祝大家有美好的一天,哈勃(Habr)的读者们!
背景知识
在我们这里,习惯上在开发团队中交流有趣的发现。 在下一次会议上,尤其是讨论.NET和.NET 5的未来时,我和我的同事们着重于从这张图片看到一个统一的平台:
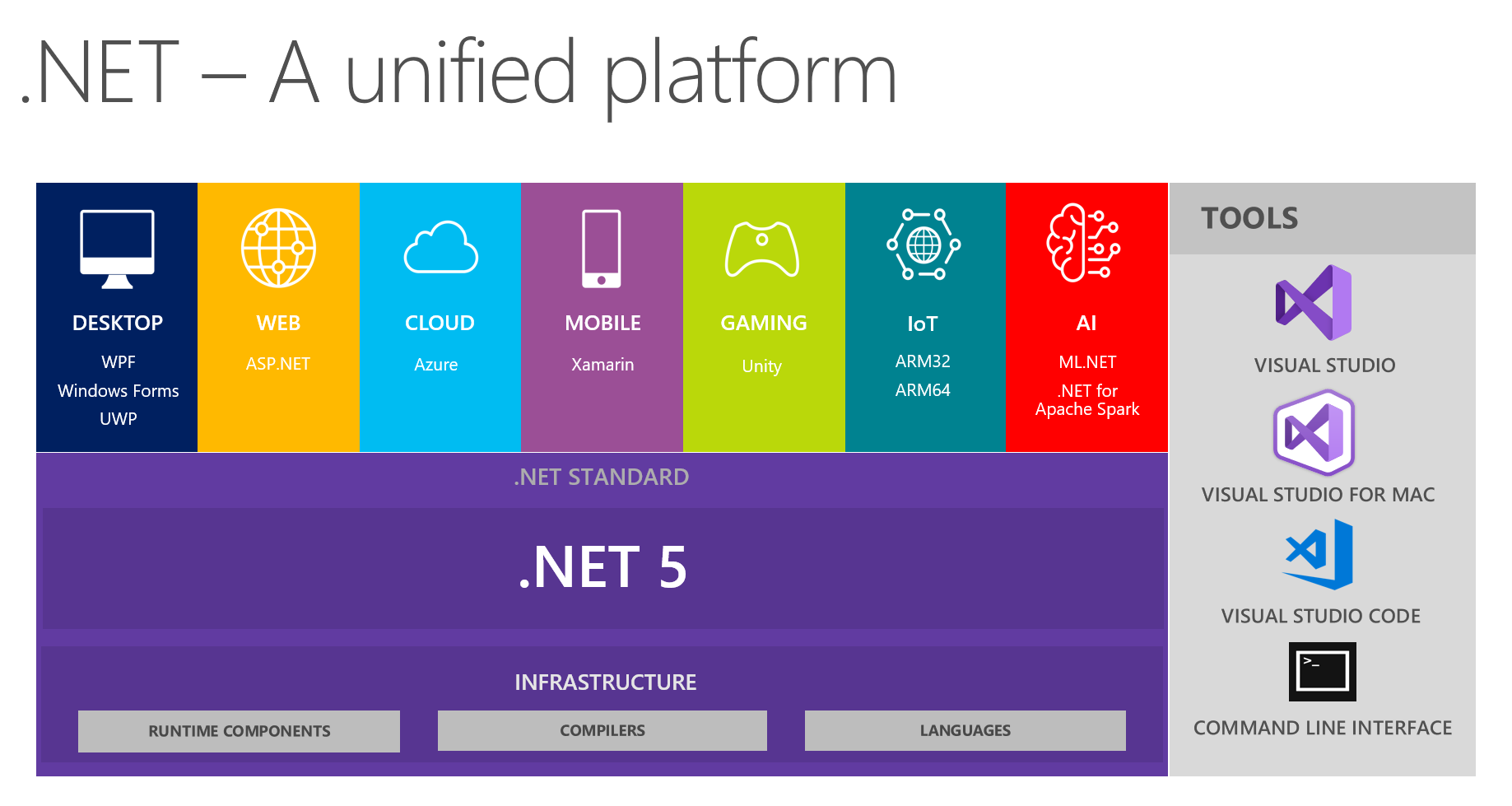
它表明该平台结合了桌面,Web,云,移动,游戏,物联网和人工智能。 我想到了在下次会议上以小报告+关于每个主题的问题/答案的形式进行对话的想法。 负责特定主题的人员正在进行初步准备,读取有关主要创新的信息,尝试使用所选的技术来实施某些事物,然后与我们分享他的想法和印象。 这样一来,每个人都会从可信赖的来源直接获得有关工具的真实反馈-这非常方便,因为尝试并闯入所有主题可能并不方便,因此您将无法动手。
由于一段时间以来我一直对机器学习兴趣浓厚(有时将它用于工作中的非业务任务),因此有了AI&ML.NET的话题。 在准备过程中,我遇到了许多奇妙的工具和材料,令我惊讶的是,我发现哈布雷(Habré)上关于它们的信息很少。 微软早些时候在官方博客中写过关于ML.Net的发布,尤其是关于Model Builder的发布 。 我想分享我对他的了解以及与他一起工作给我的印象。 这篇文章更多地是关于.NET中的ML而不是Model Builder。 我们将尝试看看MS为普通的.NET开发人员所提供的功能,但是精通ML。 同时,我将尝试在重提本教程,完全为初学者咀嚼和为ML专家(由于某种原因而需要进入.NET)的详细说明之间保持平衡。
主体
因此,快速浏览.NET中的ML将我带到了教程页面 :
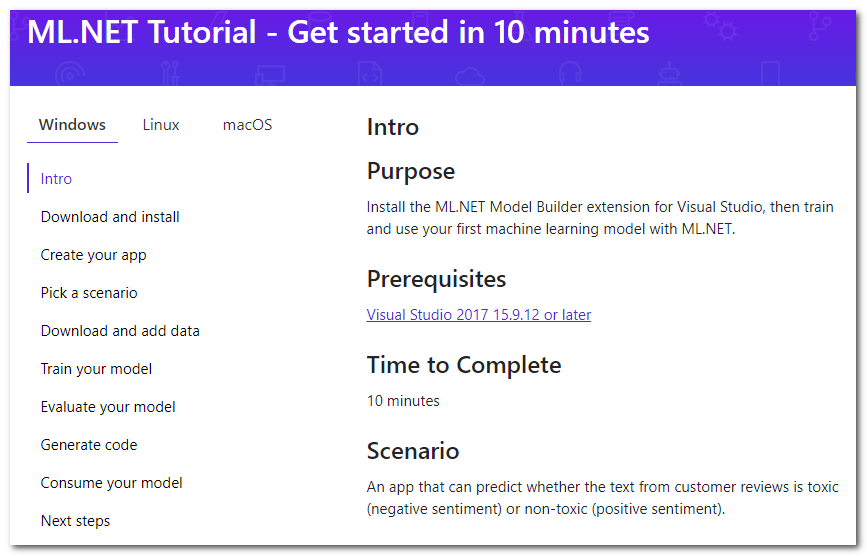
事实证明,Visual Studio有一个特殊的扩展名为Model Builder,它“允许您使用鼠标右键将机器学习添加到项目中”(免费翻译)。 我将简要介绍本教程要完成的主要步骤,并添加细节和想法。
下载并安装
按下按钮,下载并安装。 工作室必须重新启动。
建立您的应用程式
首先,创建一个常规的C#应用程序。 在本教程中,建议创建Core,但也适合Framework。 然后,实际上,ML开始-右键单击项目,然后单击添加->机器学习。 将分析将出现的用于创建模型的窗口,因为发生了所有魔术。
选择一个方案
选择您的应用程序的“脚本”。 目前有5个可用(本教程有些过时,到目前为止有4个):
- 情感分析-语调分析,二元分类(binary class),文字确定其情绪色彩,正面还是负面。
- 问题分类-多类分类,问题的目标标签(票证,错误,支持电话等)可以选择为三个互斥选项之一
- 价格预测-回归,当输出为连续数时的经典回归问题; 在此示例中,这是公寓估算
- 图像分类-多类分类,但已经用于图像
- 自定义方案-您的方案; 我不得不为这个选项没有新内容而感到悲伤,只是在稍后的阶段,他们会让我选择上述四个选项之一。
请注意,如果目标方法可以同时很多,则没有多标签分类(例如,一条语句可以同时是冒犯性,种族主义和淫秽的,可能不是任何一种)。 对于图像,没有选择分割任务的选项。 我猜想在框架的帮助下它们通常可以解决,但是今天我们将重点放在构建器上。 看来,扩展向导以扩展任务数量并不是一件困难的事情,因此您应该在将来看到它们。
下载并添加数据
建议下载数据集。 从需要下载到您的计算机上,我们自动得出结论,培训将在我们的本地计算机上进行。 这有两个优点:
- 您控制所有数据,可以更正,本地更改并重复实验。
- 您无需将数据上传到云,因此可以保护隐私。 毕竟,不上传,是微软吗? :)
利弊:
进一步建议选择下载的数据集作为“文件”类型的输入。 还有一个使用“ SQL Server”的选项-您将需要指定必要的服务器详细信息,然后选择表。 如果我理解正确,那么尚无法指定特定的脚本。 在下面,我写了关于此选项的问题。
训练模型
在此步骤中,依次训练各种模型,为每个模型显示速度,最后选择最佳模型。 哦,是的,我忘了提到这是AutoML-即 最佳算法和参数(不确定,请参阅下文)将自动选择,因此您无需执行任何操作! 建议将最大训练时间限制为秒数。 这次定义的启发式方法: https : //github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train 。 在我的机器上,默认情况下10秒内,只有一种模型可以学习,因此我必须下更多的赌注。 我们开始,我们等待。
在这里,我真的要补充一点,对于我个人而言,模型的名称似乎有点不寻常,例如:AveragedPerceptronBinary,FastTreeOva,SdcaMaximumEntropyMulti。 如今,“ Perceptron”这个词并不经常使用,“ Ova”可能是“一对多”,而“ FastTree”我很难说什么。
另一个有趣的事实是LightGbmMulti是候选算法之一。 如果我正确理解的话,那就是相同的LightGBM,它是渐变增强引擎,与CatBoost一起,现在正在与曾经的XGBoost规则竞争。 他对目前的表现速度有些沮丧-根据我的数据,他的训练花费了最多的时间(约180秒)。 尽管输入是文本,但是在比输入示例多了数千列的矢量化之后,一般而言,这不是增强树的最佳情况。
评估模型
实际上是对模型结果的评估。 在此步骤中,您可以查看已实现了哪些目标指标以及如何运行模型。 关于指标本身,可以在此处阅读: MS和sklearn 。
我主要对这个问题感兴趣-测试了什么? 在同一帮助页面上进行搜索会给出答案-分区非常保守,占80%到20%。 我没有在UI中配置此功能。 实际上,我想对此进行控制,因为当确实有大量数据时,分区甚至可以达到99%和1%(根据Andrew Ng的说法,我本人并未使用此类数据)。 能够设置随机种子数据采样也将很有用,因为在构建和选择最佳模型期间的可重复性很难高估。 似乎添加这些选项并不难,为了保持透明度和简单性,您可以将它们隐藏在一些其他选项复选框后面。
在构建模型的过程中,带有速度指示器的平板电脑会显示在控制台上,其生成代码可以在下一步的项目中找到。 我们可以得出结论,生成的代码确实有效,并且其诚实的输出就是输出,没有伪造。
一个有趣的观察-在撰写本文时,我再次走过了构建者的步骤,使用了来自Wikipedia的建议评论数据集。 但是作为一项任务,我选择了“自定义”,然后将一个多类分类作为目标(尽管只有两个类)。 结果,该速度比带有二进制分类的屏幕快照的速度差了约10%(约73%比83%)。 对我来说,这有点奇怪,因为系统可能已经猜到只有两个类。 原则上,一对多类型的分类器(当将多类分类问题简化为针对N个类中的每一个的N个二元问题的顺序解决方案时,一个对所有类型的分类器)在这种情况下也应显示相似的二进制速度。
产生程式码
在这一步,将生成两个项目并将其添加到解决方案中。 其中一个提供了使用模型的完整示例,而另一个仅在实现细节令人感兴趣时才应查看。
对我自己来说,我发现整个学习过程简明扼要地形成了一条管道(您好,从sk-learn获得的指导):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(稍微触摸一下代码的格式就可以了)
还记得我在说参数吗? 我没有看到任何自定义参数,所有默认值。 顺便说一下,使用FeaturizeText输出上的SentimentText_tf标签FeaturizeText我们可以得出结论,这是一个术语频率(文档说这些是文本的n-gram和char-gram;我想知道是否存在IDF,即文档频率的倒数)。
消耗模型
实际上是一个使用示例。 我只能注意到Predict是基本完成的。
好的,仅此而已-我们检查了构建器的所有步骤,并指出了关键点。 但是,如果不对自己的数据进行测试,那么本文将是不完整的,因为曾经遇到过ML和AutoML的任何人都非常清楚,任何机器都擅长于标准任务,综合测试和Internet数据集。 因此,决定检查建造者的任务。 在下文中,它始终适用于文本或文本+分类特征。
我手头有一个在一个项目上注册有一些错误/问题/缺陷的数据集,这并不是巧合。 它有2949行,8个不平衡的目标类别,4mb。
ML.NET(以下列表中的加载,转换,算法;耗时219秒)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(板上的空隙可放入Markdown中)
我的Python版本(加载, 清理 ,转换,然后是LinearSVC;花了41秒):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0.80 vs. 0.747 Micro和0.73 vs 0.542 Macro(宏的定义可能有些不准确,如果有趣的话,我会在评论中告诉您)。
我很惊讶,只有5%的差异。 在其他一些数据集上,差异甚至更小,有时甚至根本没有。 在分析差异的大小时,值得考虑的事实是数据集中的样本数量很少,有时在下一次上传(删除某些内容后添加一些内容)之后,我观察到速度变化为2%至5%。
当我自己进行实验时,使用构建器没有任何问题。 但是,在演示过程中,同事仍然遇到了一些障碍:
- 我们试图从表中诚实地将一个数据集加载到数据库中,但是偶然发现了一个无用的错误消息。 我对文本数据有什么样的计划有一个大概的了解,然后立即发现问题可能出在换行中。 好吧,我使用pandas.read_csv下载了数据集,从\ n \ r \ t中清除了数据集,将其保存在tsv中,然后继续。
- 在训练下一个模型时,他们收到了一个异常报告,报告说每1000个〜220,000大小的矩阵无法舒适地容纳在内存中,因此停止了训练。 同时,也没有生成模型。 下一步该怎么做还不清楚;我们通过“目视”替换学习时间限制来摆脱局面,从而使下降算法没有时间开始工作。
顺便说一下,从第二段我们可以得出结论,向量化过程中单词和n-gram的数量实际上不受上限的限制,“ n”可能等于2。 我可以根据自己的经验说200k显然太多了。 通常,它要么仅限于最频繁出现,要么应用于各种降维算法,例如SVD或PCA。
结论
构建器提供了几种方案的选择,在这些方案中,我没有找到需要沉浸在ML中的关键位置。 从这个角度来看,它非常适合作为“入门”工具或解决当前和现在的典型简单问题的工具。 实际用例完全取决于您的想象。 您可以使用MS提供的选项:
- 解决情感评估(情感分析)的问题,例如,在网站上对产品的评论中
- 按类别或团队对票进行分类(问题分类)
- 继续模拟门票,但借助价格预测-估计时间成本
并且,您可以添加自己的内容,例如,自动化在开发人员之间分配传入错误/事件的任务,将其简化为按文本分类的任务(目标标签是开发人员的ID /姓氏)。 或者,也可以请内部工作站的操作员在卡中的字段中填充其他字段或文本描述的固定值集(下拉列表)。 为此,您只需要在csv中准备一个选择(即使数百行就足以进行实验),直接从UI Visual Studio讲授模型,并通过复制生成的示例中的代码将其应用到您的项目中。 我得出这样一个事实,我认为ML.NET非常适合解决不需要特殊资格且浪费时间的实用,务实,平凡的任务。 而且,它可以应用在最普通的项目中,而这并不是声称具有创新性。 任何准备掌握新库的.NET开发人员都可以成为这种模型的作者。
我比一般的.NET开发人员拥有更多的ML背景,所以我自己决定:对于图片,对于复杂的情况,可能没有,但是对于简单的表格任务,肯定是的。 目前,对我来说,在更熟悉的Python / numpy / pandas / sk-learn / keras / pytorch技术堆栈上执行任何ML任务更为方便,但是,我会做一个典型的案例,以后再使用ML.NET嵌入.NET应用程序中。
顺便说一句,很好的是,文本框架可以完美运行,而无需任何不必要的手势,也不需要用户进行调整。 通常,这并不奇怪,因为在实践中,在少量数据上,具有分类器(如SVC / NaiveBayes / LR)的老式TfIDF效果很好。 iPavlov在夏季DataFest的一份报告中对此进行了讨论-在一些测试套件中,将word2vec,GloVe,ELMo(某种)和BERT与TfIdf进行了比较。 在测试中,尽管花在培训上的资源根本无法比拟,但在7-10个案例中,只有一个案例可以实现百分之几的优势。
PS现在,即使使用 “ 即使是小学生也可以使用的Google创建AI工具 ”,在ML中,大众化的趋势正在发展。 对于用户而言,这都是有趣且直观的,但是尚不清楚云中幕后的真实情况。 在这种情况下,对于.NET开发人员而言,带有模型构建器的ML.NET似乎是一个更具吸引力的选择。
PSS Presentation轰轰烈烈,同事们都积极尝试:)
意见反馈
顺便说一句,标题为“ ML.NET Model Builder”的新闻通讯之一说:
给我们您的反馈
如果遇到任何问题,觉得缺少某些东西,或者真的很喜欢ML.NET Model Builder,请在GitHub存储库中创建一个问题,让我们知道。
模型构建器仍处于预览状态,您的反馈对于推动我们使用该工具的发展方向至关重要!
本文可视为反馈!
参考文献
在ML.NET上
到指导下的较旧文章