
计算机视觉中的神经网络正在积极发展,许多任务仍未解决。 要在您所在的领域成为潮流,只需关注Twitter上的影响者并在arXiv.org上阅读相关文章。 但是我们有机会参加了2019年国际计算机视觉会议(ICCV)。今年的会议在韩国举行。 现在,我们想与我们看到和学习的Habr读者分享。
Yandex中有许多人:无人驾驶汽车开发商,研究人员以及参与服务中CV任务的人员到达了。 但是现在我们想介绍一下我们团队的一个稍微主观的观点-机器智能实验室(Yandex MILAB)。 其他人可能从他们的角度看了会议。
实验室做什么我们进行与娱乐目的图像和音乐生成相关的实验项目。 我们对允许您更改用户内容的神经网络特别感兴趣(对于照片,此任务称为图像处理)。 YaC 2019大会的工作成果
示例 。
有许多科学会议,但最著名的所谓A *会议从中脱颖而出,通常会发表有关最有趣和最重要技术的文章。 没有确切的A *会议列表,这是一个示例且不完整:NeurIPS(以前为NIPS),ICML,SIGIR,WWW,WSDM,KDD,ACL,CVPR,ICCV,ECCV。 后三个专门研究CV主题。
ICCV一目了然:海报,教程,工作坊,展台
会议共接受论文1075篇,参会人数7500人,来自俄罗斯的103人,Yandex,Skoltech,莫斯科三星AI中心和萨马拉大学的员工发表了文章。 今年,访问ICCV的顶尖研究人员并不多,但在这里,例如总聚集了很多人的Alexey(Alyosha)Efros:

在所有此类会议上,文章均以海报的形式展示(
更多关于格式),而最好的文章也以简短报告的形式展示。
在教程中,您可以将自己沉浸在某个主题领域中,就像在大学里的讲座一样。 它是由一个人阅读的,通常不谈论特定作品。 示例示例很酷(
Michael Brown,《了解色彩和用于计算机视觉的相机内图像处理管道》 ):

相反,在研讨会上,他们谈论文章。 通常,这是在一个狭窄的主题中进行的工作,实验室负责人关于所有最新学生工作的故事,或者是主要会议上不接受的文章。
赞助公司带着展位来到ICCV。 今年,谷歌,Facebook,亚马逊和许多其他国际公司以及大量的初创公司(韩国和中国)到来。 特别是有很多专门从事数据标记的初创公司。 展位上有表演,您可以购买商品并提问。 赞助公司举行狩猎聚会。 如果说服招聘人员您感兴趣并且可以接受面试,他们就会继续努力。 如果您发表了一篇文章(或者用它进行了介绍),开始或结束了博士学位-这是一个加号,但是有时您可以在一个摊位上达成一致,向公司的工程师提出有趣的问题。
发展趋势
会议使您可以浏览整个简历区域。 通过特定主题的发帖者数量,您可以评估该主题的热度。 关键字得出一些结论:

零射,单射,少射,自我监督和半监督:长期研究问题的新方法
人们学会了更有效地使用数据。 例如,在
FUNIT中,您可以生成不在训练集中的动物的面部表情(在应用程序中应用几张参考图片)。 已经开发了Deep Image Prior的思想,现在可以在一张图中训练
GAN网络-我们将在稍后
的重点文章中对此
进行讨论 。 您可以使用自我监督进行预训练(解决可以合成对齐的数据(例如,预测图片的旋转角度)的问题),或者同时从标记的和未标记的数据中学习。 从这个意义上讲,可以将创造的皇冠视为
S4L:自我指导的半监督学习 。 但是在ImageNet
上进行预培训
并不总是有帮助。

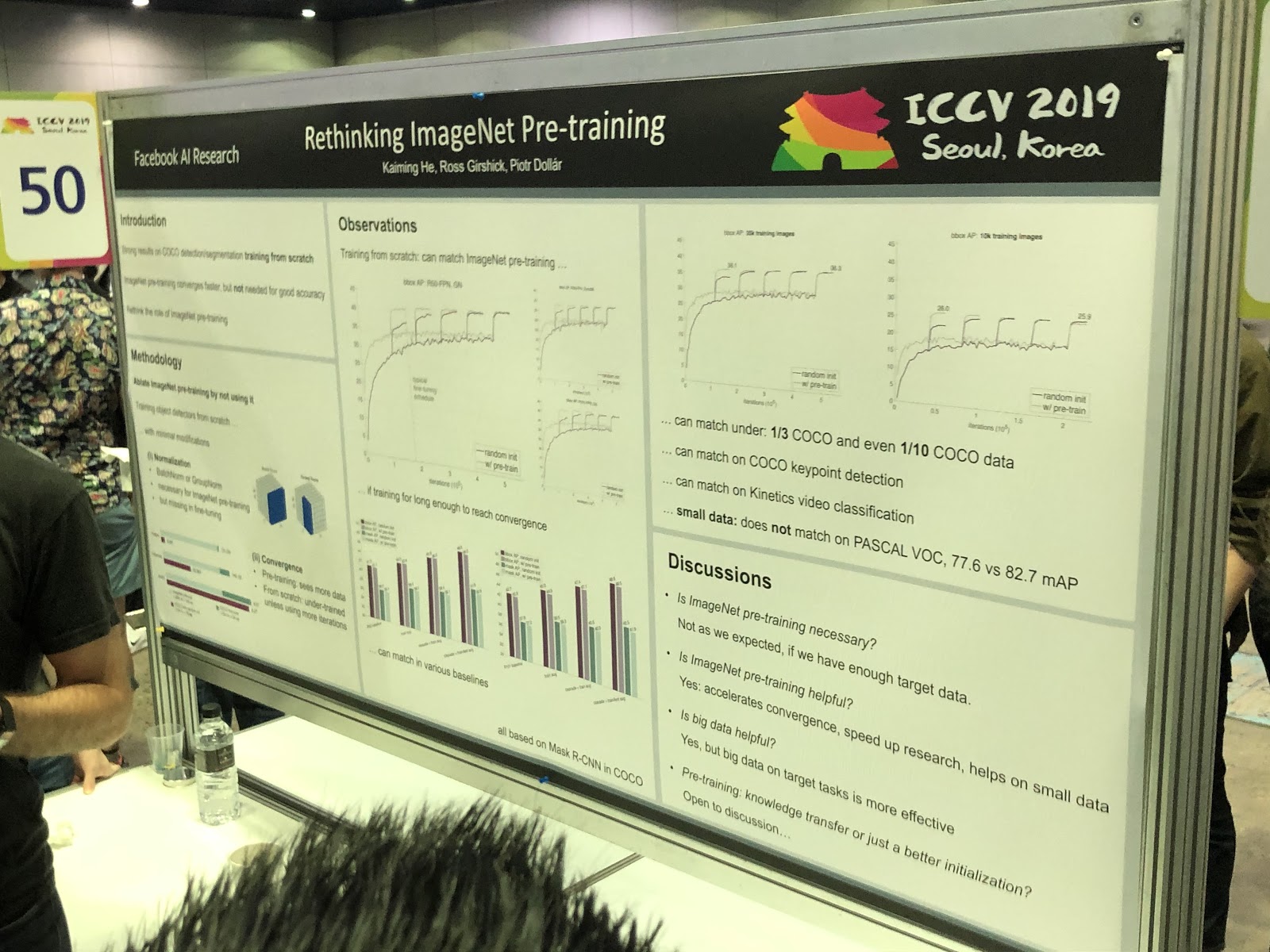
3D和360°
大多数任务是针对照片解决的(分割,检测)任务,需要对3D模型和全景视频进行更多研究。 我们看到了许多有关将RGB和
RGB-D转换为3D的文章。 如果我们使用三维模型,则可以更自然地解决某些任务,例如确定一个人的姿势(姿势估计)。 但是到目前为止,关于如何精确地表示3D模型(网格,点云,
体素或
SDF形式)尚无共识。 这是另一种选择:
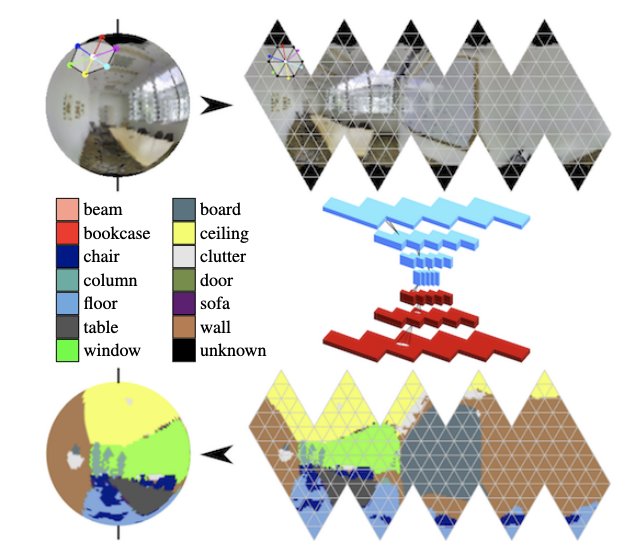
在全景图中,球体上的卷积正在积极发展(请参阅
二十面体球体上的面向
方向的语义分割 ),并在框架中搜索关键对象。
姿势的定义和人体运动的预测
为了确定2D姿态,已经取得了成功-现在的重点已转向使用多台摄像机和3D模式。 例如,您可以确定穿过墙壁的骨骼,跟踪Wi-Fi信号穿过人体时的变化。
在手关键点检测领域已经做了很多工作。 出现了新的数据集,包括基于带有两个人对话的视频的数据集-现在您可以通过对话的音频或文本来预测手势! 注视评估任务也取得了相同的进展。

您还可以突出显示与人体运动预测相关的大量作品(例如,
通过时空时空绘画进行人体运动预测或
结构化预测有助于3D人体运动建模 )。 这项任务很重要,根据与作者的对话,它最常用于分析自动驾驶中行人的行为。
在照片和视频,虚拟试衣间中操纵人
主要趋势是根据解释后的参数更改面部图像。 想法:一张照片上的
假照片,通过面部渲染更改表情(
PuppetGAN ),前馈更改参数(例如
age )。 样式转移已从主题标题移至应用程序工作。 另一个故事-虚拟试衣间,它们几乎总是工作不好,
这里是一个演示示例。


草图/图形生成
“让网格根据以前的经验产生一些东西”这一想法的发展已经变得与众不同:“让我们向网格展示哪些选项使我们感兴趣。”
SC-FEGAN允许您进行引导式修补:用户可以在图像的已擦除区域中绘制面部的一部分,并根据渲染获得还原的图像。

在25篇关于ICCV的Adobe文章中,有两种GAN结合在一起:一种为用户绘制草图,另一种从该草图生成逼真的图片(
项目页面 )。

在图像生成的早期,不需要图形,但现在它们已成为有关场景的知识的容器。 ICCV最佳论文荣誉奖也被授予“
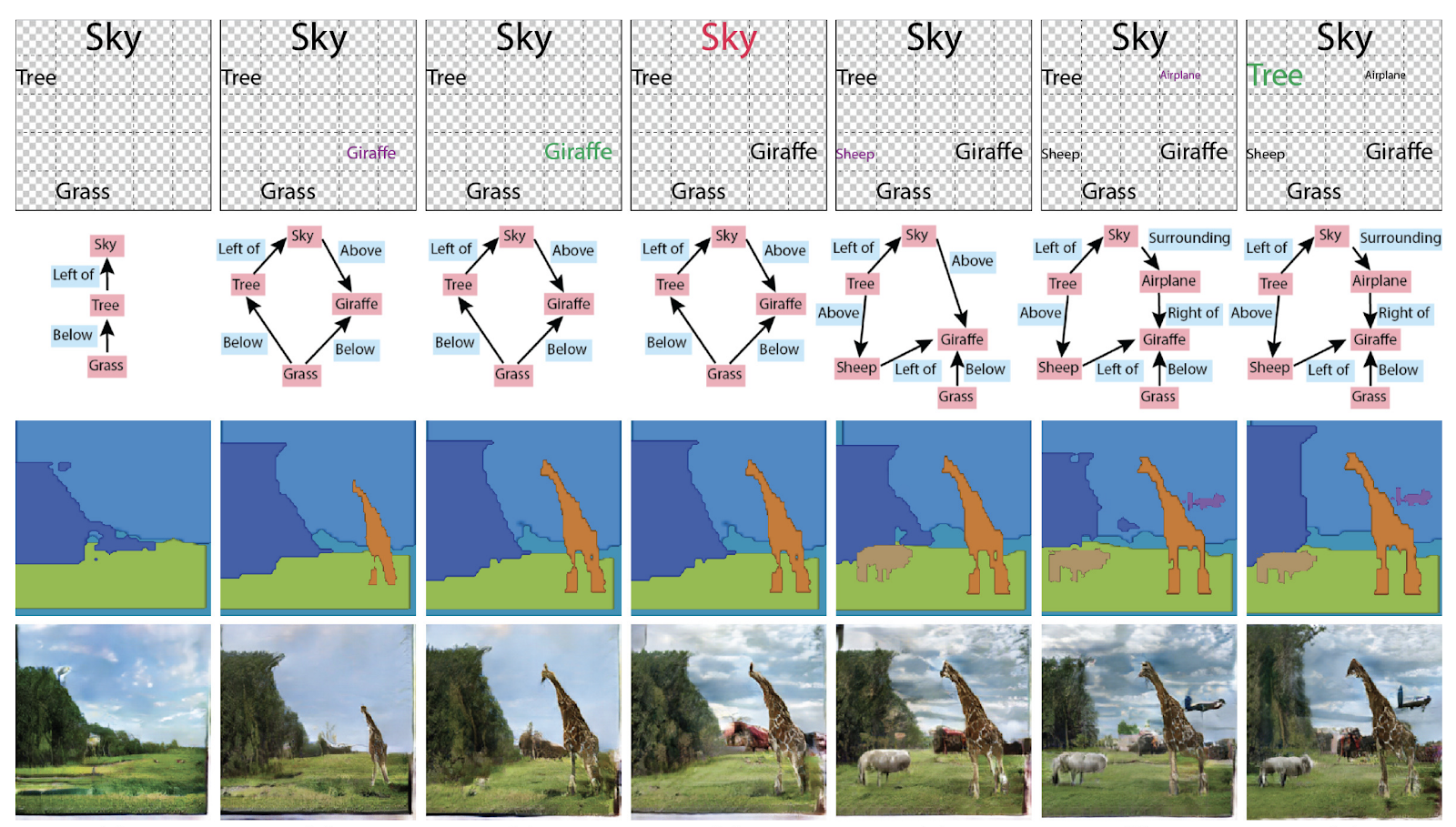
指定交互式场景生成中的对象属性和关系”一文 。 通常,您可以以不同的方式使用它们:根据图片生成图形,或者根据图形生成图形和文本。
重新识别人员和机器,计算人数(!)
许多文章致力于跟踪人员并
重新识别人员和机器。 但是令我们感到惊讶的是,有很多关于计数人群的文章,全部来自中国。
相反,Facebook将照片匿名化。 而且,它以一种有趣的方式做到了这一点:它教导神经网络生成没有唯一细节的人脸-相似但不那么多,以至于面部识别系统可以正确地检测到它。

对抗攻击防护
随着现实世界中计算机视觉应用的发展(在无人驾驶车辆中,在人脸识别中),这种系统的可靠性问题更加频繁地出现。 要充分利用CV,您需要确保系统能够抵抗对抗性攻击-因此,关于防御攻击的文章不少于关于攻击本身的文章。 许多工作是关于解释网络预测(显着性图)和衡量结果的可信度。
组合任务
在大多数只有一个目标的任务中,提高质量的可能性几乎用尽了;进一步提高质量的新领域之一是教神经网络同时解决多个相似的问题。 范例:
-动作预测+光流预测,
-视频演示+语言表示(
VideoBERT ),
-
超分辨率+ HDR 。
还有关于分割,确定动物的姿势和重新识别的文章!

重点介绍
几乎所有文章都是预先知道的,其文本可在arXiv.org上找到。 因此,诸如“每个人现在跳舞”,“ FUNIT”,“ Image2StyleGAN”之类的作品的呈现似乎很奇怪-这些是非常有用的作品,但根本不是新作品。 科学出版的经典过程似乎在这里失败了-科学发展太快了。
确定最佳作品非常困难-它们很多,主题不同。 几篇文章获得了
奖项和参考 。
我们希望突出显示在图像处理方面有趣的作品,因为这是我们的主题。 事实证明,它们对我们来说非常新鲜和有趣(我们不假装客观)。
SinGAN(最佳论文奖)和InGAN
SinGAN:
项目页面 ,
arXiv ,
代码 。
InGAN:
项目页面 ,
arXiv ,
代码 。
Dmitry Ulyanov,Andrea Vedaldi和Victor Lempitsky提出的“深层影像先验”概念的发展。 网络不是在数据集上训练GAN,而是从同一图片的片段中学习,以便记住其中的统计信息。 训练有素的网络使您可以编辑照片(SinGAN)和为其添加动画,或者从原始图像的纹理生成任何大小的新图像,同时保持本地结构(InGAN)。
辛甘:

英甘

看到GAN无法生成的内容
项目页面 。
图像生成神经网络通常会接收随机噪声向量作为输入。 在训练有素的网络中,许多输入矢量形成一个空间,很小的运动,沿着这些运动,导致图片的微小变化。 使用优化,您可以解决反问题:为现实世界中的图片找到合适的输入向量。 作者表明,几乎永远不可能在神经网络中找到完全匹配的图片。 图片中的某些对象未生成(显然,由于这些对象的变化很大)。
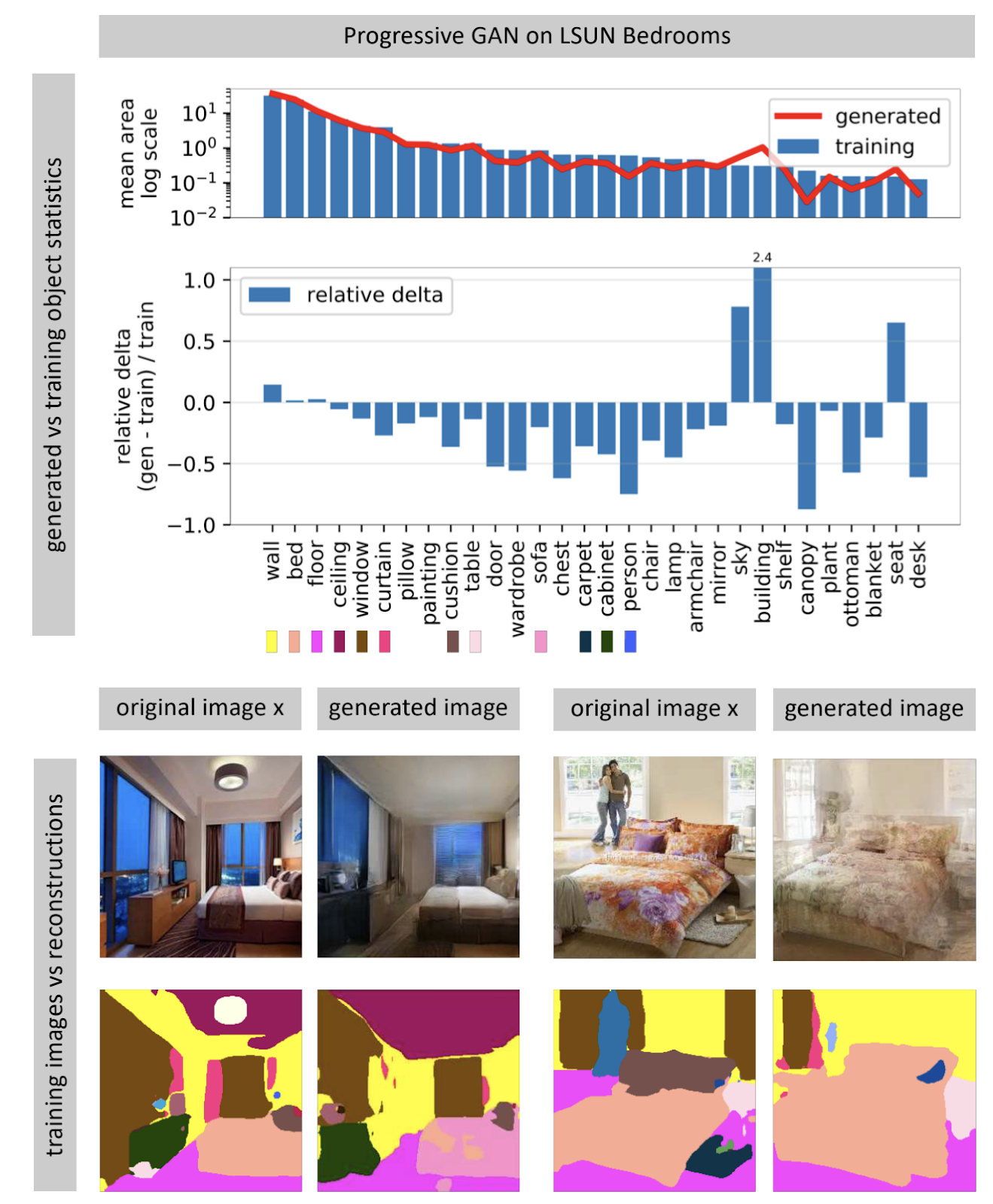
作者假设GAN不能覆盖图片的整个空间,而只能覆盖一些填充有孔的子集,例如奶酪。 当我们尝试从其中的真实世界中找到照片时,我们总是会失败的,因为GAN仍然无法生成真实的照片。 您仅通过更改网络的权重即可克服真实图像和生成图像之间的差异,即对特定照片进行重新训练。

当网络针对特定照片进行培训时,您可以尝试对此图像进行各种操作。 在下面的示例中,在照片中添加了一个窗口,网络还额外在厨房设备上产生了反射。 这意味着在进行摄影训练之后,网络不会失去查看场景对象之间连接的能力。

GANalyze:走向认知图像属性的视觉定义
项目页面 arXiv 。
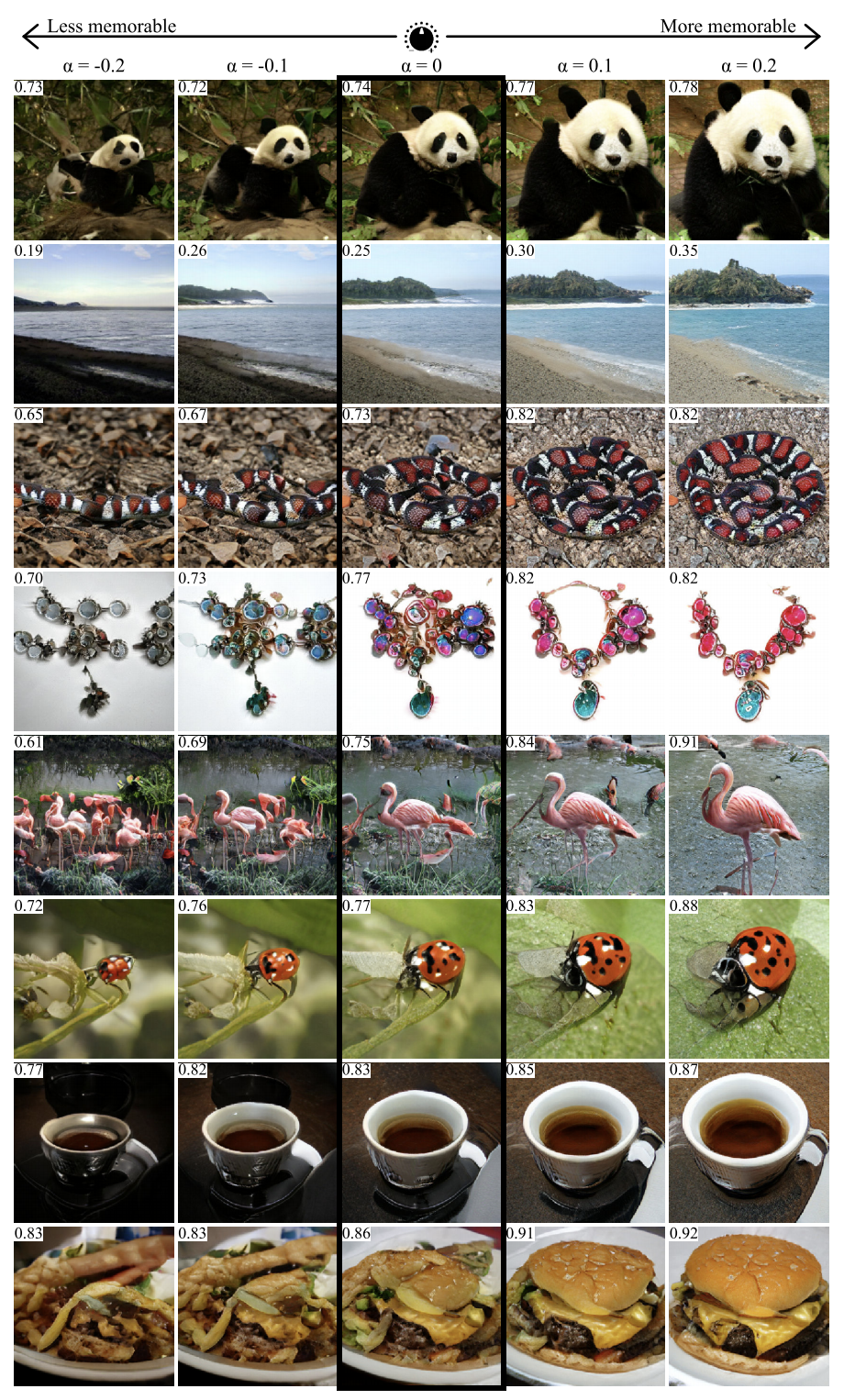
使用这项工作中的方法,您可以可视化和分析神经网络学到的知识。 作者建议对GAN进行训练,以创建网络将为其生成给定预测的图片。 文章中使用了几个网络作为示例,包括MemNet,它可以预测照片的记忆力。 事实证明,为了获得更好的记忆力,照片中的对象应:
- 靠近中心
- 具有圆形或方形且结构简单,
- 在统一的背景下,
- 包含富有表情的眼睛(至少用于狗的照片),
- 在某些情况下更明亮,更丰富-更红。
Liquid Warping GAN:模仿人体运动,外观转移和新颖视图合成的统一框架
项目页面 ,
arXiv ,
代码 。
用于从一张照片生成人照片的管道。 作者展示了将一个人的运动转移到另一个人,在人与人之间转移衣服并产生人的新观点的成功实例-所有这些都来自一张照片。 与先前的作品不同,此处创建条件的方式不是使用2D(姿势)中的关键点,而是使用身体的3D网格(姿势+形状)。 作者还弄清楚了如何将信息从原始图像传输到生成的图像(液体翘曲块)。 结果看起来不错,但最终图像的分辨率仅为256x256。 为了进行比较,一年前出现的vid2vid能够以2048x1024的分辨率生成,但与数据集一样,它需要多达10分钟的视频拍摄时间。

FSGAN:与对象无关的面部交换和重演
项目页面 arXiv 。
乍一看似乎没什么不寻常的:仿冒品或多或少都具有正常品质。 但这项工作的主要成就是在一幅图片中替换了面孔。 与以前的作品不同,需要对特定人的各种照片进行培训。 事实证明,该管道很麻烦(重新制定和分割,视图插值,修复,混合),并且存在很多技术漏洞,但是这样做值得。

通过图像再合成检测意外
arXiv 。
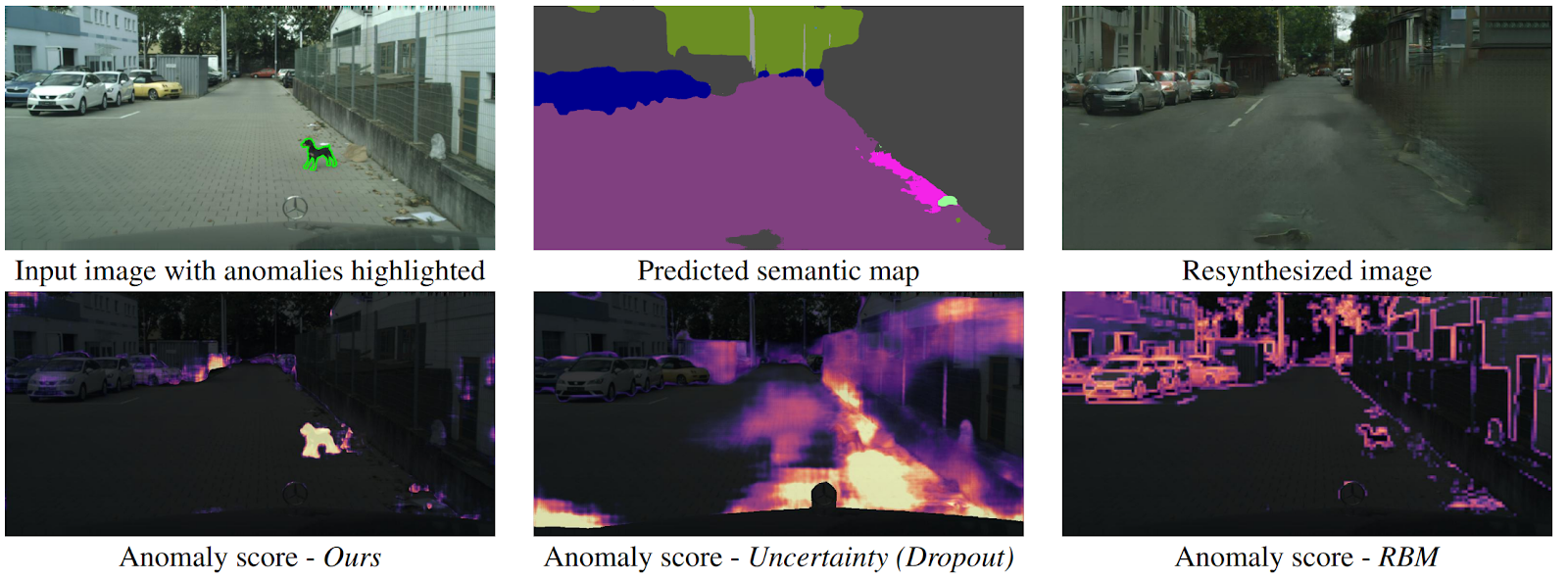
无人机如何理解某个对象突然出现在它前面,而该对象不属于任何语义分割类别? 有几种方法,但是作者提供了一种新的,直观的算法,比以前的算法效果更好。 语义分割是根据道路的输入图像预测的。 它被馈送到GAN(pix2pixHD)中,后者试图仅从语义映射中还原原始图像。 未落入任何片段的异常在来源和生成的图像上将有很大的不同。 然后,将三个图像(初始图像,分割图像和重建图像)提交给另一个预测异常的网络。 此数据集是从著名的Cityscapes数据集生成的,偶然更改了语义分割上的类。 有趣的是,在这种情况下,站在路中间但被正确分割(这意味着有一个类别)的狗不是异常,因为系统能够识别它。
结论
会议之前,重要的是要了解您的科学兴趣,我想发表的演讲以及与谁交谈。 这样,一切都会变得更有生产力。
ICCV主要是联网。 您了解到有顶尖的机构和顶尖的科学家,您开始了解这一点,从而结识了人们。 而且,您可以阅读关于arXiv的文章-顺便说一句,很酷,您无法到任何地方去获取知识,这非常酷。
此外,在会议上,您可以深入探讨与您不熟悉的主题,并查看趋势。 好吧,写出要阅读的文章列表。 如果您是一名学生,这是一个机会与潜在的科学家相识,如果您来自该行业,那么您可以结识新雇主,如果您是公司,则可以展示自己。
订阅
@loss_function_porn ! 这是一个个人项目:我们和
karfly在一起。 会议期间我们喜欢的所有工作都在这里发布:
@loss_function_live 。