对于“为什么?”风格的问题 有一篇较老的文章- 自然极客时间-使空间更清洁 。
由于主观原因,很多文章不喜欢,而有些则相反,遗憾的是错过了。 我想优化此过程并节省时间。
上面的文章提出了一种在浏览器中使用脚本的方法,但是由于以下原因,我并不真正喜欢它(即使我以前使用过它):
- 对于计算机/电话上的不同浏览器,如果可能的话,您必须重新配置它。
- 作者的严格筛选并不总是很方便。
- 即使文章每年出版一次,也不想遗漏其文章的作者所遇到的问题。
根据内置在网站中的文章评分进行过滤并不总是很方便,因为高度专业化的文章(尽管具有全部价值)可以得到相当适度的评分。
最初,我想生成rss feed(或什至是一些),只留下有趣的内容。 但最后,事实证明,阅读rss似乎不太方便:无论如何,要对文章进行评论/投票/将其添加到收藏夹,您都必须通过浏览器。 因此,我为电报写了一个机器人,在PM中向我投掷了有趣的文章。 Telegram本身使它们成为漂亮的预览,结合有关作者/等级/视图的信息,看起来很有启发性。
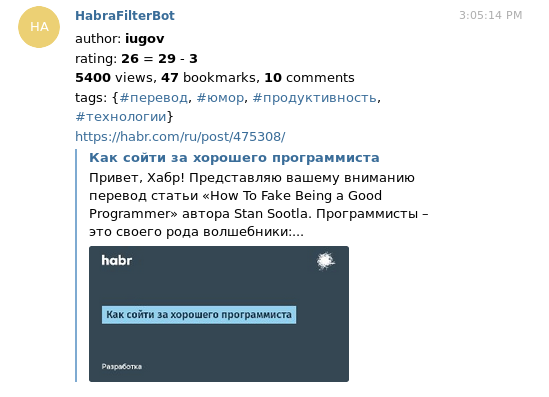
在裁切之下,详细信息包括工作特征,编写过程和技术解决方案。
简要介绍一下该机器人
仓库: https : //github.com/Kright/habrahabr_reader
电报漫游器: https : //t.me/HabraFilterBot
用户为标签和作者设置附加等级。 之后,将过滤器应用于文章-添加文章在Habré上的评分,作者的用户评分以及按标签划分的用户评分平均值。 如果该数量大于用户定义的阈值,则商品将通过过滤器。
编写机器人的一个附带目标是获得乐趣和经验。 另外,我经常提醒自己我不是Google ,因此许多事情都尽可能简单甚至原始。 但是,这并没有阻止机器人的编写过程延长三个月。
窗外是夏天
7月结束,我决定写一个机器人。 并不是一个人,而是和一个掌握了scala并想在上面写点东西的朋友一起。 一开始看起来很有希望-代码将被视为“团队”,任务似乎很简单,我认为机器人将在几周或一个月内准备就绪。
尽管我本人过去几年一直在写代码,但通常没有人看到或看到此代码:宠物项目,检查一些想法,数据预处理,掌握FP中的一些概念。 我对团队中的代码的外观非常感兴趣,因为可以用完全不同的方式编写代码。
怎么会这样呢? 但是,我们不会急于求成。
发生的所有事情都可以通过提交历史进行跟踪。
一位朋友在7月27日创建了存储库,但是什么也没做,所以我开始编写代码。
7月30日
简要地说:我写了解析Habr的rss feed。
com.github.pureconfig用于在案例类中直接读取类型安全的配置文件(事实证明非常方便)- 用于读取xml的
scala-xml :由于我最初想以xml格式编写rss磁带和rss磁带的实现,因此我使用了该库进行解析。 实际上,解析rss也出现了。 - 测试最
scalatest 。 即使对于小型项目,编写测试也可以节省时间-例如,在调试解析xml时,将其下载到文件,编写测试和修复错误要容易得多。 后来出现了一个错误的解析,该错误解析了一些带有无效utf-8字符的奇怪html,结果发现将其放入文件并添加测试更加方便。 - 来自Akka的演员。 客观上,根本不需要它们,但是该项目是出于娱乐目的而编写的,我想尝试一下。 因此,我准备说我喜欢它。 一个人可以从另一端看待OOP的想法-有些参与者交换消息。 更有意思的是-可能(并且有必要)以某种方式编写代码,使得消息可能无法到达或无法被处理(通常来说,当帐户在单台计算机上运行时,消息不应丢失)。 最初,我绞尽脑汁,在代码中有一个垃圾箱,各个演员互相订阅,但是最后,我设法提出了一个相当简单而优雅的架构。 每个actor内的代码都可以视为单线程,当actor崩溃时,Akka会重新启动它-获得了一个相当容错的系统。
8月9日
我添加了scala-scrapper项目,用于从Habr解析html页面(以提取诸如文章评级,书签数量等信息)。
和猫。 那些在岩石中。
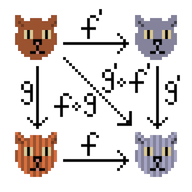
然后,我读了一本有关分布式数据库的书,我喜欢CRDT(无冲突的复制数据类型, https : //en.wikipedia.org/wiki/Conflict-free_replicated_data_type,habr )的概念,所以我为以下内容拍摄了交换半群的类型类有关哈布雷的文章的信息。
实际上,这个想法很简单-我们的计数器会单调变化。 启动子的数量增长平稳,加号的数量也增长(但是,负号的数量)。 如果我有一篇文章的两种信息版本,则可以“将它们合并为一体”-考虑更相关的计数器状态。
半组意味着可以将具有有关文章信息的两个对象合并为一个对象。 可交换意味着您可以同时合并A + B和B + A,结果不取决于顺序,因此,将保留最新版本。 顺便说一下,关联性也在这里。
例如,根据设计,解析后的rss会为文章提供稍有减弱的信息-而没有诸如观看次数之类的指标。 然后,一个特殊演员获取了有关文章的信息,并跑到html页面进行更新,并与旧版本合并。
一般来说,就像akka一样,没有必要,可以只存储文章的updateDate并在没有任何合并的情况下采用更新的版本,但是冒险之路带给我了。
8月12日
我开始变得更加自由,出于兴趣的考虑,让每个聊天对象都是一个独立的演员。 从理论上讲,一个演员本身重约300个字节,并且至少可以被数百万个演员创建,因此这是一种完全正常的方法。 在我看来,结果是一个相当有趣的解决方案:
一个参与者是电报服务器和Akka中消息系统之间的桥梁。 他只是接收消息并将其发送给所需的聊天演员。 作为响应的演员聊天可以将某些内容发送回去,并将其发送回电报中。 非常方便-这个参与者变得尽可能简单,并且只包含对消息响应的逻辑。 顺便说一句,每次聊天都涉及到有关新文章的信息,但是我再一次也看不到任何问题。
通常,该机器人已经在工作,可以响应消息,并保留发送给用户的文章列表,而我已经认为该机器人几乎已准备就绪。 我慢慢地完成了一些小小的工作,例如规范了作者和标签的名称(用“ s_d_f”替换了“ sd f”)。
只有一个很小,但是 -这个国家没有在任何地方持续存在。
一切都出了问题
您可能已经注意到,我主要是独自编写该机器人的。 因此,第二个参与者加入了开发,并且以下更改出现在代码中:
- 存储状态出现在mongoDB中。 同时,该日志在项目中中断了,因为由于某种原因,monga开始向其发送垃圾邮件,而有些人只是在全球范围内将其关闭。
- 电报中的角色桥已转变为无法识别的状态,并开始解析消息本身。
- 聊天的演员被无情地喝醉了,代替他们出现的是一个演员,他一次隐藏了所有聊天的所有信息。 每次打喷嚏,这个演员就爬上蒙古。 是的,在更新有关文章的信息时,很难将其发送给所有聊天参与者(例如Google,数百万用户正在等待每个人聊天的一百万篇文章),但是每次更新聊天时进入monga是正常的。 正如我以后很了解的那样,聊天的工作逻辑也被完全切断,并且出现了无法操作的情况。
- 这些类没有痕迹。
- 演员之间的相互排斥出现了不健康的逻辑,从而导致了比赛条件。
- 字段类型为
Option[Int]数据结构已转换为类型为-1的默认值的Int。 后来我意识到mongoDB存储json,并且在其中存储Option并没有问题,或者至少像None一样解析-1,但是那时我不知道这一点,因此相信“这是必要的”这个词。 该代码不是我编写的,因此我暂时不必更改它。 - 我发现我的公共IP地址具有更改的属性,每次必须将其添加到白名单中。 我在本地启动了bot,monga作为一家公司位于monga服务器上。
- 突然,标签的标准化和电报的消息格式消失了。 (嗯,为什么呢?)
- 我喜欢将该漫游器的状态存储在一个外部数据库中,并在重新启动后继续运行,就好像什么都没发生一样。 但是,这是唯一的优点。
第二个人并不着急,所有这些变化在9月初就已经出现在一大堆中。 我没有立即意识到破坏的程度,而是开始了解数据库的工作,因为 以前从未与他们打交道。 直到那时,我才意识到削减了多少工作代码,并增加了多少错误。
九月
起初,我认为精通Mongu并做好所有工作会很有用。 然后,我逐渐开始理解,组织与数据库的交流也是一门艺术,您可以在其中进行比赛,也可以犯错误。 例如,如果来自用户的两条消息类型为/subscribe ,并且响应每条消息,我们将在面板中创建一个条目,因为在处理这些消息时,未对用户签名。 我怀疑以现有形式与僧侣的交流不是最好的方式。 例如,用户设置是在他注册时创建的。 如果他试图在订阅之前更改它们,则该机器人无法回答,因为actor中的代码爬入了数据库的设置中,无法找到并崩溃。 问题-为什么不根据需要创建设置,我发现如果用户未订阅,则没有任何更改...邮件过滤系统以某种方式变得不明显,即使仔细查看代码,我也无法理解它是最初构思还是有一个错误。
没有发送到聊天的文章列表;相反,建议我自己编写。 这让我感到惊讶-总的来说,我并不反对将各种片段拖入项目中,但是将这些东西拉入并拧紧是合乎逻辑的。 但是,不,第二位参与者似乎忘记了一切,但他说聊天中的列表可能是一个错误的决定,您需要制作一个带有诸如“将x条发送给用户x”之类事件的标牌。 然后,如果用户请求发送新文章,则有必要向数据库发送请求,哪个事件将选择与用户相关的事件,仍然获得新文章的列表,对其进行过滤,发送给用户并将有关该事件的事件返回数据库。
机器人不仅将接收来自Habr的文章并不仅发送给电报,还会在抽象方向上遭受第二个参与者的折磨。
我以某种方式在9月下半月以单独的平板电脑形式实施了这些活动。 这不是最佳选择,但该机器人至少可以正常工作并再次开始向我发送文章,然后我慢慢弄清楚了代码中发生了什么。
现在,您可以先返回,并记住该存储库最初不是由我创建的。 怎么会这样呢? 我的游泳池要求被拒绝了。 原来,我有一个简码,我不知道如何在团队中工作,我不得不编辑当前实现曲线中的错误,而不是将其修改为可用状态。
我很沮丧,看着提交的历史,编写的代码量。 我看着原本写得很好的那一刻,然后折断了……
F * rk it
我还记得文章《你不是谷歌》 。
我以为没有实现,没有人真的需要一个主意。 我以为我想拥有一个可以在单个计算机上的单个副本中作为简单Java程序运行的bot。 我知道我的机器人可以在不重启的情况下工作几个月,因为过去我写过这样的机器人。 如果他突然摔倒而没有向用户发送下一篇文章,那么天空就不会掉落在地球上,也不会发生灾难性事件。
如果代码不能愚蠢地工作或弯曲地工作,为什么为什么需要docker,mongoDB和其他杂货店的“严重”软件?
我分叉了该项目,并按需要完成了所有工作。
大约在同一时间,我换了工作,非常缺乏空闲时间。 早上,我正好在火车上醒来,到了深夜才回来,不想再做任何事情了。 我有一段时间没有做任何事情,后来我克服了完成机器人程序的渴望,然后在早晨开车上班时开始慢慢地重写代码。 我不能说这很有用:坐在摇晃的火车上,膝上放着笔记本电脑,看看手机堆栈溢出并不是很方便。 但是,编写代码的时间完全没有被注意到,项目开始慢慢地进入工作状态。
在深处的某个地方,有一个蠕虫病毒怀疑mongoDB是否要使用,但是我认为除了“可靠”状态存储的优点之外,还有明显的缺点:
- 数据库成为另一个故障点。
- 代码越来越难了,我会写更长的时间。
- 代码变得缓慢且效率低下;更改没有发送到内存中,而是将更改发送到数据库,并在必要时撤回。
- 在单独的数据库中存储事件的类型受到限制,这些限制与数据库的功能相关。
- 在monga的试用版中,存在一些限制,如果遇到这些限制,则必须启动并配置mongu进行某些操作。
我喝了Mongu,现在僵尸程序的状态只是存储在程序内存中,并不时以json的形式保存在文件中。 也许他们在评论中会说我错了,因为这是您应该使用的地方,依此类推。 但这是我的项目,使用文件的方法尽可能简单,并且以透明的方式工作。
我抛出了-1之类的魔术值,并返回了正常的Option ,添加了一个散列表的存储,将已发送的文章返回给带有聊天信息的对象。 添加了有关五天以上的文章信息的删除,以免连续存储所有内容。 他使日志记录处于工作状态-将合理数量的日志记录到文件和控制台中。 添加了一些管理命令,例如保存状态或获取统计信息(例如用户和文章的数量)。
我修复了很多小问题:例如,文章现在指出了通过用户过滤器时视图,喜欢,不喜欢和评论的数量。 通常,令人惊讶的是必须修复多少小东西。 我列出了清单,记录了所有“粗糙度”并尽可能地对其进行了纠正。
例如,我添加了直接在一条消息中设置所有设置的功能:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
/settings命令以这种形式显示它们,您可以从中获取文本并将所有设置发送给朋友。
这似乎有些微不足道,但是有许多类似的细微差别。
以简单的线性模型的形式实现对文章的过滤-用户可以为作者和标签设置附加等级以及阈值。 如果作者的评分,标签的平均评分和文章的实际评分之和大于阈值,则会向用户显示该文章。 您可以使用/ new命令向机器人询问文章,或者订阅该机器人,它将在一天中的任何时间在PM中投掷文章。
一般而言,我对每篇文章都有一个想法,以画出更多的符号(轮毂,注释,书签的数量,等级变化的动态,文章中的文本,图片和代码的数量,关键字),并让用户在每篇文章中都表示可以/不可以文章并为每个用户训练模型,但是我变得太懒了。
此外,工作逻辑不会那么明显。 现在,我可以手动将PatientZero的评分定为+9000,并且将阈值评分定为+20,我将保证会收到他的所有文章(当然,除非我为任何标签都放置-100500)。
产生的架构非常简单:
- 存储所有聊天和文章状态的演员。 它从磁盘上的文件加载其状态,并不时将其保存回新文件。
- 偶尔遇到rss feed的演员会学习新文章,查看链接,进行解析,然后将这些文章发送给第一位演员。 此外,他有时会要求第一位演员提供文章列表,选择不超过三天但很长时间没有更新的文章,然后进行更新。
- 与电报进行通信的演员。 我仍然在这里完全解析消息。 我想以一种很好的方式将其分为两部分,以便其中一个分析传入的消息,而第二个解决传输问题,例如转发未发送的消息。 现在没有重新发送,并且由于错误而未到达的消息将简单地丢失(除了将在日志中将其标记),但是到目前为止这不会引起问题。 如果一群人订阅了该漫游器,而我达到了发送消息的极限,则可能会出现问题。
我喜欢的-感谢akka,actor 2和3的倒台一般不会影响机器人的性能。 也许有些文章没有及时更新,或者某些消息没有到达电报中,但是Akka重新启动了actor,一切继续进行下去。 我保存的信息是,仅当电报演员回复他成功发送消息时,该文章才会显示给用户。 威胁我的最糟糕的事情是多次发送一条消息(如果已发送,但确认以某种未知的方式丢失了)。 原则上,如果第一个演员没有保留自己的状态,而是与某种数据库进行通信,那么他也可以安静地跌倒并恢复生活。 我也可以尝试akka持久性来恢复参与者的状态,但是当前的实现方式非常简单。 并不是我的代码经常崩溃—相反,我付出了很多努力使这不可能。 但是,事情发生了,将程序拆分成孤立的演员的功能对我来说确实很方便和实用。
添加了circle-ci以便在代码中断时立即知道它。 至少该代码已停止编译。 最初,我想添加travis,但它仅显示我的项目,而没有显示分叉的项目。 通常,这两种东西都可以在开放存储库中自由使用。
总结
已经是十一月了。 该机器人是书面的,我在过去的两个星期中一直使用它,而且我喜欢它。 如果您有改进的想法,请写下。 我看不到将其货币化的意义-让它正常工作并发送有趣的文章。
链接到机器人: https : //t.me/HabraFilterBot
GitHub: https : //github.com/Kright/habrahabr_reader
小结论:
- 即使是一个小项目也可能需要很长时间。
- 您不是Google。 用大炮射麻雀是没有意义的。 一个简单的解决方案也可以工作。
- 宠物项目非常适合尝试新技术。
- 电报机器人的编写非常简单。 如果不是为了“团队合作”和技术试验,那么该机器人将在一两个星期内被编写出来。
- actor模型很有趣,可以与多线程和代码弹性配合使用。
- 我似乎自己感觉到开源社区为什么喜欢叉子。
- 数据库的优点在于,应用程序的状态不再取决于应用程序的崩溃/重新启动,而是与数据库一起使用会使代码复杂化,并对数据结构施加限制。