TL DR:JSONB可以大大简化数据库架构的开发,而不会牺牲查询性能。
引言
让我们举一个经典的例子,大概是关系数据库(数据库)最古老的用例之一:我们有一个实体,有必要保留该实体的某些属性(属性)。 但是并非所有实例都可能具有相同的属性集,此外,将来可能会添加更多属性。
解决此问题的最简单方法是在数据库表中为每个属性值创建一列,然后只需填写特定实体实例所需的那些列即可。 太好了! 问题得到解决...直到您的表包含数百万条记录,并且您无需添加新记录。
考虑EAV(
实体-属性-值 )模式,这很常见。 一个表包含实体(记录),另一个表包含属性名称(属性),第三个表将实体与其属性相关联,并包含当前实体的这些属性的值。 这使您有机会为不同的对象提供不同的属性集,以及在不更改数据库结构的情况下即时添加属性。
但是,如果使用EVA的方法没有缺点,我不会写这篇说明。 因此,例如,要获得一个或多个每个都具有1个属性的实体,在查询中需要2个join'a(联接):第一个是与属性表的并集,第二个是与值表的并集。 如果一个实体有2个属性,则已经需要4个联接! 此外,所有属性通常都存储为字符串,这将导致对结果和WHERE子句进行类型转换。 如果您编写了很多请求,那么就资源使用而言,这是相当浪费的。
尽管存在这些明显的缺陷,但EAV长期以来一直用于解决此类问题。 这些都是不可避免的缺陷,而且没有更好的选择。
但是后来一种新的“技术”出现在PostgreSQL中...
从PostgreSQL 9.4开始,添加了JSONB数据类型以存储二进制JSON数据。 尽管以这种格式存储JSON通常比纯文本JSON占用更多的空间和时间,但使用它的操作要快得多。 JSONB还支持索引编制,这使查询速度更快。
JSONB数据类型使我们可以通过在实体表中仅添加一个JSONB列来替换笨重的EAV模式,从而大大简化了数据库设计。 但是许多人认为这应该伴随生产率的下降。这就是为什么我出现在本文中。
测试数据库设置
为了进行比较,我在$ 80的
DigitalOcean Ubuntu 14.04构建上的新安装的PostgreSQL 9.5上创建了一个数据库。 在postgresql.conf中设置一些参数后,我使用psql运行了
该脚本。 创建了下表以将数据表示为EAV:
CREATE TABLE entity ( id SERIAL PRIMARY KEY, name TEXT, description TEXT ); CREATE TABLE entity_attribute ( id SERIAL PRIMARY KEY, name TEXT ); CREATE TABLE entity_attribute_value ( id SERIAL PRIMARY KEY, entity_id INT REFERENCES entity(id), entity_attribute_id INT REFERENCES entity_attribute(id), value TEXT );
下表是将存储相同数据的表,但表中的属性为JSONB类型column-
properties 。
CREATE TABLE entity_jsonb ( id SERIAL PRIMARY KEY, name TEXT, description TEXT, properties JSONB );
看起来容易很多,对吧? 然后,将1000万条记录添加到实体表(
Entity &
Entity_jsonb ),因此,使用EAV模式和带有JSONB列的方法-entity_jsonb.properties填充了相同的表数据。 因此,我们在整个属性集中收到了几种不同的数据类型。 样本数据:
{ id: 1 name: "Entity1" description: "Test entity no. 1" properties: { color: "red" lenght: 120 width: 3.1882420 hassomething: true country: "Belgium" } }
因此,对于两个选项,我们现在具有相同的数据。 让我们开始比较工作中的实现!
设计简化
已经说过,数据库的设计已大大简化:一个表,通过使用JSONB列作为属性,而不是三个表用于EAV。 但这在请求中如何体现? 更新实体的一个属性如下:
如您所见,最后一个请求看起来并不容易。 要更新JSONB对象中属性的值,我们必须使用
jsonb_set()函数,并且必须将新值作为JSONB对象传递。 但是,我们不需要事先知道任何标识符。 看一下EAV示例,我们需要知道entity_id和entity_attribute_id才能进行更新。 如果要基于对象的名称更新JSONB列中的属性,则只需在一个简单的行中完成所有操作。
现在,根据新颜色的条件选择刚刚更新的实体:
我认为我们可以同意,第二个较短(无需加入!),因此更具可读性。 这是JSONB的胜利! 我们使用JSON->>运算符从JSONB对象获取颜色作为文本值。 还有第二种使用@>运算符在JSONB模型中实现相同结果的方法:
这有点复杂:我们检查一下属性列中的JSON对象是否包含@>运算符右侧的对象。 可读性较低,生产率更高(请参见下文)。
当您需要一次选择多个属性时,可以进一步简化JSONB的使用。 这就是JSONB方法真正出现的地方:我们只需选择属性作为结果集中的其他列即可,而无需进行连接:
使用EAV时,您要请求的每个属性都需要2个联接。 在我看来,以上查询显示了数据库设计的极大简化。 也在
这篇文章中查看有关如何编写JSONB请求的更多示例。
现在该讨论性能了。
性能表现
为了比较性能,我在查询中使用
EXPLAIN ANALYZE来计算运行时间。 每个请求至少执行了3次,因为查询计划者第一次花费的时间更长。 首先,我运行没有任何索引的查询。 显然,这是JSONB的优势,因为EAV所需的联接无法使用索引(未索引外键字段)。 之后,我为EAV值表中的两列外键创建了索引,并为JSONB列创建了
GIN索引。
数据更新及时显示了以下结果(以毫秒为单位)。 请注意,小数位数是对数的:

由于上述原因,我们发现如果不使用索引,JSONB比EAV快很多(> 50,000-x)。 当我们使用主键索引列时,差异几乎消失了,但是JSONB仍然比EAV快1.3倍。 请注意,JSONB列中的索引在这里无效,因为我们没有在评估标准中使用属性列。
要基于属性值选择数据,我们获得以下结果(正常标度):
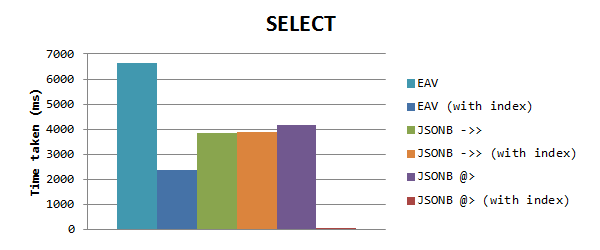
您可能会注意到,JSONB再次比没有索引的EAV更快,但是当EAV与索引一起使用时,它仍然比JSONB更快。 但是后来我发现JSONB请求的时间是相同的,这使我想到了GIN索引无效的事实。 显然,当对具有填充属性的列使用GIN索引时,仅当使用包含运算符@>时,该索引才起作用。 我在新测试中使用了此功能,它对时间产生了巨大影响:仅0.153毫秒! 这比EAV快15,000倍,比操作员->>快25,000倍。
我认为速度足够快!
数据库表大小
让我们比较两种方法的表大小。 在psql中,我们可以使用
\ dti +命令显示所有表和索引的大小
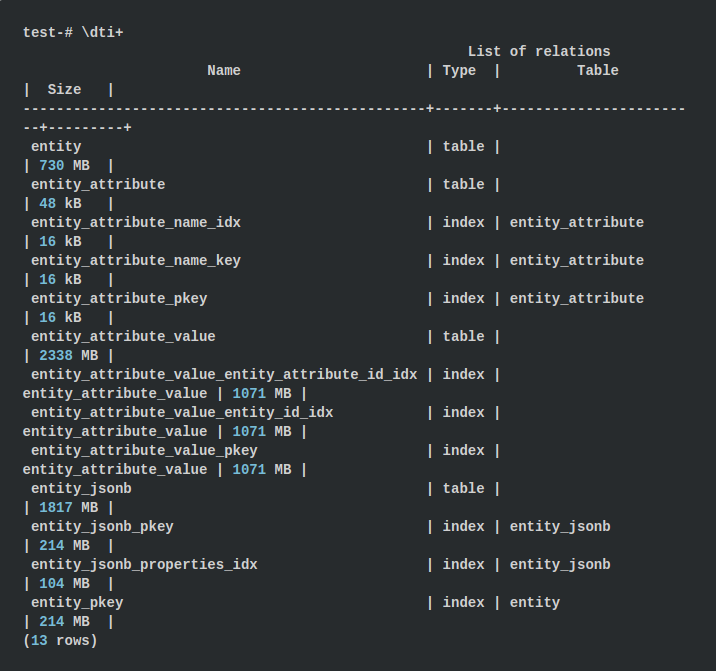
对于EAV方法,表大小约为3068 MB,索引最大为3427 MB,总共为6.43 GB。 使用JSONB方法,表使用1817 MB,索引使用318 MB,即2.08 GB。 原来少了3倍! 这个事实让我有些惊讶,因为我们将属性名称存储在每个JSONB对象中。
但是,数字都是不言而喻的:在EAV中,我们为属性值存储2个整数外键,结果得到8个字节的附加数据。 另外,在EAV中,所有属性值都存储为文本,而JSONB会在可能的情况下在内部使用数字和逻辑值,从而减少体积。
总结
通常,我认为以JSONB格式存储实体属性可以大大简化数据库的设计和维护。 如果执行大量查询,则与实体存储在同一表中的所有内容实际上将更有效地工作。 而且,这简化了数据之间的交互这一事实已经是一个加分了,但是生成的数据库的容量却小了3倍。
另外,根据测试,我们可以得出结论,性能损失非常小。 在某些情况下,JSONB甚至比EAV更快地工作,这使其变得更好。 但是,此基准当然不能涵盖所有方面(例如,具有大量属性的实体,现有数据的属性数量显着增加...),因此,如果您对如何改进它们有任何建议,请随时发表评论!