你好
本年(2019年)的9月,举行了圣彼得堡州长选举。 所有投票数据都可以在选举委员会的网站上公开获得,我们不会破坏任何内容,而只是以我们需要的形式可视化该网站
www.st-petersburg.vybory.izbirkom.ru上的信息,我们将进行非常简单的分析并找出一些“魔术”模式。
通常对于此类任务,我使用Google Colab。 这是一项服务,可让您运行Jupyter Notebook,并免费访问GPU(NVidia Tesla K80),它将显着加快数据解析和进一步处理的速度。 导入之前,我需要做一些准备工作。
%%time !apt update !apt upgrade !apt install gdal-bin python-gdal python3-gdal
进一步进口。
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt import geopandas as gpd import xlrd
使用的库的描述
- BeautifulSoup-用于解析html和xml文档的模块; 允许您直接访问html中任何标签的内容
- matplotlib.pyplot-构造方法的模块集
parsim是时候收集数据本身了。 选举委员会照顾了我们的时间,并在表格中提供了报告,很方便。
因此,这就是讨论的内容。 Google Colab中的数据可以很聪明地收集,但数量不多。
在构建各种图形和地图之前,对我们所谓的“数据集”有所帮助。
选举委员会数据分析
在圣彼得堡市有30个地区委员会;在第31栏中,我们指的是数字投票站。

每个地区委员会都有数十个PEC(区域选举委员会)。

我们最感兴趣的是每个投票站的外观以及可以观察到的依存关系。 我将基于以下内容:
从裸露的数据表很难追踪选举的进行并得出一些结论,因此图表是我们的出路。
让我们来构建我们想出的东西。
投票人数和投票站数目的依赖性 候选人对投票率的依赖性
候选人对投票率的依赖性 投票率对选民人数的依赖性
投票率对选民人数的依赖性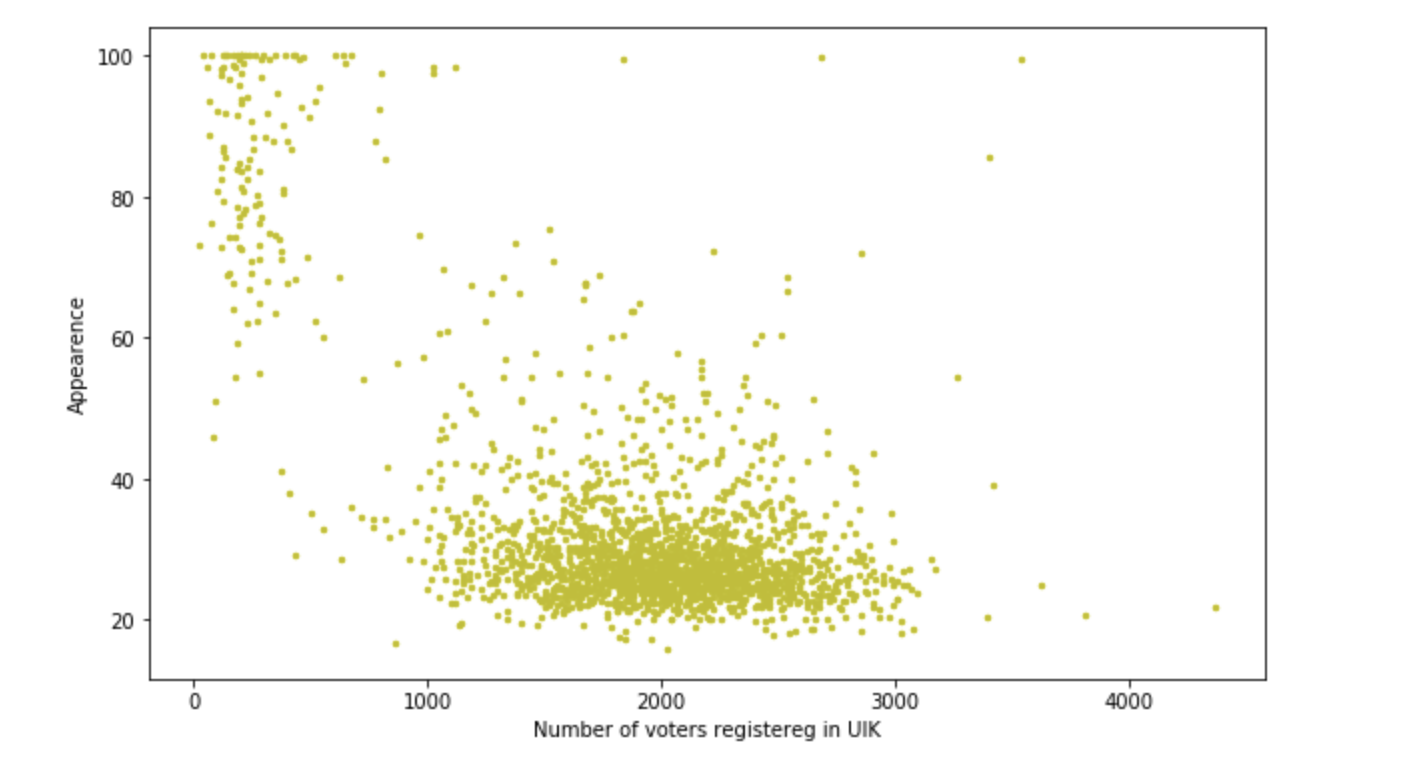
构造是可以忍受的,但是在工作过程中,发现该站点平均有400人,而Beglov的百分比是50到70,但是有两个站点的投票率大于1200,百分比为90 + -0.2。 有趣的是,这发生在这些地区。 有一些出色的搅拌器吗? 还是只开了10人的公共汽车并被迫投票? 我们很高兴地以一种或另一种方式进行了这样的小型调查。 但是我们仍然必须抽牌。 让我们继续。
视觉表示并与Geopandas合作
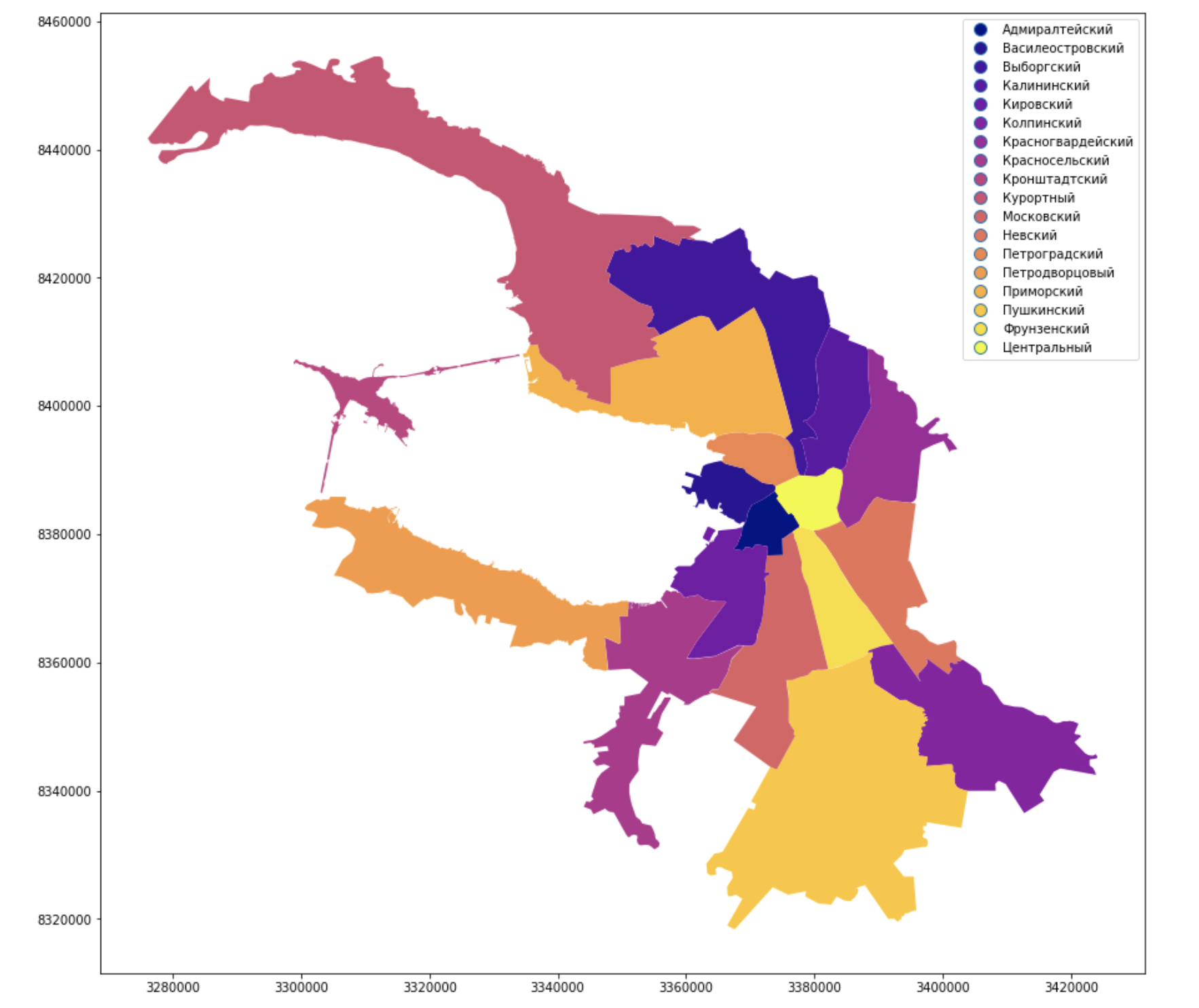
他们给城市的行政区划了油漆并签了字,看起来很熟悉,看起来像彼得,但是涅瓦河还不够。
选民人数
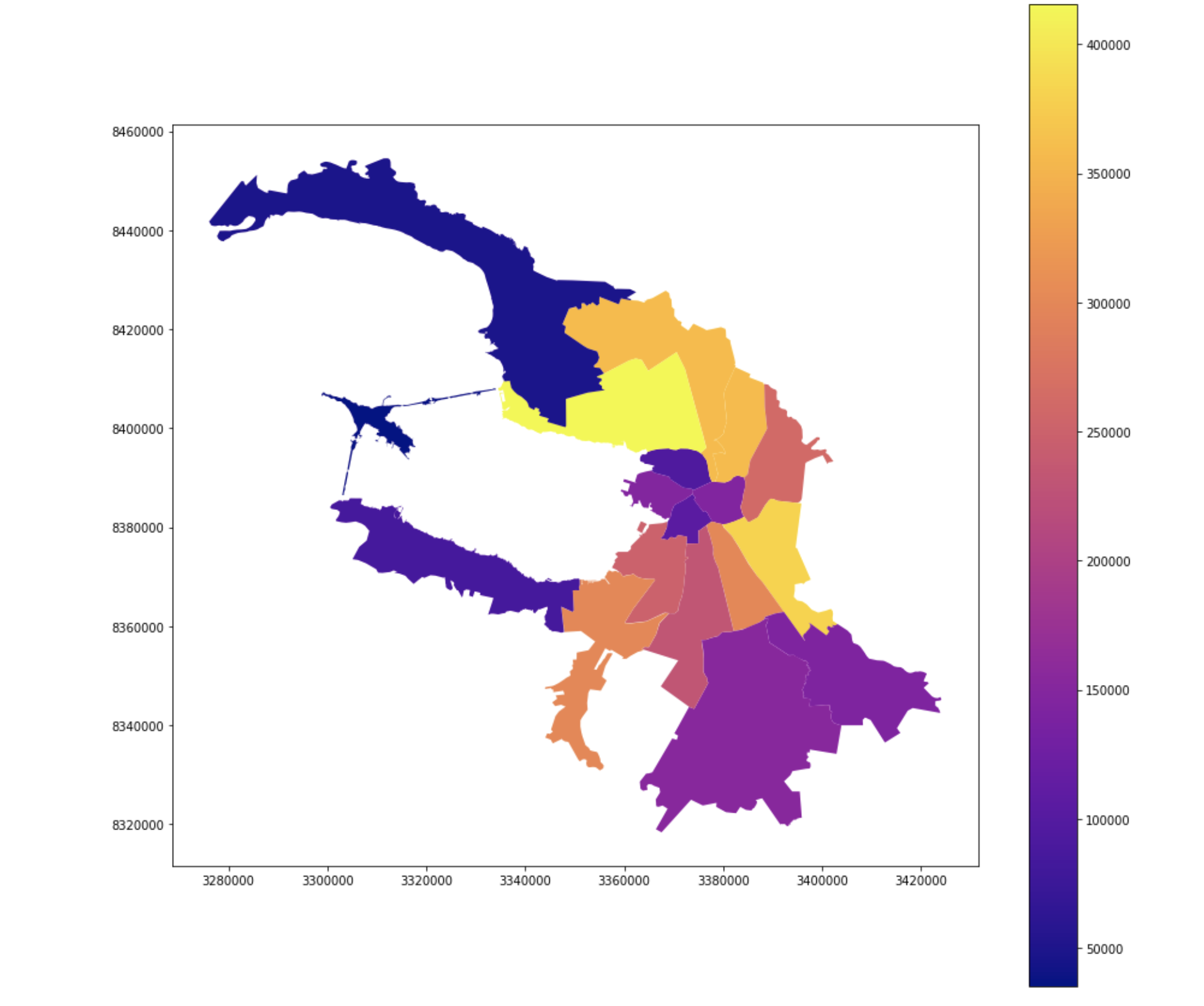 投票率
投票率

结论
您可以长时间使用数据,并在不同的领域中使用它,当然,并从中受益,因为它们的存在。 简单而复杂的地理位置可视化工具可以完成很多工作。 在评论中写下您的成功!