 CS-1计算机图显示,大多数计算机专用于为巨型“板载处理器”晶圆级引擎(WSE)供电和冷却。 照片:Cerebras系统
CS-1计算机图显示,大多数计算机专用于为巨型“板载处理器”晶圆级引擎(WSE)供电和冷却。 照片:Cerebras系统在2019年8月,Cerebras Systems及其制造合作伙伴台积电宣布了
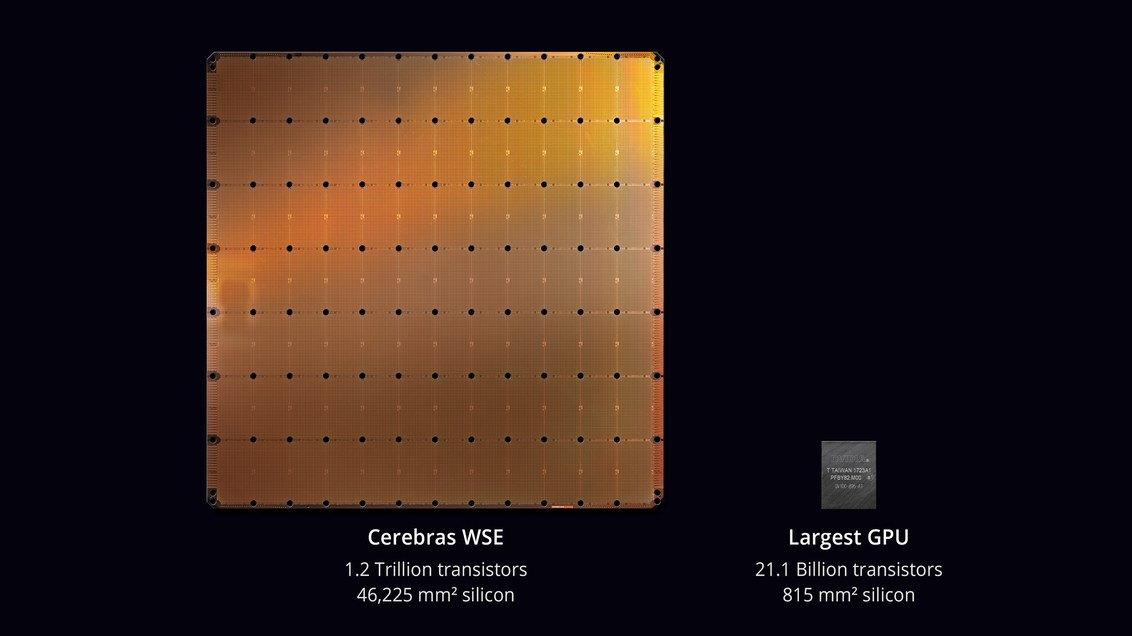
计算机技术史上最大的芯片 。 晶圆级引擎(WSE)芯片的面积为46,225mm²,晶体管为1.2万亿个,约为最大GPU(211亿个晶体管,815mm²)的56.7倍。
怀疑论者说,开发处理器并不是最困难的任务。 但是,这将在实际计算机中如何工作? 有缺陷的工作所占的百分比是多少? 需要什么电源和散热? 这样的机器要花多少钱?
看来Cerebras Systems和TSMC的工程师能够解决这些问题。 在2019年11月18日的
Supercomputing 2019大会上,他们正式发布了
CS-1 ,“
CS-1 ”是“机器学习和人工智能领域用于计算的世界上最快的计算机”。
CS-1的第一份副本已发送给客户。 其中一台安装在美国能源部的阿贡国家实验室中,其中一台将开始
使用新的Intel GPU架构,从
Aurora模块组装美国最强大的超级计算机。 另一个客户是利弗莫尔国家实验室。
具有400,000核的处理器是为数据中心设计的,用于在机器学习和人工智能领域中处理计算。 Cerebras声称,计算机比现有设备更有效地训练AI系统几个数量级。 性能CS-1相当于消耗数百千瓦的“数百个基于GPU的服务器”。 同时,它仅占用服务器机架中的15个单元,消耗约17 kW功率。
 WSE处理器。 照片:Cerebras系统
WSE处理器。 照片:Cerebras系统Cerebras Systems的首席执行官兼联合创始人安德鲁·费尔德曼(Andrew Feldman)表示,CS-1是“世界上最快的AI计算机”。 他将其与Google的TPU集群进行了比较,并指出,每个集群“占用10个机架,消耗的功率超过100千瓦,才能提供单个CS-1安装的三分之一的性能。”
 计算机CS-1。 照片:Cerebras系统
计算机CS-1。 照片:Cerebras系统在标准计算机上,学习大型神经网络可能需要数周时间。 IEEE Spectrum
写道 ,安装带有400,000个内核和1.2万亿个晶体管的处理器芯片的CS-1可以在几分钟甚至几秒钟内完成此任务。 但是,Cerebras并未提供真实的测试结果来测试
MLPerf测试等高性能语句。 相反,该公司直接与潜在客户建立了联系-并允许在CS-1上训练自己的神经网络模型。
分析师说,这种方法并不罕见:“每个人都可以管理自己为自己的业务开发的模型,” Moor Insights&Strategies的人工智能分析师
Karl Freund说。 “这是唯一对客户重要的事情。”
许多公司都在为AI开发专用芯片,包括英特尔,高通等传统行业代表以及美国,英国和中国的多家初创公司。 Google已经开发出专门用于神经网络的芯片-张量处理器或TPU。 其他几家制造商也纷纷效仿。 人工智能系统在多线程模式下运行,瓶颈正在芯片之间移动数据:“连接芯片实际上会降低它们的速度并需要大量能量,”加利福尼亚大学洛杉矶分校教授Subramanian Iyer
解释说 。开发人工智能芯片。 设备制造商正在探索许多不同的选择。 一些正在尝试扩展进程间连接。
Cerebras创业公司成立于三年前,该公司获得了超过2亿美元的风险融资,并提出了一种新的方法。 这个想法是将所有数据保存在一块巨大的芯片上,从而加快计算速度。

考虑到其中的一些不起作用,将整个微电路板划分为40万个较小的部分(芯)。 该芯片具有绕缺陷区域布线的能力。 可编程内核SLAC(稀疏线性代数核)针对线性代数(即,向量空间中的计算)进行了优化。 该公司还开发了“稀疏收集”技术,以在稀疏工作负载(包含零)(例如深度学习)下提高计算性能。 向量空间中的向量和矩阵通常包含很多零元素(从50%到98%),因此在传统GPU上,大多数计算都是浪费的。 相反,SLAC内核会预先过滤空数据。
内核之间的通信由Swarm系统提供,吞吐量为每秒100皮比特。 硬件路由,延迟以纳秒为单位。
不称计算机的成本。 独立专家认为,实际价格取决于婚姻的百分比。 同样,还无法可靠地知道芯片的性能以及实际样本中有多少个内核可以运行。
软体类
Cerebras已经宣布了有关CS-1系统软件部分的一些细节。 该软件使用户能够使用标准框架(例如
PyTorch和
TensorFlow)创建自己的机器学习模型。 然后,系统将芯片上的400,000个内核和18 GB的SRAM内存分配给神经网络的各层,以便所有层在与相邻层几乎同时的同时完成其工作(优化任务)。 结果,信息被所有层无延迟地处理。 借助12端口100 Gb以太网I / O子系统,CS-1每秒可处理1.2 TB的数据。
源神经网络到优化的可执行表示形式(Cerebras Linear Algebra Intermediate Representation,CLAIR)的转换由Cerebras Graph Compiler(CGC)完成。 编译器为图的每个部分分配计算资源和内存,然后将它们与计算数组进行比较。 然后,根据板的内部结构(对于每个网络都是唯一的)来计算通信路径。
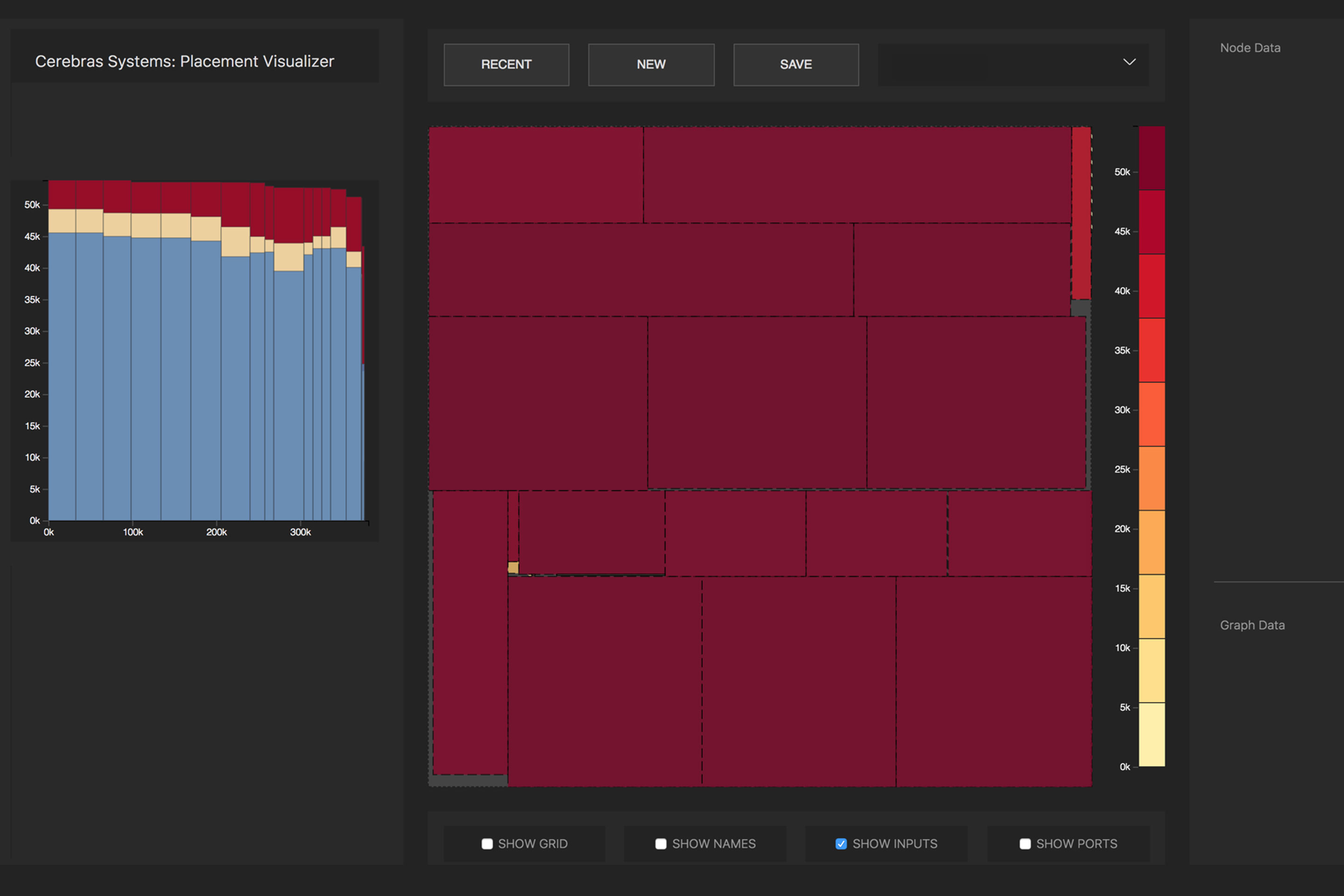 通过处理器内核分配神经网络的数学运算。 照片 :Cerebras
通过处理器内核分配神经网络的数学运算。 照片 :Cerebras由于WSE的巨大规模,神经网络中的所有层都同时位于其上并并行工作。 Cerebras说,这种方法是WSE独有的-没有其他设备拥有足够的内部存储器来一次将一个芯片上的所有层都容纳进去。 将整个神经网络放置在芯片上的这种架构由于其高吞吐量和低延迟而具有巨大的优势。
该软件可以为多台计算机执行优化任务,从而使计算机集群可以充当一台大型计算机。 由32台CS-1计算机组成的群集显示出大约32倍的性能提升,这表明它具有很好的可伸缩性。 费尔德曼说,这与基于GPU的集群不同:“如今,当您组成一个GPU集群时,它的行为不像一台大型计算机。 你有很多小型车。”
新闻稿说,阿贡国家实验室已经与Cerebras合作了两年:“通过部署CS-1,我们大大提高了神经网络的训练速度,这使我们能够提高研究效率并取得重大成功。”
CS-1的第一个载荷之一是
神经网络模拟黑洞和重力波
的碰撞 ,这是由于碰撞而产生的。 该任务的先前版本可在
Theta超级计算机的4392个节点中的1024个上使用。