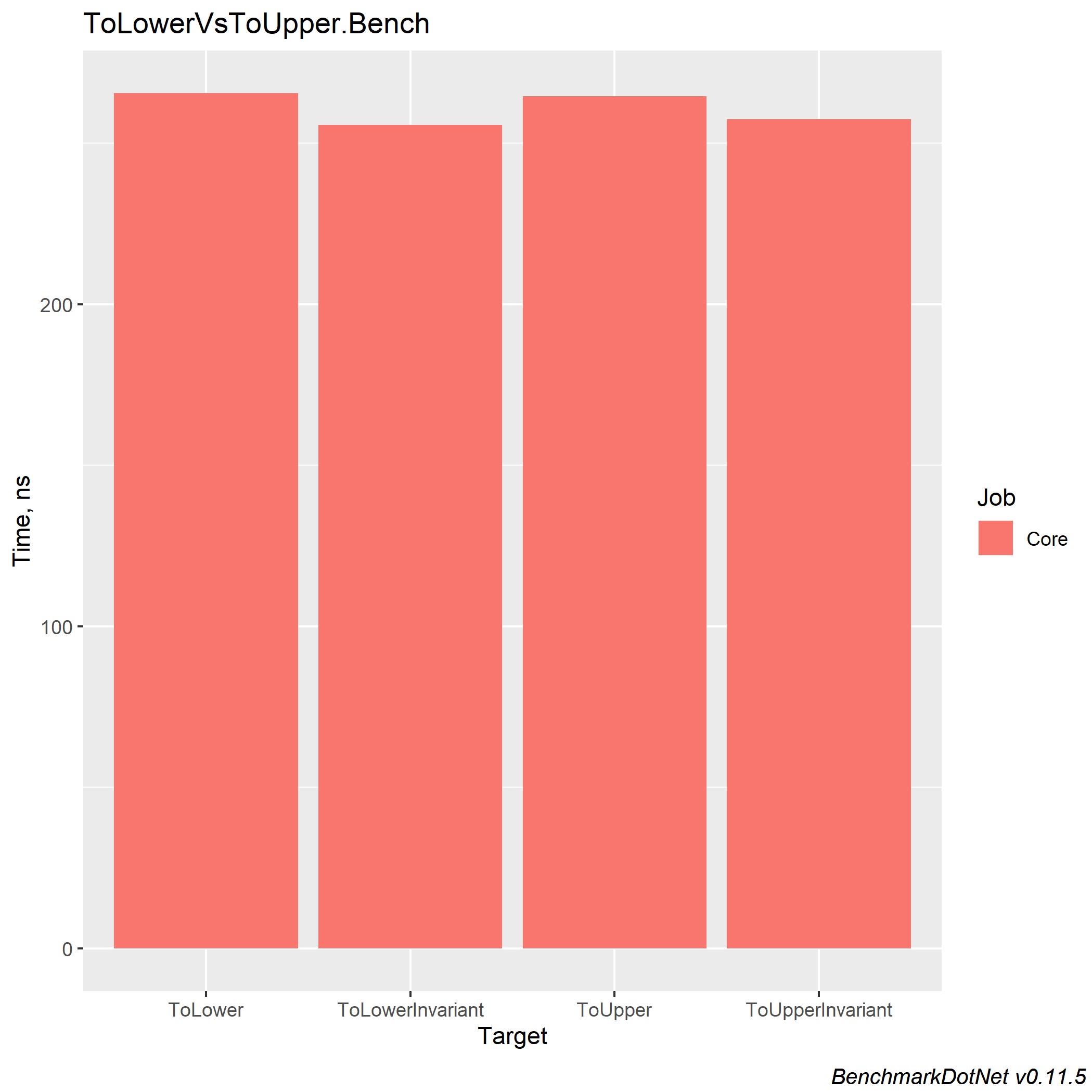
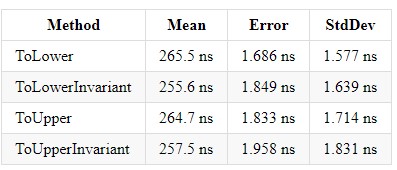
层编译
在上一篇文章中,我简要介绍了此功能,我想更正和补充我的话。 多层编译可加快解决方案的启动时间,但您会牺牲部分代码以在后台编译为更优化的版本,这可能会导致少量开销。 随着NET Core 3.0的出现,启用了层编译的项目的构建时间得以减少,并修复了与该技术相关的错误。 以前,该技术导致ASP.NET Core中的第一个请求出错,并在多级编译模式下的第一个构建期间冻结。 当前,它在.NET Core 3.0中默认为启用,但是您可以根据需要禁用它。 如果您是团队负责人,高级,中层或部门主管,则必须了解项目的快速发展会增加团队的价值,而这项技术将使您既节省开发人员时间,又节省项目工作时间。
.NET升级
升级.NET Framework / .NET Core。 通常,每个新版本都会提高性能并增加新功能。
但是究竟有什么好处呢? 让我们看看其中的一些:

结论
编写代码时,应注意项目的各个方面,并使用编程语言和平台的功能来达到最佳效果。 如果您分享有关.NET优化的知识,我将感到非常高兴。
Github链接