
据分析师称,未来几年数据中心市场将以每年38%的速度增长,并在五年内增长到350亿美元,而资源密集型的利基市场(就计算强度而言)是深度学习,神经网络和AI任务。
当然,英特尔将毫不动摇地观看英伟达(以及在较小程度上包括AMD)如何利用其GPU占领这一市场,包括增长最快的领域。 上周,微电子行业巨人一次发表了几项备受瞩目的公告:
Aurora计算模块
在这些CPU,GPU和oneAPI上,它们将组成同名超级计算机的Aurora计算模块,性能级别为1 exaflops(每秒10 ^ 18次操作)。 假定该机器将安装在美国能源部的阿贡国家实验室中。

每个计算模块都有两个通过CXL总线连接的Sapphire Rapids处理器和六个GPU。

根据
AnandTech的估计 ,在
如上所述的200个机架的系统中,如果减去网络和驱动器的预留空间,大约将适合2400个两单元Aurora节点。 总共约有5,000个Sapphire Rapids处理器和15,000个Ponte Vecchio。 如果将声明的1 exaflops性能除以GPU数量,则每个GPU大约有66.6 teraflops。 此外,假设CPU性能为14 teraflops,我们仍然可以获得约50 teraflops,也就是说,到2021年,这将使数据中心的GPU性能提高五倍。
当然,计划不仅限于能源部的超级计算机。 英特尔宣布联想和Atos已经准备发布基于Xeon CPU,X
e GPU和oneAPI的服务器平台。 因此,某种形式的Aurora计算模块将在其他数据中心中找到应用。
超级计算机应该在2021年启动。 同时,7纳米X
e GPU应该出现在市场上。
据英特尔称,现在传统的高性能解决方案(HPC)与AI融合,转移到使用深度学习的工作负载上。 HPC,AI和分析是驱动对计算资源需求的三个主要工作负载:“各种各样的计算需求鼓励了异构计算。 英特尔企业与政府部门副总裁兼总经理Rajeeb Hazra
说 。 -通用解决方案在这里不再适用。 在这个融合的时代,您应该研究针对不同类型的工作负载的不同需求而调整的体系结构。”
数据中心GPU

Ponte Vecchio是新X
e架构上的第一个GPU。 该架构本身将成为各个领域中GPU的基础:
- 高性能计算;
- 深度学习
- 云计算
- 图形;
- 媒体转码;
- 工作站
- 游戏计算机;
- 普通台式电脑;
- 移动和超移动设备。

英特尔架构,图形和软件副总裁Ari Rauch表示,一个GPU架构将为开发人员提供“通用结构”,但作为该架构的一部分,该公司正在开发“许多微架构,它们为每个架构提供最高效的性能。这些工作量。”
Ponte Vecchio GPU基于专门用于HPC和AI的X
e微体系结构,并且微体系结构功能包括具有矢量矩阵的灵活并行矩阵引擎,双精度浮点计算(FP64)的高吞吐量以及超高速缓存和内存的吞吐量。 对于INT8,Bfloat16和FP32格式,将有一个单独的矩阵引擎,用于矩阵的并行处理(可能是TensorCore的模拟),而对于FP64,每个计算单元的加速将高达40倍。
“这种工作量需要很高的计算性能,因此我们专注于添加大量针对此工作量进行了调整和优化的矢量和矩阵模块以及并行计算,” Rauch说。
Ponte Vecchio将成为新一代的第一个GPU。 它采用了英特尔近年来开发的几种新技术:
- 生产工艺7纳米;
- Foveros 3D集成电路的分层布局;
- EMIB(嵌入式多管芯互连桥),用于在一个基板上连接多个晶体;
- 新的CXL互连标准(基于PCI Express 5.0)上的X e Link-通过单个内存空间访问GPU。

 英特尔2018年12月演示文稿中的分层Foveros 3D集成电路
英特尔2018年12月演示文稿中的分层Foveros 3D集成电路该芯片的技术规格尚未公布。 他们说,在这些GPU中,将有成千上万个通过XEMF(XE内存结构)与内存和缓存连接的执行单元。

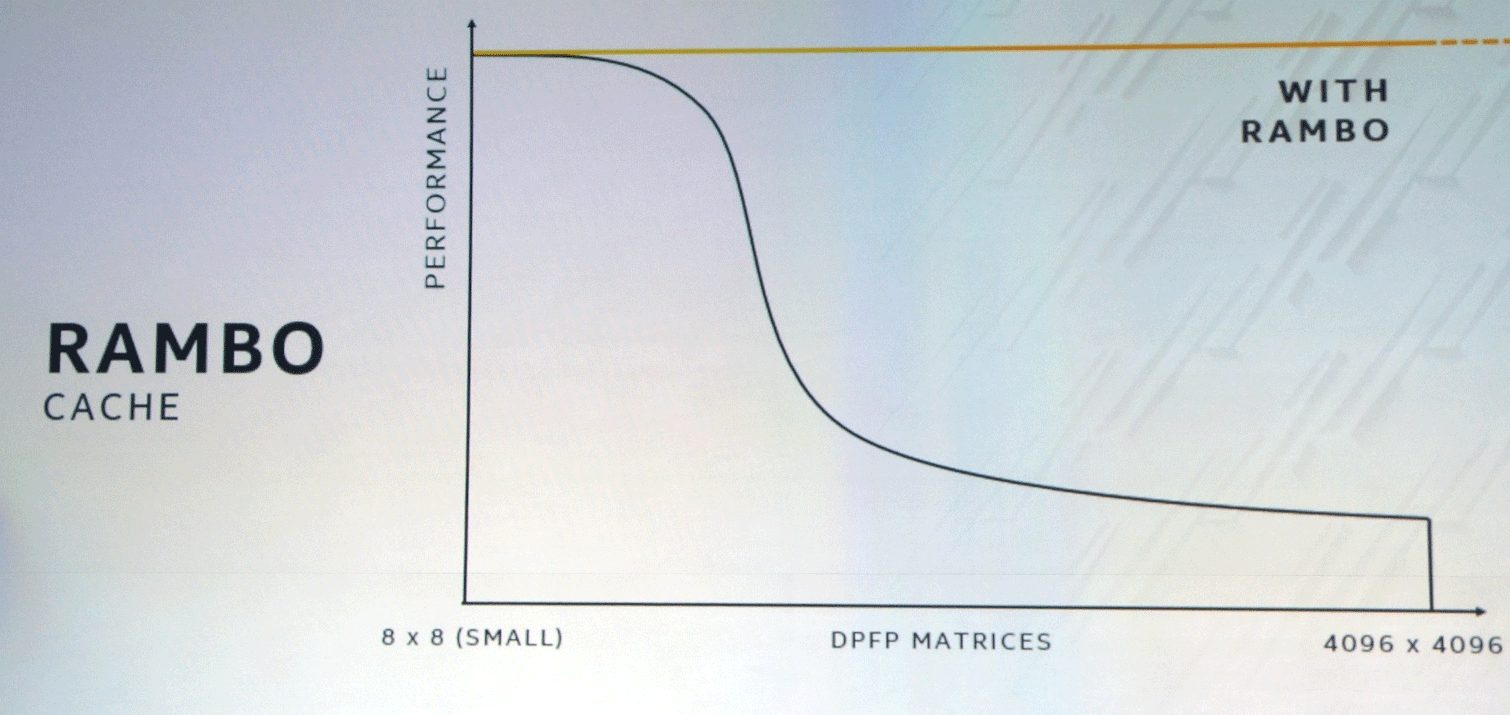
XEMF总线与特殊的超快速Rambo Cache高速缓存一起使用,可以消除内存访问的瓶颈。 此缓存通过Foveros连接到计算单元,并且EMIB将用于连接HBM内存。
分别针对GPU和CPU的SIMT和SIMD方法的组合以及可变长度矢量指令将在某些类型的问题中显着提高性能。

许多人期望英特尔在数据中心和AI市场上与Nvidia和AMD竞争。 这不仅与价格竞争有关,而且与替代技术平台的出现有关,这将刺激总体技术进步。
OneAPI:异构铁的抽象顶点
除了宣布新设备外,英特尔还发布了统一软件接口oneAPI的Beta版。 它们旨在促进开发人员的工作,这些开发人员为了最大程度地优化其程序,传统上不得不使用中间件和框架在不同的编程语言和库之间进行切换。
默认情况下,业界公认,在较低级别上,需要为每种体系结构准备不同的代码。 例如,TensorFlow在发布时最初针对一家供应商的GPU(针对Nvidia CUDA)进行了完全优化。
英特尔架构,图形和软件部门副总裁比尔·萨维奇(Bill Savage)表示:“ OneAPI试图通过为性能卓越的异构硬件提供通用的低级接口来解决这些问题。 “以便开发人员可以通过不同体系结构和供应商通用的语言和库在硬件上直接编写程序,并确保中间件和框架可以在oneAPI上运行,并且为处于此抽象顶层的开发人员进行了充分优化。”
英特尔将oneAPI称为“社区和行业支持的开放标准”,它将允许“跨不同制造商的架构和硬件重用代码”。
oneAPI规范将包括基于C ++和SYCL的标准跨体系结构DPC ++编程语言,以及“加速关键领域特定功能的强大API”。
除了DPC ++编译器和API库之外,还将发布特殊工具,包括VTune Inspector Advisor,调试器和用于将CUDA(Nvidia)代码移植到DPC ++的“兼容性工具”。
为了促进向oneAPI的过渡,英特尔在
DevCloud中启动了一个沙箱,以在许多CPU,GPU和FPGA上开发和测试程序。 使用沙盒不需要安装任何硬件或软件。
同时,英伟达第一季度的收入
增长到了30亿美元 ,而在数据中心市场上,这三个月的增长是11%(7.26亿美元)。 V100和T4处理器的销售量打破了所有记录。 英特尔仍在从外部进行研究,但是我们已经知道答案是什么。 最有趣的才刚刚开始。