最近,举行了
ID R&D语音反欺骗挑战赛 ,其主要任务是创建一种可以从合成记录(欺骗)中区分人声的算法。 我是Dasha AI的ML研究员,并且在语音识别方面做了大量工作,因此我决定参加。 与团队一起我们获得了第一名。 在剪辑中,我将讨论声音处理的新方法,以及我们必须面对的困难和奇怪之处。
共有98人参加了比赛-人数很少,因为这是在俄罗斯平台上甚至在docker上进行声音处理的比赛。 我与Kaggle Master的德米特里·丹内夫斯基(Dmitry Danevsky)在一个团队中,我们见面并同意参加,同时讨论另一场比赛的方法。
挑战赛
我们获得了5 GB的音频文件,分为欺骗/人类类,我们必须预测该类的可能性,将其包装在docker中并将其发送到服务器。 该解决方案应该可以在30分钟内运行,并且重量不到100 MB。 根据官方信息,有必要区分一个人的声音和自动生成的声音-尽管就我个人而言,欺骗类还包括通过将扬声器保持在麦克风上来生成声音的情况(就像攻击者通过窃取他人声音的录音来进行识别)。
指标是
EER :
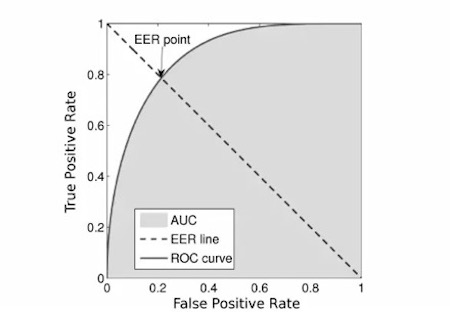
我们采用了网络上的
第一个代码 ,因为
组织者的
代码似乎超载了。
比赛项目
组织者提供了基线,同时也提供了比赛的主要谜语。 就像一根棍子一样简单:我们获取音频文件,计算
粉笔频谱图 ,训练MobileNetV2并发现自己位于第12位或更低的位置。 因此,许多人会认为有十几个人参加了比赛,但事实并非如此。 在整个比赛的第一阶段,我们的团队无法打破这个基线。 理想情况下,相同的代码会使结果差得多,并且任何改进(例如用较重的网格替换和
OOF预测)都有帮助,但并没有使其接近基线。
然后出乎意料的事情发生了:比赛结束前大约一周,事实证明组织者指标的实施包含一个错误,并取决于预测的顺序。 大约在同一时间,发现组织者没有在docker容器中关闭互联网,因此许多人下载了测试样本。 然后比赛被冻结了4天,更正了指标,更新了数据,关闭了Internet,然后又开始了2周。 重新计算后,我们的第一个提交材料名列第七。 这是继续参加比赛的强大动力。
谈到模特
我们使用了经过粉笔频谱图训练的类似于Resnet的卷积网格。
- 总共有5个这样的块,在每个这样的块之后,我们进行了深入的监督,并将过滤器的数量增加了一半半。
- 在比赛中,我们从二元分类转变为多分类,以便更有效地利用混合技术,在混合技术中,我们将两种声音混合并汇总其类别标签。 此外,经过这样的过渡,我们可以通过将欺骗类乘以1.3来人为地增加欺骗类的概率。 这有助于我们,因为有一个假设,即测试样本中的类平衡可能不同于训练样本,因此我们提高了模型的质量。
- 对折叠模型进行了训练,并对几种模型的预测结果进行了平均。
- 频率编码技术也派上了用场。 底线是:2D卷积是位置不变的,并且在频谱图中,沿垂直轴的值具有非常不同的物理含义,因此我们希望将此信息传递给模型。 为此,我们将频谱图和矩阵连接起来,由从下到上从-1到1的段中的数字组成。
为了清楚起见,我将给出代码:
n, d, h, w = x.size() vertical = torch.linspace(-1, 1, h).view(1, 1, -1, 1) vertical = vertical.repeat(n, 1, 1, w) x = torch.cat([x, vertical], dim=1)
- 我们对所有这些进行了训练,包括从第一阶段泄漏的测试样本中获得的伪标签数据 。
验证方式
从比赛一开始,所有参与者都被一个问题折磨:为什么本地验证的EER为0.01和更低,而排行榜为0.1,却没有特别相关? 我们有两个假设:要么数据中有重复项,要么在一组说话者上收集了训练数据,而在另一组说话者上收集了测试数据。
真相介于两者之间。 在训练数据中,大约有5%的数据被证明是重复的,并且这仅计算了哈希的完全重复(顺便说一句,它也可能包含同一文件的不同部分,但是检查起来并不容易-这就是为什么我们没有这样做)。
为了检验第二个假设,我们训练了一个说话者ID网格,接收了每个说话者的嵌入,将它们与k均值聚类,然后对其进行折叠分层。 即,我们训练了来自一个集群的发言人,并预测了来自其他集群的发言人。 这种验证方法已经开始与排行榜相关联,尽管它的得分要高出3-4倍。 作为替代方案,我们尝试仅对模型至少不确定的预测进行验证,也就是说,预测与类别标签之间的差异为> 10 **-4(0.0001),但这种方案未带来结果。
而且什么没用?
在Internet上,只需查找数千小时的人类语音就足够了。 此外,几年前已经举行过类似的比赛。 因此,下载大量数据(我们下载了约300 GB)并为此训练分类器似乎是一个显而易见的主意。 在某些情况下,如果我们在达到平稳状态之前就附加数据和训练数据进行了教学,那么对此类数据的训练就证明了一点点,然后我们仅对训练数据进行了训练。 但是,通过这种方案,模型可以在大约2天的时间内收敛,这意味着所有折叠都需要10天。 因此,我们放弃了这个想法。
另外,许多参与者注意到文件长度和类别之间的相关性;在测试样本中没有注意到这种相关性。 诸如resnext,nasnet-mobile,mobileNetV3之类的普通图片网格显示效果不佳。
后记
这并非易事,有时甚至很奇怪,但我们仍然获得了很棒的经验,并脱颖而出。 通过反复试验,我意识到哪些方法行之有效,哪些方法不是很好。 现在,我将在处理声音时利用这些见解。 我努力将对话式AI提升到与人类无法区分的水平,因此一直在寻找有趣的任务和筹码。 希望您也学到了一些新知识。
好吧,最后,我发布
了代码 。