你好 今天,我将向Habr的读者介绍我们如何创建支持45种语言并可供Yandex.Cloud用户使用的文本识别技术,我们设置了哪些任务以及如何解决它们。 如果您正在从事类似的项目,或者想了解今天是怎么发生的,那么只需要拍摄土耳其商店的标志,以便爱丽丝将其翻译成俄语,这将非常有用。

光学字符识别(OCR)技术已经在世界范围内发展了数十年。 Yandex的我们开始开发自己的OCR技术,以改善我们的服务并为用户提供更多选择。 图片是Internet的重要组成部分,如果无法理解它们,则在Internet上进行搜索将是不完整的。
图像分析解决方案变得越来越受欢迎。 这是由于人工神经网络和带有高质量传感器的设备的激增。 显然,首先我们谈论的是智能手机,而不仅仅是智能手机。
文本识别领域中任务的复杂性不断增长-一切都始于对扫描文档的识别。 然后添加了来自互联网的带有文字的数字图像的
识别 。 然后,随着移动相机的日益普及,对优质相机镜头的识别(
聚焦场景文本 )。 而且,参数越复杂:文本可以是模糊的(
偶然场景文本 ),可以任意弯曲或螺旋形
书写 ,其类别各不相同-从收据的
照片到
货架和招牌。
我们去了哪条路
文本识别是计算机视觉任务的独立类别。 像许多计算机视觉算法一样,在神经网络流行之前,它很大程度上是基于手动功能和启发式算法。 然而,最近,随着向神经网络方法的过渡,技术的质量已显着提高。 看照片中的例子。 这是怎么发生的,我将进一步讲。
将今天的识别结果与2018年初的结果进行比较:
一开始我们遇到什么困难?
在旅程的开始,我们开发了用于俄语和英语的识别技术,主要用例是从互联网拍摄的文字和图片页面。 但是在工作过程中,我们意识到这还不够:图像上的文字可以用任何语言,在任何表面上找到,有时图片的质量也大不相同。 这意味着识别应该在任何情况下都适用于所有类型的传入数据。
在这里,我们面临许多困难。 这里只是一些:
- 详细资料 对于习惯于从文本中获取信息的人,图像中的文本是段落,线条,单词和字母,但是对于神经网络,一切看起来都不同。 由于文本的复杂性,网络被迫同时查看整个图片(例如,如果人们手拉手并刻了题词)和最小的细节(在越南语中,相似的符号ử和ừ改变了单词的含义)。 单独的挑战包括识别任意文本和非标准字体。
- 多种语言 。 添加的语言越多,我们面对的细节也就越多:西里尔字母和拉丁词由单独的字母组成,阿拉伯语由共同字母组成,日语没有区别。 有些语言从左到右使用拼写,有些从右到左使用拼写。 有些单词是水平书写的,有些是垂直书写的。 通用工具应考虑所有这些功能。
- 文本的结构 。 为了识别特定的图像(例如支票或复杂的文档),考虑到段落,表格和其他元素的布局的结构至关重要。
- 表现 。 该技术已在包括脱机在内的各种设备上使用,因此我们必须考虑严格的性能要求。
检测模型选择
识别文本的第一步是确定其位置(检测)。
文本检测可以看作是对象识别任务,其中各个
字符 ,
单词或
行都可以充当对象。
对于我们而言,重要的是该模型随后可以扩展到其他语言(现在我们支持45种语言)。
关于文本检测的许多研究文章都使用预测单个
单词位置的模型。 但是在
通用模型的情况下
,这种方法有几个局限性-例如,中文单词的概念与英文单词的概念根本不同。 中文中的单个单词之间没有空格。 在泰语中,仅将单个句子与空格一起丢弃。
以下是俄语,中文和泰语中相同文本的示例:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้ว线条反过来在宽高比方面变化很大。 因此,此类通用检测模型(例如,基于SSD或RCNN的模型)用于行预测的可能性受到限制,因为这些模型基于具有许多预定义长宽比的候选区域/锚点框。 此外,这些线可以具有任意形状,例如弯曲的形状,因此,对于这些线的定性描述,即使具有旋转角度,仅仅描述四边形也是不够的。
尽管每个
字符的位置
都是局部的和已描述的,但它们的缺点是需要单独的后处理步骤-您需要选择启发式方法将字符粘贴到单词和行中。
因此,我们以
SegLink模型为基础进行检测,其主要思想是将行/单词分解为另外两个本地实体:段和它们之间的关系。
检测器架构
该模型的体系结构基于SSD,它可以在多个尺度的特征上预测对象的位置。 除了预测单个“段”的坐标外,还预测相邻段之间的“连接”,即两个段是否属于同一条线。 预测“连接”是针对具有相同符号比例的相邻段,还是针对位于邻近比例上的相邻区域的段(来自不同比例符号的段的大小可能略有不同,并且属于同一行)。
对于每个比例,每个特征单元都与一个对应的“段”相关联。 对于刻度l上的点(x,y)上的每个段s
(x,y,l) ,训练以下内容:
-p
s给定的段是否为文本;
-x
s ,y
s ,w
s ,h
s ,θs-基本坐标的偏移量和线段的倾斜角度;
-从{s
(x',y',l) } / s
(x,y,l)中与第l个标度相邻的线段(L
w s,s' ,s'
)的 s /
x(x,y,l)得分为8。 –1≤x'≤x + 1,y – 1≤y'≤y + 1);
-从{s
(x',y',l-1) }到与l-1标度(L
c s,s' ,s')相邻的线段存在“连接”的得分为4,其中2x≤x'≤2x + 1 ,2y≤y'≤2y +1)(这是正确的,原因是相邻尺度上的要素尺寸恰好相差2倍)。
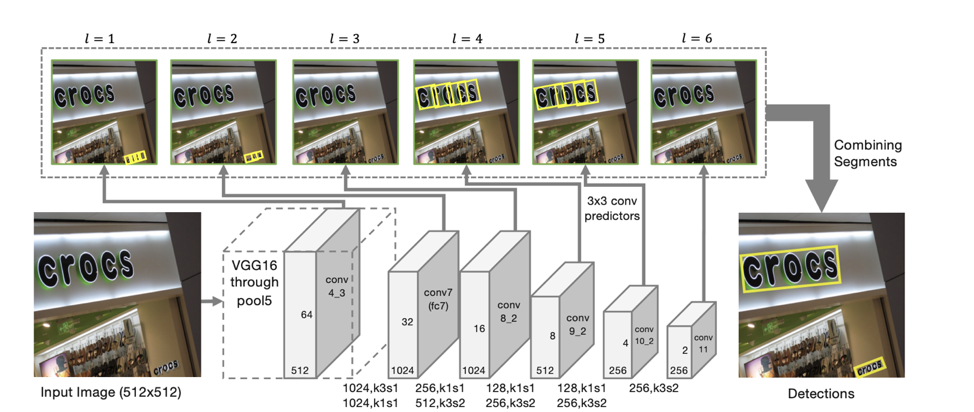
根据这样的预测,如果我们将其概率大于阈值α的所有线段作为顶点,并将概率大于阈值β的所有键作为边缘,则这些线段形成连接的成分,每个成分描述一行文本。
生成的模型具有
很高的泛化能力 :即使是在俄语和英语数据的第一种方法上进行训练的情况下,它也定性地找到了中文和阿拉伯文本。
十个脚本
如果要进行检测,我们能够创建一个对所有语言都可以立即使用的模型,那么对于发现的行,则很难获得这种模型。 因此,我们决定
为每个脚本 (西里尔文,拉丁文,阿拉伯文,希伯来文,希腊文,亚美尼亚文,格鲁吉亚文,韩文,泰文)使用
单独的模型 。 由于象形文字的交集较大,因此中文和日语使用单独的通用模型。
整个脚本的通用模型与每种语言的单独模型的差异小于1p.p。 质量。 同时,一个模型的创建和实现比25种模型(我们的模型支持的拉丁语言的数量)更简单。 但是由于英语在所有语言中的频繁出现,因此除主要脚本外,我们所有的模型都能够预测拉丁字符。
为了了解应该使用哪种模型进行识别,我们首先确定接收到的行是否属于可用于识别的10个脚本之一。
应当单独注意的是,并非总是可以唯一地确定其脚本。 例如,许多脚本中包含数字或单个拉丁字符,因此模型的输出类之一是“未定义”脚本。
脚本定义
为了定义脚本,我们做了一个单独的分类器。 定义脚本的任务比识别任务简单得多,并且神经网络很容易在合成数据上进行训练。 因此,在我们的实验中,通过
对字符串识别问题进行
预训练 ,极大地提高了模型的质量。 为此,我们首先对网络进行了训练,以解决所有可用语言的识别问题。 之后,使用生成的主干将模型初始化为脚本分类任务。
尽管单行上的脚本通常很嘈杂,但整个画面通常包含一种语言的文本,此外还散布着主要的英语(或者对于俄罗斯用户而言)。 因此,为了
增加稳定性,我们汇总了来自图像的线的预测,以获得图像脚本的更稳定的预测。 聚合中不考虑预测类别为“不确定”的行。
线识别
下一步,当我们已经确定了每一行的位置及其脚本时,我们需要
从显示在给定脚本上
的字符序列中识别出字符序列 ,即从像素
序列中识别出字符序列以预测字符序列。 经过多次实验,我们得出了以下基于序列2序列注意的模型:

在编码器中使用CNN + BiLSTM可使您获得捕获本地和全局上下文的信号。 对于文本而言,这很重要-通常以一种字体书写(用字体信息来区分相似的字母要容易得多)。 为了将两个用空格写的字母与连续的字母区分开,该行还需要全局统计信息。
一个有趣的发现 :在生成的模型中,特定符号的注意遮罩的输出可用于预测其在图像中的位置。
这激发了我们尝试
清楚地“集中”模型的注意力 。 在文章中也发现了这样的想法,例如,在文章《
集中注意力:走向自然图像中的准确文本识别》中 。
由于注意力机制给出了特征空间上的概率分布,因此,如果将掩码内与该步骤中预测的字母相对应的注意力输出总和作为额外损失,我们将得到“注意力”直接关注的部分。
通过引入损失-log(∑
i,j∈Mtαi ,j ),其中M
t是第t个字母的掩码,α是注意的输出,我们将鼓励“注意”专注于给定的字符,从而有助于神经网络学得更好。
对于那些个别字符的位置未知或不正确的训练示例(并非所有训练数据的标记都在单个字符而非单词的级别),最终损失中未考虑该术语。
另一个不错的功能:此体系结构使您无需进行其他更改即可预测
从右到左的行的
识别 (这对于例如阿拉伯语,希伯来语之类的语言很重要)。 模型本身开始从右向左发出识别。
快慢模型
在此过程中,我们遇到了一个问题:
对于“高”字体 ,即垂直拉长的字体,该模型无法正常工作。 这是由于以下事实引起的:由于网络卷积部分的体系结构中的跨步和拉动,因此注意级别的符号尺寸比原始图像的尺寸小8倍。 并且源图像中几个相邻字符的位置可能与同一特征向量的位置相对应,这可能会导致此类示例中的错误。 使用具有较小特征尺寸范围的缩小的体系结构导致质量的增加,但也导致处理时间的增加。
为了解决此问题并
避免增加处理时间 ,我们对模型进行了以下改进:
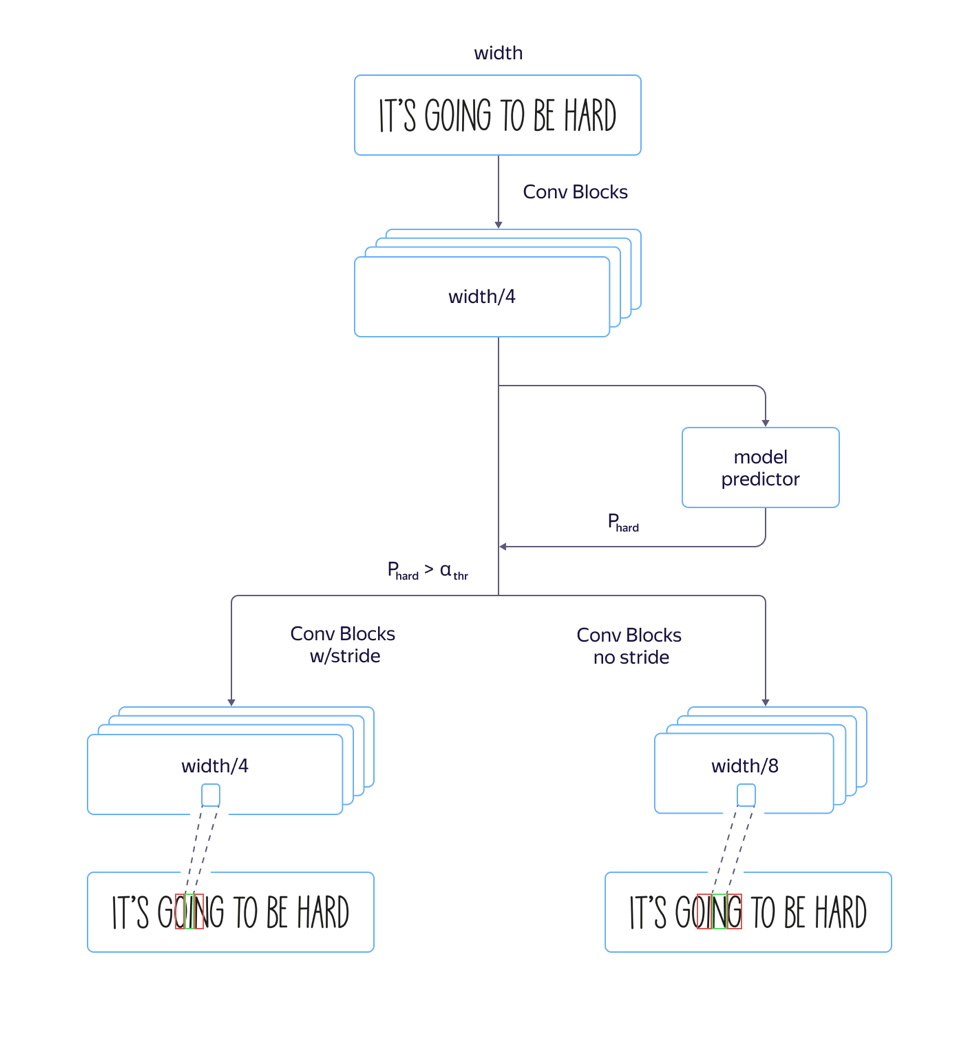
我们既训练了速度快,步伐大的模型,又训练了速度慢而步幅小的模型。 在模型参数开始有所不同的层上,我们添加了一个单独的网络输出,该输出可预测哪个模型的识别误差较小。 模型的总损失由L
小 + L
大 + L
质量组成 。 因此,在中间层,模型学会了确定此示例的“复杂性”。 此外,在应用阶段,对所有线路都考虑了示例的一般部分和“复杂性”的预测,并且根据其输出,将来会使用阈值使用快速模型或慢速模型。 这使我们获得的质量与长模型的质量几乎没有什么不同,而速度仅提高了5%,而不是估计的30%。
训练数据
创建高质量模型的重要阶段是准备大量多样的训练样本。 文本的“合成”性质使得可以生成大量示例并在真实数据上获得不错的结果。
在第一种生成合成数据的方法之后,我们仔细查看了所获得模型的结果,发现该模型不能很好地识别单个字母“ I”,这是因为用于创建训练集的文本存在偏差。 因此,我们清楚地生成了一
组“问题”示例 ,并将其添加到模型的初始数据中后,质量显着提高。 我们重复了此过程多次,添加了越来越多的复杂切片,我们希望在这些切片上提高识别质量。
重要的一点是,生成的
数据应该是多样的并且与真实数据相似 。 而且,如果您希望模型在纸上的文字照片上工作,并且整个合成数据集都包含写在风景之上的文字,那么这可能不起作用。
另一个重要步骤是用于训练那些当前识别错误的示例。 如果存在大量没有标记的图片,则可以获取她不确定的当前识别系统的输出,并仅标记它们,从而降低标记成本。
对于复杂的示例,我们要求Yandex.Tolok服务的用户收取一定费用,以拍摄并向我们发送
某个“复杂”组的图像,例如,货物包装的照片:


“复杂”数据的工作质量
我们希望为用户提供处理任何复杂照片的机会,因为可能不仅需要识别或翻译书本页面或扫描的文档上的文字,而且还必须识别或翻译路牌,公告或产品包装上的文字。 因此,在保持书籍和文档流的高质量工作的同时(我们将在这个主题上专门讲一个故事),我们要特别注意“复杂的图像集”。
通过上述方式,我们整理了一组包含野外文字的图像,这对我们的用户可能有用:招牌照片,告示牌,盘子,书套,家用电器,衣服和物体上的文字。 在此数据集(下面的链接)上,我们评估了算法的质量。
作为比较的指标,我们使用数据集中单词识别的准确性和完整性的标准指标以及F量度。 如果识别出的单词的坐标与标记单词的坐标相对应(IoU> 0.3),并且该识别与所标记的单词完全符合情况,则认为该单词已正确找到。 结果数据集上的数字:
此处提供
了用于重现结果的数据集,指标和脚本。
更新。 朋友们,将我们的技术与Abbyy的类似解决方案进行了比较,引起了很多争议。 我们尊重社区和业界同行的意见。 但是与此同时,我们对结果充满信心,因此我们决定采用这种方式:我们将从比较中删除其他产品的结果,再次与他们讨论测试方法,然后返回我们达成普遍协议的结果。
后续步骤
在诸如检测和识别之类的各个步骤的交界处,总是会出现问题:检测模型的最细微变化都需要更改识别模型,因此我们正在积极尝试创建端到端解决方案。
除了已经描述的改进技术的方法之外,我们还将开发一个分析文档结构的方向,这在提取信息时至关重要,并且用户之间也很需要。
结论
用户已经习惯了便捷的技术,毫不犹豫地打开相机,指向商店的招牌,餐厅的菜单或外文书籍中的页面,并迅速获得翻译。 我们以公认的准确性识别45种语言的文字,并且机会只会不断扩大。 Yandex.Cloud中的一组工具使任何想要使用Yandex长期以来为自己做的最佳实践的人都能使用。
今天,您只需采用完成的技术,将其集成到您自己的应用程序中,然后使用它来创建新产品并自动化您自己的流程。 我们的OCR文档可
在此处获得 。
阅读内容:
- D. Karatzas,SR Mestre,J。Mas,F。Nourbakhsh和PP Roy,“文档分析和识别”(ICDAR)中的“ ICDAR 2011健壮的阅读比赛挑战1:阅读原始数字图像(网络和电子邮件)中的文本” ),2011年国际会议上。 IEEE,2011年,第pp。 1485-1490。
- Karatzas D.等。 ICDAR 2015健壮阅读竞赛// 2015年第13届国际文档分析与识别会议(ICDAR)。 -IEEE,2015年。-S. 1156-1160。
- e志谦等 等 ICDAR2019任意形状文本(RRC-ArT)的稳健阅读挑战[ arxiv:1909.07145v1 ]
- ICDAR 2019扫描收据OCR和信息提取上的强大阅读挑战rrc.cvc.uab.es/?ch=13
- ShopSign:街景中的中国商店标志的多种场景文本数据集[ arxiv:1903.10412 ]
- 石宝光,白香,Serge Belongie通过链接段检测自然图像中的定向文本[ arxiv:1703.06520 ]。
- 程占战,范凡,徐云璐,郑刚,蒲世良,周水庚着重注意:努力实现自然图像中的准确文本识别[ arxiv:1709.02054 ]。