你好
您经常在社交网络上看到有毒评论吗? 这可能取决于您正在观看的内容。 我建议对此主题进行一些实验,并教神经网络确定仇恨评论。
因此,我们的全球目标是确定注释是否具有侵略性,也就是说,我们正在处理二进制分类。 我们将编写一个简单的神经网络,在来自不同社交网络的评论数据集中对其进行训练,然后使用可视化进行简单分析。
对于工作,我将使用Google Colab。 此服务使您可以运行Jupyter Notebook,并免费访问GPU(NVidia Tesla K80),从而加快学习速度。 我将需要后端TensorFlow(Colab 1.15.0中的默认版本),因此只需升级到2.0.0。
我们导入模块并更新。
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
您可以看到这样的当前版本。
print(tf.__version__)
准备工作完成后,我们将导入所有必要的模块。
import os import numpy as np
使用的库的描述
- keras.preprocessing.Text-用于文本处理,以数字形式提交以训练神经网络
- sklearn.train_test_split-从训练中分离测试数据
- sklearn.normalize-标准化测试和训练数据
用Kaggle解析数据
我直接将数据加载到Colab笔记本电脑本身。 此外,没有任何问题,我已经在提取它们。
path = 'labeled.csv' df = pd.read_csv(path) df.head()
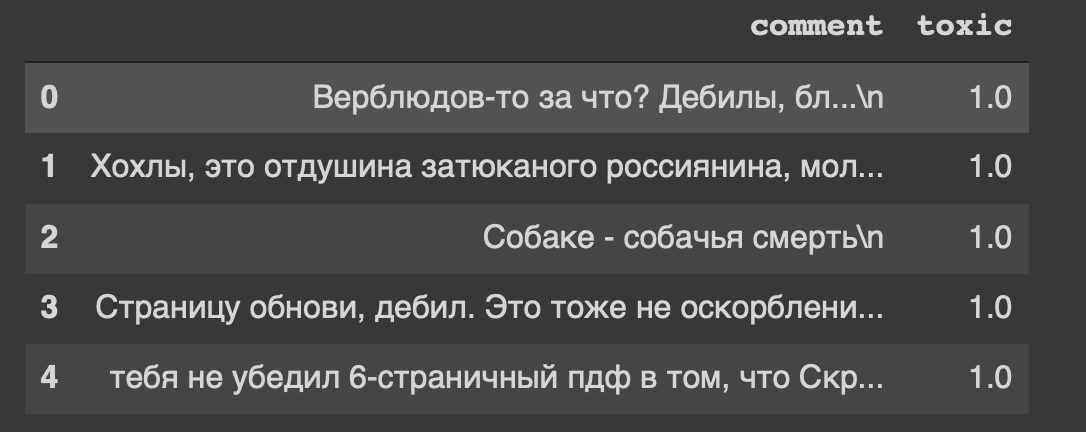
这就是我们数据集的标题...我也从某种意义上对“刷新页面,白痴”感到不安。
因此,我们的数据在表格中,我们将其分为两部分:用于训练的数据和用于测试模型的数据。 但这只是全部文字,需要做些事情。
资料处理
从文本中删除换行符。
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
注释具有真实的数据类型,我们需要将它们转换为整数。 接下来,将其保存在单独的变量中。
target = np.array(df['toxic'].astype('uint8')) target[:5]
现在,我们将使用Tokenizer类对文本进行一些处理。 让我们写一个副本。
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
快速了解参数- char_level-指示是否将单个字符视为一个单词
现在,我们将使用该类来处理文本。
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
我们有14k样本行和30k特征列。

我从两个层次构建模型:密集和辍学。
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
我们对矩阵进行归一化,然后按照约定将数据分为两部分(训练和测试)。
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
模型训练
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
我将在最后的迭代中展示学习过程。

可视化学习过程
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
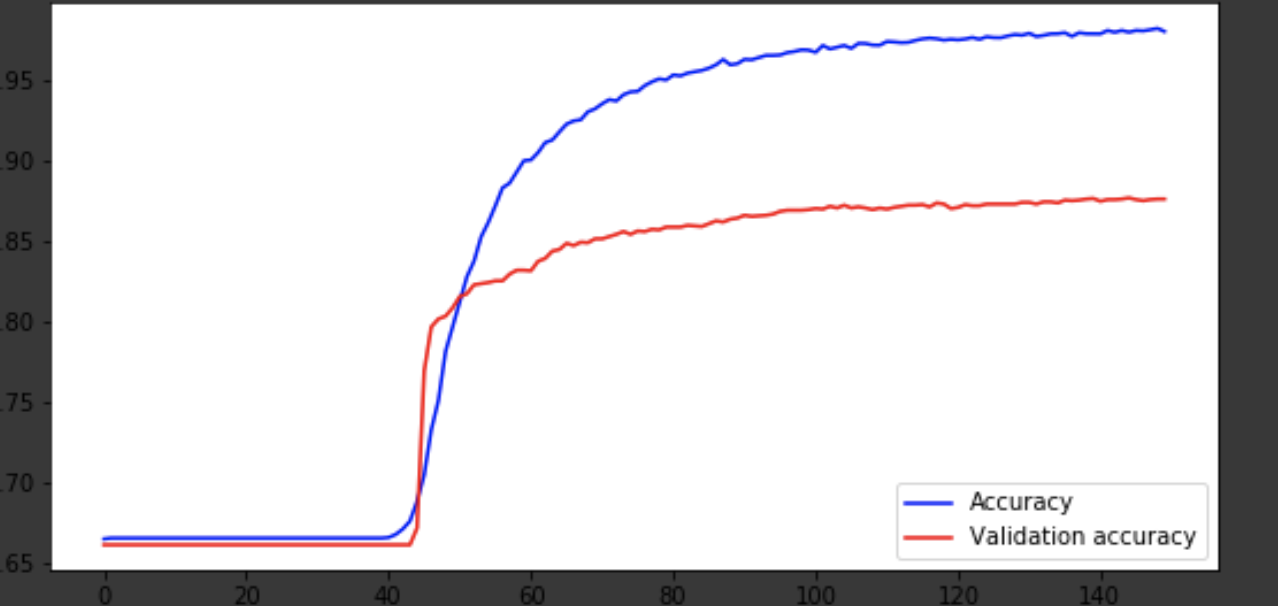
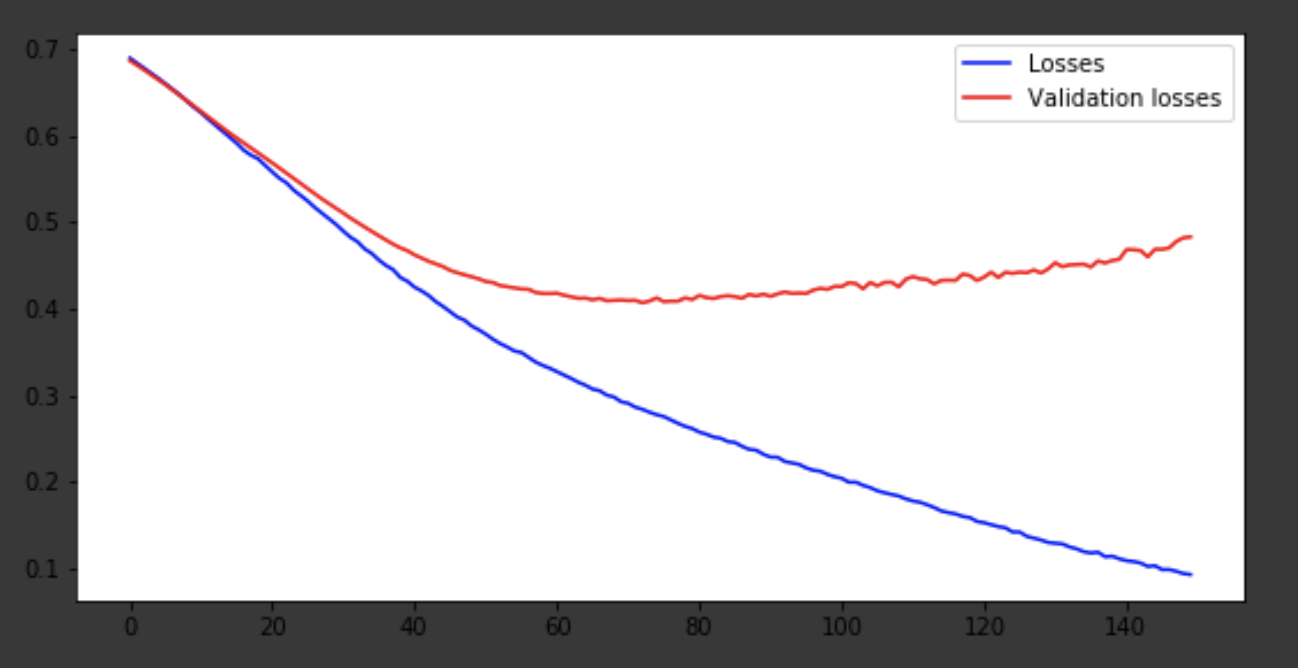
结论
该模型大约在75年代问世,然后表现不佳。 0.85的准确度不会打乱。 您可以玩弄层数,超参数,并尝试改善结果。 它总是很有趣,并且是工作的一部分。 在评论中写下您的想法,我们将看到这篇文章能赢得多少顶帽子。