我向您介绍了HaxeUp Sessions 2019 Linz的另一份报告的译文,我认为这是对上一份报告的很好的补充,因为 延续了2019年发生的Haxe变化主题,并对其未来进行了一些讨论。
关于报告作者的一些信息: Aurel Bili遇到了Haxe ,参加了各种游戏卡纸,并且他继续参与其中(例如,这是他上次Ludum Dare 45的游戏 )。

Aurel目前正在伦敦帝国理工学院完成学业,这意味着必须进行实习。 他进行的第一次实习是在一个偏僻的办公室,那条路花了很多时间。 因此,他希望下一步的做法可以远程进行。

碰巧的是,Haxe基金会很长时间找不到适合编译器开发人员的雇员 。 Aurel决定尝试自己的运气,并致函要求远程工作。 他很幸运- 他被接受为期六个月的实习,并有机会在伦敦工作。
设置设备时,商定了Aurel将要从事的任务范围(尽管并非最终实现了所有事情)。

他做了什么?
首先, 文档处于悲惨状态:描述了语法的所有更改,语言和编译器的新功能,并补充了有关字符串,文字和常量的部分。
所有文档已从LaTeX转换为Markdown !
其次,将标准库的代码格式设置为一种样式 (因为使用不同样式的代码设计的人对此进行了10多年的努力)。 因此,在Haxe编译器存储库中,Aurel在添加的代码行数中排名第七:)
第三,Aurel还研究了标准库和编译器:
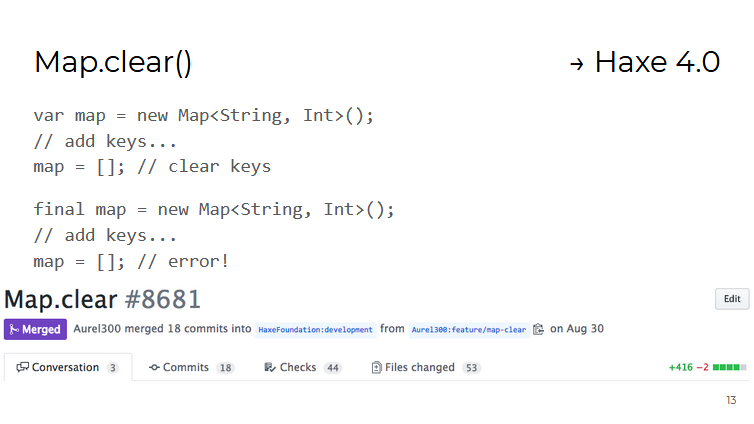
例如, Map容器具有一个新的clear()方法,该方法将删除所有存储的值。 这样做主要是为了方便使用作为final变量创建的容器(即,不能为它们分配新值,但是可以对其进行修改):
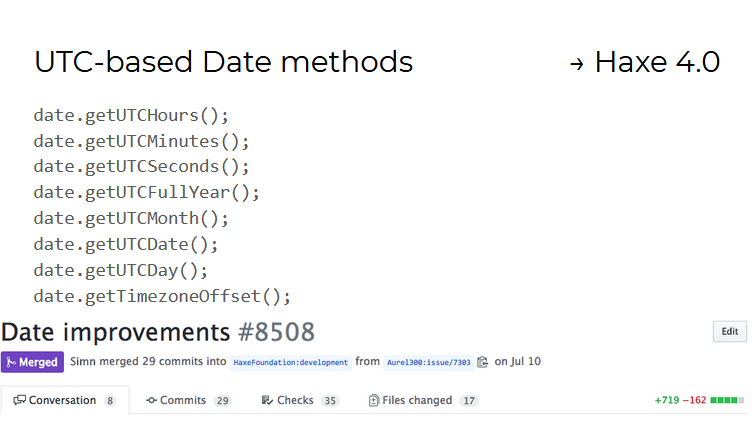
对于类型为Date对象,已经出现了使用UTC(全球通用时间)格式的Date方法。 对它们的研究表明,实现在Haxe支持的所有11种语言/平台上均能正常工作的单一API的难度。
在旧的编译器中,定义和元标记是在OCaml上定义的,但是现在它们以JSON格式描述,这应该简化外部工具的解析(例如,以自动生成文档):

您可能还会注意到,在大型项目中,编译服务器开始使用大量内存。
为了解决此问题,Simon Kraevsky和Aurel开发了hxb二进制格式,该格式用于序列化类型化的AST。 现在,编译服务器可以将模块加载到内存中,直到需要使用它为止,然后将其从内存中卸载到hxb格式的文件中,并释放占用的内存。

hxb格式规范可在单独的存储库中获得 ,其当前在编译器(带有序列化器/解串器)中的实现位于单独的Haxe分支中 。 有关此功能的工作尚未完成,也许会出现在Haxe 4.1中。

实习期间Aurel的工作的第四个重点是创建新的异步系统API-asys。

之所以需要创建它,是因为现有的API无法提供简单的方法来异步执行系统操作。 例如,要异步处理文件,您将必须创建一个单独的线程,在该线程中将执行所需的操作,并手动控制其状态。 另外,当前的API不具有使用UDP套接字的所有功能(其他语言的标准库中有此功能),不支持IPC套接字。

在创建和实现新的API时,会出现许多问题:
如何设计API? 也许值得以现有的为例? 毕竟,我们不想从头开始创建所有内容,因为 这将花费更多时间,并且可能不符合团队其他成员的口味,并引起了很多争论。
而且,正如已经提到的,Haxe的实际问题是为所有受支持的平台实现单个API。

选择了API Node.js.作为示例。 经过深思熟虑,它支持必要的系统功能,非常适合创建服务器应用程序。

但是同时,Node.js API是一种Javascript API,没有强类型。 例如,来自fs模块的用于文件系统的函数可以将字符串或诸如Buffer甚至URL类的对象用作路径。 对于Haxe来说,这不是很好。

反过来,Node.js使用用C编写的libuv库 。直接从Haxe使用libuv API并不那么方便:例如,为了异步重命名文件,您需要另外创建uv_loop_t (用于管理的结构) libuv中的事件循环)和uv_fs_t (用于描述对文件系统的请求的结构):

结果,Node.js和libuv API集成如下(以eval宏解释器和rename方法为例):
- 他们采用了Node.js的API方法,将其转换为Haxe,试图标准化参数类型并摆脱对Haxe多余的参数。 例如,路径参数(
FilePath类型)是字符串的抽象:


- 链接的OCaml和C(使用CFFI-C外部功能接口):

- 最后编写了C-binders以从OCaml调用libuv C函数:

同样,它是针对HashLink和Neko完成的(目前,仅针对这三个平台实现了asys API)。 您可能会猜到,它花费了很多工作。
Aurel展示了一些小型应用程序,演示了asys API的工作原理。
第一个示例是异步读取文件内容的演示。 到目前为止,由于尚未完成API的工作(但将来),因此代码明确调用了初始化libuv( hl.Uv.init() )和启动应用程序周期( hl.Uv.run() )的方法。它们将被自动添加):
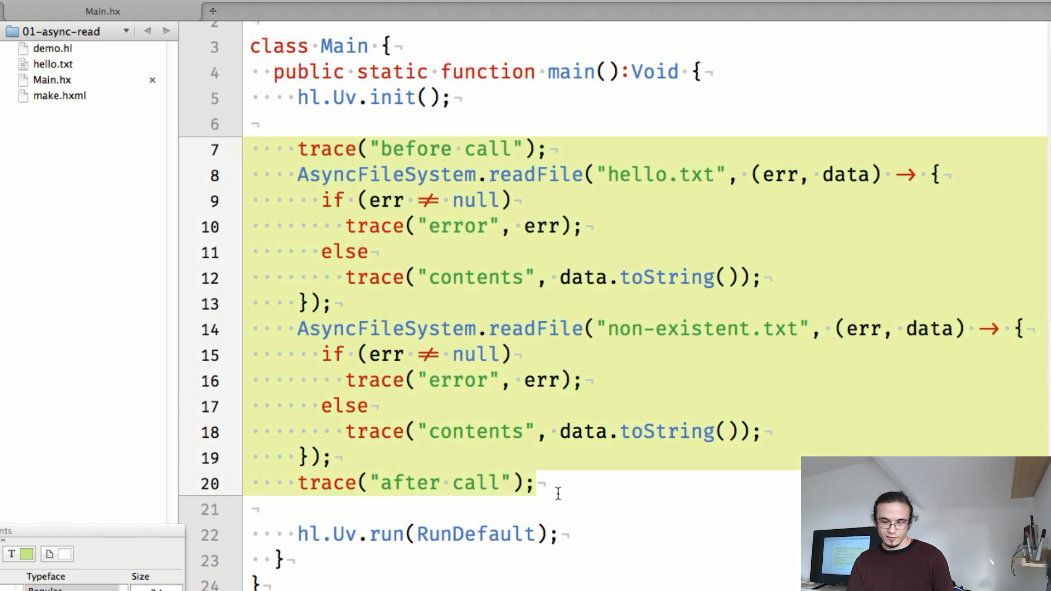
显示代码的结果:
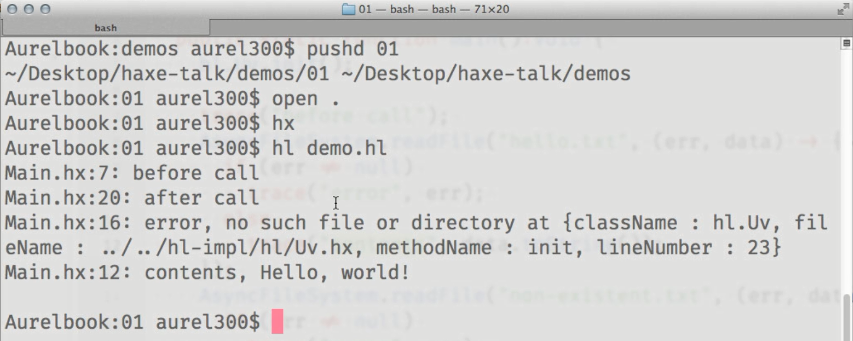
我们看到被调用的AsyncFileSystem.readFile()方法的结果在“调用后”跟踪之后显示在控制台中,该跟踪在尝试读取文件内容后在代码中被调用。
第二个示例演示了使用DNS和IP地址进行异步操作。
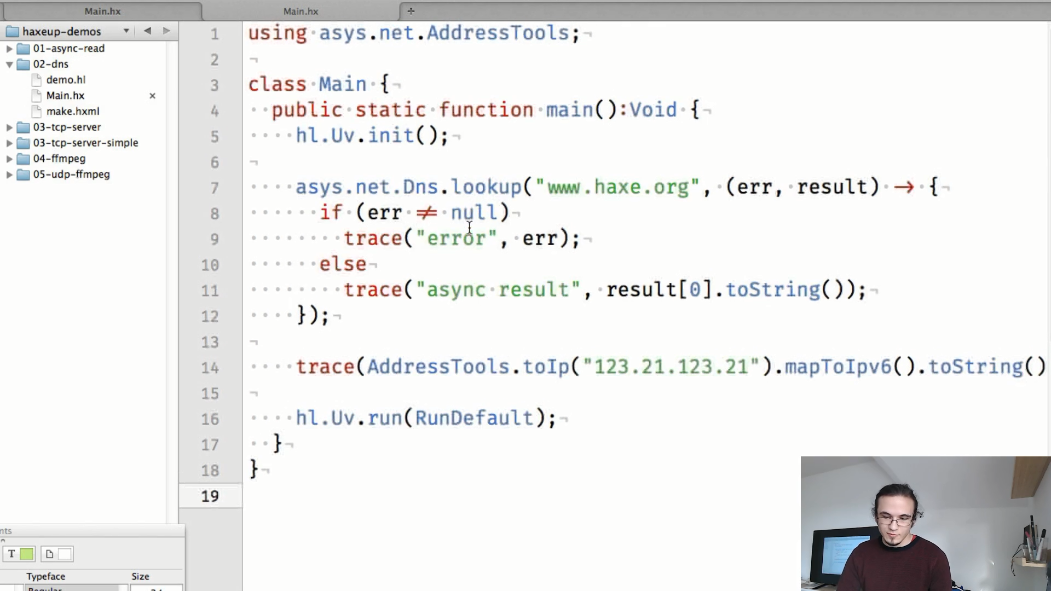
在新的API中,确定主机名以及使用IP地址的辅助方法将变得更加容易。
第三个示例是一个简单的TCP回显服务器,它仅需要三行代码即可创建:

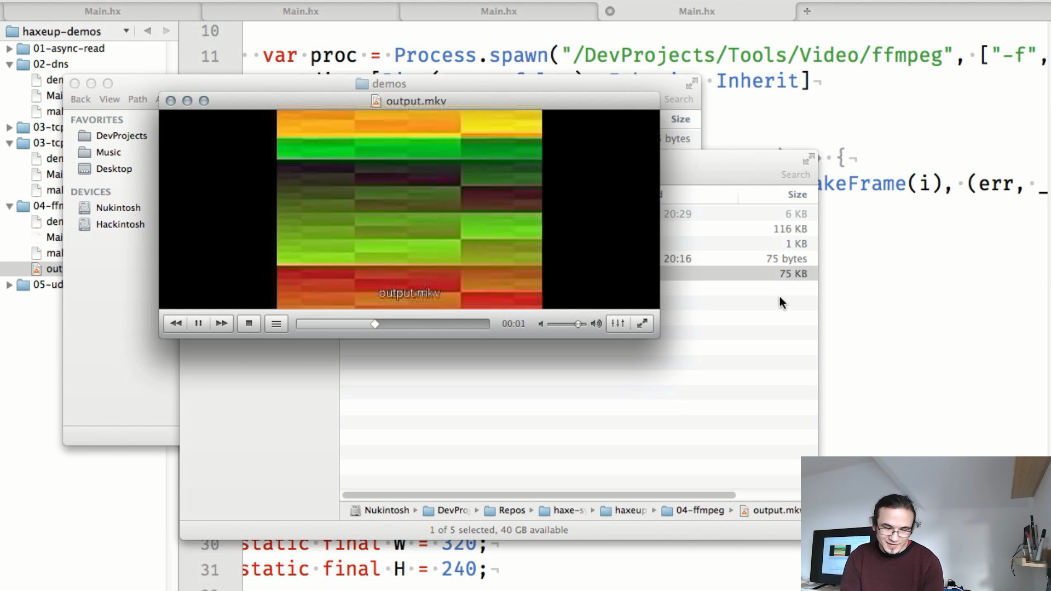
第四个示例说明了流程之间的信息交换:
此示例中的静态makeFrame()方法创建单独的png图像:

在main方法中,我们启动ffmpeg流程,并将在makeFrame()生成的帧传输到其中:
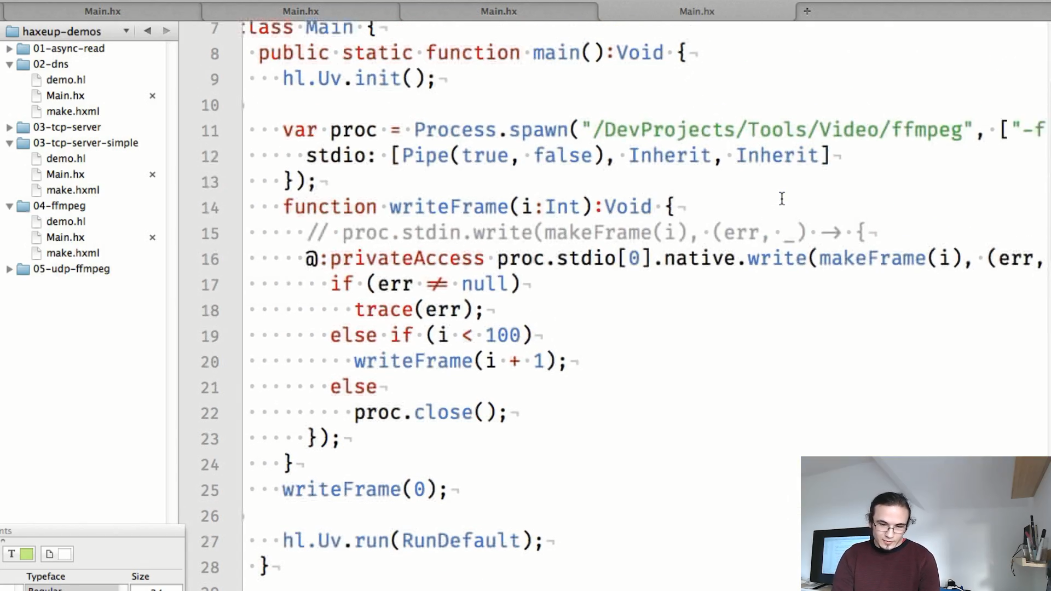
并且输出将是一个视频文件:
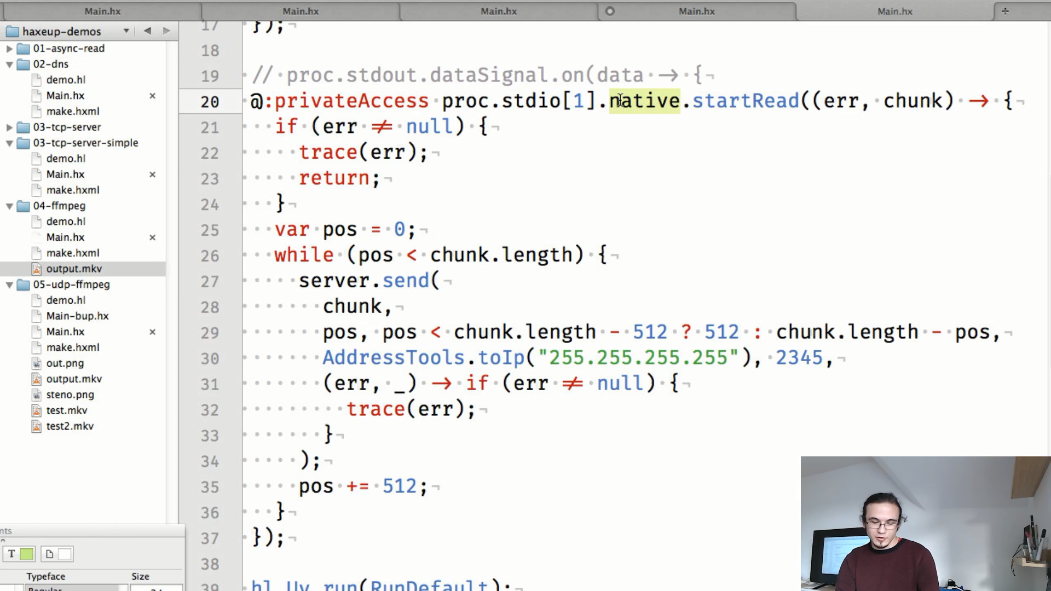
第五个示例是UDP视频流。 在这里,与前面的示例一样,ffmpeg进程已启动,但是这次它播放视频并将其数据输出到标准输出流。 还创建了一个UDP套接字,该套接字将转换ffmpeg进程中的数据。

最后,我们将从ffmpeg接收的数据分成较小的“部分”,并将其转换为指定的端口:
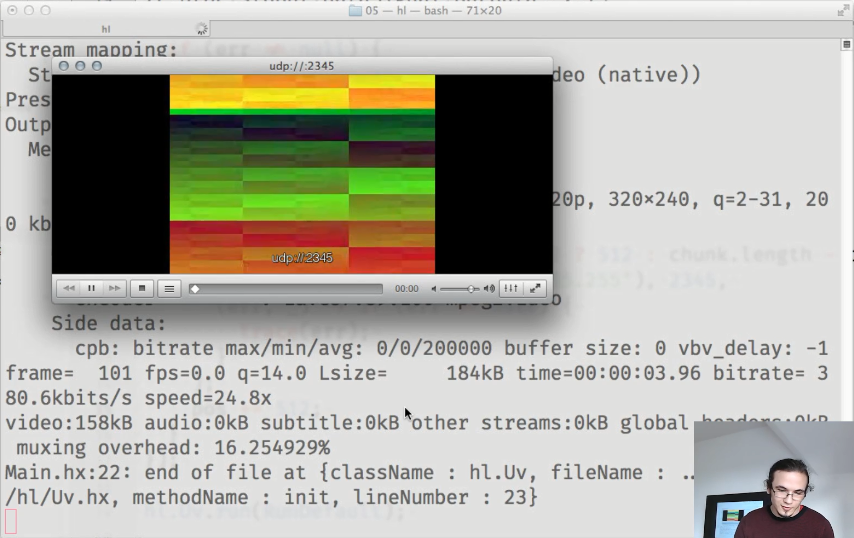
结果,我们得到了一个有效的视频流:
综上所述,新的asys API包括:
- 用于文件系统的方法,包括标准库中没有的新功能(例如,用于更改权限),以及旧标准库中所有可用功能的异步版本
- 支持使用TCP / UDP / IPC套接字进行异步操作
- 使用DNS的方法(到目前为止,有2种方法:
lookup和reverse ) - 以及与流程异步工作的方法。

关于asys API的工作尚未完成;当前使用libuv库时,垃圾收集器存在一些问题。 带有相应更改的Pull Request尚未合并到Haxe主分支中,对此的评论欢迎就新方法的名称,其签名和文档提供意见。
如前所述,仅针对HashLink,Eval和Neko(以三个单独的Pull Request的形式)实现对asys API的支持。 Aurel已经制定了计划,以增加对C ++和Lua的新API的支持。 其他平台的实施将需要进一步的研究。

asys API可能会在Haxe 4.1中可用(但仅在某些平台上可用)。
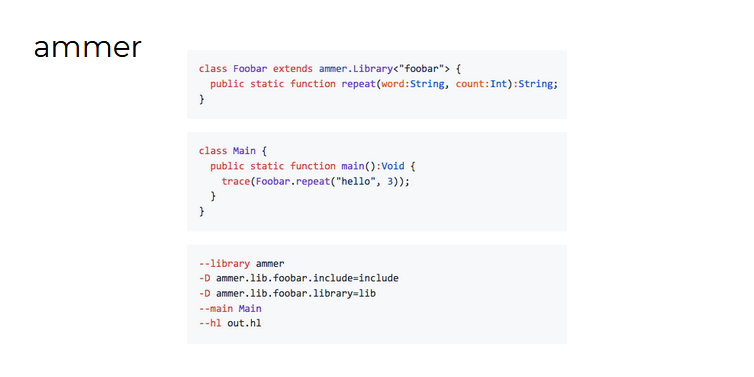
Aurel还谈到了他的副项目-ammer库 (尽管与他在Haxe基金会的工作有关)。

Ammer的目标是自动创建C库的绑定程序,以便可以在HashLink和HXCPP中使用它们(2018年10月, Lars Duse指定了解决此问题的费用 )。
为什么这项任务有意义? 事实是,尽管为HashLink和HXCPP创建绑定程序的过程相似,但是对于每个平台,您都必须编写自己的粘合代码。
当Aurel将libuv库集成到Haxe中时,他做了大致相同的事情-对于Eval,Neko和HashLink,他必须编写相同的代码,只是细节有所不同(函数调用,FFI工作上的差异等):

在Haxe端需要进行类似的工作,以便可以从中调用本机函数:

而ammer的想法是采用API的Haxe版本,而不是被多余的信息所困扰,并使该代码以某种方式适用于所有平台:

现在需要使用外部C库的高级软件:
- 为该库创建Haxe规范,该规范本质上是所用库的外部
- 编写应用程序代码
- 通过指定头文件和C库文件的路径来编译项目
- ...
- 获利
在后台,ammer执行以下操作:
- 根据目标平台匹配类型
- 自动生成C代码以调用本机函数
- 生成用于创建hdll,ndll文件的makefile

Ammer目前支持:
- 简单的功能
- 从头文件定义(在Hax代码中,它们可以作为常量访问)
- 指针
计划的支持:
- 回调(它们仍然供不应求)
- 和结构(使用C-API非常必要)

现在,ammer可与C ++,HashLink和Eval一起使用。 Aurel确信他可以添加对其他系统平台的支持。

为了演示ammer的功能,Aurel展示了一个运行Lua解释器的小应用程序:
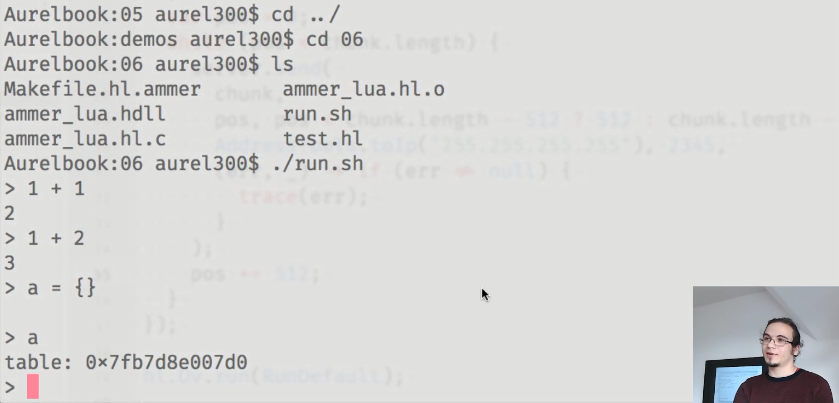
其中使用的粘合剂如下:
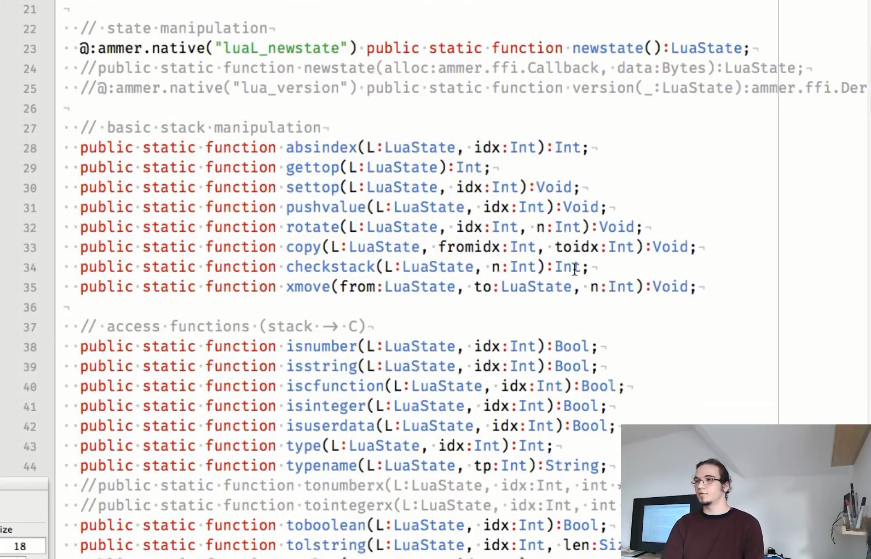
如您所见,某些方法被注释掉了,因为 他们使用回调,但尚未实现对回调的支持,但是Aurel希望他能够尽快解决此问题。

因此,ammer可以用于:
- 嵌入Lua虚拟机
- 在SDL上创建应用程序
- 使用libuv可以实现自动化工作(如前所述,现在使用libuv需要很多手写代码)
- 当然,它将大大简化许多其他有用的C库的使用(例如OpenAL,Dear-imgui等)。

尽管Aurel在Haxe基金会的实习期已经结束,但他计划继续与Haxe合作, 他的大学教育尚未完成,他仍然需要写最后的工作。 Aurel已经知道它将专门用于-改进HashLink中的垃圾收集器的工作。 好吧,这将很有趣!