 根据我在Highload ++和DataFest Minsk 2019上的表现
根据我在Highload ++和DataFest Minsk 2019上的表现对于许多人来说,今天的邮件是在线生活中不可或缺的一部分。 在它的帮助下,我们进行商务往来,存储与财务,酒店预订,结帐等有关的各种重要信息。 在2018年中,我们制定了邮件开发产品策略。 什么是现代邮件?
邮件必须是
智能的 ,也就是说,可以帮助用户浏览越来越多的信息:以最方便的方式过滤,组织和提供信息。 它应该
很有用 ,可以直接在邮箱中解决各种问题,例如,罚款(我不幸使用的一项功能)。 同时,当然,邮件应该通过切断垃圾邮件并防止黑客入侵来提供信息保护,即
安全 。
这些领域确定了许多关键任务,其中许多任务可以使用机器学习有效地解决。 以下是作为策略一部分开发的现有功能的示例-每个方向一个。
- 智能回复 。 邮件中有一个智能应答功能。 神经网络分析字母的文本,了解其含义和目的,从而提供三种最合适的答案选项:肯定,否定和中性。 这有助于显着节省接听信件时的时间,并且经常为自己做出非标准的响应和乐趣。
- 与在线商店中的订单相关的字母分组 。 我们通常在Internet上进行购买,通常,商店可以为每个订单发送多个字母。 例如,在最大的服务速卖通中,一个订单有很多字母,我们发现在终端的情况下,它们的数量可以达到29。因此,使用命名实体识别模型,我们从文本和组中选择订单号和其他信息一个线程中的所有字母。 我们还将在一个单独的框中显示有关订单的基本信息,从而简化了此类信件的工作。
- 防网络钓鱼 。 网络钓鱼是一种特别危险的欺诈性电子邮件,攻击者试图借助电子邮件来获取财务信息(包括用户银行卡)和登录。 这样的信件模仿了服务发送的真实信件,包括视觉上的信件。 因此,借助Computer Vision,我们可以识别大型公司(例如Mail.ru,Sberbank,Alpha)的徽标和字母样式,并将其与垃圾邮件和网络钓鱼分类器中的文本和其他符号一起考虑在内。
机器学习
一般来说,有关邮件中的机器学习的知识。 邮件是一个高负载的系统:在我们的服务器上,每天平均有15亿封信件传递给3000万DAU用户。 服务约30个机器学习系统的所有必要功能。
每个字母都经过整个分类输送机。 首先,我们切断垃圾邮件并留下良好的电子邮件。 用户通常不会注意到反垃圾邮件的操作,因为95-99%的垃圾邮件甚至都没有进入相应的文件夹。 垃圾邮件识别是我们系统中非常重要的部分,也是最困难的部分,因为在反垃圾邮件领域,防御和攻击系统之间存在不断的适应性变化,这给我们的团队带来了持续的工程挑战。
接下来,我们将字母与人和机器人分开。 人们的来信最为重要,因此我们为他们提供诸如智能回复之类的功能。 机器人发出的信件分为两个部分:交易-这些是来自服务的重要信件,例如,购买或酒店预订确认,财务和信息确认-这些是商业广告,折扣。
我们认为,交易信函的价值等同于个人信件。 他们应该在手边,因为经常需要快速找到有关订单或订票的信息,我们会花时间搜索这些字母。 因此,为方便起见,我们将它们自动分为六个主要类别:旅行,预订,财务,机票,登记,最后是罚款。
通讯是最大的,可能不太重要的组,不需要立即作出反应,因为如果用户不读这样的信,不会对用户的生活产生重大影响。 在我们的新界面中,我们将它们折叠成两个线程:社交网络和新闻通讯,从而从视觉上清理邮箱并仅留下重要的字母。

运作方式
大量的系统在操作中造成许多困难。 毕竟,模型会像任何软件一样随着时间的推移而退化:信号失效,机器故障,代码四处滚动。 另外,数据在不断变化:添加新数据,改变用户行为模式等,因此,没有适当支持的模型将随着时间的推移越来越差。
我们一定不要忘记,越深入的机器学习会渗透到用户的生活中,他们对生态系统的影响就越大,结果,市场参与者可以获得的财务损失或利润就越大。 因此,在越来越多的领域中,参与者正在适应ML算法的工作(经典示例包括广告,搜索和已经提到的反垃圾邮件)。
此外,机器学习任务具有特殊性:系统中的任何变化(尽管微不足道)都可能引起模型的大量工作:处理数据,重新培训,部署,这可能需要数周或数月的时间。 因此,模型运行的环境越快,其支持就需要付出更多的努力。 一个团队可以创建许多系统并享受其中的乐趣,然后将几乎所有资源都花费在他们的支持上,而又没有能力做新的事情。 我们曾经在反垃圾邮件小组中遇到过这种情况。 他们得出了显而易见的结论,即维护应该自动化。
自动化技术
什么可以自动化? 实际上,几乎所有东西。 我已经确定了定义机器学习基础架构的四个领域:
如果环境不稳定且不断变化,则模型周围的整个基础结构比模型本身重要得多。 它可能是很好的旧线性分类器,但是如果正确应用符号并获得用户的良好反馈,它将比带有所有花哨的最新模型更好地工作。
反馈回路
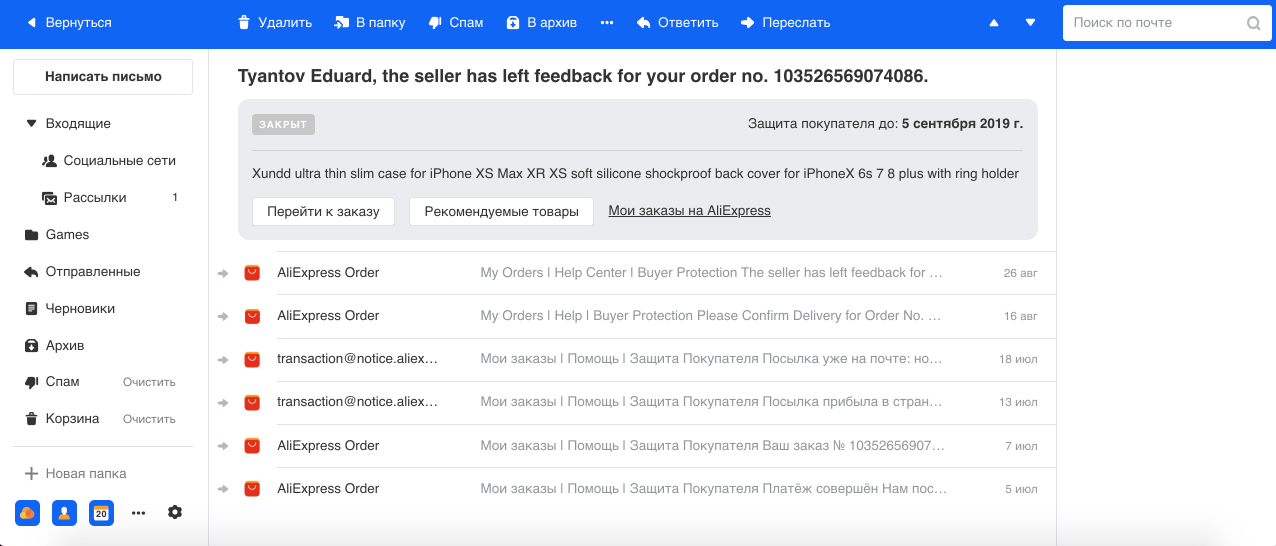
这个周期结合了数据收集,进一步的培训和部署-实际上是模型更新的整个周期。 为什么这很重要? 查看邮件中的注册时间表:

机器学习开发人员引入了一种反机器人模型,该模型可防止机器人在邮件中注册。 该图下降到仅保留真实用户的值。 一切都很棒! 但是四个小时过去了,僵尸们收紧了他们的脚本,一切都回到了平方。 在此实现中,开发人员花了一个月的时间来添加功能和培训模型,但垃圾邮件发送者能够在四个小时内适应。
为了避免如此痛苦,并且以后不必重做所有事情,我们必须首先考虑反馈循环的外观以及在环境变化时我们将如何做。 让我们从收集数据开始-这是我们算法的动力。
资料收集
显然,现代神经网络的数据越多越好,它们实际上会吸引产品的用户。 用户可以通过标记数据来帮助我们,但您不能滥用它,因为在某些时候,用户会厌倦于完成您的模型,而他们会切换到另一种产品。
最常见的错误之一(在此我参考了Andrew Ng)是测试数据集指标的定位过于强烈,而不是用户的反馈,这实际上是我们为用户创建产品时工作质量的主要衡量标准。 如果用户不理解或不喜欢模型的工作,那么一切都会变得很容易腐烂。
因此,用户应该始终能够投票,应该给他提供反馈的工具。 如果我们认为与财务相关的信件已到达框中,则需要将其标记为“财务”,并绘制一个按钮,用户可以单击该按钮并说这不是财务。
反馈质量
让我们谈谈用户反馈的质量。 首先,您和用户可以在一个概念中赋予不同的含义。 例如,您和产品经理认为“财务”是银行的来信,而用户则认为祖母关于退休的信也涉及财务。 其次,有些用户不加思索地喜欢无逻辑地按下按钮。 第三,用户可能会深深地误以为他们的结论。 我们的做法的一个生动例子就是引入了
尼日利亚垃圾邮件分类器,这是一种非常有趣的垃圾邮件类型,当用户被要求从非洲一个突然发现的远亲中收取几百万美元时。 引入此分类器后,我们选中了这些字母的“无垃圾邮件”点击,结果发现其中80%是多汁的尼日利亚垃圾邮件,这表明用户可以非常信任。
而且不要忘记,不仅人们可以拨动按钮,还可以装扮成浏览器的各种机器人。 因此,原始反馈不利于学习。 使用此信息可以做什么?
我们使用两种方法:
- 来自相关机器学习的反馈 。 例如,我们有一个在线反机器人系统,正如我提到的那样,它可以根据有限的标志快速做出决定。 还有第二个缓慢的系统可以事后使用。 她具有有关用户,其行为等的更多数据。 结果,分别做出最平衡的决策,它具有更高的准确性和完整性。 您可以首先将这些系统的工作差异作为培训数据。 因此,更简单的系统将始终尝试接近更复杂的性能。
- 点击的分类 。 您可以简单地对用户的每次点击进行分类,评估其有效性和使用能力。 我们在反垃圾邮件中使用用户的属性,用户的历史记录,发件人的属性,文本本身以及分类器的结果来执行此操作。 结果,我们得到了一个可以验证用户反馈的自动系统。 而且由于有必要减少培训的频率,因此它的工作可以成为所有其他系统的主要工作。 精度是此模型的主要优先事项,因为在不准确的数据上训练模型会带来很多后果。
在清理数据并重新训练机器学习系统时,我们不要忘记用户,因为对于我们来说,图上成千上万的错误是统计信息,对于用户而言,每个错误都是悲剧。 除了用户需要以某种方式忍受您在产品中的错误这一事实外,他在反馈后还希望将来不会出现类似情况。 因此,您不仅应始终为用户提供投票的机会,而且还应纠正ML系统的行为,例如对于每次单击反馈创建个人启发式方法(对于邮件而言),可以通过发件人和标头对此用户过滤此类消息。
您还需要根据一些报告或要求以半自动或手动模式获得支持的模型,从而使其他用户也不会遭受类似问题的困扰。
启发式学习
这些试探法和拐杖有两个问题。 首先是拐杖的数量不断增加,难以维护,更不用说它们的质量和远距离性能。 第二个问题是误差可能不是频率误差,而单击几下以重新训练模型是不够的。 如果采用以下方法,似乎可以将这两个不相关的影响大幅度提高。
- 创建一个临时拐杖。
- 我们将数据从其中引导到模型;它会定期进行检索,包括收到的数据。 当然,在这里重要的是启发式方法必须具有较高的准确性,以免降低训练集中数据的质量。
- 然后,我们挂断了拐杖的运行监控,如果一段时间后拐杖不再工作并且被模型完全覆盖,则可以安全地将其卸下。 现在这个问题不太可能再次发生。
因此拐杖大军非常有用。 最主要的是他们的服务是紧急的,不是永久的。
继续教育
再培训是添加由于用户或其他系统的反馈而获得的新数据并对其进行培训的过程。 再培训可能存在几个问题:
- 模型可能根本不支持继续教育,只能从头开始学习。
- 在自然书中没有写到继续教育肯定会提高生产中的工作质量。 通常情况恰好相反,也就是说,仅可能发生恶化。
- 变化可能是不可预测的。 这是我们为自己确定的一个相当微妙的观点。 即使A / B测试中的新模型与当前模型相比显示出相似的结果,也并不意味着它会完全相同。 他们的工作可能有百分之一的差异,这可能带来新的错误或返回已经纠正的旧错误。 我们和用户都已经知道如何忍受当前错误,并且当发生大量新错误时,用户可能也无法理解正在发生的事情,因为他期望可预期的行为。
因此,保证了再培训中最重要的事情是改进模型,或者至少不使其恶化。
当我们谈论继续教育时,想到的第一件事是主动学习方法。 这是什么意思? 例如,分类器确定字母是否与金融相关,并在其决策边界附近添加一系列标记示例。 例如,这在广告中效果很好,其中有很多反馈,您可以在线训练模型。 如果反馈很少,则相对于数据分布的产生,我们会得到一个有强烈偏见的样本,在此基础上,不可能评估操作期间模型的行为。
实际上,我们的目标是保留旧的模式,已知的模型并获取新的模型。 在这里,连续性很重要。 我们经常会非常困难地推出该模型,该模型已经可以使用,因此我们可以专注于其性能。
在邮件中,使用了不同的模型:树,线性,神经网络。 对于每个,我们都制定自己的再训练算法。 在重新训练的过程中,我们不仅获得新数据,而且经常获得新功能,这些新功能将在以下所有算法中予以考虑。
线性模型
假设我们有逻辑回归。 我们由以下部分组成损失模型:
- 新数据的LogLoss;
- 我们调整了新标志的权重(不触及旧标志);
- 我们从旧数据中学习,以保留旧模式;
- 也许,最重要的一点是:我们附加了谐波正则化功能,根据规范,该规则可确保权重相对于旧模型有所变化。
由于每个损耗分量都有系数,因此我们可以为我们的任务选择最佳值以进行交叉验证或基于产品要求。

树木
让我们继续到决策树。 我们拍摄了以下树再训练算法:
- 针叶上有100到300棵树木的树林,并在旧数据集上进行了训练。
- 最后,我们删除了M = 5件并添加了2M = 10个新件,它们在整个数据集上进行了训练,但是从新数据中获得的权重很高,这自然保证了模型的增量变化。
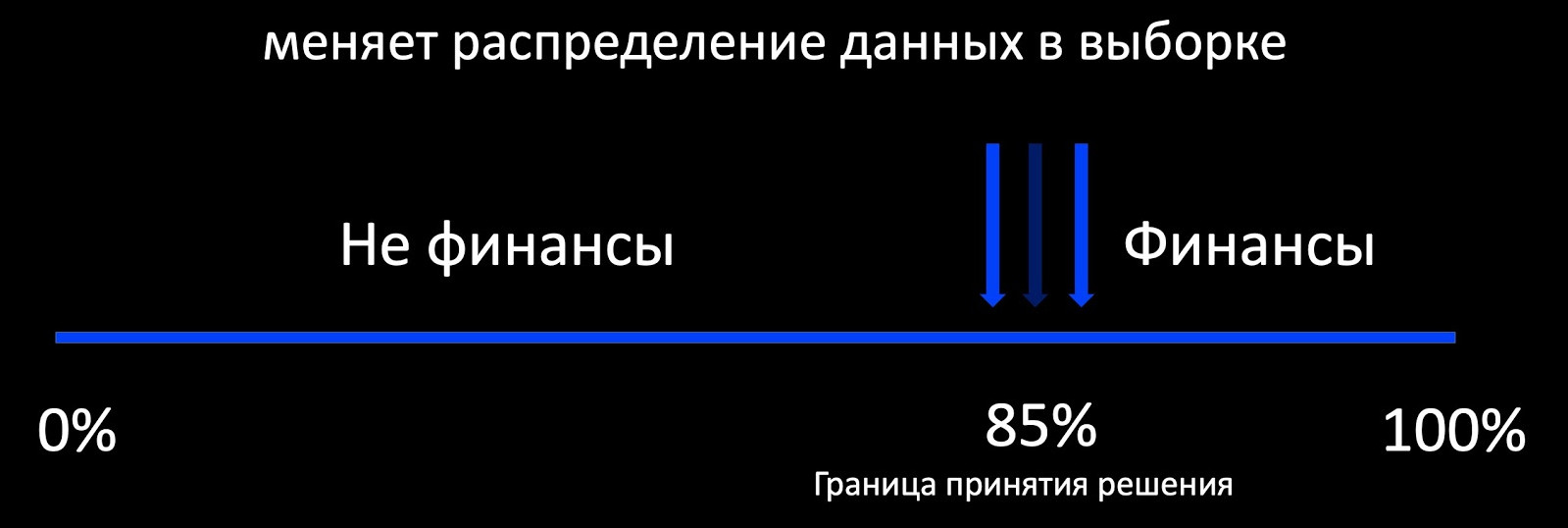
显然,随着时间的流逝,树木的数量显着增加,必须定期减少树木的数量以适应时机。 为此,我们使用了无处不在的知识蒸馏(KD)。 简要介绍其工作原理。
- 我们拥有当前的“复杂”模型。 我们从训练数据集开始,并在输出中获得各类的概率分布。
- 接下来,我们使用类的分布作为目标变量,教导学生模型(在这种情况下为具有较少树的模型)重复该模型的结果。
- 在此必须注意,我们不以任何方式使用数据集标记,因此可以使用任意数据。 当然,我们使用战斗流中的数据样本作为学生模型的训练样本。 因此,训练集使我们能够确保模型的准确性,并且流程样本保证了生产分布上的相似性能,从而补偿了训练样本的偏移。
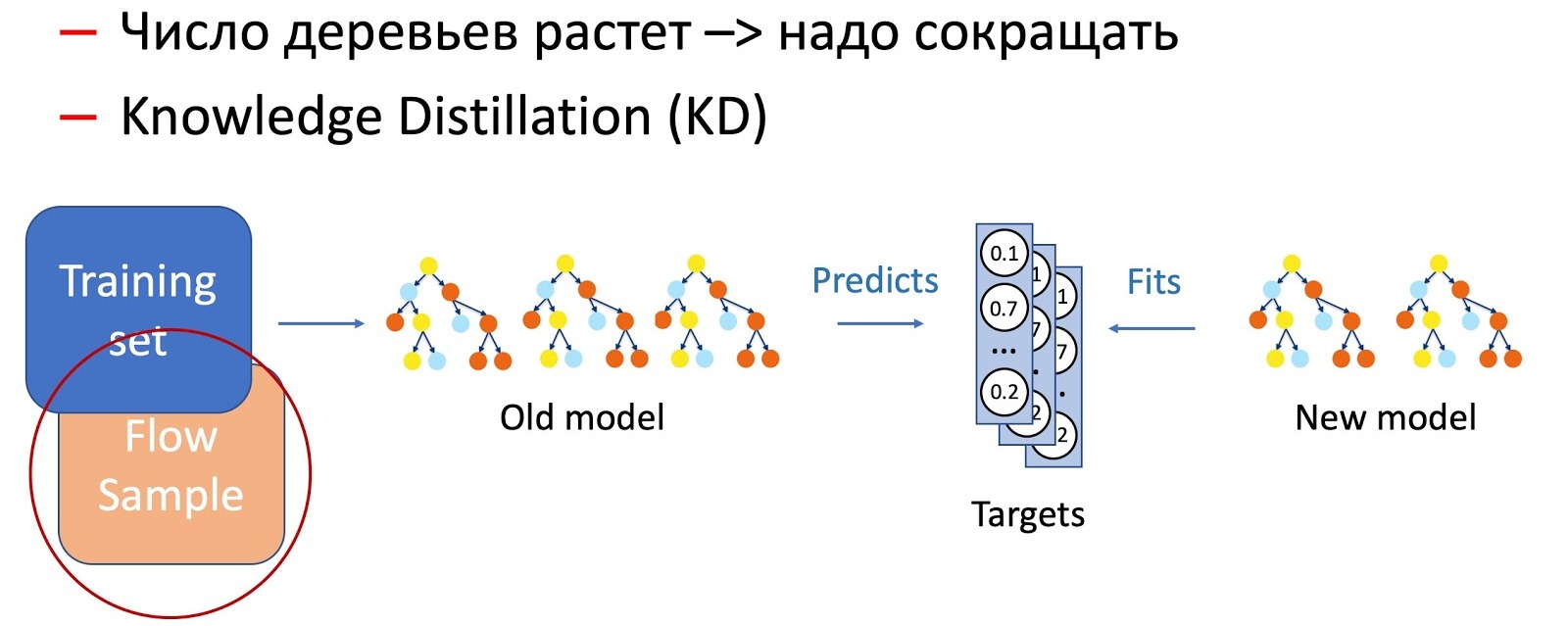
这两种技术的结合(使用知识蒸馏技术添加树并定期减少其数量)可确保引入新的模式并实现完全的连续性。
在KD的帮助下,我们还可以区分具有模型特征的操作,例如特征的去除和通过过程。 在我们的案例中,我们具有许多重要的统计功能(按发件人,文本哈希,URL等),这些功能存储在具有拒绝属性的数据库中。 当然,该模型尚未为此类事件发展做好准备,因为训练集中没有失败情况。 在这种情况下,我们将KD和扩充技术结合在一起:训练一部分数据时,我们将必要的符号删除或归零,然后将标签(当前模型的输出)作为初始符号,学生模型则教我们重复此分布。
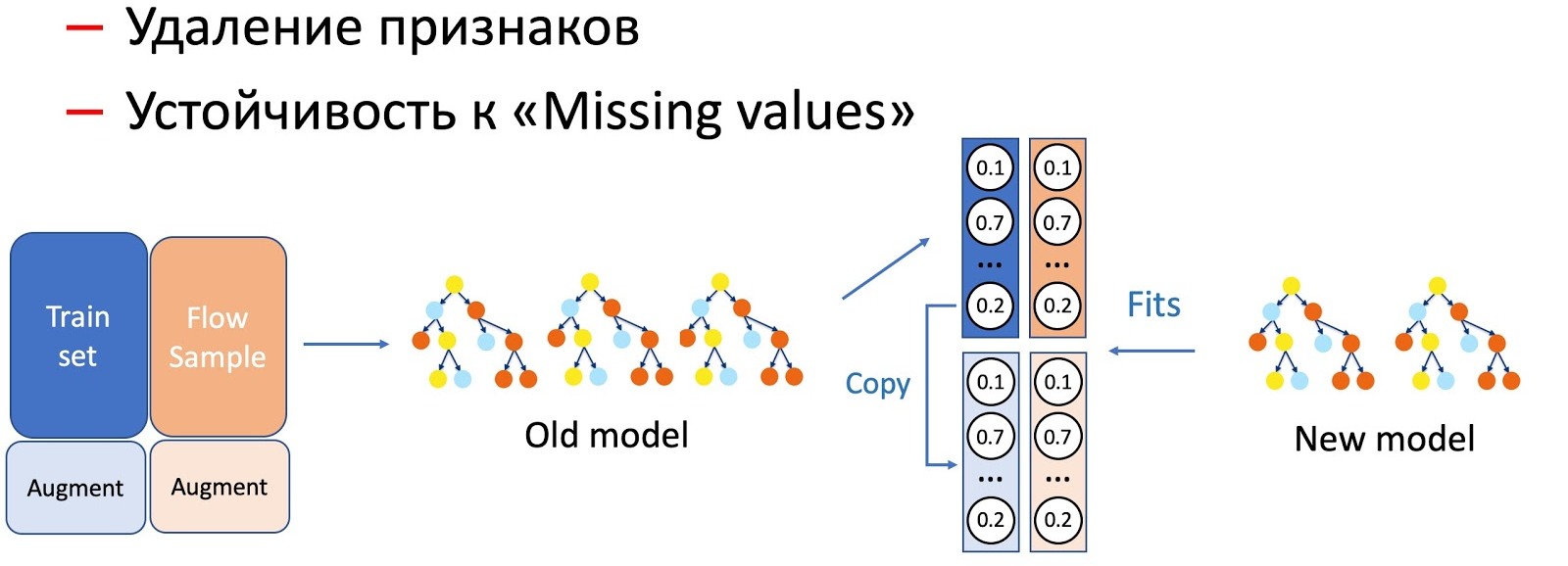
我们注意到,对模型的操纵越严格,所需的样品流量百分比就越大。
要删除特征(最简单的操作),只需要流程的一小部分,因为只有几个特征会发生变化,并且当前模型在同一组上进行研究-差异很小。 为了简化模型(将树的数量减少几倍),已经需要50到50个树,而忽略严重影响模型性能的重要统计特征,则需要更多的流程来使新模型的工作均匀化,从而可以抵抗所有字母的遗漏。
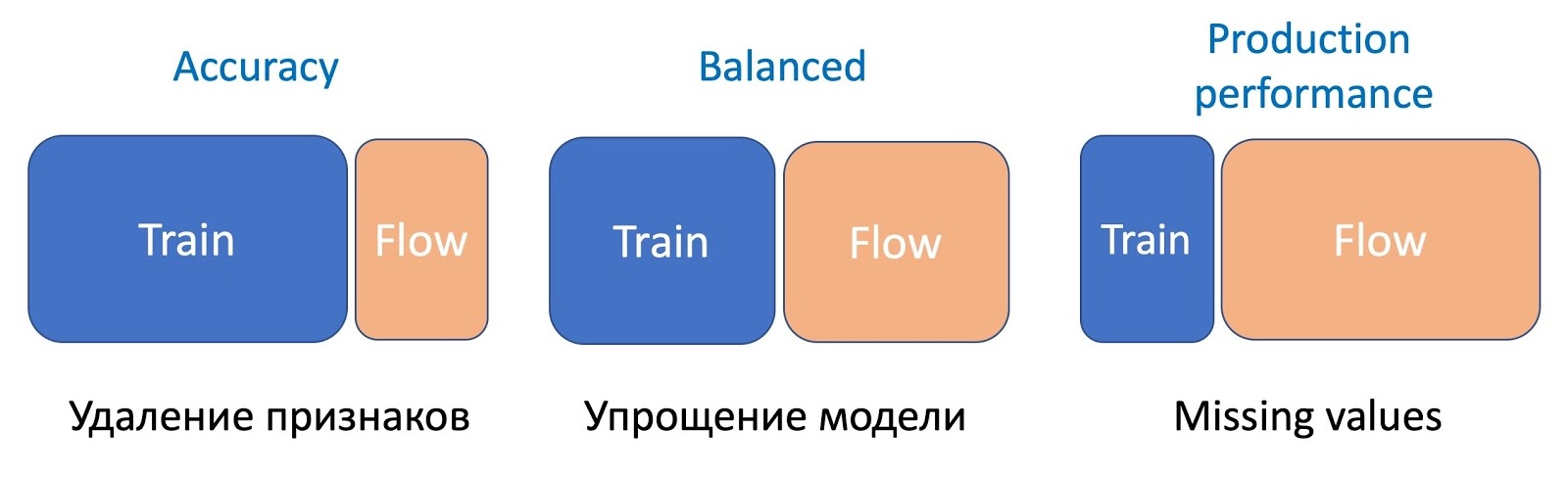
快速文字
让我们继续进行FastText。 让我提醒您,单词的表示形式(嵌入)由单词本身及其所有字母N-gram(通常为三字母)的嵌入之和组成。 由于三字组可能很多,因此使用“桶散列”,即将整个空间转换为某个固定的哈希图。 结果,权重矩阵是通过内层的尺寸乘以单词数+存储桶而获得的。
在继续教育期间,出现了新的征兆:单词和卦。 在Facebook进行的标准培训中,没有任何重大变化。 仅对新数据具有交叉熵的旧权重进行训练。 , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
部署
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
总结
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- . . , .
, , ML-, , .