
哈Ha 最近有来自Tinkoff和McKinsey 的比赛。 比赛分两个阶段进行:第一阶段-以kaggle格式进行排位赛,即 发送预测-获得对预测质量的评估; 获胜者是得分最高的人。 第二个是在莫斯科举行的现场黑客马拉松比赛,其中包含第一阶段前20名的队伍。 在本文中,我将讨论排位赛阶段,在那里我获得了第一名并赢得了MacBook。 排行榜上的团队称为“勒莎的孩子”。
比赛于9月19日至10月12日举行。 我恰好在结束前一周开始解决问题,并决定几乎全职。
比赛的简短说明:
在夏天,故事出现在Tinkoff银行应用程序(如Instagram)上。 在故事中,您可以喜欢,不喜欢,跳过或查看到最后。 任务是预测用户对故事的反应。
比赛大多以表格形式进行,但故事本身有文字和图片。
故事计划

公制
反应预测的取值范围是-1至1(包括1)-值越接近1,获得相似值的可能性越高。 并且值为-1时,最好从用户的眼睛中删除该故事。
为了检查解决方案的准确性,使用了一个公式,将其标准化为最大可能的结果:
\开始{array} {l} {\文本{weight(event)} = \左\ {\开始{array} {ll} {-10}&{\ text {dislike}} \\ {-0.1}& {\ text {skip}} \\ {0.1}&{\ text {view}} \\ {0.5}&{\ text {like}} \ end {array} \ right。} \\ [15pt] {\ text {公制} \左(y _ {\文本{pred}} \右)= \ sum_ {i = 1} ^ {n} \左(\文本{weight} \左(\文本{event} _ {i} \右)\ cdot y _ {\文本{pred,} i} \右)} \结束{array}
那里有什么数据:
- 基本用户信息
- 用户交易
- 有关故事的信息(可从中构造故事的json)
- 用户对故事的反应历史。
接下来,我将详细讨论每条数据,如何处理以及提取了哪些特征(以下称为特征)。

最初是什么:
- 用户名
- 用户打开(OPN),使用(UTL)或关闭(CLS)的匿名银行产品
- 性别,二元化年龄,婚姻状况,首次申请
- job_title-人们对自己的看法
- job_position_cd-一个人的职务,作为22个类别之一
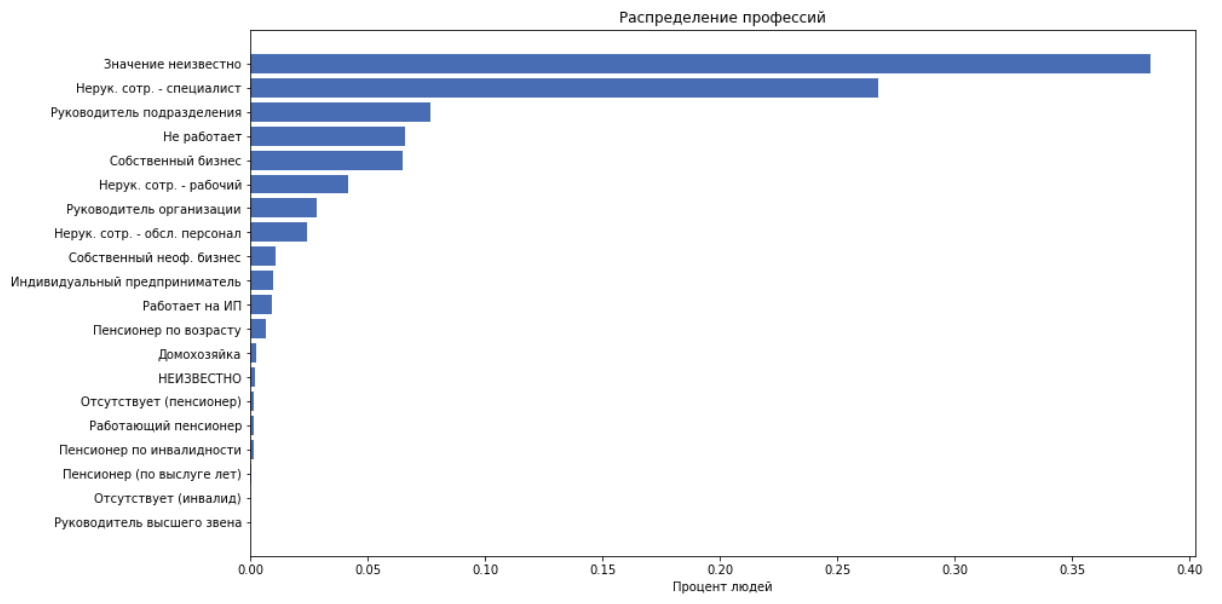
作为功能,我们使用上述所有内容,但job_title除外,因为 我们假设job_position_cd通常描述一个人的职位。
交易次数

最初是什么:
- 用户名
- 交易日,月
- 交易金额(二值化,增量为250)
- Businessman_id-收银机的内部银行ID。 进一步不使用。
- Businessman_mcc
MCC-商家类别代码。 这是收件人提供的标准化服务代码。 此信息是开放的,这里是成绩单 。 这些代码可以方便地分为几类,例如:娱乐,酒店等。
对于每个customer_id,我们比较以下功能:
- 计算费用金额,平均支票,标准差
- 交易数量
- 我们将“我的客户中心”代码分为20个类别,计算有多少人在此类别上花了钱。 获得20个功能
- 通过将类别中的支出除以支出金额,我们将获得另外20个功能。 即 获取花在该类别上的钱的百分比。
故事
总共有959个故事。
最初是什么:
json看起来像这样:

这是一棵元素树,其中每个元素都由键描述:['guid','type','description','properties','content']。 “内容”包含子项列表。 故事由页面组成。 背景,文本,图片都被扔在页面上。 我们没有故事的构建者,要绘制所有这些故事相当困难,而不是事实,这将在将来极大地帮助您。
常规字体会提取所有文本和相应的字体大小。 我们提取以下功能:
- 页面数,链接数,元素总数
- 平均文字字体大小
- 文字元素数量
- “文本量”是一种启发式方法,可以根据字体大小仔细考虑文本的长度。
卷计数代码def get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- 现在,让我们来看整个文本,使用陀思妥耶夫斯基定义文本的语义:['中性','否定','跳过','语音','正']。 并将其添加为5个功能
反应

最初是什么:
我们处理时间并将要素添加为要素:
接下来,将基于反应数据添加一组功能,但是目前,我们将与这些功能库作斗争以制定基准。
整个高层使用的最佳方法如下:将问题简化为多类分类,即 预测每个反应的可能性。 考虑评估的期望 这个故事 :
二值化 :
-我们对目标的回答 可以带来价值
型号
从头到尾,我都使用CatBoost。 这是由于CatBoost开箱即用地为分类功能建立了有用的统计数据。 用户的统计信息-他对什么反应有多大的倾向,以及历史记录-他们最常不反应的统计信息,是此任务中最强大的功能。
该文档很好地解释了CatBoost如何与分类功能一起工作。
TLDR:
- 生成多个数据排列
- 按顺序进行,并在他已经看到的那些对象上建立均值目标编码(mte)
在我们的示例中简要介绍mte我们以符号的值为例,例如customer_id之一,我们考虑了该客户做出喜欢,不喜欢,跳过或查看的情况的百分比。 我们得到4个数字。 我们用这4个数字替换customer_id并将其用作符号。 我们为每个customer_id执行此操作。
当前结果
凭借当前的功能以及未优化的设计,我当时在公共排行榜上排名第11位,结果为0.31209
杀手级功能
在某个时候,出现了一个假设,即应用程序可能会根据用户对它的早期反应来显示故事的频率更高或更小。 然后让我们添加以下功能:
- 用户在过去/将来/每月/每天/小时/总计中看到多少次相应历史记录
- 自上次观看同一故事以来的时间
- 用户下一次看相同故事的时间
- 实际上,用户一秒钟一次加载多个故事,通常在5到7个左右。 将这组故事称为一组 。 我将这个数目的故事添加到组中作为功能,这大大提高了质量。
当然,这些功能不能在生产中使用,因为 在应用该模型时,它们不会很老套,但是在竞争中,任何手段都是好的。
因此,据说-完成了。 在排行榜上获得了0.35657 。
模型优化
我使用贝叶斯优化来检查参数
有趣的是,我们可以提到max_ctr_complexity参数,该参数负责可组合的最大分类特征数量。 以扰流板为例。
文档摘录假设训练集中的对象属于两个分类特征:音乐体裁(“摇滚”,“独立”)和音乐风格(“舞蹈”,“古典”)。 这些功能可以以不同的组合出现。 CatBoost可以创建一个新功能,将这些功能组合在一起(“舞蹈摇滚”,“经典摇滚”,“独立舞蹈”或“独立古典”)。
有趣的观察
CatBoost可以在GPU上进行训练,这大大加快了学习速度,但同时也引入了许多限制,尤其是在分类功能方面。 在此任务中,在GPU上进行培训比在CPU上进行培训要差得多。
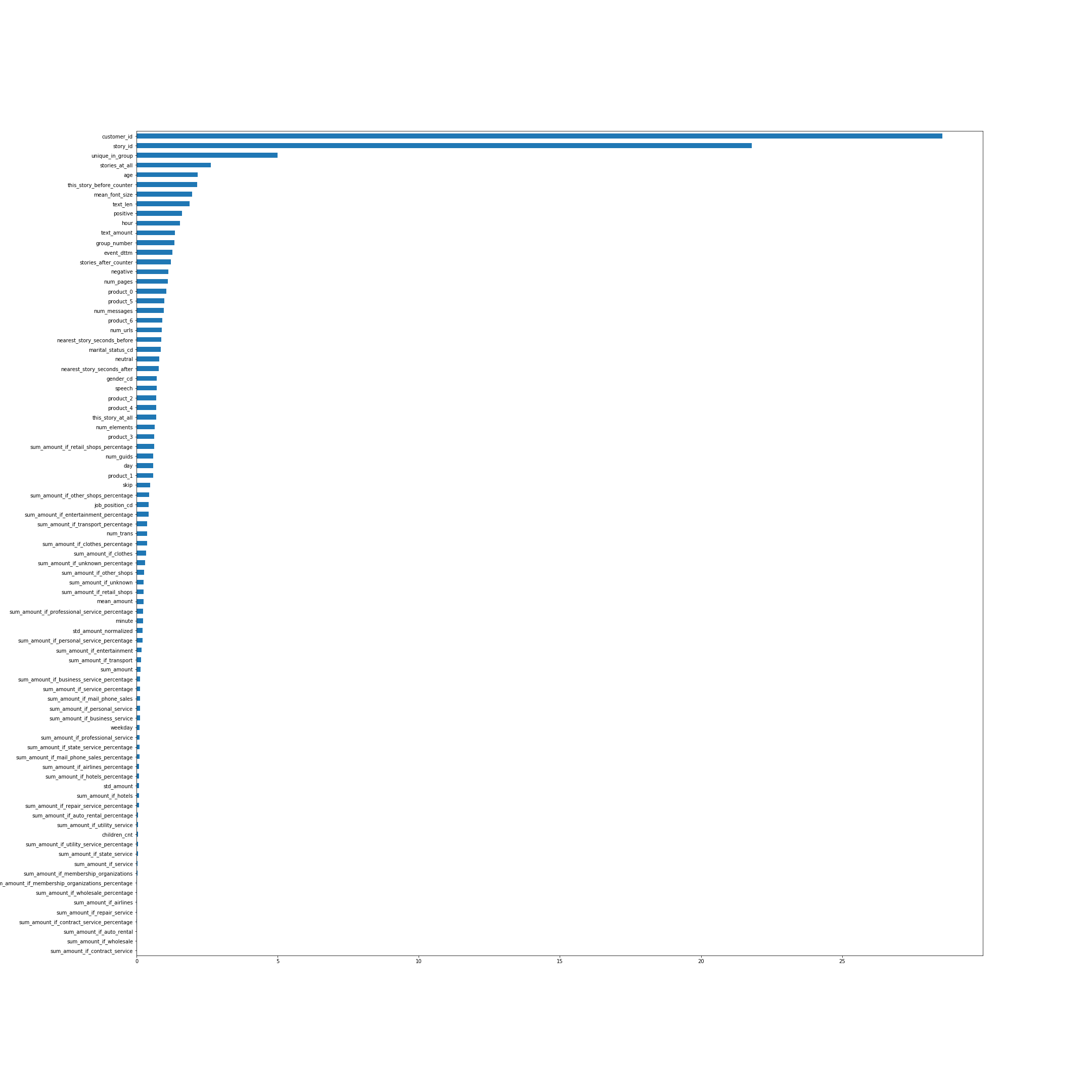
根据CatBoost,功能的重要性。 在许多方面,功能的名称可以说明一切,但是从顶部开始,我将解释一些功能,而不是最明显的功能:
- unique_in_group-组中的故事数。 (在组中它们始终是唯一的,就在创建功能时我还不知道)
- story_at_all-一个人在将来和过去浏览过的故事数。
- this_story_before_counter-人们之前看过这个故事的次数。
- text_amount-启发式的文本量。
- group_number-组的序列号。
- near_story_seconds_before / after-本质上,这是直到显示下一组的时间。
图片是可单击的。
让我们看一下反应随时间的分布:

即 在某些时候,反应的分布差异很大。
接下来,我想确认测试中的分布与训练样本末尾的分布相同。 让我们将所有这些作为预测发送,我们得到的结果为0.00237。 我们预测火车最后部分的所有结果-在第一部分得到大约0.009--0.22。 因此,测试中的分布很可能与火车末尾的分布相同,并且绝对看起来不像主要部分。 这就提出了一个假设,即如果分配得到纠正 根据我们的预测,排行榜上的结果将大大改善,因为 火车上和测试上的分布是不同的。
阈值预测
在获得最终预测的最后一步,添加一个阈值:
在上一个模型中,如果将垃圾箱二进制化为0,那么我将拥有大约66%的单位。事实证明,+1数量的减少确实带来了质量的极大提高。 仅评估了最后3个前提,因此我发送了具有不同垃圾箱的最佳模型的预测,因此百分比加一约为62、58和54。
结果,在公共排行榜上,我最好的成绩是0.37970 。
比赛结果
关于公共/私人排行榜按照机器学习竞赛的惯例,当您将预测发送到系统时,仅对整个测试样本的一部分评估结果。 通常约为30%。 此部分的结果反映在公共排行榜中。 在剩下的测试中,将评估最终结果,并在比赛结束后显示在私人排行榜上。
在公共排行榜上的比赛结束时,情况如下:
- 0.382-可以在这里做广告
- 0.379-蕾莎的孩子
- 0.372-园丁
- 0.35-懒惰&阿库洛夫
在考虑到最终结果的私人排行榜上,我很幸运,由于某种原因,这些人从第四名跌至第四名。 这是最终位置。
- 0.45807乐莎的孩子
- 0.45264园丁
- 0.44136竹克
- 0.43704这可能是您的广告
- 0.43474懒惰&阿库洛夫
什么没用
- 我尝试使用快速文本将故事中的所有文本转换为向量,然后将向量聚类并将聚类号用作分类特征。 该功能在CatBoost的功能重要性中排在前3位(在story_id和customer_id之后),但是由于某种原因,它是稳定的并且显着恶化了验证结果。
- 多亏了这些集群,人们可以找到与世界杯有关的故事,并且只在训练集中出现。
但是,从数据集中弹出此类对象并不能改善结果。 - 默认情况下,CatBoost会生成对象的随机排列,并根据对象考虑符号以进行分类。 但是我们可以对这套怪兽说,我们的数据中有时间-has_time = True。 然后它将按顺序进行,而不会混合数据集。 在这个问题中,尽管我们确实有时间,但是has_time的结果稳定地更差。
在一般情况下,如果有时间,但在构造平均目标编码时不应考虑,因此模型将使用有关将来正确答案的信息,并可以对其进行重新训练。 显然,在这个问题中,这没有太大的作用,而在不同的排列中重复几次更为重要。 - 有一种想法是在火车结束时为物体分配更多的重量,即 考虑到更多具有正确分布反应的对象。 但是无论是在验证还是在公共排行榜上,这都给出了更糟糕的结果。
- 您可以在训练过程中考虑不同权重的不同反应。 尽管这对我而言并没有改善,但对一些团队有所帮助。
结论
竞赛之所以有趣是因为它汇集了许多组成部分,例如表格数据,文本和图片。 有大量的研究空间,仍有很多可以尝试的空间。 通常,我不必感到无聊。
感谢比赛的组织者!
所有代码都发布在github上 。