
在作为开放创新的一部分在斯科尔科沃举行的RAIF 2019论坛上,我谈到了如何实施机器学习模型。 结合行业的特点,我每周花几天时间在生产中,介绍机器学习模型,其余时间开发这些模型。 这篇文章是一份报告的录音,我试图总结自己的经验。
我们从大笔画开始描述过程,然后逐步进入每个阶段的细节。
无论我们是指基于全面调查的结果(理想情况下)来优化生产,还是只是收集想法(“拼布优化”),其结果都以某种方式
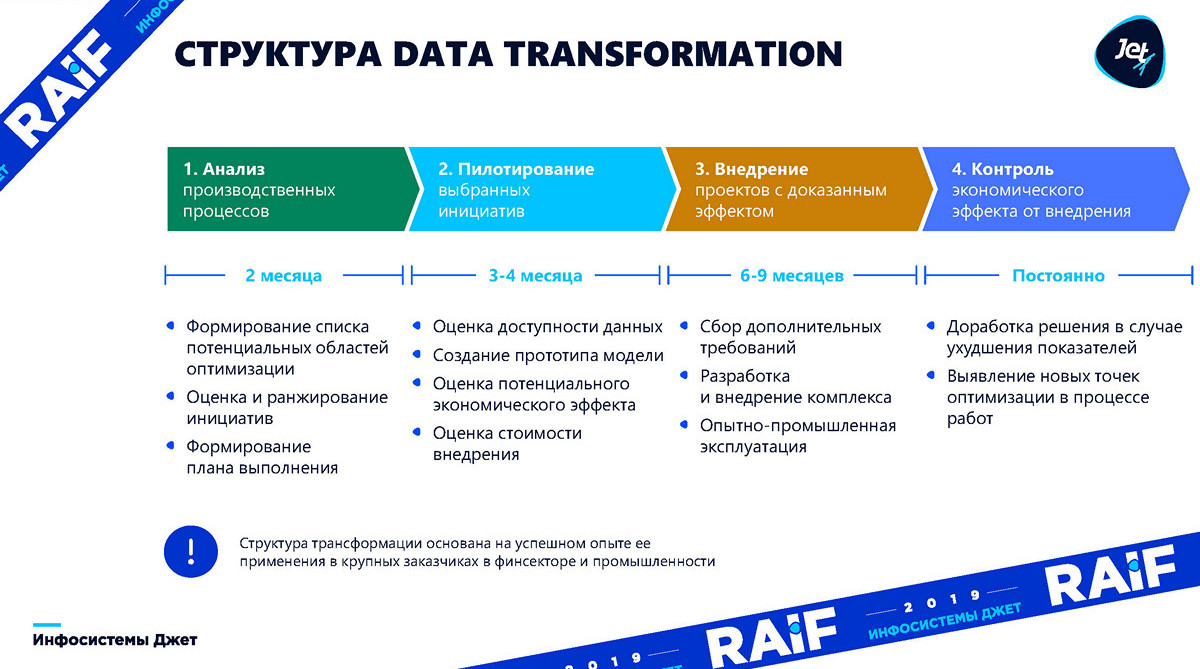
形成了一系列举措 。 有必要了解我们将优化哪些生产领域。 此过程通常需要两个月左右的时间。
然后我们进入
试点阶段,这将需要三到四个月的时间-我们必须建立一个基本模型,并了解机器学习是否适用于它,以及它可以给企业带来什么好处。
下一阶段的时间更长,没有太多的机器学习知识-
实施是在您需要集成,构建当前系统并开始获得我们在第二阶段中预测的丰厚收益时。 实施通常需要六个月到九个月。
控制阶段完成该过程。 制作模型并进行展示是一回事,而维持模型一段时间则是另一回事。 生产在变化,机床正在更换。 在这种情况下,模型必须不断“加速”并寻找新的优化机会。
现在按顺序更详细地:
寻找假设
假设来自何处? 谁来提名她?
通常,向IT部门提出假设是很常见的,但是可以配置系统的人员在那里工作,了解集成并且对机器学习一无所知。 此外,他们不太了解生产。 他们没有能力在实践中了解机器学习的工作原理。
第二个尝试是去生产假设。 确实,接近生产的专家知道该过程的技术特征,但是...不了解机器学习。 因此,他们不能说它在哪里适用,在哪里不适用。
在这种情况下,假设从何而来? 为此,他们提出了一个特殊职位-首席数字转型官。 这是从事数字化转型的人。 或首席约会官-知道数据及其应用方式的人。 如果这两个人不在公司,则假设应来自高层管理人员。 即,完全了解业务并从事现代技术的专家。
如果企业既没有首席数字转型官,也没有首席数据官,并且高层管理人员无法产生假设,那么……竞争对手将出手相救。 如果他们实施了某些措施,那么就不能从他们身上夺走这些东西。 但是,连接到该项目的集成商公司可以告诉您如何进行优化以及如何进行优化。

如何选择一个主意?
这里有四个重要因素:
- 要优化的流程周转率。
- 过程中的重大偏差。 有一种六西格玛方法,该方法建议所有过程与其结果的偏差应不超过六个标准偏差。 如果您有更多这些偏差,则需要解析它们,机器学习将有所帮助。
- 可用性和数据可用性。 例如,如果您在12个月后从传感器接收到有关设备运行的数据,那么您将不会实施机器学习。
- 在此过程中实施数字化的复杂性。 与可节省的成本相比,引入模型的成本。
有什么数据?
数据的结构为:
结构化:一些表,读数-一切都很简单。 当我们要使用来自社交网络或照片集的数据时,我们必须处理非结构化数据。 必须指出,此类数据也必须进行结构化,从而变成机器学习可以感知的数字。 第三类数据是线程化的。 如果我们处理每毫秒变化的数据,我们需要立即考虑负载平衡:我们的系统可以承受接收速度吗?

按来源将数据分为:
自动化-传感器生成某种数字,我们信不信由你。 但是它们大致相同。 手动输入-在这里您需要了解可能存在与人为因素有关的错误。 该模型必须对此有所抵抗。 外部数据-如果实施与金融交易有关,也许我们会对汇率感兴趣,而如果预测温度热交换,则可能对天气预报感兴趣。 静态数据是可以重用的。

资料问题
- 完整性-可以跳过某些数据/月份的时刻。
- 更改错误-例如,如果您的传感器有5毫秒的错误,则模型的精度为2毫秒-您将无法执行更改,因为输入数据开始发散。
- 在线可访问性-如果您想“立即”进行预测,则必须准备好数据。
- 存储时间-如果要使用年度趋势,并且需要预测需求,并且数据仅存储六个月,则不会构建模型。
处理数据
听专业人士,但只相信数据。 您需要去车间,与专业人员交谈,去工厂,与操作员交谈,了解他们的业务。 但是只相信数据。 当运营商说不可能做到这一点时,有很多例子-我们展示了数据-事实证明这确实在发生。 一个有趣的例子:一旦模型表明星期几会影响生产。 星期一-一个系数,星期五-另一个系数。
这种效果只有在战斗中才能理解-快速成型非常重要。 最重要的是快速了解模型在日常生活中的工作方式。 在演示文稿和本地笔记本电脑上,该项目看起来可能与实际情况完全不同:通常,实际上首先出现完全不同的问题。
只有解释的模型才有改进的机会。 您始终需要清楚地了解模型为何以这种方式做出决定,而不是其他方式。
使用指标
实际上,准确性对利润的依赖可以是任何。 在我们了解这种准确性如何影响效果之前,准确性问题完全没有意义。 您始终需要转化为利润。 下图显示了利润可以根据模型的准确性而变化。 第一张图说明了提前准确确定模型的精确度足以满足利润增长的困难:
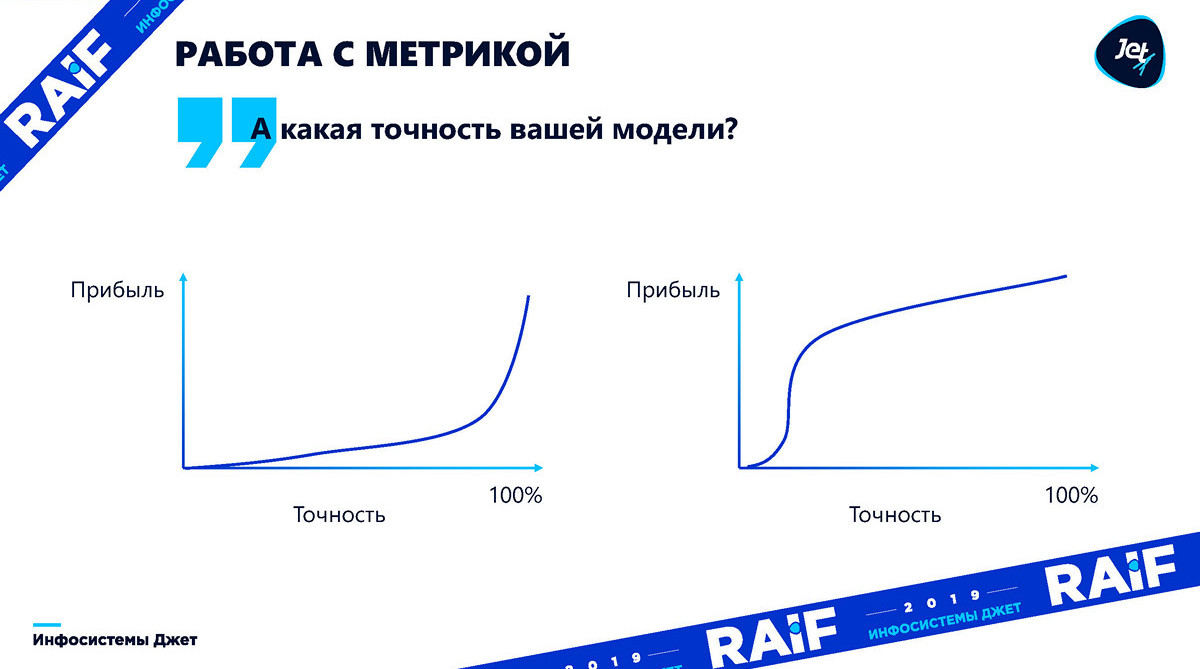
此外,在某些情况下,模型的准确性不足,这只会带来损失:

集成要点:
- 集成比模型开发花费更多的时间。
- 新想法。 有时,事实证明该项目在预期之外的地方受益。
- 培训。 人的适应能力比铁快。
数据专家通常会忘记的另一点是引入模型的目标:预测或推荐。 通常,建议基于预测模型,但是在这种情况下,应该特别构建预测模型,因为要找到具有突然不愉快影响的最小黑匣子是非常困难的。 如果我们谈论性能指标,则取决于实现的目的:
- 发布预测,-评估应用知识的结果;
- 提供建议-评估与旧流程的比较。
实施阶段的重要差异:
实施/培训
- 统计素养-当本地员工开始使用正确的统计术语进行操作时,实施会更加成功。
- 各种结构单元的动机-每个人都应该了解为什么会这样,而不要害怕改变。
- 组织变更-至少一名员工将查看模型的结果,这意味着他们将更改其流程方法。 事实证明,人们并没有为此做好准备。
技术支持
不要忘记条件在变化,模型必须不断地“扭曲”并寻找新的优化机会。 这里很重要:
- 管理模型和对预测做出反应的策略有些自我宣传:我们在Jet Infosystems对此进行了很多思考,并开发了自己的JET GALATEA系统。
- 人为因素-模型的主要问题通常与模型无法预见的使用或人为干预相关。
- 与来自该领域的专业人员进行定期的工作分析-不可能将所有事情减少到一个数目,这将表明需要改进的地方,有必要分析每个可疑的预测或建议。 准备学习另一种与工作场所的技术人员和设备操作员说相同语言的专业。

由Jet Infosystems机器学习小组负责人Nikolay Knyazev发表