我们一直想快速编写代码,但是您必须为此付费。 使用普通的高级灵活语言,程序可以快速开发,但是在启动后运行缓慢。 例如,在纯Python中读取沉重的内容太慢了。 类似于C的语言可以更快地工作,但是更容易出错,对其进行搜索将使所有的速度提高变为零。
通常,这种困境可以通过以下方式解决:首先,他们使用诸如Python或R之类的灵活代码编写原型,然后再使用C / C ++或Fortran重写原型。 但是这个周期太长了,您可以不用它吗?

也许有解决方案。 Julia是一种高级,灵活但快速的编程语言。 Julia具有多个调度程序,集成的智能编译器和元编程工具。
Datarythmics的创始人
Gleb Ivashkevich (
phtRaveller )曾为物理学家开发过用于行业和其他行业的机器学习系统的软件,他将为您提供有关Julia的更多信息。
Gleb将解释为什么需要新语言以及为什么有时缺少Python。 他将告诉您Julia有趣的地方,它的优缺点,将其与其他语言进行比较,并展示该语言在机器学习和计算方面的总体前景。
免责声明 将没有语法解析。 Habrazhiteli有经验的开发人员,因此例如显示如何编写循环是没有意义的。两种语言的问题
如果您快速编写代码,程序将运行缓慢。 如果程序运行很快,请长时间编写它们。
经典Python属于第一类。 如果删除NumPy,请慢慢考虑使用纯Python。 另一方面,还有C和C ++之类的语言。 很难找到平衡点,因此大多数情况下,他们通常首先在一些灵活的东西上编写原型,然后在调试算法后,更快地将其重写为语言。 这是
两种语言中一个
明显问题的示例:例如,您必须用Python编写并用C或Cython重写它的周期很长。
机器学习和数据科学方面的专家有NumPy,Sklearn,TensorFlow。 他们多年来一直在解决问题,而在C语言中却没有任何一行,看来这两种语言的问题与他们无关。 事实并非如此,问题
隐含地显现出来,因为NumPy或TensorFlow中的代码实际上并不是真正的Python。 它用作启动内部内容的元语言。 内部恰好是C / Fortran(对于NumPy)或C ++(对于TensorFlow)。
例如,在PyTorch中,此“功能”很难看到,但在Numpy中,它却清晰可见。 例如,如果在计算中出现了经典的Python循环,则出问题了。 在生产代码中,不需要循环;您必须重写所有内容,以便NumPy可以对其向量化并快速进行计算。
同时,在许多人看来NumPy速度很快,一切都很好。 让我们看看NumPy在幕后拥有什么。
- NumPy试图解决Python类型灵活性问题,因此它具有相当严格的类型系统 。 如果数组具有某种类型,则其中将没有其他内容;如果
Float64 ,则无法进行任何处理。 - 调度。 根据数组的类型和需要执行的操作,NumPy内部将决定调用哪个函数以尽可能快地进行计算。 该库将尝试将经典Python排除在计算循环之外。
事实证明,Numpy的速度不如看上去的快。 这就是为什么有像
Cython或
Numba这样的项目的
原因 。 第一个从Python和C的“混合”生成C代码,第二个在Python中编译代码,通常这样做更快。
如果NumPy真的像许多人一样快,那么Cython和Numba的存在将毫无意义。
如果我们想快速找到大而复杂的内容,我们将重写Cython中的所有内容。 Cython中包装器质量的标准之一是生成的代码中是否存在纯Python调用。
一个简单的例子:我们添加类型(好)或不添加(坏),并且得到两个完全不同的代码,尽管除了类型之外,初始选项没有什么不同。

在生成C代码时,在第一种情况下,我们得到以下信息:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
而第二个
result =0. 会变成这样:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
指定类型后,C代码将快速运行。 如果未指定类型,我们将在C端看到普通的Python:标准Python调用,出于某种原因,从
double中创建了
float ,并计算了链接以及许多其他垃圾代码。 这段代码很慢,因为它会为每个操作调用Python。
是否可以一次解决所有问题
有趣的是,当我们想到某些东西时,我们尝试删除纯Python。 有两种选择方法。
- 使用Cython或其他工具。 您可以通过多种方法来优化Cython代码,从而最终几乎不需要进行Python调用。 但这不是最令人愉快的活动:在Cython中并不是所有事情都如此明显,并且花费的时间仅比在C语言中编写所有事情少一点。生成的模块可以在Python中使用,但仍然需要很长时间,会发生错误,代码并不总是很明显,并且尚不清楚如何进行优化。
- 使用Numba进行JIT编译 。
但是也许有更好的方法,我想这就是
朱莉娅 。
朱莉亚
创作者声称这是一种
快速 ,
高级且
灵活的语言,就编写代码的便利性而言,它可与Python相提并论。 在我看来,Julia就像一种
脚本语言:您无需执行C语言中的所有工作,因为C语言中的所有内容都是非常底层的,包括数据结构。 同时,您可以在常规控制台中工作,例如使用Python和其他语言。
Julia使用
即时编译 -这是提高速度的要素之一。 但是该语言适合计算,因为它是为计算而开发的。 朱莉娅(Julia)用于科学任务,并获得不错的表现。
尽管Julia试图看起来像是一种通用语言,但是Julia擅长计算,但不适用于Web服务。 例如,使用Julia而不是Django并不是最佳选择。
让我们看一下语言的功能,作为原始函数的示例。
function f(x) α = 1 + 2x end julia> methods(f)
此代码中有四个功能很明显。
- 使用Unicode实际上没有任何限制 。 您可以从有关深度学习或数值建模的文章中获取公式,使用相同的字符进行重写,所有内容都将起作用-Unicode几乎被缝在任何地方。
- 没有乘法符号。 但是,并非总是不可能做到这一点,例如,Julia会发誓2.x(浮点数乘以x)。
- 没有
return 。 通常,建议您编写return以便可以看到正在发生的事情,但是该示例将返回α ,因为赋值是一个表达式。 - 没有类型 。 看来,如果有速度,那么在某些时候应该出现这些类型? 是的,它们会出现,但是稍后。
Julia具有三个具有灵活性和速度的功能:
多个调度,元编程和并行性 。 我们将讨论前两个,并将并行化留给高级用户进行独立研究。
多重排程
在上面的示例中,对
methods(f)的调用出乎意料-该函数具有哪种方法? 我们已经习惯了拥有类对象,类具有方法的事实。 但是在Julia中,所有内容都由内而外:函数具有方法,因为该语言使用多个分派。
多重调度意味着将要执行的特定功能的变型由该功能的整个参数类型集确定。
我将在一个已经熟悉的示例中简要描述这是如何工作的。
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
相同函数针对不同类型集的变体称为方法。 代码中有两个:第一个用于所有浮点数,第二个用于其他所有内容。 当我们第一次调用该函数时,Julia将决定使用哪种方法以及是否对其进行编译。 如果它已经被调用和编译,它将采用那个。
由于在Julia中一切都不是我们习惯的方式,因此您可以在此处向用户类型添加函数,但是就OOP而言,它们不是类型方法。 它只是函数编写所在的字段,因为
函数与其他所有
函数都是同一个完整的对象 。
为了找出确切会触发什么,有一些特殊的宏。 它们以
@开头。 在该示例中,
@which宏使
@which可以找出在特定情况下调用了哪种方法。

在第一种情况下,Julia决定因为2是整数,所以它不适合
AbstractFloat ,因此将其称为第一个选项。 在第二种情况下,她认为它是
Float并且已经要求使用专门的版本。 如果您为某些特定类型添加其他方法,大约可以使用。
LLVM和JIT
Julia使用LLVM框架进行编译。 JIT编译库包含在语言包中。 第一次调用该函数时,Julia会查看该函数是否已用于此类型的集合,并在必要时进行编译。 首次启动将需要一些时间,然后一切都会快速进行。
该函数将在首次调用此参数集时进行编译。
编译器功能
- 编译器合理合理,因为LLVM是一个很好的产品。
- 大多数高级开发人员可以研究编译过程,并查看编译过程 。
- 朱莉娅和努巴的著作相似 。 在Numba中,您还创建了一个JIT装饰器,但是在Numba中,您不能“介入”太多并决定要优化或更改的内容。
为了说明编译器的工作,我将给出一个简单函数的示例:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
宏
@code_llvm允许您查看生成结果。 该
LLVM IR是
一个中间表示 ,一种汇编程序。
在代码中,函数参数乘以3,结果加1,返回结果。 一切都尽可能简单。 如果您对函数的定义有所不同,例如,将3替换为2,则所有内容都会改变。
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
看起来有什么区别:2、3、10? 但是Julia和LLVM看到,当您为整数调用函数时,您可以做得更聪明。 整数乘以2就是左移一位-它比乘积快。 但是,当然,这仅适用于整数,将
Float向左移动1位并获得乘以2的结果将不起作用。
自定义类型
Julia中的自定义类型与内置类型一样快。 对它们执行多个调度,它的速度与内置类型一样快。 从这个意义上说,多重调度机制深深地嵌入了该语言中。
逻辑上期望变量没有类型,只有值才有它们。 没有类型的变量只是标记,是某些容器上的标签。
类型系统是分层的。 我们不能创建具体类型的后代;抽象类型只能具有它们。 但是,不能实例化抽象类型。 这种细微差别不会吸引所有人。
正如该语言的作者在开发Julia时所解释的那样,他们想要获得结果,并且如果难以执行某些操作,则拒绝了。 这种分层类型的系统更易于开发。 这不是一个灾难性的问题,但是如果您一开始不把头脑从里到外,那将会很不方便。
类型可以参数化 ,有点像C / C ++。 例如,我们可能具有其中包含字段的结构,但是未指定这些字段的类型-这些是参数。 我们在实例化时指定一个特定的类型。
在大多数情况下,可以跳过类型 。 当类型可以帮助编译器猜测如何最佳编译时,通常需要使用它们。 在这种情况下,最好指定类型。 如果要获得更好的性能,还需要指定类型。
让我们看看什么是可能的,哪些不能被实例化。

第一种类型的
AbstractPoint无法实例化。 例如,这只是我们可以在方法中指定的每个人的共同父级。 第二行说
PlanarPoint{T}是此抽象点的后代。 在字段下方开始-在这里您可以看到参数化。 您可以在此处放置
float ,
int或其他类型。
第一种类型无法实例化,而对于所有其他类型,则不可能创建后代。 另外,默认情况下它们是
不可变的 。 为了能够更改字段,必须明确指定。
一切准备就绪后,您可以继续进行操作,例如,计算不同类型的点的距离。 在示例中,平面上的第一个点是
PlanarPoint ,然后在球体和圆柱上。 根据我们计算的两点之间的距离,我们需要使用不同的方法。 通常,该函数将如下所示:
function describe(p::AbstractPoint) println("Point instance: $p") end
对于
Float64 ,
Float32 ,
Float16 ,它将是:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
对于整数,距离计算方法将如下所示:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
对于每种类型的点,将调用不同的方法。
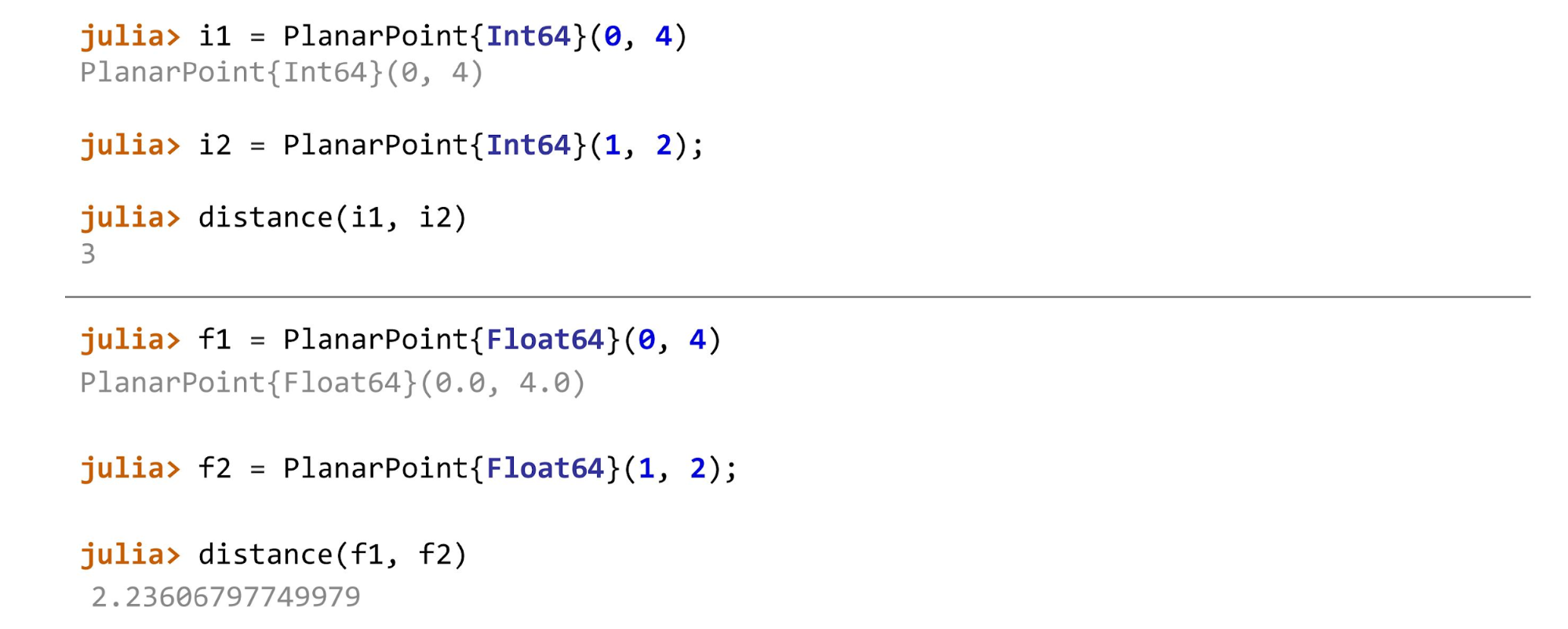
例如,如果您作弊并应用
distance(f1, i2) ,朱莉娅会发誓:“我不知道这种方法! 您问我这样的方法,并说它们都是同一类型。 您没有告诉我当一个参数为
float且另一个参数为
int时该如何计数。”
速度
您可能已经很高兴:“有一个JIT编译:编写很容易,它将很快生效。 扔掉Python并开始用Julia写作!”
但不是那么简单。 并非Julia的所有功能都会很快。 这取决于两个因素。
- 来自开发商 。 没有任何语言可以快速执行任何功能。 一个没有经验的开发人员甚至会用C编写代码,而这将比有经验的开发人员的Python代码慢得多。 任何语言都有其性能所依赖的技巧和细微差别。 不管是常规的静态编译器还是JIT编译器,都无法提供所有可能的选项并完全优化所有内容。
- 从型稳定 。 在更快的版本中,将编译按类型稳定的函数。
类型稳定性
什么是类型稳定性? 当编译器无法完全可靠地猜测类型会发生什么时,它必须生成大量包装器代码,以便输入的所有内容都可以正常工作。
一个了解类型稳定性的简单示例。

机器学习专家会说这是正常的relu激活:如果x> 0,则按原样返回,否则返回零。 一个问题是问号整数后面的零。 这意味着如果我们为浮点数调用此函数,则在一种情况下,将返回浮点数,而在另一种情况下,将返回整数。
编译器无法仅通过函数参数的类型来猜测结果的类型。 他还需要知道含义。 因此,它会生成很多代码。
接下来,我们创建一个数组,每100个随机数中的100个从0到1,将其移动0.5,以均匀分布正数和负数,并测量结果。 有两个有趣的点:点和函数。
rand(100,100)之后的点表示“应用于每个元素”。 如果您具有某种集合和标量函数,则可以结束它,其余的工作由Julia来完成。 我们可以假设这与普通编译语言中的普通循环一样有效。 无需编写-一切都会为您完成。
此时没有问题-
问题在函数本身内部 。 在体面的计算机上,对于此类矩阵,此类选项的估计执行时间为微秒。 但是实际上-毫秒,对于这么小的矩阵来说太过分了。
只需更改一行。

执行
zero(x)函数将生成与参数
(x)相同类型的零。 这意味着无论
x的值
x什么,结果的类型将始终由
x本身的类型知道。
当我们仅查看参数的类型并且已经知道结果的类型时,这些是类型稳定的函数。
如果需要查看参数的含义,则这些不是稳定的函数。
当编译器可以优化代码时,执行时间的差异可得到两个数量级。 在第二个示例中,它仅被精确分配给一个新的数组,只有几十个字节,仅此而已。 此选项比以前的选项有效得多。
当我们用Julia编写代码时,这是要注意的主要事情。 如果您使用Python编写代码,那么它将像使用Python一样工作。 如果在NumPy上执行相同的操作,则带或不带点的零都不起作用。 但是在Julia中,这可能会大大降低性能。
幸运的是,有一种方法可以找出问题是否存在。 这是
@code_warntype宏,它使您能够找出编译器是否可以猜测哪些类型,并在一切正常的情况下进行优化。

在第一个选项(左)中,编译器不确定类型,并以红色显示。 在第二种情况下,此类参数将始终为
Float64 ,因此您可以生成短得多的代码。
这还不是LLVM,但是标记为Julia的代码(
return 0或
return 0.0会产生两个数量级的性能差异。
元编程
元编程是当我们在程序中创建程序并在运行中运行它们时。
这是一种功能强大的方法,可让您执行许多不同的有趣的事情。 Django ORM是一个经典示例,它使用元类创建字段。
许多人都知道Python Zen的作者
蒂姆·彼得斯 (
Tim Peters)的免责声明:
“元类是一种更深的魔力,99%的用户永远都不必担心。 如果您想知道Python是否需要元类,则不需要它们。 如果您需要它们,那么您确切地知道为什么以及如何使用它们。”
使用元编程时,情况类似,但是在Julia中它的缝合要深得多,这是整个语言的重要特征。 Julia代码与任何其他代码都是相同的数据结构,您可以操纵,组合,创建表达式,所有这些都将起作用。
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
宏是Julia中的元编程工具之一 :我们给它们一些东西,它们看起来像,添加正确的,删除不必要的,并给出结果。 在前面的所有示例中,我们将调用传递给函数,并且内部的宏解析了该调用。 所有这一切都发生在使用语法树的级别上。
您可以解析非常简单的表达式:例如,如果它是
(x+1) ,则这是对
+函数的调用(像许多其他语言一样,它不是运算符,而是一个函数)和两个参数:一个字符(冒号表示它是一个字符) ),第二个只是一个常数。
另一个简单的宏示例:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
例如,使用宏可以创建进度指示器或数据帧过滤器-这是Julia中的常见机制。
宏不是在调用时执行,而是在解析代码时执行。
这是Julia的主要宏功能。 - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
生态系统
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.