在
上一篇文章中,我们讨论了推荐系统和用例的基础。 我们了解到,主要原则是推荐具有相似品味的人喜欢的产品并应用协作过滤算法。
在本文中,将考虑基于实际业务案例的推荐系统的生活技巧。 它将显示最适合使用哪些度量标准以及为预测选择哪种接近程度。
机器学习使用各种指标来评估算法的性能。 但是在业务中,基本指标是相同的-解决方案的实施将带来多少资金。 基于此,在
Data4团队
实施的情况下 ,我们尝试增加每位用户的总收入。
为了使收入最大化,了解用户购买了哪些产品很有用。 但是不幸的是,如果我们仅基于购买数据建立产品偏好矩阵,那么我们的矩阵将变得稀疏,质量将受到损害。
Lifehack 1号
让我们在产品偏好矩阵中不仅使用购买,还使用中间步骤:单击卡片,添加到购物篮中,下订单。
我们为每个动作分配一个加权系数,我们的矩阵将变得更“密集”。
但是,并非所有产品都可以平等地转换。 打开卡后,由于商品的“内部”属性,人们可能无法继续购买。 示例:经常看到奢侈品,但很少购买。
生活技巧2
让我们为渠道的每个阶段建立商品分配,并从建议中删除每个阶段转化率最低的产品的5-10%。 最主要的是不要“用水泼婴儿”。 其余商品将具有“内部”属性,不会干扰购买。 内部属性的一个示例是可用的衣服尺码。 如果产品好,但只有一种尺寸,则转换率会很低。
我们找出了商品,现在让我们看一下如何衡量用户的“相似性”。
有许多相似性指标,从余弦接近度,最小二乘开始,到以奇异选项结束。
Lifehack 3号
根据
Data4在构建在线商店推荐系统中的经验,正在处理排出的矩阵。 对于此类矩阵,最好使用接近系数-提花。 与改变算法相比,这增加了度量标准。
Lifehack 4号
在使用神经网络之前,请尝试使用SVD和分解机。 可以用
图1分解机的工作原理
Lifehack 5号
通过图像识别相似产品很有趣,但是使用基于行为的SVD的质量更好。
Lifehack 6号
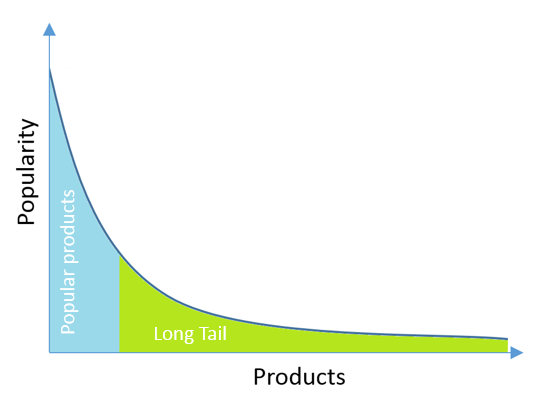
我们向新用户推荐流行产品(这是解决冷启动问题的方法),并从商品受欢迎程度的长尾巴向常规用户推荐流行产品。 当推荐适合用户的低频产品时,建议会很好地起作用。 推荐《泰坦尼克号》电影没有任何意义,如果用户想观看它,他已经看过了。 但是鲜为人知的电影或产品可以使用户感到惊喜。
Lifehack 7号
提出各种建议,没有人愿意打开页面,看到10相同的皮大衣,或只看一个导演的电影。 各种内容会增加购买的可能性。

Lifehack 8号
选择一个您了解其工作原理的指标。 让我们做一个简单的RMSE,但比nDCG @ K(此度量标准合适)可靠的结果,以及一个随机结果。
Lifehack 9号
建议可能会激怒人们,因此如果您不知道她们的尺码,则女性不应建议穿大尺寸的衣服。
Lifehack 10号
仅对用户进行A / B测试会告诉您该解决方案的工作方式。 质量指标-中间结果,A / B测试-确认,这可能会让您失望,但通常会令您满意。
使用描述的技术,我们的
Data4团队进行了几种实施推荐系统的案例。
在本文中,我们谈到要提高推荐系统的质量,您可以1)考虑中间用户的操作2)消除低转化率的产品3)对稀疏矩阵使用提花系数4)如果您不是Google则使用SVD和因式分解机5)搜索邻近度时要小心根据图片,如果预算有限6)从流行程度的尾部向老用户推荐非显而易见的产品7)建议各种产品8)使用正确的质量指标 wa 9)不要冒犯建议的人10)使用A / B测试来验证结果。