本文讨论了构建个性化产品和内容推荐的方法以及可能的用例。
个性化的产品和内容推荐可用于增加转化次数,平均检查并改善用户体验。

使用该方法的一个示例是Amazon和Netflix。 亚马逊在成立之初就开始使用协作过滤方法,仅通过该算法就实现了10%的收入增长。 通过基于推荐系统算法的方法,Netflix将观看内容的数量增加了40%。 现在,命名一个不使用这种方法的公司要比列出所有使用这种方法的公司容易。
Netflix有一个与此技术有关的有趣故事。 在2006-2009年(甚至在Kaggle ML比赛场地流行之前),Netflix宣布进行公开比赛以改善算法,奖金池为1,000,000美元。 比赛历时2年,数千名开发人员和科学家参加了比赛。 如果Netflix在该州雇用他们,费用将比承诺的奖金高出许多倍。 结果,一个团队通过比另一个团队提前2小时发送具有所需质量的解决方案而获胜,从而重复了获胜者的结果。 结果,这笔钱流到了一支快速团队。 竞争已成为个性化推荐领域质变的催化剂。
解决构建推荐系统问题的主要方法是协作过滤。
协作过滤的想法很简单-如果用户购买了产品或观看了内容,我们会找到具有相似品味的用户,并向我们的客户推荐像他这样的人已经消费了,但客户却没有。 这是基于用户的方法。
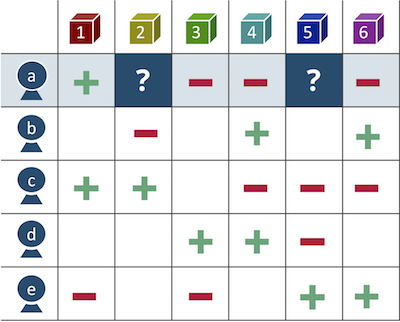 图1-产品偏好矩阵
图1-产品偏好矩阵同样,您可以从商品的角度看问题,然后通过增加平均支票或用类似物替换没有库存的商品,将补充商品拿到客户的购物篮中。 这是一种基于项目的方法。
在最简单的情况下,将使用查找最近邻居的算法。
示例:如果玛丽亚喜欢电影《泰坦尼克号》和《星球大战》,则最接近她口味的用户将是安雅,她除了这些电影外还观看了《八公》。 让我们推荐玛丽亚电影“八公”。 值得澄清的是,他们通常不使用一个最近的邻居,而是使用多个邻居,并对结果取平均值。
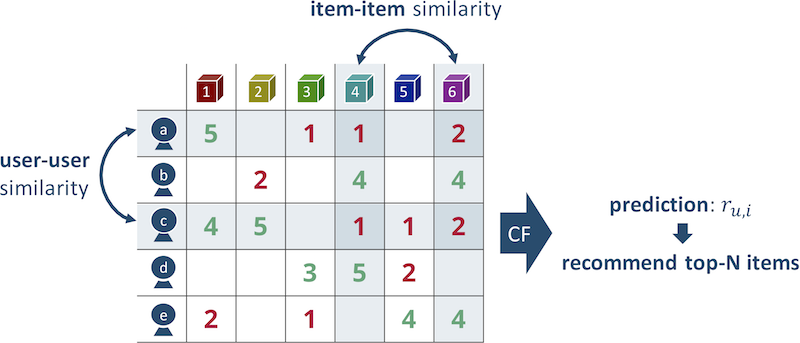 图2最近邻居算法的操作原理
图2最近邻居算法的操作原理一切似乎都很简单,但是使用这种方法的建议质量很小。
考虑基于矩阵属性或更确切地说基于矩阵分解的推荐系统的复杂算法。
经典算法是SVD(奇异矩阵分解)。
该算法的含义是,产品偏好矩阵(行是用户,列是用户与之交互的产品的矩阵)表示为三个矩阵的乘积。
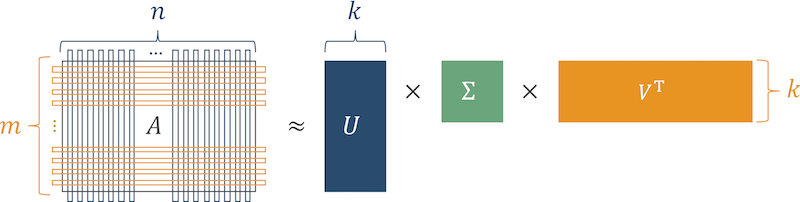 图3 SVD算法
图3 SVD算法恢复原始矩阵后,出现用户为零且“大”数字的单元格,表示对该产品潜在的兴趣程度。 排列这些数字,并获得与用户相关的产品列表。
在此操作过程中,用户和产品出现“潜在”标志。 这些是表明用户和产品处于“隐藏”状态的标志。
但是,众所周知,除了“潜在”用户和产品外,用户和产品也都有明显的迹象。 这是性别,年龄,平均购买收据,地区等。
让我们尝试用这些数据丰富我们的模型。
为此,我们使用分解机算法。
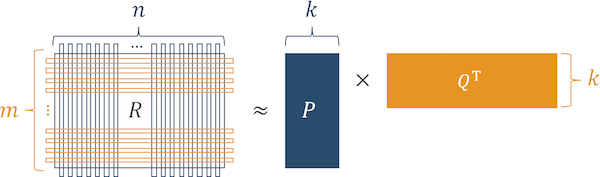 图4分解机的操作算法
图4分解机的操作算法根据我们的经验,在
Data4上 ,针对在线商店构建推荐系统(即分解机)的案例研究得出了最佳结果。 因此,我们使用分解机为我们的客户KupiVip构建了一个推荐系统。 RMSE指标的增长为6-7%。
但是基于矩阵的方法有其缺点。 货物相互组合的广义模式的数量不多。 为了解决这个问题,建议使用神经网络。 但是神经网络需要只有大公司才能拥有的大量数据。
根据我们在
Data4的经验,只有一个客户拥有一个神经网络,用于提供最佳结果的个性化产品推荐。 但是,成功的话,您可以获得最高10%的RMSE指标。 在YouTube和一些最大的内容网站上使用神经网络。
用例
对于在线商店
- 在在线商店的页面上推荐与用户相关的产品
- 使用产品卡中的“您可能喜欢”字样
- 在购物篮中,推荐其他商品(电视遥控器)
- 如果产品没有库存,建议使用类似产品
- 制作个性化新闻通讯
对于内容
- 通过推荐相关文章,电影,书籍,视频来提高参与度
其他
- 推荐约会应用中的人
- 推荐餐厅的菜肴
在本文中,我们讨论了设备推荐系统和案例研究的基础。 我们了解到,主要原则是推荐口味相似的人喜欢的产品,并使用协作过滤算法。
在下一篇文章中 ,将考虑基于实际业务案例的推荐系统的生活技巧。 我们显示了最适合使用哪些指标,以及选择哪个接近系数进行预测。