我们已经开发了一个数据中心网络的设计,它使您可以部署大于10万台服务器的计算集群,其对分带宽每秒超过一个PB。
从Dmitry Afanasyev的报告中,您将了解新设计的基本原理,扩展因这些问题而产生的拓扑,解决方案,有关在具有大量ECMP路由的密集连接拓扑中路由和扩展现代网络设备的转发平面功能的功能。 此外,Dima还简要介绍了外部连接的组织,物理级别,电缆系统以及进一步提高容量的方法。

大家下午好! 我叫Dmitry Afanasyev,我是Yandex的网络架构师,主要负责数据中心网络的设计。

我的故事将与更新的Yandex数据中心网络有关。 这在很大程度上是我们设计的发展,但同时也有一些新元素。 这是一个评论演示文稿,因为有必要在短时间内适应大量信息。 我们从选择逻辑拓扑开始。 然后,将概述控制平面以及数据平面的可伸缩性问题,以及在物理层上将要发生的情况的选择,让我们看一下设备的某些功能。 我们还将讨论MPLS在数据中心中正在发生的事情,我们早些时候就谈到了这一点。

那么,就工作负载和服务而言,Yandex是什么? Yandex是典型的超缩放器。 如果您朝着用户的方向看,我们主要处理用户的请求。 此外,由于我们还具有存储服务,因此各种流服务和数据输出。 如果离后端更近,那么那里就会出现基础架构负载和服务,例如分布式对象存储,数据复制,以及持久队列。 负载的主要类型之一是MapReduce等,流处理,机器学习等。

所有这些基础设施如何发生? 同样,我们是一个非常典型的超级溜冰者,尽管也许我们离较小的超级溜冰者所在的频谱更近一些。 但是我们拥有所有属性。 我们尽可能使用商品硬件和水平缩放。 我们已经充分利用了资源池:我们不使用单独的机器,单独的机架,而是将它们组合成一个可互换的资源大池,并使用一些额外的服务进行规划和分配,并且我们使用所有这些池。
因此,我们有了下一层-操作系统层计算集群。 完全控制我们使用的技术堆栈非常重要。 我们控制端点(主机),网络和软件堆栈。
我们在俄罗斯和国外都有几个大型数据中心。 它们通过使用MPLS技术的骨干网相连。 我们的内部基础结构几乎完全基于IPv6,但是由于我们需要处理仍主要通过IPv4传递的外部流量,因此我们需要以某种方式将通过IPv4到达的请求传递给前端服务器,而对外部IPv4仍然有所帮助互联网-例如,用于索引。
数据中心网络设计的最后几次迭代使用多层Clos拓扑,并且仅使用L3。 我们前段时间离开L2,松了一口气。 最后,我们的基础架构包括数十万个计算(服务器)实例。 一段时间前的最大群集大小约为1万台服务器。 这主要是由于相同的群集级操作系统(调度程序,资源分配等)如何工作,由于基础架构软件方面已经取得了进展,因此现在的目标是在一个计算群集中约有10万台服务器,并且我们有一个任务-能够建立网络工厂,以允许在这样的集群中有效地汇集资源。

我们想要数据中心网络有什么? 首先-很多便宜且相当均匀分布的带宽。 因为网络是我们可以汇集资源的基础。 新的目标大小是在一个群集中大约10万台服务器。
另外,当然,我们需要一个可伸缩且稳定的控制平面,因为在如此大的基础架构上,即使只是随机事件也会引起很多麻烦,并且我们不希望控制平面让我们感到头痛。 同时,我们要最小化其中的状态。 条件越小,一切正常且越稳定,越容易诊断。
当然,我们需要自动化,因为不可能手动管理这样的基础结构,并且不久前也不可能。 只要有可能,我们就需要尽可能的操作支持和CI / CD支持。
由于数据中心和集群的规模如此之大,支持增量部署和扩展而不中断服务的任务已变得十分紧迫。 如果在群集上一千辆汽车的大小可能接近一万辆汽车,那么它们仍然可以作为单个操作推出-也就是说,我们计划扩展基础架构,并且单个操作添加了数千台机器,那么就不会出现十万辆汽车的群集就像这样,它已经建立了一段时间。 希望一直以来,所有已经被抽出的资源,已部署的基础结构都是可用的。
还有我们要离开的一项要求:这是对多租户的支持,即虚拟化或网络分段。 现在,我们不需要在网络工厂级别执行此操作,因为分段已进入主机,这使得扩展非常容易。 由于IPv6和较大的地址空间,我们不需要在内部基础结构中使用重复的地址,所有寻址已经是唯一的。 而且由于我们对主机进行了过滤和网络分段,因此我们不需要在数据中心网络中创建任何虚拟网络实体。

一个非常重要的事情是我们不需要。 如果可以从网络中删除某些功能,则这将大大简化使用寿命,并且通常会扩大可用硬件和软件的选择范围,并大大简化诊断。
那么,我们不需要什么,我们能够拒绝什么呢?在发生这种情况的那一刻,我们并不总是感到高兴,而当过程完成时,我们却会欣慰地拒绝呢?
首先,拒绝L2。 我们不需要实数或仿真的L2。 由于我们控制应用程序堆栈,因此在很大程度上未使用。 我们的应用程序是水平扩展的,可以与L3寻址一起使用,他们并不真正担心某些特定实例已关闭,他们只是推出了一个新实例,而无需在旧地址上推出,因为存在单独的服务发现和监视集群中机器的级别。 我们不会将此任务转移到网络上。 网络的任务是将数据包从A点传送到B点。
另外,我们也没有地址在网络中移动的情况,因此需要对其进行监视。 在许多设计中,通常需要此功能来支持VM移动性。 我们不在大型Yandex的内部基础架构中使用虚拟机的移动性,此外,我们相信,即使做到了这一点,在网络支持下也不应该发生。 如果确实需要执行此操作,则需要在主机级别执行此操作,并驱动可迁移到覆盖层中的地址,以免对路由系统本身底层(传输网络)造成影响或对其进行过多的动态更改。
我们不使用的另一种技术是多播。 我可以详细告诉您原因。 这使生活变得更加轻松,因为如果有人与他打交道,并观看多播的控制平面到底是什么样子-在除最简单的安装之外的所有安装中,这都是一个很大的麻烦。 而且,例如,很难找到运行良好的开源实现。
最后,我们设计网络,使它们不会有太多更改。 我们可以指望路由系统中外部事件的流很小。

开发数据中心网络时会出现什么问题,应考虑哪些限制? 费用当然。 可扩展性,我们要增长到什么水平。 需要扩展而不停止服务。 带宽可用性。 对网络,监视系统和运营团队正在发生的事情的可见性。 同样,尽可能多地支持自动化,因为可以在不同级别上解决不同的任务,包括引入其他层。 好吧,而不是(只要有可能)依赖于供应商。 尽管在不同的历史时期(取决于要查看的部分),这种独立性更容易实现或更难实现。 如果我们只使用网络设备的一部分芯片,那么直到最近,还要谈论与供应商的独立性,如果我们还想要高吞吐量的芯片,那可能是非常随意的。

我们将使用什么逻辑拓扑来构建我们的网络? 这将是一个多层次的Clos。 实际上,目前没有真正的替代方案。 即使我们将其与具有较大基数的交换机相比较,即使我们将其与现在更受学术关注的各种高级拓扑进行比较,Clos拓扑也足够好。
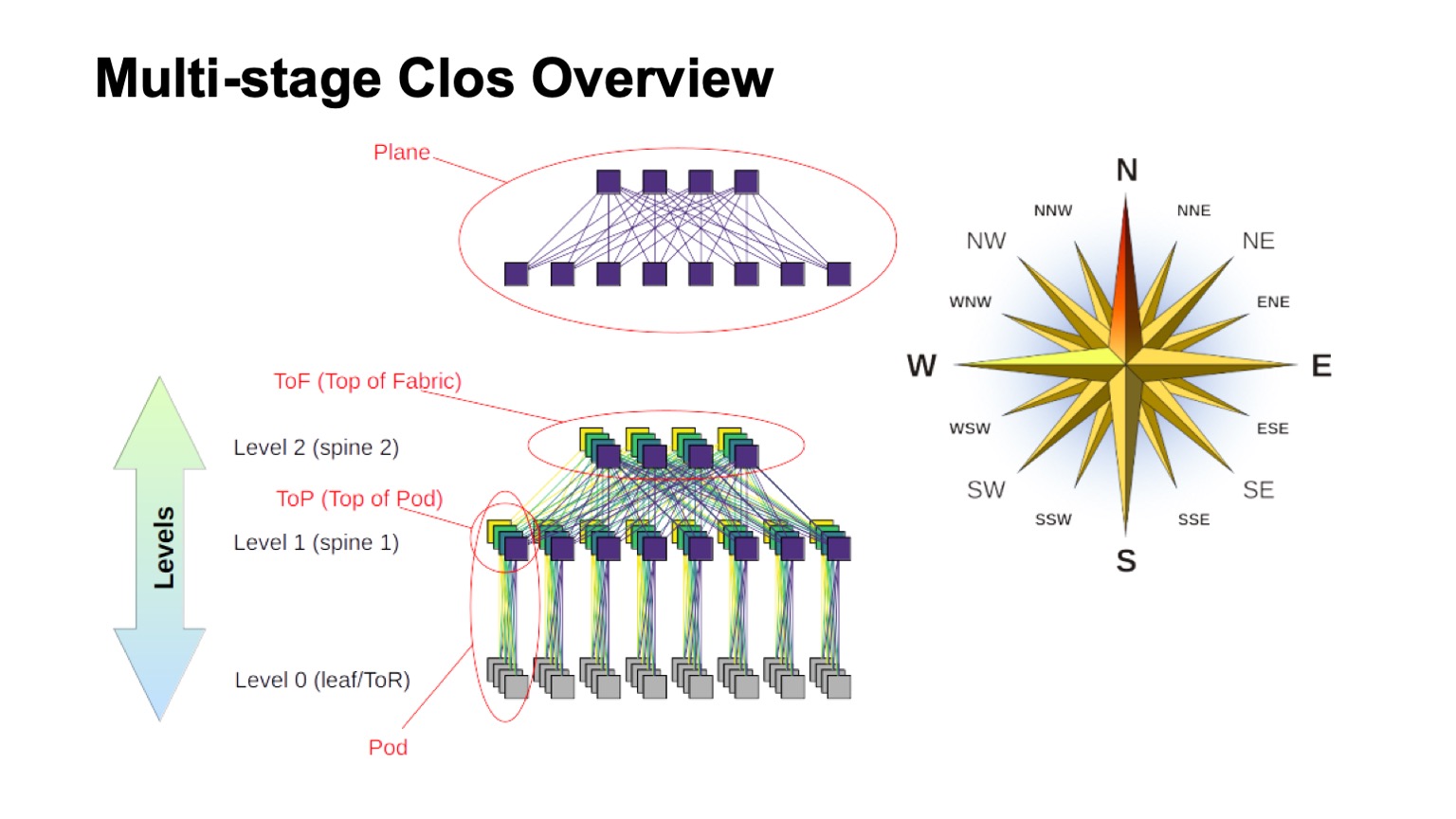
分层Clos网络是如何近似构造的?其中的不同元素是什么? 首先,风向上升,找出北,南,东,西。 这种类型的网络通常是由东西向流量很大的人建立的。 至于其余的元素,顶部显示了由较小的交换机组装而成的虚拟交换机。 这是递归构建Clos网络的基本思想。 我们采用具有某种基数的元素并将其连接起来,以便将发生的情况视为具有较大基数的开关。 如果您需要更多,可以重复该过程。
例如,在使用两级Clos的情况下,当可以清楚地区分图中的垂直组件时,通常将它们称为平面。 如果我们用三层的主干交换机(不是边界线和ToR交换机,并且仅用于运输)来构建Clos,那么飞机将看起来更加复杂,两层的外观完全一样。 ToR或叶子交换机的块以及相关的第一级主干交换机,我们称为Pod。 Pod顶部的Spine级别1开关是Pod的顶部,Pod的顶部。 位于整个工厂顶部的交换机是工厂的顶层,即“织物顶部”。

当然,会出现一个问题:Clos网络已经建立了一段时间,这种想法本身通常来自古典电话TDM网络的时代。 也许出现了更好的事情,也许您可以以某种方式做得更好? 是的,没有。 从理论上讲,是的,实际上在不久的将来,肯定不会。 因为存在许多有趣的拓扑,所以其中一些甚至被用于生产中,例如Dragonfly被用于HPC应用程序中。 还有一些有趣的拓扑,例如Xpander,FatClique,水母。 如果您最近查看诸如SIGCOMM或NSDI之类的会议上的报告,则会发现大量关于替代拓扑的论文(具有比Clos更好的属性(一种或另一种))。
但是所有这些拓扑都有一个有趣的特性。 它阻止了它们在数据中心网络中的实施,我们正试图在商品硬件上构建这些中心,而这些中心花费合理的钱。 不幸的是,在所有这些替代拓扑中,大部分频段都不是通过最短路径访问的。 因此,我们立即失去了使用传统控制平面的能力。
从理论上讲,该问题的解决方案是已知的。 例如,这些是使用第k条最短路径对链接状态的修改,但是同样,没有协议可以在生产中实施并且可以在设备上大量使用。
此外,由于大多数容量不能通过最短路径访问,因此我们不仅需要修改控制平面,以便它选择所有这些路径(顺便说一句,这是控制平面中的一个更大的状态)。 我们仍然需要修改转发平面,并且通常至少需要两个附加功能。 这是一次就主机上的转发包做出所有决定的机会。 这实际上是源路由,在有关互连网络的文献中有时将其称为一次性转发决策。 自适应路由已经是我们在网元上所需的功能,例如归结为以下事实:我们基于有关队列中最小负载的信息选择下一跳。 例如,其他选项也是可能的。
因此,这个方向很有趣,但是,a,我们现在不能应用它。

好的,决定使用Clos的逻辑拓扑。 我们将如何扩展? 让我们看看它是如何工作的以及可以做什么。

在Clos网络中,有两个主要参数可以通过某种方式改变并获得某些结果:基数元素和网络中的层数。 我示意性地描述了一个和另一个如何影响大小。 理想情况下,我们将两者结合起来。
可以看出,Clos网络的总宽度是南部基数的所有水平脊柱交换机,我们断开的链路数量以及分支方式的乘积。 这就是我们扩展网络规模的方式。
至于容量,特别是在ToR交换机上,有两个缩放选项。 我们可以在维持通用拓扑的同时使用更快的链接,或者可以添加更多平面。
如果您查看Clos网络的详细版本(位于右下角),并使用下面的Clos网络返回此图片...
...然后这是完全相同的拓扑,但是在此幻灯片上,它以更紧凑的方式折叠,并且工厂平面彼此重叠。 这是一回事。

缩放Clos网络的数字看起来是什么样的? 这里我有关于网络可以获得的最大宽度,机架,ToR交换机或叶子交换机的最大数量(如果它们不在机架中)的数据,我们可以根据对棘刺使用的交换机基数来获得级别以及我们使用的级别数。
它显示了每个机架以20 kW的速度我们可以拥有多少个机架,多少服务器以及所有这些消耗的功率。 早些时候,我提到过我们的目标是集群规模约为10万台服务器。
可以看出,在整个结构中有两个半选项值得关注。 有一个带有两层棘刺和64端口交换机的选项,有点短。 然后,完美适合两个级别的128端口(带128基数)脊椎交换机,或三个级别的32根脊椎交换机。 在所有基数和级别更高的所有情况下,您都可以建立一个非常大的网络,但是如果您查看预期的消耗量,通常会有千兆瓦。 您可以铺设电缆,但是我们不太可能在一处获得这么多的电。 如果您查看统计数据,就可以看到数据中心的公共数据-可以发现的数据中心很少,估计容量超过150 MW。 更重要的是-通常,数据中心园区,几个大型数据中心之间的位置都非常接近。
还有另一个重要参数。 如果查看左列,则会在此处指示可用带宽。 很容易注意到,在Clos网络中,端口的很大一部分用于交换机之间的相互连接。 可用带宽是您可以分配给服务器的带宽。 自然,我在说的是条件端口和地带。 通常,网络内的链接要比与服务器的链接要快,但是,就我们可以将其分发给服务器设备而言,在每个频带单位内,网络本身仍存在更多频带。 而且,我们做的次数越多,将该条带提供给外部的单位成本就越高。
而且,即使这个额外的频带也不完全相同。 虽然跨度很短,但我们可以使用诸如DAC(直接连接铜线,即双芯电缆)或多模光学器件之类的东西,它们花费的钱或多或少是合理的。 一旦我们更真实地切换到跨度-通常,这就是单模光学元件,并且这个额外频段的成本会显着增加。
再次回到上一张幻灯片,如果我们在不重新订阅的情况下建立Clos网络,那么可以很容易地查看图表,了解网络的构建方式-添加每个级别的骨干交换机,我们重复下面的整个内容。 加级别-加上整个相同的频段,交换机上的端口数量与上一个级别相同,收发器的数量相同。 因此,非常希望使脊柱开关的水平数最小化。
根据这张图片,很明显,我们确实希望基于具有128基数的开关之类的东西。

原则上,这里的一切都与我刚才说的相同,以后可能会考虑使用此幻灯片。

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
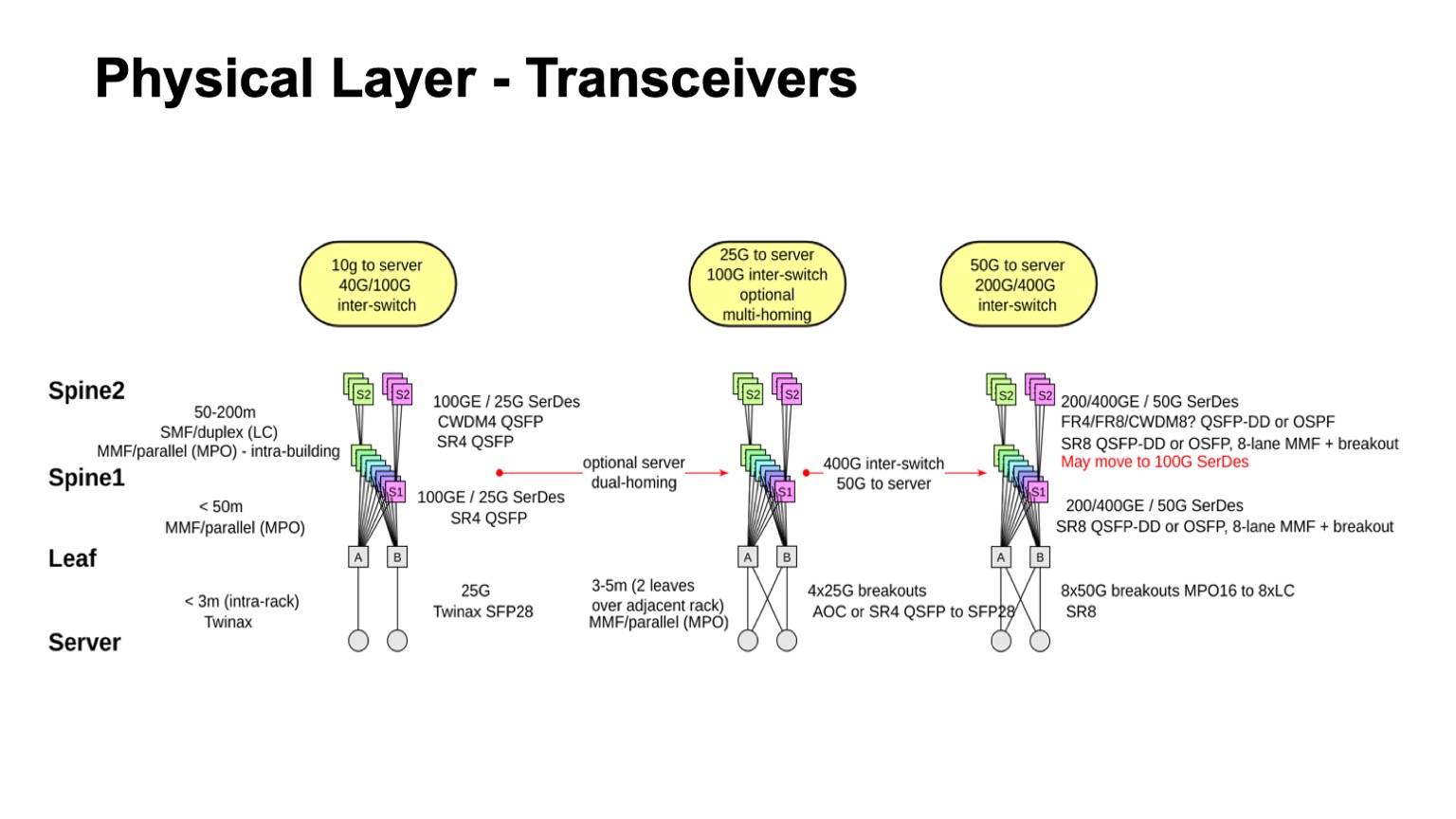
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
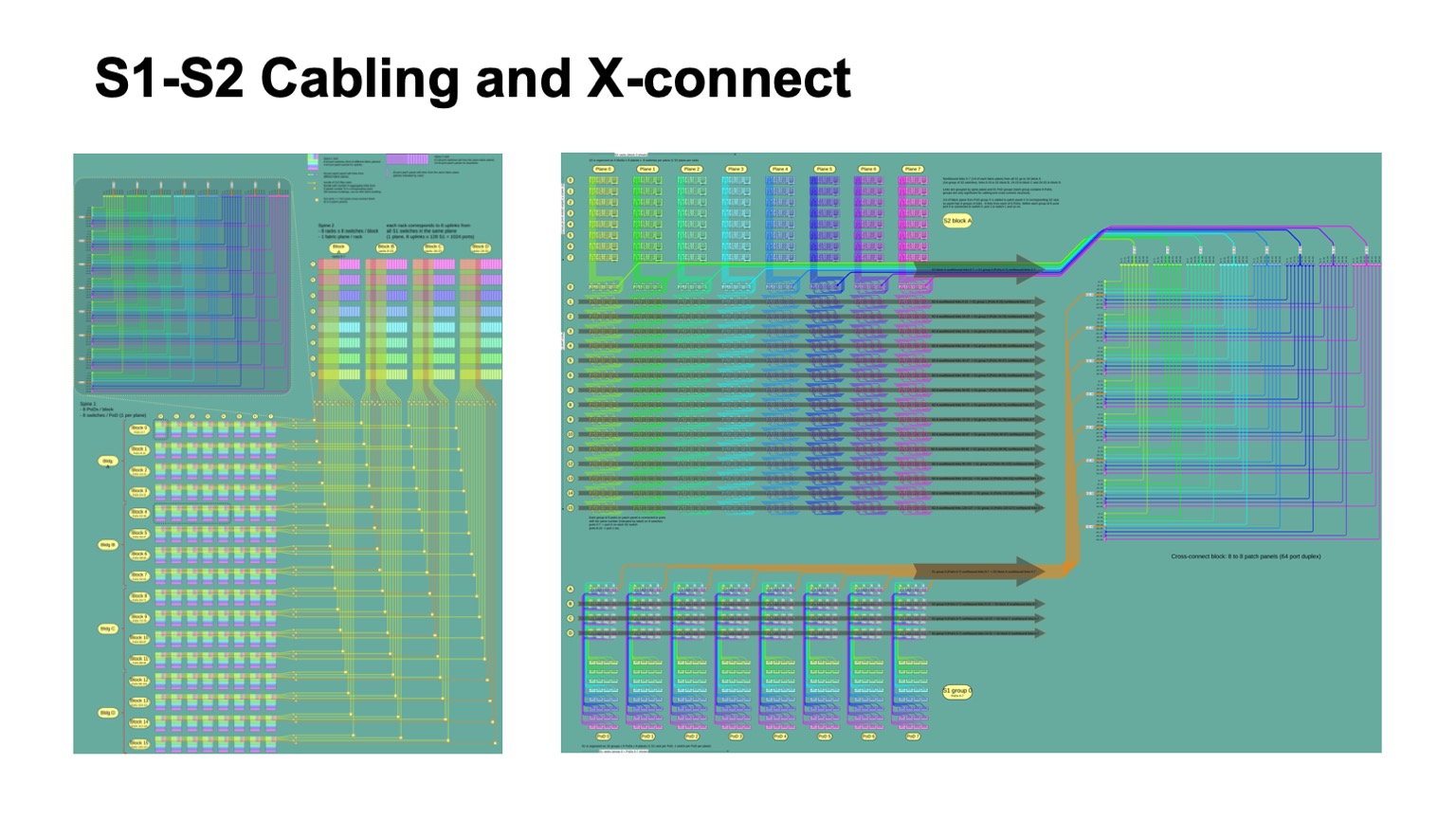
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

这是它的外观。 -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. . , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. 这就是为什么。

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . 谢谢啦