Redash最近开始从一种任务执行系统更改为另一种。 即,他们开始了从Celery到RQ的过渡。 在第一阶段,只有那些不直接执行请求的任务才被转移到新平台。 这些任务包括发送电子邮件,确定应更新哪些请求,记录用户事件以及其他支持任务。

部署完所有这些之后,人们注意到RQ工作者需要更多的计算资源来解决Celery以前要解决的相同数量的任务。
我们今天发布的翻译材料专门讲述Redash如何找出问题原因并加以解决的故事。
几句话关于芹菜和RQ之间的区别
Celery和RQ具有过程工人的概念。 那里和那里都使用创建fork来组织任务的并行执行。 当Celery工作者启动时,将创建几个fork过程,每个fork过程自动处理任务。 在RQ的情况下,worker的实例仅包含一个子进程(称为“主力马”),该子进程执行一项任务,然后被销毁。 当工作人员从队列下载下一个任务时,他将创建一个新的“主力马”。
使用RQ时,只需运行更多工作进程,即可达到与使用Celery时相同的并行度。 但是,芹菜和RQ之间有一个细微的区别。 在Celery中,工作人员在启动时会创建许多子流程实例,然后重复使用它们来完成许多任务。 对于RQ,您需要为每个作业创建一个新的fork。 两种方法都有其优点和缺点,但是在此我们不再赘述。
绩效评估
在开始进行性能分析之前,我决定通过找出工作容器需要处理1000个作业的时间来评估系统性能。 我决定专注于
record_event任务,因为这是常见的轻量级操作。 为了衡量性能,我使用了
time命令。 这需要对项目代码进行一些更改:
- 为了衡量执行1000个任务的性能,我决定使用RQ批处理模式,在该模式下,在处理任务之后,将退出该过程。
- 我想避免影响我的测量结果,而这可能是在测量系统性能时安排的其他任务。 所以我将
record_event移到了一个称为benchmark的单独队列中,将@job('default')替换为@job('benchmark') 。 这是在tasks/general.py的record_event之前tasks/general.py 。
现在可以开始测量了。 对于初学者,我想知道启动和停止没有负载的工人需要多长时间。 该时间可以从稍后获得的最终结果中减去。
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
在我的计算机上初始化工作程序花了14.7秒。 我记得那个。
然后,我将1000个
record_event测试用例放入
benchmark队列中:
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
之后,我以与以前相同的方式启动系统,并找出处理1000个作业所需的时间。
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
从发生的事情中减去14.7秒,我发现4个工人在102秒内处理了1000个任务。 现在,让我们尝试找出原因。 为此,我们在工作人员忙碌时,将使用
py-spy研究他们。
剖析
我们向队列添加了另外1,000个任务(之所以必须这样做,是因为在之前的测量过程中,所有任务均已处理),然后运行工作程序并对其进行监视。
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
我知道以前的团队很长。 理想情况下,为提高其可读性,值得将其分成单独的片段,并在找到
&&字符序列的位置将其划分。 但是命令必须在相同的
docker-compose exec worker bash会话中顺序执行,因此一切看起来都是这样。 这是此命令的作用的描述:
- 在后台启动4个批处理工人。
- 等待15秒(完成下载大约需要很多时间)。
- 安装
py-spy 。 - 运行
rq-info并找出其中一个工人的PID。 - 使用先前接收的PID记录有关工人工作的信息,持续10秒钟,并将数据保存在
profile.svg文件中
结果,获得了以下“火热时间表”。
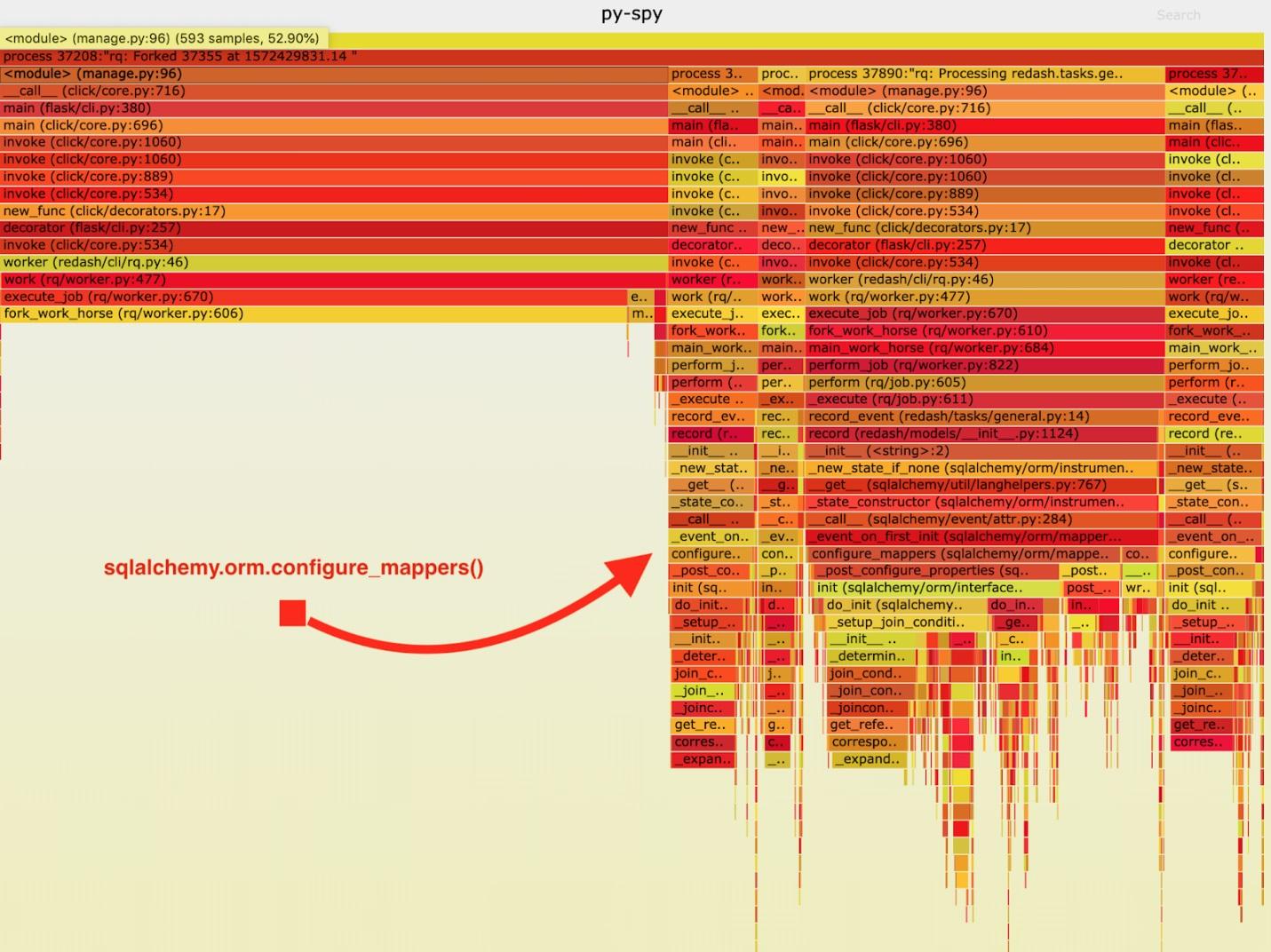 可视化py-spy收集的数据
可视化py-spy收集的数据在分析了这些数据之后,我注意到
record_event任务花了很长时间在
record_event运行它。 这发生在每个任务期间。 从文档中我了解到,在我感兴趣的时候,所有先前创建的映射器的关系都已初始化。
绝对不需要每个叉子都发生这样的事情。 我们可以在父级工作人员中初始化一次关系,而避免在“主力军”中重复执行此任务。
结果,在启动“主力马”之前,我在代码中添加了对
sqlalchemy.org.configure_mappers()的调用,并再次进行了测量。
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
如果从这些结果中减去14.7秒,结果表明我们将4个工作人员处理1000个任务所需的时间从102秒缩短到24.6秒。 这是性能的四倍提高! 借助此修复程序,我们能够将RQ生产资源增加四倍,并保持相同的系统带宽。
总结
从这一切,我得出以下结论:值得记住的是,如果它是唯一的过程,并且涉及到分叉,则应用程序的行为会有所不同。 如果在每项任务期间有必要解决一些棘手的正式任务,那么最好先解决这些问题,在完成分叉之前先完成一次。 在测试和开发过程中不会检测到此类问题,因此,在感觉到项目存在问题,测量其速度并最终找到问题性能原因的过程中,一直没有发现这些问题。
亲爱的读者们! 您是否在Python项目中遇到了性能问题,可以通过仔细分析工作系统来解决?
