
我们周围的世界充满了大脑不断处理的各种信息。 他通过感官接收该信息,每种感官均负责其信号份额:眼睛(视觉),舌头(味觉),鼻子(气味),皮肤(触觉),前庭装置(平衡,空间位置和重量感)以及耳朵(声音)。 通过汇总所有这些器官的信号,我们的大脑可以建立环境的准确图片。 但是,我们并不了解外部信号处理的所有方面。 这些秘密之一是声源的定位机制。
来自言语和听力神经工程实验室(新泽西理工学院)的科学家们提出了声音定位神经过程的新模型。 在感知声音的过程中,大脑中到底发生了什么过程,我们的大脑如何理解声源的位置,以及这项研究如何帮助抗击听力缺陷。 我们从研究小组的报告中了解到这一点。 走吧
学习基础
我们的大脑从感觉中获得的信息在来源和处理方面都互不相同。 一些信号以准确的信息形式立即出现在我们的大脑前,而另一些则需要其他计算过程。 粗略地说,我们会立即感觉到触摸,但是当我们听到声音时,我们仍然必须找到它的来源。
在水平面上定位声音的基础是到达听众耳朵的声音的双耳时间差(ITD与双耳
时间差之和 )。
耳间基* -耳朵之间的距离。
大脑中一定区域(中上橄榄或MBO)负责该过程。 在MBO中接收到声音信号的那一刻,听觉上的时间差异转换为神经元的反应速率。 作为ITD函数的MBO的输出速度曲线的形状类似于每个耳朵的输入信号的互相关函数的形状。
在MBO中处理和解释信息的方式仍然不十分清楚,这就是为什么存在几种非常矛盾的理论的原因。 声音定位的最著名且实际上是经典的理论是Jeffress模型(
Lloyd A. Jeffress )。 它基于对来自每个耳朵的神经输入信号的双耳同步敏感
的神经元检测器的
标记* ,并且每个神经元对特定的ITD值(
1A )最敏感。
标记线*的原理是一个假设,它解释了所有不同的神经(它们都使用相同的生理原理沿其轴突传递冲动)如何产生不同的感觉。 如果结构相似的神经与能够以各种方式解码相似神经信号的中枢神经系统中的独特神经元相关联,则它们会产生不同的感觉感知。
 图片编号1
图片编号1该模型在计算上类似于基于到达双耳的声音的无限互相关的神经编码。
还有一种模型,其中假定可以根据来自大脑不同半球的某些神经元群体的反应速度的差异来模拟声音的定位,即 半球不对称模型(
1B )。
到现在为止,很难明确地指出这两种理论(模型)中的哪一种是正确的,因为它们每个都预测了声音定位对声强的不同依赖性。
在我们今天正在考虑的研究中,科学家决定将这两种模型结合起来,以了解声音的感知是基于神经编码还是基于单个神经种群的响应差异。 进行了一些实验,其中年龄在18至27岁之间的人(5名女性和7名男性)参加了试验。 参与者的听力测验(听力敏锐度测量)在250至8000 Hz的频率下为25 dB或更高。 实验参与者被放在隔声室中,在隔声室中以高精度校准了专用设备。 与会者应在听到声音信号后指明其发出的方向。
研究成果
为了评估大脑活动的
侧向化*对标记的神经元作出反应的声音强度的依赖性,我们使用了关于仓脑的层状核心中神经元反应速率的数据。
侧向性* -身体左右两半的不对称性。
为了评估大脑活动的偏侧化对某些神经元种群反应率的依赖性,我们使用了恒河猴下部两脑的活动数据,然后另外计算了来自不同半球的神经元速度的差异。
神经元检测器标记线的模型表明,随着声音强度的降低,感知到的声源的侧向性将收敛于类似于安静声音和响亮声音之比(
1C )的平均值。
反过来,半球间不对称模型表明,随着声音强度降低到接近阈值,感知到的偏斜将向中线(
1D )移动。
在较高的总体声音强度下,可以假定,横向化强度不变(在
1C和
1D插入)。
因此,对声音强度如何影响声音的感知方向的分析使您可以准确地确定此时发生的过程的性质-来自一个公共区域的神经元或来自不同半球的神经元。
显然,一个人区分ITD的能力可能会随声音强度而变化。 但是,科学家们说,很难解释先前对ITD的敏感性以及听众对声源方向与声强的函数关系的评估。 一些研究说,当声强达到边界阈值时,感知到的声源的横向性会降低。 其他研究表明,强度对感知完全没有影响。
换句话说,科学家“轻轻地”暗示,文献中没有关于ITD,声强和确定其来源方向的信息。 存在着作为科学界普遍接受的一种公理而存在的理论。 因此,决定在实践中详细测试所有理论,模型和听力感知的可能机制。
第一个实验是使用心理物理范式进行的,它使我们能够在实验的十名正常听觉参与者中研究基于ITD的侧向化与声音强度的关系。
 图片编号2
图片编号2声源经过专门调整,可以覆盖人们能够识别ITD的大部分频率范围,即 300至1200 Hz(
2A )。
在每项测试中,听众必须指出在375到375毫秒的ITD值范围内,根据感觉水平测得的期望的横向性。 为了确定声强的影响,使用了非线性混合效应模型(NMLE),其中包括固定声强和随机声强。
图
2B示出了对于代表性的听众在两个声音强度下具有频谱平坦的噪声的估计的偏侧化。 曲线图
2C示出了原始数据(圆圈)并且针对所有收听者定制了NMLE模型(线条)。
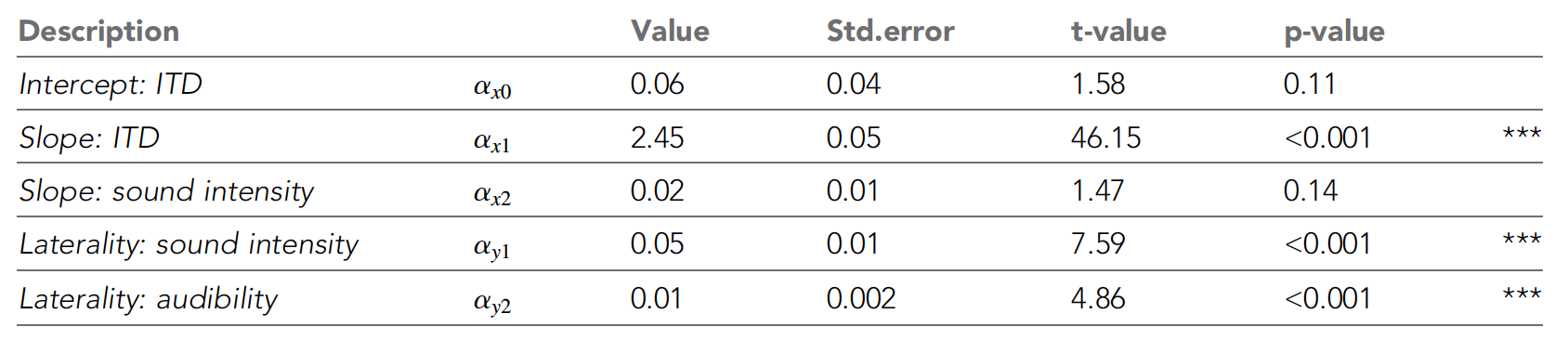 表号1
表号1上表显示了所有NLME参数。 可以看出,正如科学家所期望的,随着ITD的增加,可感知的横向性也随之增加。 随着声音强度的降低,知觉越来越向中线移动(插入
2C图)。
NLME模型强化了这些趋势,该模型显示了ITD和声音强度对最大横向度的显着影响,证实了半球间差异模型。
此外,纯音的平均听力阈值对感觉到的侧向性影响可忽略不计。 但是声音强度并没有显着影响心理测量功能的性能。
第二个实验的主要目的是确定在考虑刺激(声音)的频谱特征后,在先前实验中获得的结果如何变化。 在低声音强度下测试频谱平坦的噪声的需求是可能听不到频谱的某些部分,这可能会影响声音方向的确定。 因此,频谱的可听部分的宽度可以随着声音强度的减小而减小的事实可能被误认为是第一个实验的结果。
因此,决定进行另一个实验,但已经使用了反向
A加权*噪声。
A加权*应用于声音级别,以考虑人耳感知到的相对响度,因为耳朵对低频声音不太敏感。 A加权是通过将八度频段中列出的值表与以dB为单位的测得声压级进行算术运算而实现的。
2D图形显示了针对所有实验参与者针对NMLE模型定制的原始数据(圆圈)和数据(线)。
数据分析表明,当声音的所有部分都大致相等时(在第一个和第二个实验中),说明ITD的侧向性变化的曲线图上感知到的侧向性和倾斜度会随着声音强度的降低而降低。
因此,第二个实验的结果证实了第一个实验的结果。 就是说,实际上证明了Jeffress在1948年提出的模型是不正确的。
事实证明,声音的局部性会随着声音强度的降低而恶化,并且Jeffress认为,无论声音的强度如何,人都能平等地感知和处理声音。
要更详尽地了解这项研究的细微差别,建议您研究一下
科学家的
报告 。
结语
理论假设和实践实验证实了它们的存在,表明哺乳动物脑神经元根据声音信号的方向以不同的速度被激活。 之后,大脑会比较参与该过程的所有神经元之间的速度,以动态映射声音环境。
Jeffresson模型实际上并不是100%错误的,因为它可以用来完美描述声源在仓中的位置。 是的,对于bar,声音的强度并不重要,它们将在任何情况下决定其声源的位置。 但是,如先前实验所示,此模型不适用于恒河猴。 因此,这种Jeffresson模型无法描述所有生物的声音定位。
与人的实验再次证实,声音的定位发生在不同生物体中的方式不同。 由于声音强度低,许多参与者无法正确确定声音信号源的位置。
科学家认为,他们的工作在我们的观察方式和听觉方式之间显示出一定的相似性。 这两个过程都与大脑不同部位的神经元速度有关,并与对这种差异的评估有关,以确定我们在太空中看到的物体的位置以及我们听到的声音的来源的位置。
将来,研究人员将进行一系列实验,以更仔细地检查人类听觉与视觉之间的关系,这将有助于我们更好地了解我们的大脑如何动态地构建周围世界的地图。
谢谢大家的关注,保持好奇心,祝大家工作愉快! :)
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或向您的朋友推荐来支持我们
,开发人员的云VPS从4.99美元起 ,
为Habr用户提供
30%的折扣,这是我们为您发明的入门级服务器的独特模拟: 关于VPS(KVM)E5-2650 v4的全部真相(6核心)10GB DDR4 240GB SSD 1Gbps from $ 20或如何共享服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
戴尔R730xd便宜2倍? 只有我们有
2台Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100电视在荷兰起价199美元 ! 戴尔R420-2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB-$ 99起! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?