今天,我们要讨论基于洞察力的概念以及如何使用DataOps和ModelOps将其付诸实践。 洞察驱动方法是一个全面的主题,我们在最近创建的有关数据管理的有用材料库中对此进行了详细讨论(链接将在下面)。 在当今的habratopica中,我们将专注于机器学习模型生命周期的关键阶段, 这是概念中的主要主题之一。

洞察驱动方法的本质是什么
长期以来,许多专家一直在谈论
数据驱动的重要性,这在总体上是绝对正确的,因为这种方法涉及通过分析数据而不是凭直觉和个人领导经验来提高管理决策的效率。 Forrester分析师
指出 ,在活动中依靠数据分析的公司平均比竞争对手快30%。
但是我们所有人都知道,该公司不是从数据本身的可用性而是从与它们一起工作的能力而向前迈进,也就是说,寻找可以被货币化的见解,并且值得收集,处理和分析数据。 因此,我们在专门讨论Insight驱动方法,它是Data-Driven的更高级版本。
通常,在处理数据时,大多数专家主要是指公司内部的结构化信息,但是不久前,我们谈到了为什么绝大多数业务未使用约80%的潜在可用数据。 Insight-Driven只是为用外部非结构化信息以及图片解释结果来寻找图片之间的隐式依赖关系补充图片的基础。
所承诺的链接将指向有关数据管理的完整资料库 ,其中提到了有关未使用数据的视频。
DevOps + DataOps + ModelOps
Insight驱动的实践基于DevOps,DataOps和ModelOps。 让我们谈谈为什么将这些特定实践结合起来可以确保该方法的完整实施。
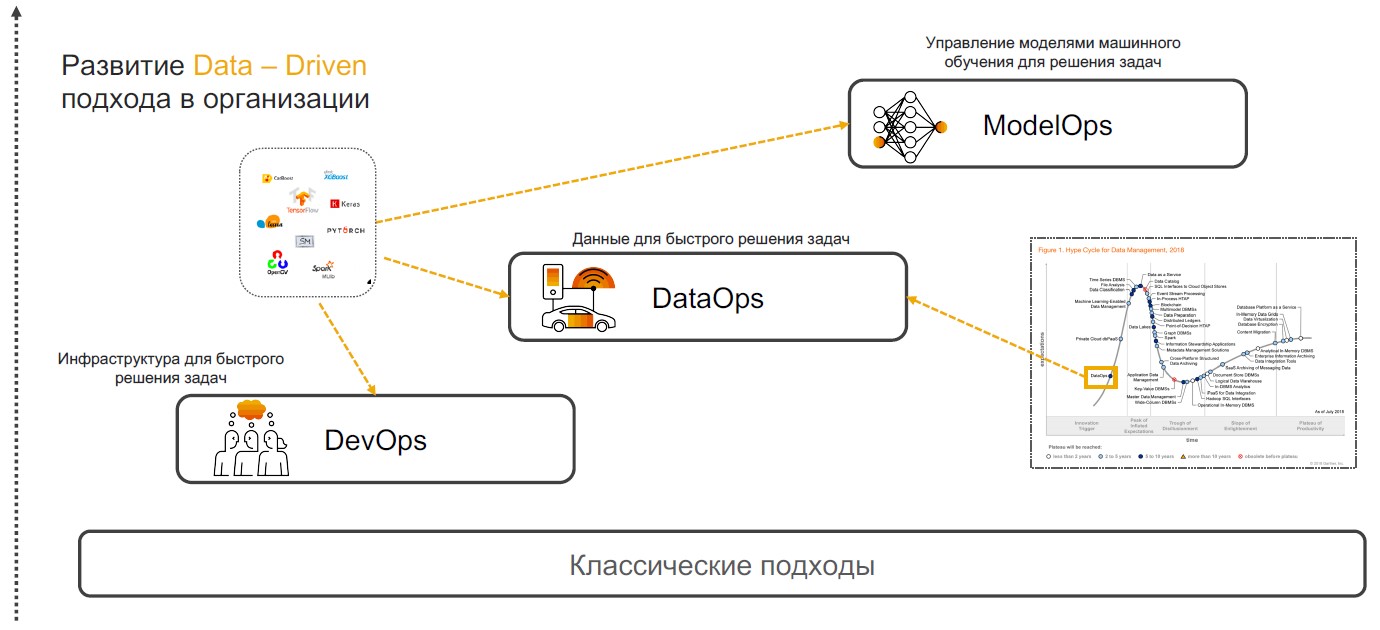 DevOps + DataOps
DevOps + DataOps 。 DevOps涉及通过使用用于版本控制,持续集成,测试和监视,发布管理的工具来减少产品发布,更新的时间,并最大程度地降低进一步支持的成本。 如果我们在这些实践中加深对公司内部数据的了解,如何管理其格式和结构,标签,跟踪质量,转换,聚合并具有快速分析和可视化的能力,那么我们将获得
DataOps 。 该方法的重点是使用机器学习模型来实现场景,该模型提供决策支持,洞察力搜索和预测。
模型操作 。 一旦公司开始积极使用机器学习模型,就必须管理它们,监视质量指标,重新培训,比较,更新和版本化。 ModOps是一组可简化此类模型的生命周期管理的实践和方法。 公司在业务的各个领域中处理大量模型的公司使用它,例如,流服务。
在公司中实施“洞察驱动”方法并非易事。 但是对于仍然希望与他合作的人,我们将告诉您如何进行。
搜索和数据准备
洞察驱动实践的实施始于数据的搜索和准备。 后来,对它们进行了分析,并用于建立MO的模型,但是先前已经确定了可以使用智能算法的情况。
任务的定义 。 在此阶段,公司设定业务目标,例如,增加市场利润。 接下来,确定要实现这些目标的业务指标,例如新客户数量的增加,平均支票的大小以及转化百分比。 因此,在某些情况下已经可以搜索相关数据。
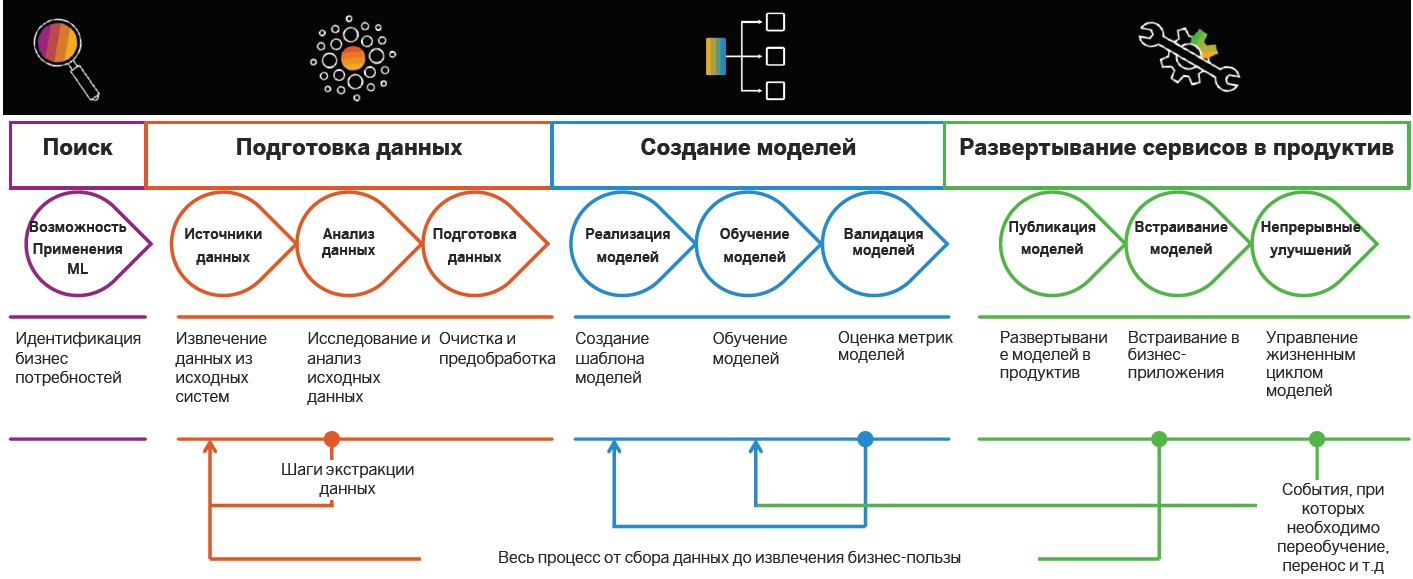 采购和数据分析
采购和数据分析 。 定义了数据检索的目标和方向后,就该对源进行分析了。 与准备相关的智能场景开发的此阶段和后续阶段占实施中公司预算的70-80%。 事实是,数据集的质量会影响设计的机器学习模型的准确性。 但是,必要的信息通常“分散”在各个系统上-它可以位于关系数据库中,例如Hadoop平台上的MS SQL,Oracle,PostgreSQL,以及许多其他来源。 在此阶段,您需要了解相关数据在哪里以及如何收集它们。
分析人员通常会手动卸载和处理所有内容,这极大地减慢了流程并增加了出错的风险。 SAP我们为客户提供实施连接到正确来源的元系统,并根据请求收集数据的方法。
因此,您可以对所有表,具有非结构化数据的外部池以及其他来源进行分类-设置标签(包括分层标签)并快速收集相关信息。 有条件地,如果有关客户端的信息位于不同的数据库中,则足以指示这些实体。 下次需要“客户数据集”时,您将选择一个现成的展示柜。
确定数据源后,您可以继续
进行数据质量跟踪和分析 。 该操作对于了解间隙数,唯一值和验证数据的整体质量是必需的。 为此,您可以使用规则构建仪表板并跟踪所有更改。
数据转换 。 下一步是直接使用应解决任务的数据。 为此,将清除数据:检查,重复数据删除,填充空白。 可以使用基于流的编程来简化此过程。 在这种情况下,我们要处理一系列操作-管道。 它的输出可以发送到图形界面或其他系统以进行后续工作。 在这里,数据处理程序被组装为构造函数(并取决于情况)。 这可以是定期处理或流处理,也可以是REST服务。

基于流程的编程概念适用于解决各种任务:从预测销售和评估服务质量到找到导致客户外流的原因。 在SAP中有两种用于搜索和准备数据的工具。 首先是面向数据分析师的
SAP Data Intelligence 。 与类似的平台不同,此解决方案可处理分布式数据,并且不需要集中化-它为模型的实现,发布,集成,缩放和支持提供了统一的环境。 第二个工具是
SAP Agile Data Preparation ,这是面向分析师和业务用户的小型数据准备服务。 它具有一个简单的界面,有助于收集数据集,过滤器,过程和地图信息。 可以将其发布在用于传输自助服务BI的展示柜中,自助服务BI是用于创建分析方案的自助服务系统(它们不需要在数据科学领域的深入了解)。
模型制作
准备之后,就该创建机器学习模型了。 这里有特色:研究,原型制作和生产率。 最后阶段包括实现模型训练和应用的管道。
研究和原型设计 。 当前,有许多主题框架和库可供使用。 使用频率的领导者是TensorFlow和PyTorch,在过去一年中,它们的普及率
增长了243%。 SAP平台允许您使用任何这些框架,并且可以灵活地补充库,例如Yandex的CatBoost,Microsoft的LightGBM,scikit-learn和pandas。 您仍然可以在hanaml库中使用
HANA DataFrame 。 该API模仿大熊猫,HANA允许您使用惰性计算处理大量数据。
对于原型模型,我们提供Jupyter Lab。 这是面向数据科学专业人员的开源工具。 我们将其内置到SAP生态系统中,同时扩展了功能。 Jupyter Lab在Data Intelligence平台中工作,由于内置了sapdi库,它可以连接到先前步骤中连接的任何数据源,监视实验和质量指标以进行进一步分析。
另外,值得注意的是,笔记本,数据集,训练和
推理管道以及用于部署模型的服务应保持一致。 要组合所有这些对象,请使用ML脚本(版本对象)。
模型训练 。 使用ML脚本有两个选择。 有些模型根本不需要训练。 例如,在SAP Data Intelligence中,我们提供人脸识别系统,自动翻译,OCR(光学字符识别)等。 他们都开箱即用。 另一方面,有些模型需要训练和生产。 这种训练既可以在数据智能集群本身中进行,也可以在仅在计算期间连接的外部计算资源上进行。
SAP Data Intelligence中的“底层”是Kubernetes平台,因此所有操作员都与Docker容器绑定在一起。 要使用该模型,只需描述docker文件并为使用的库和版本添加标签即可。
创建模型的另一种方法是使用AutoML。 这些是自动化的MO系统。 此类工具由
H2O ,
Microsoft ,
Google等开发
。 他们
在麻省理工学院朝着这个方向努力。 但是大学工程师并不专注于嵌入和生产力。 SAP还拥有一个专注于快速结果的AutoML系统。 它可以在HANA中运行,并且可以直接访问数据-无需在任何地方移动或修改它们。 现在,我们正在开发专注于模型质量的解决方案-我们将在稍后发布版本。
生命周期管理 。 条件改变,信息变得过时,因此MO模型的准确性会随着时间的推移而降低。 因此,在积累了新数据之后,我们可以重新训练模型并优化结果。 例如,一家主要的饮料生产商
使用 200个不同国家/地区的消费者偏好信息来重新培训智能系统。 该公司考虑了人们的口味,糖的含量,饮料的卡路里含量,甚至包括竞争品牌在目标市场中提供的产品。 MO模型自动确定公司在给定地区最能接受的数百种产品中的哪一种。
 在SAP Data Hub中重用基于代理的组件
在SAP Data Hub中重用基于代理的组件但是,随着新算法和硬件组件更新的发布,版本控制和更新模型也需要完成。 它们的实现可以提高工作中使用的模型的准确性和质量。
洞察力推动业务增长
实际上,上述用于管理机器学习模型生命周期阶段的方法是一个通用框架,该框架使公司能够以洞察力为驱动力,并将数据工作作为推动业务增长的关键驱动力。 体现此概念的组织知道更多,增长更快,并且在我们看来,使用该尖端技术将变得更加有趣!
在我们
的有用数据管理资料库中了解有关构建洞察驱动概念的更多信息,我们在其中收集了视频,有用的手册以及对SAP系统的试用访问。