嗨,我叫尤金。 我在Yandex.Market搜索基础架构中工作。 我想向Habr社区介绍市场的内部厨房-但有一些要说的。 首先,市场搜索,流程和体系结构如何工作。 我们如何处理紧急情况:如果一台服务器崩溃,该怎么办? 如果有100个这样的服务器?
您还将了解我们如何立即在一堆服务器上实现新功能。 以及如何在生产中直接测试复杂的服务而又不给用户带来任何不便。 通常,搜索市场是如何进行的,这样每个人都可以。
关于我们的一点:我们要解决什么问题
输入文本时,按参数查找产品或比较不同商店中的价格,所有请求都会到达搜索服务。 搜索是市场中最大的服务。
我们处理所有搜索查询:来自网站market.yandex.ru,beru.ru,Supercheck服务,Yandex.Advisor和移动应用程序。 我们还在yandex.ru的搜索结果中包含商品的报价。
对于搜索服务,我的意思是不仅可以直接搜索,还可以指一个包含市场上所有报价的数据库。 规模是这样的:每天处理超过十亿个搜索查询。 一切都应该快速工作,而不会受到干扰,并始终产生预期的结果。
什么是市场架构
简要描述市场的当前架构。 按照惯例,可以通过以下方案对其进行描述:
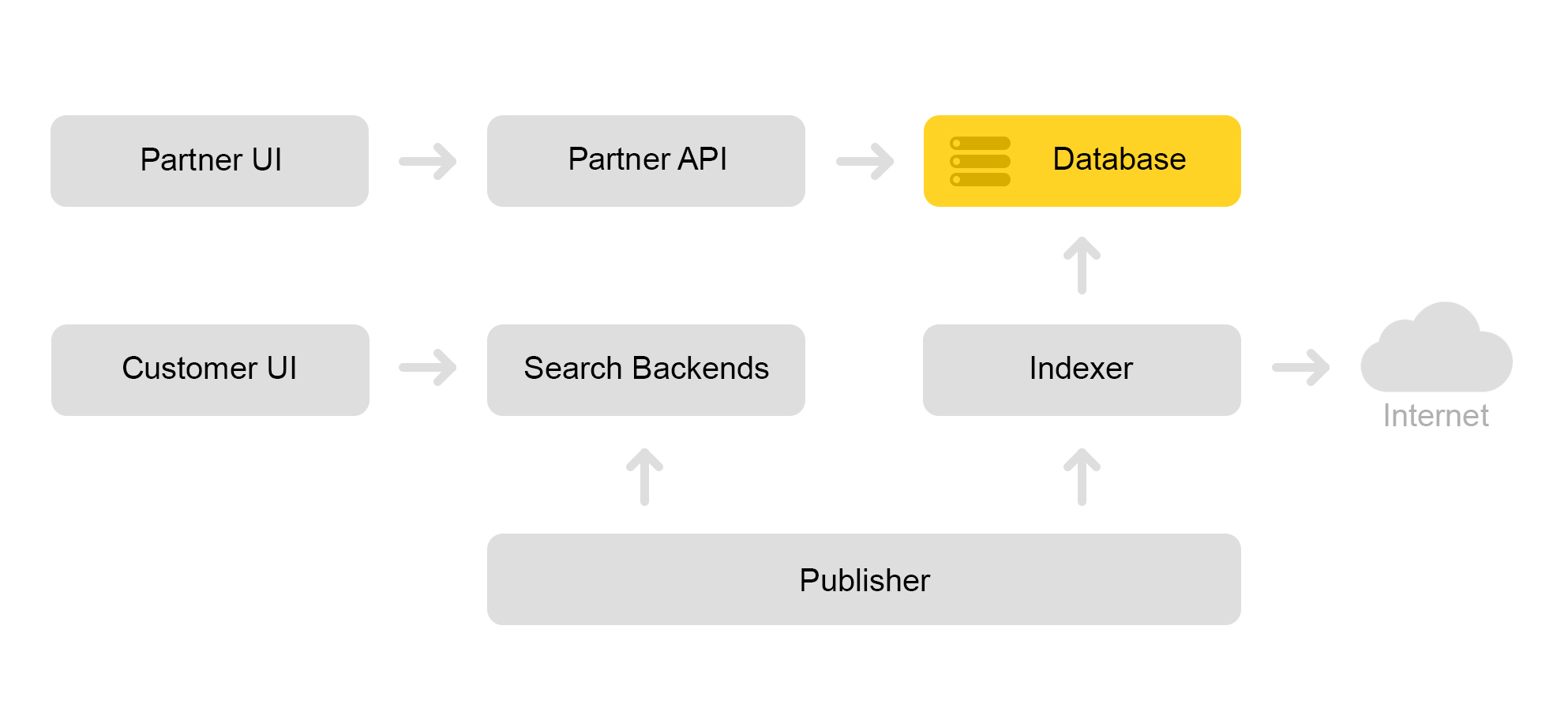
假设有一家合作伙伴商店来找我们。 他说我想卖一个玩具:这只带尖叫声的邪恶猫。 一只没有高音喇叭的邪恶猫。 还有一只猫。 然后,商店需要准备市场要搜索的报价。 该商店与要约形成一个特殊的xml,并通过合作伙伴接口将该xml的路径通信。 然后,索引器会定期下载此xml,检查错误并将所有信息存储在一个巨大的数据库中。
有很多这样保存的xml。 从该数据库创建搜索索引。 索引以内部格式存储。 创建索引后,布局服务将其上载到搜索引擎。
结果,数据库中出现了带有squeaker的邪恶猫,服务器上也出现了cat索引。
我将在搜索架构部分中讨论我们如何寻找一只猫。
市场搜索架构
我们生活在微服务的世界中:每个对
market.yandex.ru的传入请求
都会引起很多子查询,并且数十个服务参与其处理。 该图仅显示了一些:
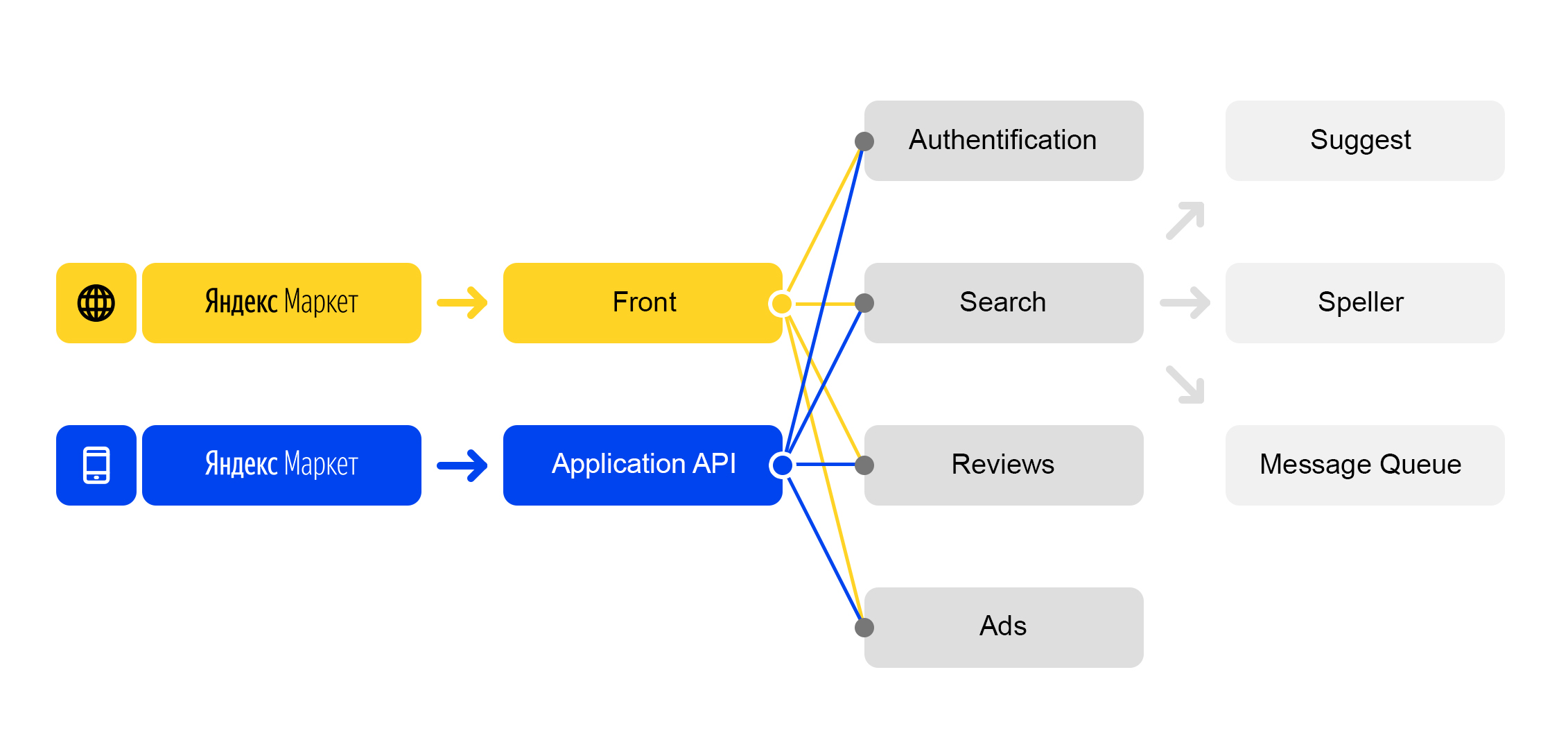 简化的请求处理方案
简化的请求处理方案每个服务都有一个奇妙的东西-它自己的平衡器具有唯一的名称:
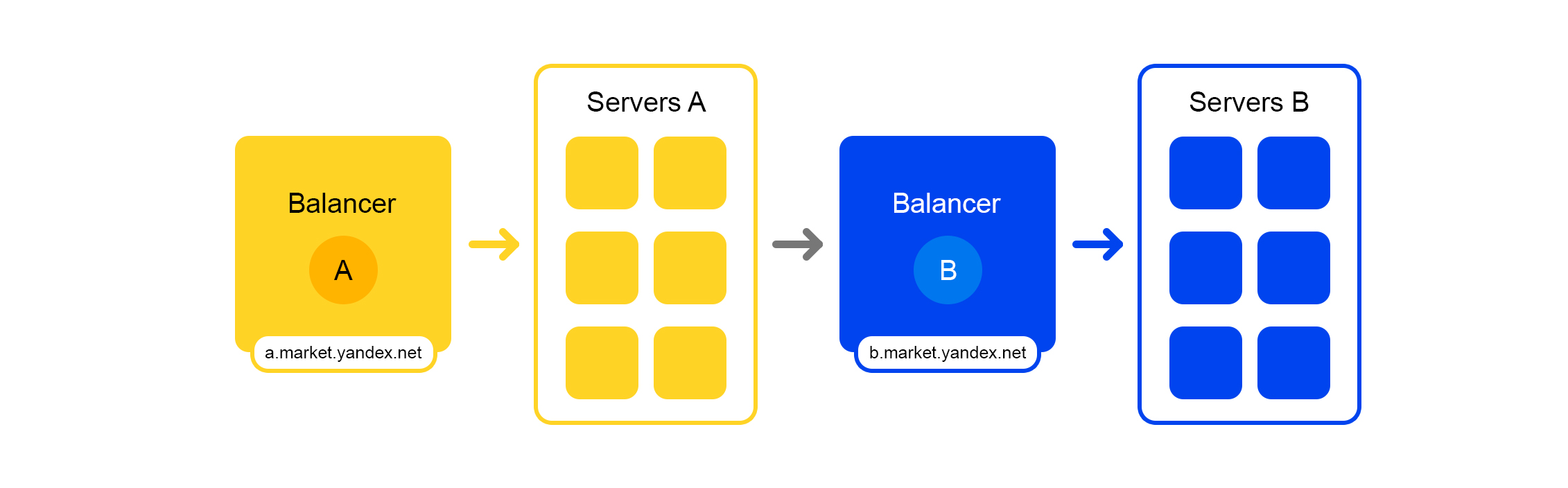
平衡器使我们在管理服务方面具有极大的灵活性:例如,您可以关闭服务器,这通常是更新所必需的。 平衡器发现服务器不可用,并自动将请求重定向到其他服务器或数据中心。 添加或删除服务器时,负载会自动在服务器之间重新分配。
平衡器的唯一名称不依赖于数据中心。 当服务A向B发出请求时,默认情况下,平衡器B将请求重定向到当前数据中心。 如果该服务在当前数据中心不可用或不存在,则该请求将重定向到其他数据中心。
所有数据中心的单个FQDN使服务A通常可以从位置脱离。 他对服务B的请求将始终得到处理。 当服务位于所有数据中心时,情况例外。
但是使用该平衡器并不是一切都那么美好:我们还有一个额外的中间组件。 平衡器可能不稳定,并且冗余服务器可以解决此问题。 服务A和服务B之间还存在一个额外的延迟。但是实际上,该延迟小于1毫秒,对于大多数服务来说,这并不重要。
应对意外情况:平衡和弹性的搜索服务
想象一下发生了崩溃:您需要找到带有尖叫声的猫,但是服务器崩溃了。 或100台服务器。 如何下车? 我们真的要让使用者没有猫吗?
情况糟透了,但我们已经做好了准备。 我会按顺序告诉你。
搜索基础架构位于几个数据中心:
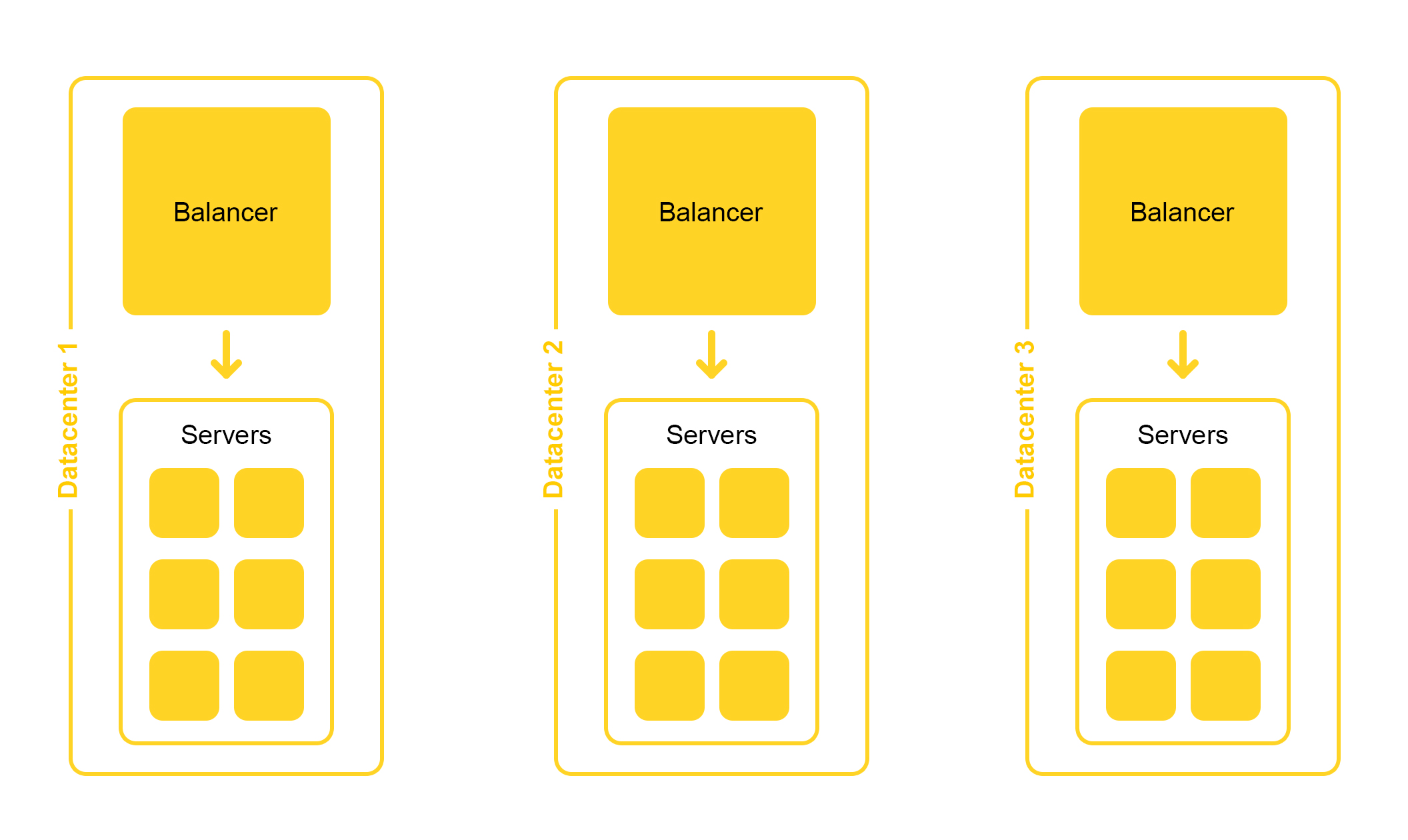
在设计时,我们提供了禁用一个数据中心的可能性。 生活充满惊喜-例如,挖掘机可以切断地下电缆(是的,就是这样)。 其余数据中心的容量应足以承受峰值负载。
考虑单个数据中心。 在每个数据中心中,平衡器的方案相同:
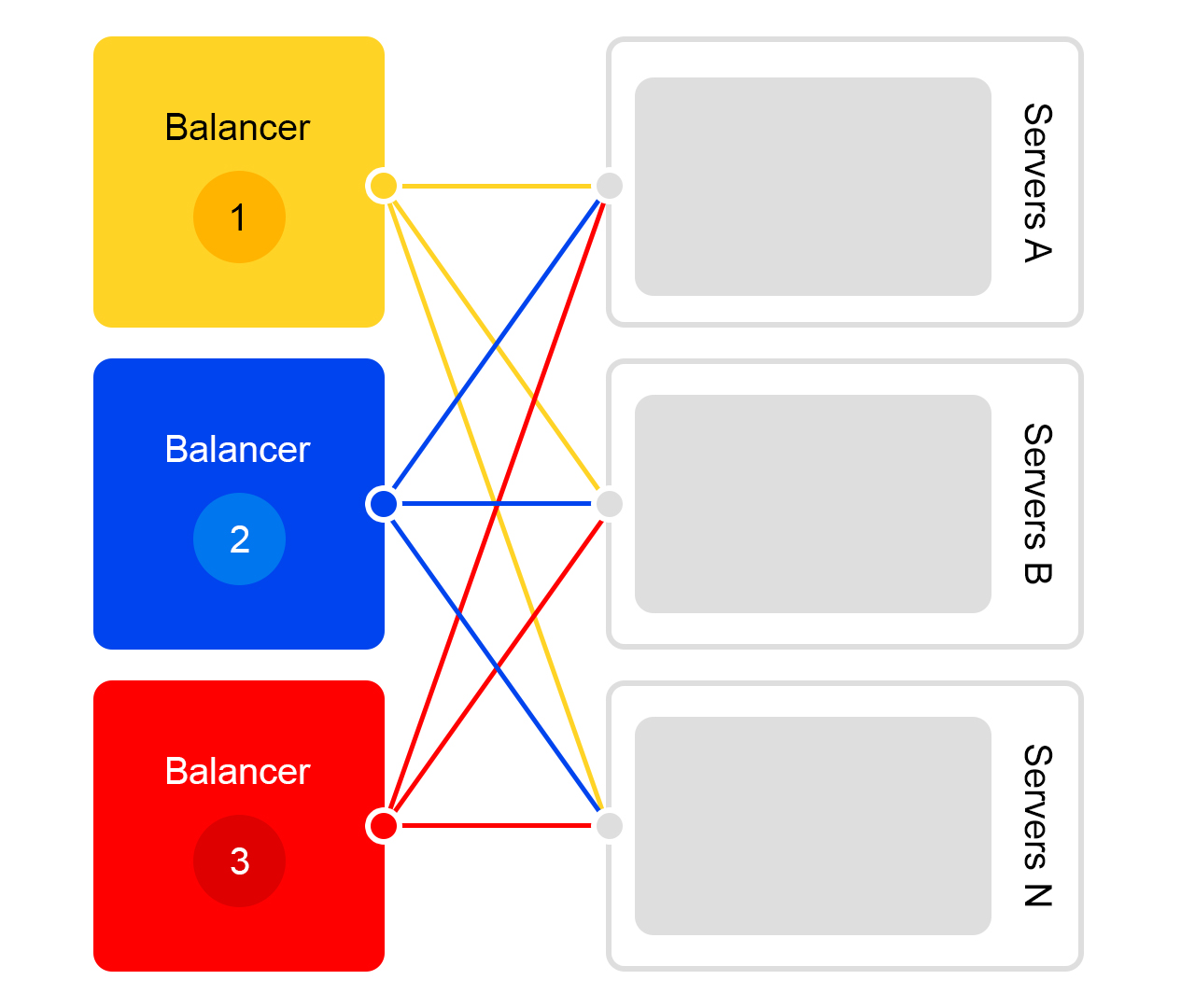
一个平衡器至少是三台物理服务器。 这样的冗余是为了可靠性。 平衡器可用于HAProx。
我们选择HAProx是因为它具有高性能,小的资源需求和广泛的功能。 在每个服务器内部,我们的搜索软件都可以运行。
一台服务器发生故障的可能性很小。 但是,如果您有许多服务器,则至少一台服务器崩溃的可能性将会增加。
实际情况就是这样:服务器崩溃。 因此,您必须不断监视所有服务器的状态。 如果服务器停止响应,则它将自动与流量断开连接。 为此,HAProxy具有内置的运行状况检查。 每秒一次对所有具有HTTP请求“ / ping”的服务器进行处理。
HAProxy的另一个功能:代理检查允许您均匀加载所有服务器。 为此,HAProxy连接到所有服务器,并根据当前负载(从1到100)返回它们的权重。权重是根据处理队列中的请求数和处理器负载来计算的。
现在开始寻找猫。 表格
/搜索的查询?文本=愤怒+猫到达
搜索 。 为了快速搜索,必须将整个cat索引放置在RAM中。 即使从SSD读取数据也不够快。
曾几何时,报价基数很小,并且有足够的RAM用于一台服务器。 随着提案数据库的增长,所有内容都不再适合该RAM,并且数据分为两部分:分片1和分片2。

但是它总是会发生:任何解决方案,即使是好的解决方案,都会引起其他问题。
平衡器仍然可以访问任何服务器。 但是在发出请求的机器上,索引只有一半。 其余的在其他服务器上。 因此,服务器必须转到某个相邻的计算机。 从两台服务器接收数据后,将结果合并并重新组织。
由于平衡器平均分配请求,因此所有服务器都在进行重新排列,而不仅仅是提供数据。
如果相邻服务器不可用,则会出现问题。 解决方案是将多个具有不同优先级的服务器指定为“相邻”服务器。 首先,请求已发送到当前机架中的服务器。 如果未收到响应,则将请求发送到该数据中心中的所有服务器。 最后但并非最不重要的一点是,请求转到了其他数据中心。
随着提案数量的增加,数据分为四个部分。 但这不是极限。
现在使用八个分片的配置。 另外,为了进一步节省内存,索引被分为搜索部分(通过其进行搜索)和代码段部分(不与搜索相关)。
一台服务器仅包含一个分片的信息。 因此,要对全索引执行搜索,需要在包含不同分片的八台服务器上进行搜索。
服务器按群集分组。 每个群集包含八个搜索引擎和一个摘要。
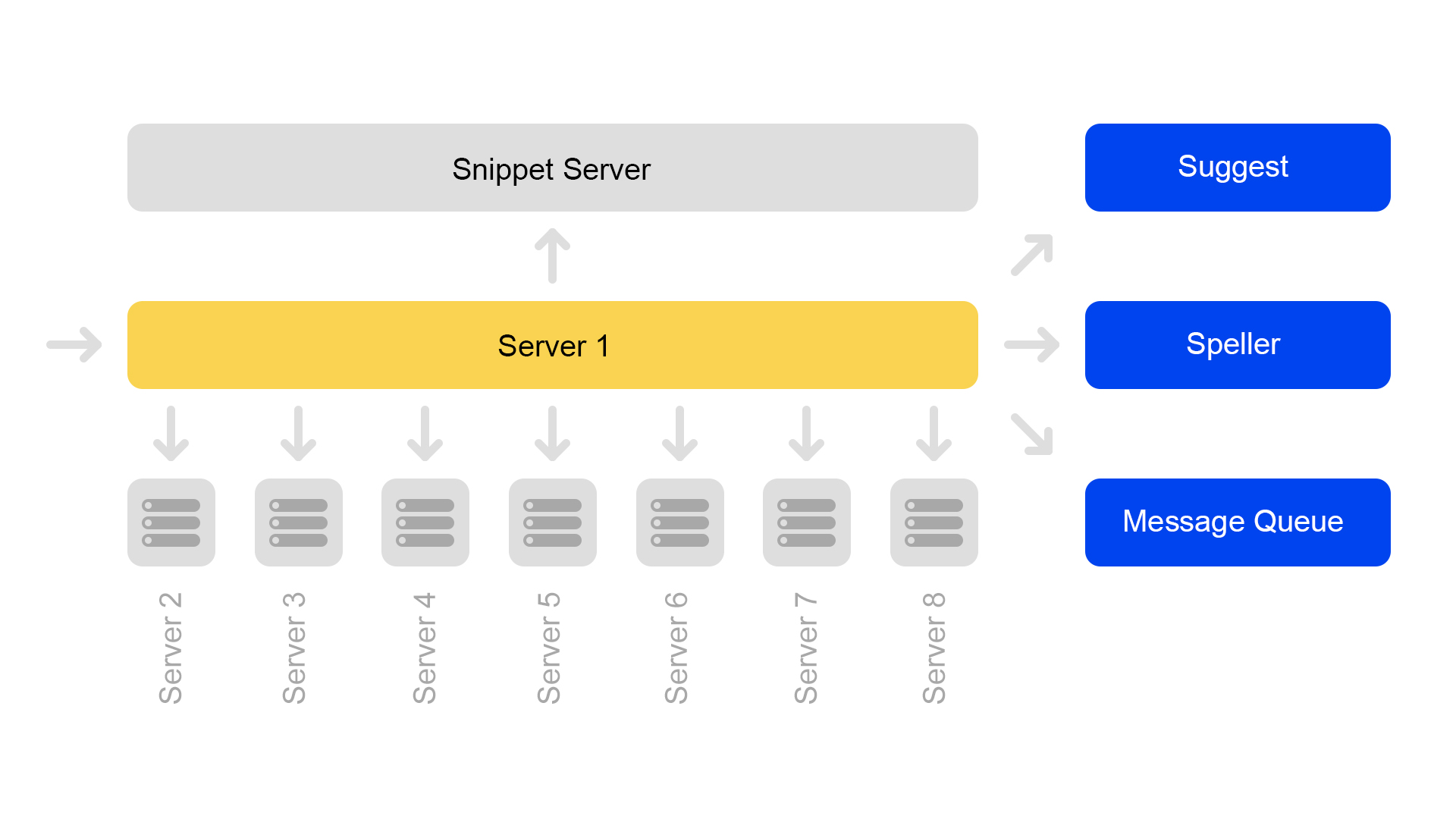
包含静态数据的键值数据库正在代码段服务器上运行。 发行文件时需要使用它们,例如,对带有尖叫声的猫的描述。 数据专门在单独的服务器上取出,以免加载搜索引擎的内存。
由于文档ID仅在一个索引的框架内是唯一的,因此可能会出现以下情况:片段中没有文档。 好吧,或者在一个ID上会有其他内容。 因此,为了使搜索工作并进行搜索,出现了对整个群集的一致性的需求。 稍后我将讨论我们如何监控一致性。
搜索本身的组织方式如下:搜索查询可以到达八个服务器中的任何一个。 假设他来了服务器1。该服务器处理所有参数并了解查找内容和查找方式。 根据传入的请求,服务器可能会向外部服务提出其他请求以获取必要的信息。 一个请求之后最多可以有十个对外部服务的请求。
收集必要的信息后,便开始搜索商品数据库。 为此,将对集群中的所有八台服务器进行子查询。
收到答案后,将结果合并。 最后,要生成问题,您可能还需要片段服务器的几个子查询。
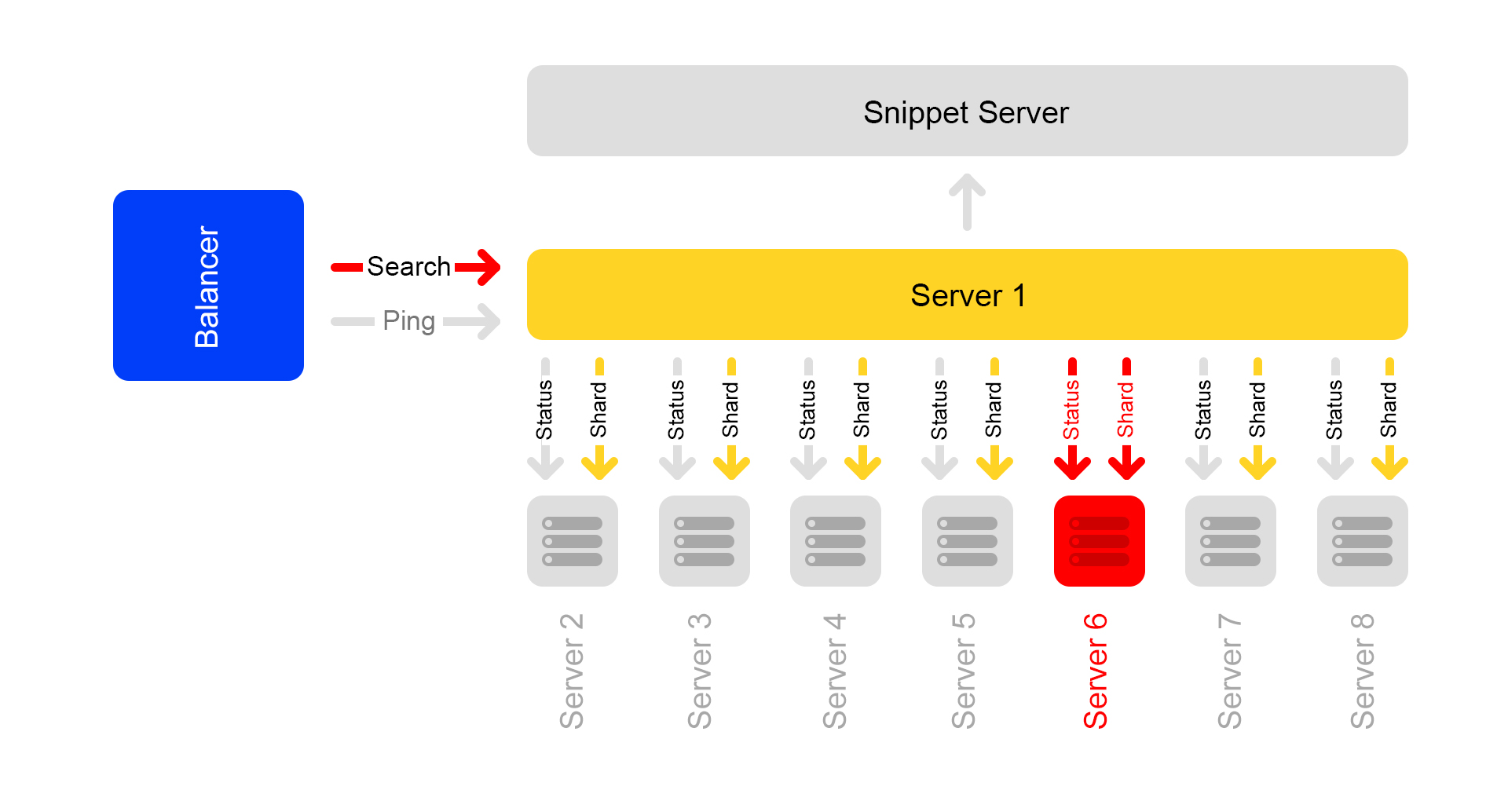
集群中的搜索查询为:
/ shard1?Text = Angry + cat 。 另外,每秒一次在群集内的所有服务器之间不断进行以下形式的子查询:
/ status 。
/状态请求检测服务器不可用时的情况。
它还控制着所有服务器上的搜索引擎版本和索引版本是否相同,否则群集中的数据将不一致。
尽管一个片段服务器处理来自八个搜索引擎的请求,但其处理器的负载非常轻。 因此,现在我们将代码段数据传输到单独的服务。
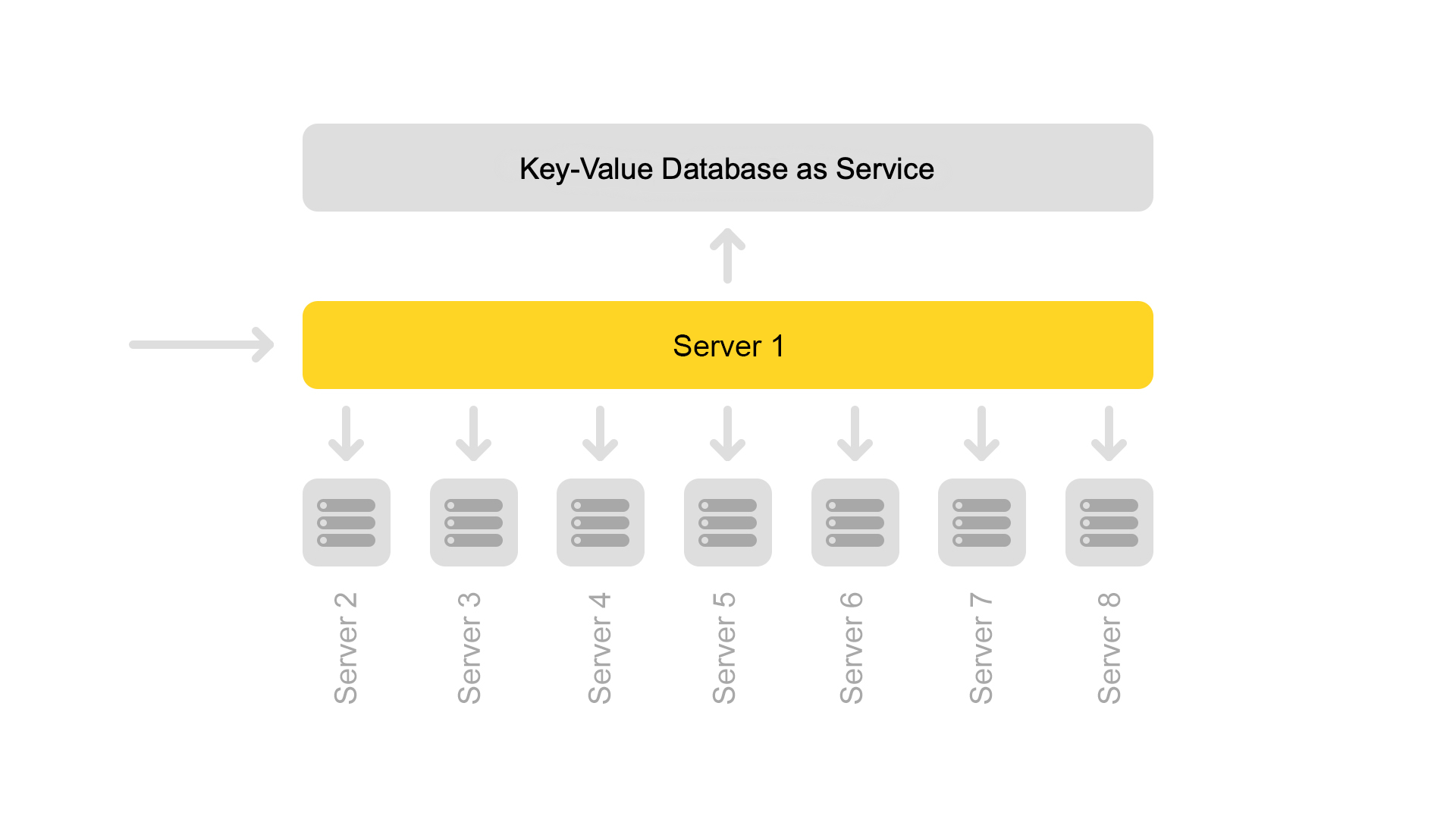
为了传输数据,我们引入了文档通用密钥。 现在,当一个键从另一个文档返回内容时,情况就不可能了。
但是到另一种架构的过渡尚未完成。 现在我们要摆脱专用的代码段服务器。 然后通常会离开集群结构。 这将使我们能够继续轻松扩展。 额外的好处是可以节省大量的铁。
现在到恐怖故事以一个幸福的结局。 考虑服务器不可用的几种情况。
可怕的事情:一台服务器不可用
假设一台服务器不可用。 然后,群集中的其他服务器可能会继续响应,但是搜索结果将不完整。
通过状态检查,相邻服务器知道其中一台不可用。 因此,为了保持完整性,群集中的所有服务器都会对平衡器的
/ ping请求做出响应,因为它们也都不可用。 事实证明,集群中的所有服务器都已消失(事实并非如此)。 这是我们集群方案的主要缺点-因此,我们希望摆脱它。
以错误结尾的请求,平衡器在其他服务器上再次询问。
此外,平衡器停止将用户流量发送到停运的服务器,但继续检查其状态。
服务器可用时,它开始响应
/ ping 。 一旦从死服务器发出的对ping的正常响应开始到达,平衡器便开始向那里发送用户流量。 群集恢复,欢呼。
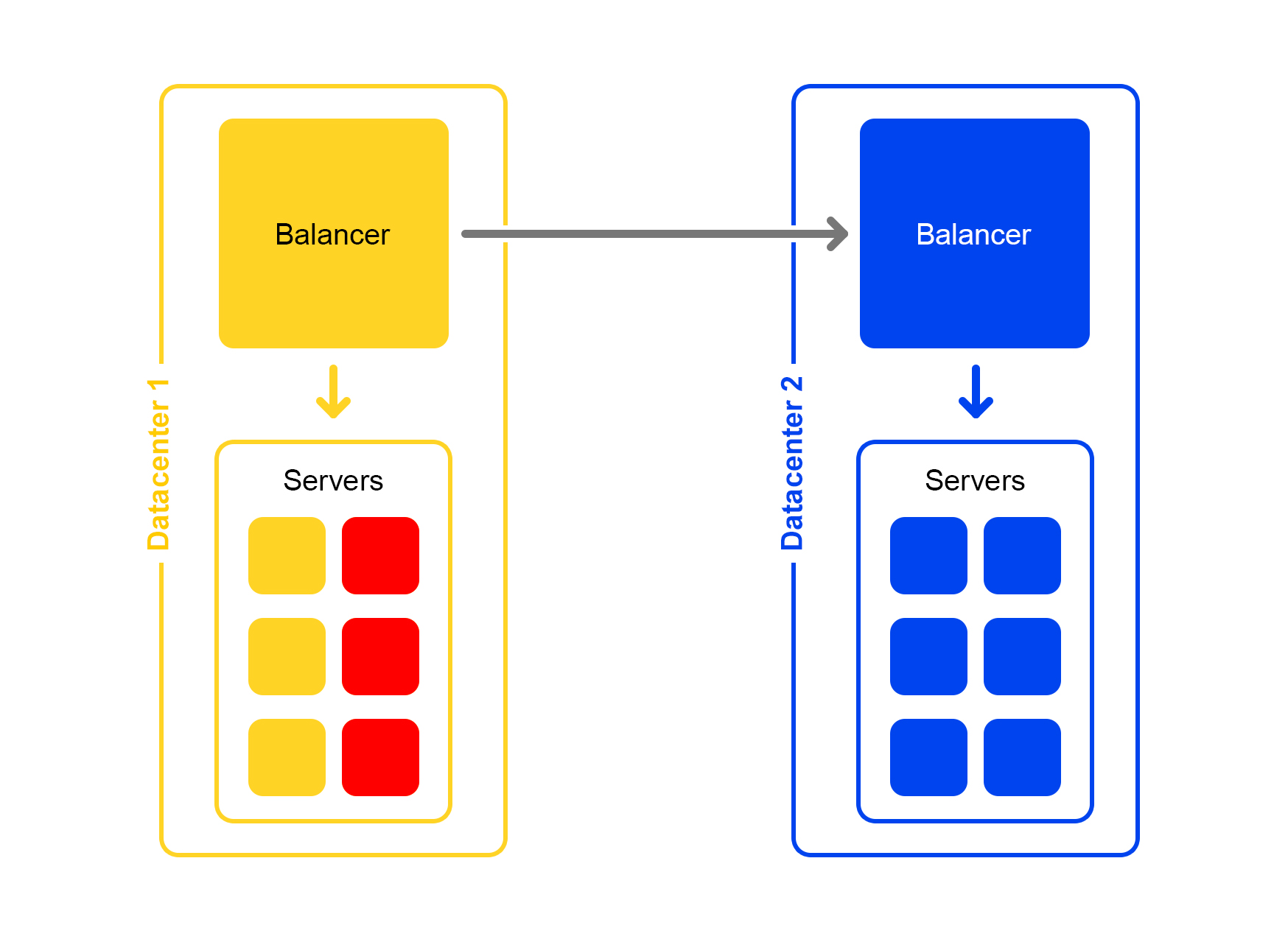
更糟糕的是:许多服务器不可用
数据中心中很大一部分服务器已被削减。 该怎么办,在哪里跑? 平衡器再次救援。 每个平衡器不断将当前活动服务器的数量保留在内存中。 他始终考虑当前数据中心可以处理的最大流量。
当数据中心中的许多服务器掉落时,平衡器就会知道该数据中心无法处理所有流量。
然后,多余的流量开始随机分配到其他数据中心。 一切正常,每个人都很高兴。
我们如何做到:发布发布
现在介绍我们如何发布对服务所做的更改。 在这里,我们采用了简化流程的途径:推出新版本几乎是完全自动化的。
当项目中累积了一定数量的更改时,将自动创建一个新版本并启动其程序集。
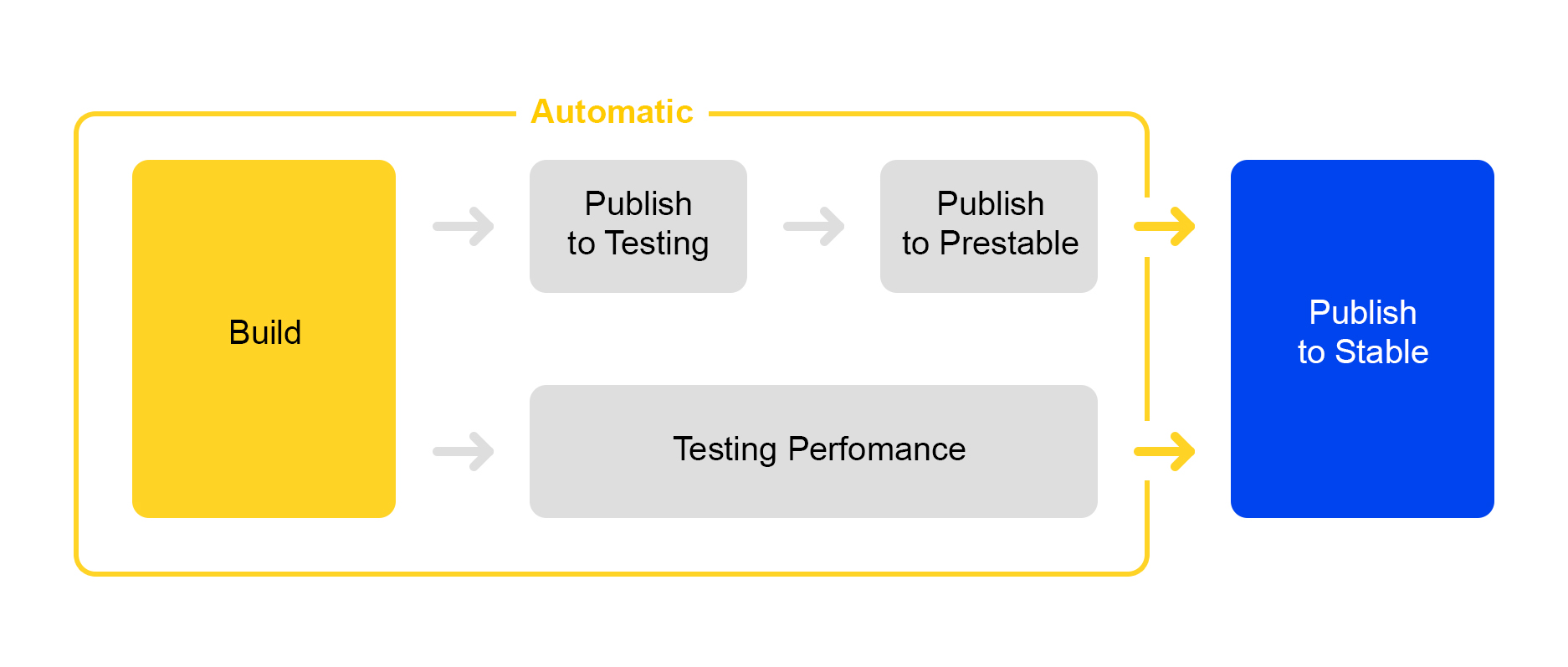
然后将服务推出以进行测试,在此检查稳定性。
同时,将启动自动性能测试。 他从事特殊服务。 我现在不再谈论他-他的描述值得写一篇单独的文章。
如果测试发布成功,则自动开始发布稳定版。 Prestable是一个特殊的群集,用于引导正常的用户流量。 如果返回错误,则平衡器在生产中进行重新请求。
稳定地,测量响应时间并将其与生产中的先前版本进行比较。 如果一切正常,那么该人员将进行连接:检查图表和负载测试结果,然后开始推广到生产中。
最适合用户的:A / B测试
服务的变化是否会带来真正的好处并不总是很明显。 为了衡量变更的有用性,人们提出了A / B测试。 我将简单介绍一下如何在Yandex.Market搜索中发挥作用。
这一切都始于添加一个包含新功能的新CGI参数。 让我们的参数为:
market_new_functionality = 1 。 然后,在代码中,使用标志启用此功能:
If (cgi.experiments.market_new_functionality) {
新功能将在生产中推出。
有专门用于自动进行A / B测试的服务,
此处将对此进行详细说明。 在服务中创建了一个实验。 流量份额设置为例如15%。 兴趣不是针对请求,而是针对用户。 还指出了实验时间,例如一周。
可以同时开始几个实验。 在设置中,您可以指定是否可以与其他实验相交。
结果,该服务会自动将参数
market_new_functionality = 1添加到15%的用户。 他还将自动计算所选指标。 实验后,分析人员查看结果并得出结论。 根据发现的结果,决定要进行生产或精炼。
市场的灵巧之手:生产测试
经常发生的情况是有必要检查生产中新功能的运行情况,但是无法确定在重负荷下“战斗”条件下它将如何运行。
有一个解决方案:CGI参数中的标志不仅可以用于A / B测试,还可以测试新功能。
我们制作了一个工具,使您可以立即在数千台服务器上更改配置,而不会使服务遭受风险。 它被称为“停止起重机”。 最初的想法是无需关闭布局即可快速关闭某些功能的能力。 然后,该工具扩展并变得更加复杂。
服务方案如下:
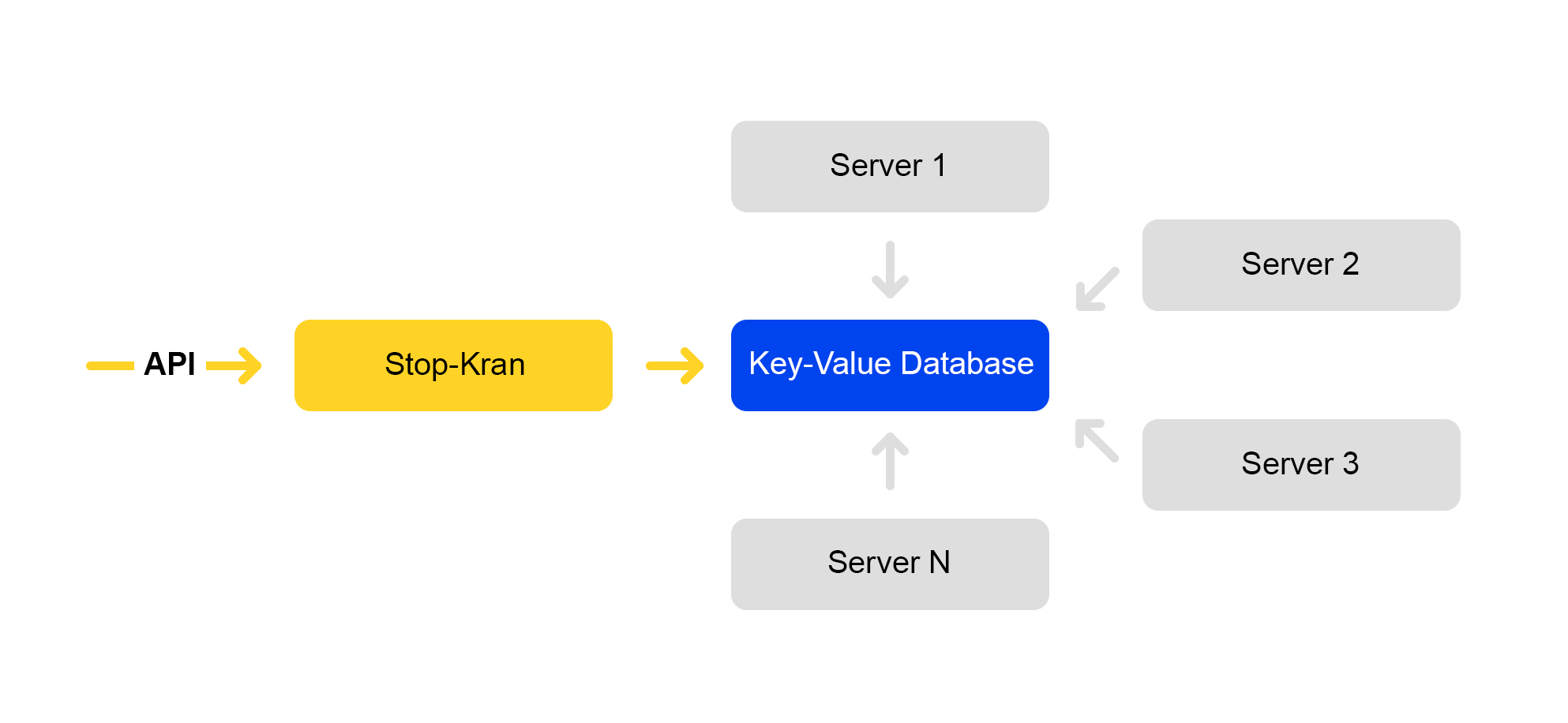
API设置标志值。 管理服务将这些值存储在数据库中。 所有服务器每十秒钟访问一次数据库,抽出标志的值,并将这些值应用于每个请求。
在Stop Crane中,可以设置两种值:
1)条件表达式。 执行其中一个值时应用。 例如:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
在DC1位置处理请求时,将应用值“ 3”。 在站点beru.ru的第二个群集上处理请求时,该值为“ 4”。
2)无条件值。 如果不满足任何条件,则默认使用它们。 例如:
值,值!如果该值以感叹号结尾,则会被赋予更高的优先级。
CGI参数的解析器解析URL。 然后应用停止抽头中的值。
具有以下优先级的值适用:
- 停止抽头(感叹号)的优先级更高。
- 查询中的值。
- 默认值为停止水龙头。
- 代码中的默认值。
条件值中指示了很多标志-对于我们已知的所有场景而言,它们就足够了:
- 数据中心。
- 环境:生产,测试,影子。
- 地点:市场,贝鲁。
- 集群号。
使用此工具,您可以在一组服务器上启用新功能(例如,仅在一个数据中心中),并检查此功能的运行,而不会对整个服务造成太大风险。 即使您在某处严重犯了一个错误,一切都开始崩溃,整个数据中心都崩溃了,平衡器仍会将请求重定向到其他数据中心。 最终用户将不会注意到任何东西。
如果发现问题,则可以立即返回该标志的先前值,并且更改将被回滚。
这项服务有其缺点:开发人员非常喜欢它,并且经常尝试将所有更改推送到Stop Crane中。 我们正在努力防止滥用。
当您已经有了稳定的代码并准备在生产中推出时,停止起重机方法会很好地工作。 同时,您仍然有疑问,并且您想在“战斗”条件下检查代码。
但是,旋塞阀不适用于开发过程中的测试。 对于开发人员,有一个单独的群集,称为“影子群集”。
秘密测试:暗影团
来自群集之一的请求被复制到影子群集。 但是平衡器完全忽略了该群集的响应。 他的工作计划如下。
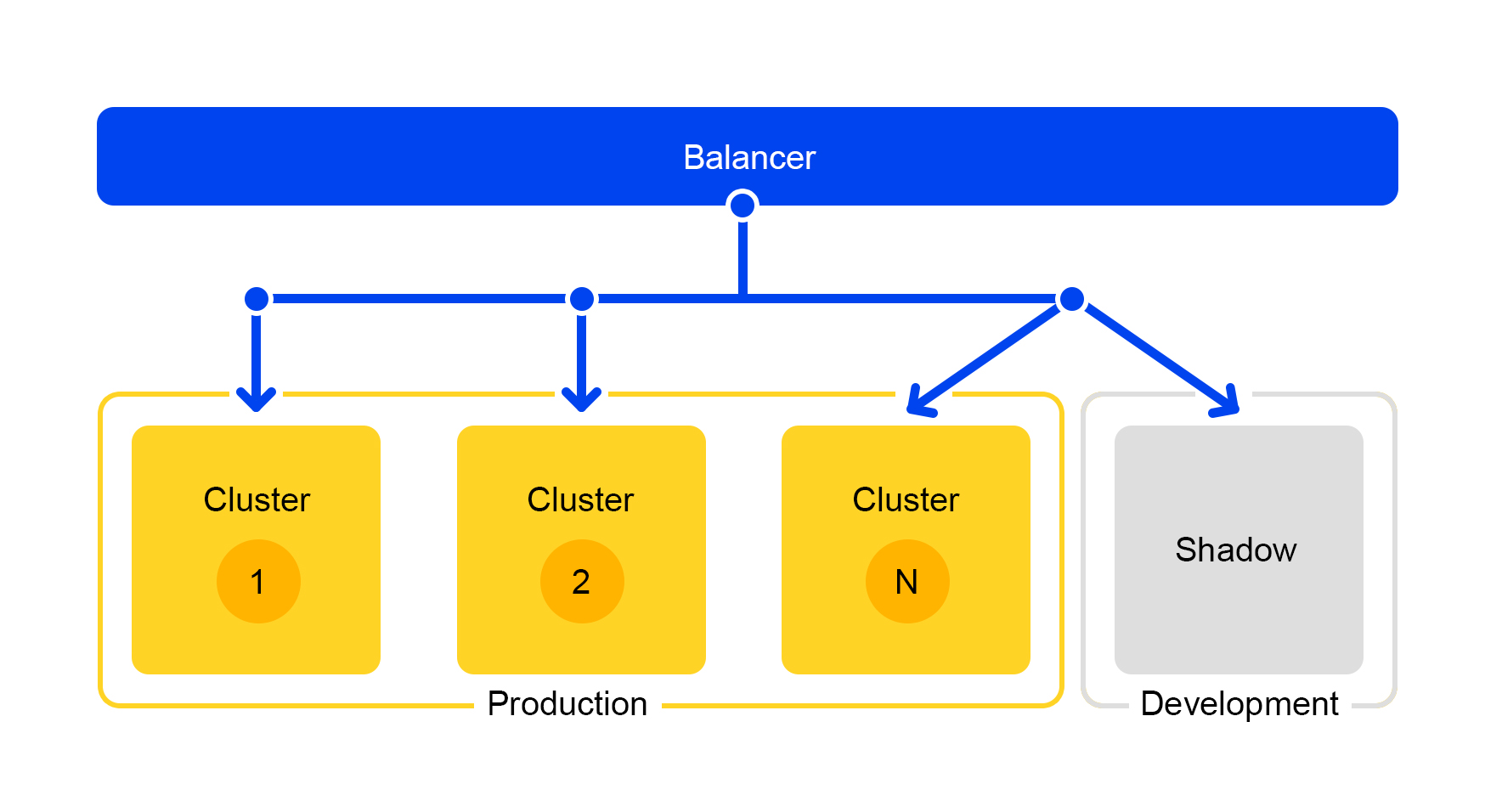
我们得到了处于真正“战斗”状态的测试集群。 正常的用户流量飞到那里。 两个群集中的硬件相同,因此您可以比较性能和错误。
而且由于平衡器完全忽略了答案,因此最终用户将看不到影子群集的响应。 因此,犯错并不可怕。
结论
那么,我们如何建立市场搜索?
为了使一切顺利进行,我们将功能分为单独的服务。 因此,您只能缩放我们需要的那些组件,并使它们更简单。 将一个单独的组件分配给另一个团队并分担工作责任很容易。 用这种方法大量节省铁是显而易见的好处。
影子集群还可以帮助我们:您可以开发服务,在流程中对其进行测试,同时也不会打扰用户。
好吧,当然要检查生产。 是否需要在一千台服务器上更改配置? 容易,使用停止起重机。 因此,您可以立即推出现成的复杂解决方案,并在出现问题时回滚到稳定版本。
我希望我能够通过不断增长的报价基础来展示如何使市场快速稳定。 如何解决服务器问题,处理大量请求,提高服务灵活性,并在不中断工作流程的情况下做到这一点。