多核处理器是司空见惯的。 早晚,任何实际的程序员都必须进入多线程编程的迷宫,并与居住在其中的“怪兽”见面。 让我们讨论从何处开始,以及哪些工具和方法将有助于取得胜利。 我向Yandex
全年实习的未来参与者做了此报告。
-我叫Seva Minkov。 我在搜索部门的云基础架构部门工作。 我主要处理后端。 我用不同的语言编写,但是最常见的是Java和Java虚拟机(JVM)上运行的语言。
我们的团队正在开发内部云,几乎所有的Yandex服务都将在其中启动,包括众所周知的Search,Mail和Alice,以及各种内部服务,虚拟机以及短暂的MapReduce任务和机器学习任务。
我们的云不是一成不变的:公司在发展,服务的数量和消耗的资源在增加。 而且我们的团队经常面临扩展和改进性能的挑战。 我们通过使用所有可用的工具(包括垂直缩放)来实现此目的,也就是说,通过加速系统的各个组件来重写某些单线程算法,以便它们更快地工作。 我们进行水平扩展:将系统粉碎成小块,以便通过添加服务器,处理器,内核等来获得更好的性能。
而多线程编程在这方面给了我们很多帮助。 今天我们将谈论他-它来自哪里,为什么相关; 什么是内存模型,以及它通常如何用Java表示。 我们将在一些实践方面涉及如何测试您的应用程序并验证其正确性。
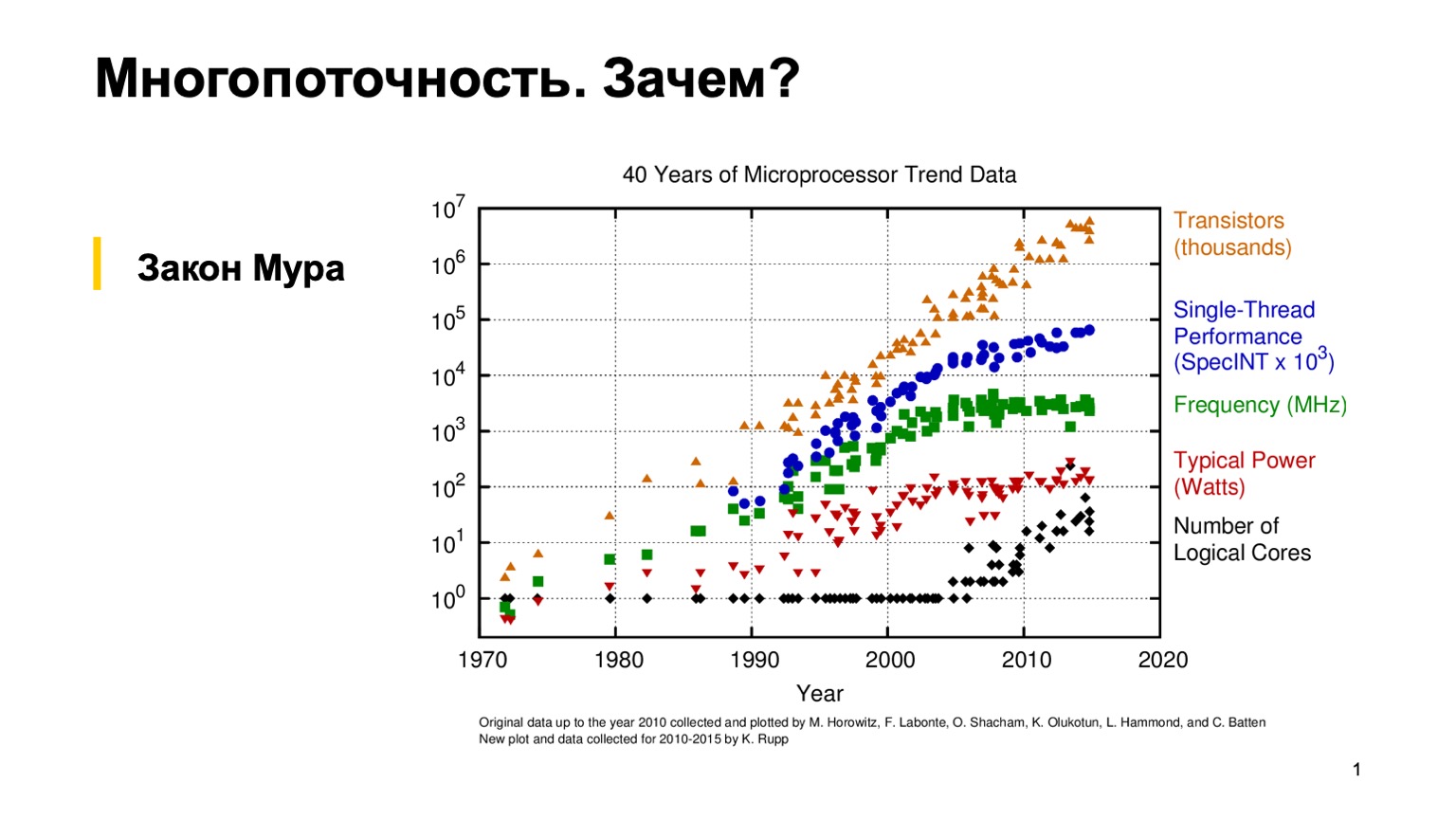
首先,让我们看一下这张有趣的图表,该图表显示了过去40年中微处理器特性的趋势。 大约10到15年前,当绿草如茵,处理器是单线程的时候,普通的程序员可以编写正确的单线程程序,然后依靠摩尔定律。 他说处理器的速度是每两年翻一番。 如您所见,由于各种原因,大约在2005年左右,微处理器制造商转向了多核体系结构,并开始增加逻辑核的数量。 而且,单核的性能提升不再遵循摩尔定律,而一个核的处理能力开始增长得更慢。 这是一场革命,普通程序员不得不使用并行编程来发挥这种性能提升。
由于我们正在练习,因此我们将尝试编写一个简单的多线程程序,并亲自了解其工作方式。
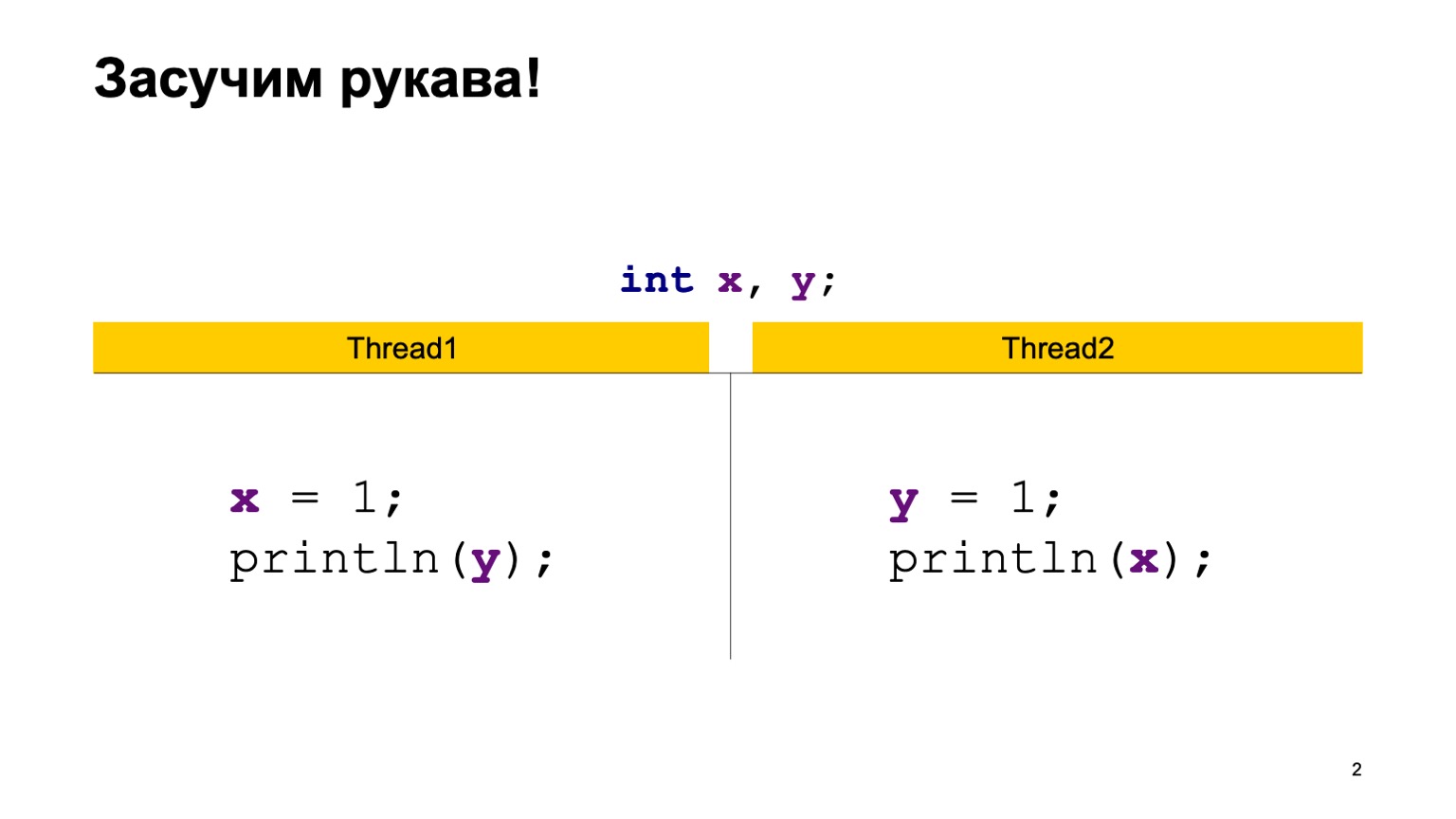
举个例子,让我们做一个交叉读取记录的相当简单的任务。 让我们有两个共享变量X和Y,以及两个流,它们首先用默认值(零)初始化。 每个线程都写入一个变量,然后读取另一个变量。 在这种情况下,线程1在X中写入一个单元并读取Y。第二个线程也这样做,只是向后。
一个简单的Java实现可能看起来像这样。

我们将编写ReadWriteTest类,它将有两个静态变量X和Y。直接在main方法中,我们构造了两个线程Thread1和Thread2,给它们每个输入一个lambda函数,这些函数将在线程执行时执行。 将上一张幻灯片中的代码放在此处,并启动两个线程。
从某种意义上说,线程启动的顺序是不可预测的。 这取决于操作系统的线程方式。 因此,我们可以有不同的版本。 似乎了解这一切是如何工作的,我们将不得不多次运行该程序,然后汇总输出并查看在该程序中发现此答案的频率。

为了不重新发明轮子,我们可以使用现成的工具。 这称为jcstress,这是Java Concurrency Stress测试实用程序,它是OpenJDK项目的一部分。
该实用程序提供了一些用于编写压力测试的框架。 在这种情况下,上一张幻灯片中的代码很容易被重写。 首先,我们将jcstress Test注释挂在类上,这仅使我们的测试脚本对实用程序可见。 我们还用State类对其进行标记,该类表示该类包含可以更改的数据:被修改并从不同流中读取。 我们声明两个方法,thread1和thread2,并用Actor注释对其进行标记。 Actor注释意味着该方法必须在单独的线程中执行。 jcstress保证每个这样的方法将在State类的一个实例上的单独线程中执行。 没有具体指定它们的启动顺序。 然后将结果写入幻灯片中显示的II_Result对象。 我们可以假定这是两个数值的元组,它们只是由依赖注入方法表示的,Cyril在上一份报告中谈到了。
在开始测试之前,让我们考虑一下命令可以给出的结论以及可以在r1和r2中添加的值。

为此,我们使用了所谓的交替模型。 每种操作(读或写)以一种或另一种方式以某种顺序执行。 只需综合考虑所有这些选项,然后看看我们将获得什么结果就足够了。

假设事件的可能变体之一是线程1在线程2之前完全执行。 首先,我们将X加1,从Y读取零,因为没有条目。 然后他们将一个写入Y并从X读取一个,因为第一个流已经设法做到这一点。
第一个答案是零。

事件发展的第二个变体恰好相反:第二个流在第一个流之前执行。

因此,我们得到的镜像结果为零。

当我们完全混淆线程的线程执行时,还有大约四个以上的选项可以提供相同的结果。 例如,我们在X的一个流中记录了一个单位,在第二个流中,在Y中记录了一个单位,然后计算了一个。 然后,您可以查看作为家庭练习的其他选项。

似乎我们已经遍历了所有可能的选择,仅此而已。 让我们运行该实用程序,看看它给出了什么结论。

输出看起来像一个表。 第一列列出了我们添加到II_Result中的结果-该实用程序将运行此代码数百万次-以及完全遇到特定结果的情况数。 但是,如果一切都这么简单,那么这份报告可能就不会了。
实际上,在这个结论中我们还可以看到零-零结果,这很难用交替模型来解释。 似乎可能的选择之一是直接在流代码中有人接过并重新排列了行。
让我们考虑一下为什么会发生这种情况以及我们如何忍受它。 我还请您注意一个事实,即在我的机器上很少发现一对一选项的情况。 在1.3亿场演出中,只有154场演出取得了一对一的结果。 相反,在几乎30%的情况下,零零非常经常发生。

因此,总结一下我们大家看到的一些中间结果。 首先,我们可以理解,流经内存的交互是不平凡的。 我们使用的旋转模型不起作用。 我们看到了一些重新安排。 可能由于多种原因而发生。
例如,我们可以看到铁的一些“相对论效应”。 可以这样看:在3 GHz处理器的一个时钟周期中,光在真空中传播约10厘米。读写处理器内存的协议很复杂,有时需要数百个时钟周期才能将值从一个内核转移到另一个内核。 因此,一个核心似乎可以看到过去。 记录发生后的结果,但是我们看到了旧值。 此外,处理器也不会停滞不前,可以在适当位置更改指令。
现代的优化编译器可以导致相同的排列。 为了获得最大的单线程性能,它们还可以交换指令,以免破坏单线程程序的正确性。 但是在多线程程序中可能会导致我们已经看到的有趣效果。
第二点-可能是主要结论:我们看到,基本上没有确定多线程程序。 单线程程序主要依赖于输入和输出的某些不变性,并且是确定性的。 假设随机数生成器和用户输入是输入参数。
这使事情变得非常复杂:难以理解程序的功能,也很难对其进行测试。
关于测试的复杂性,我们可以补充说,在1.3亿个呼叫中,仅发现154次相同的结果。 出现此结果的概率为百万分之一。 在生产中,这意味着可以在几周后重现这种错误。 当然,这肯定会发生在周日晚上的某个地方,那时您根本没有想到这一点。

让我们考虑一下应该怎样做,以及我们通常希望我们的舌头在周日晚上安静地入睡。 首先,我们需要一个工具,该工具可以预测程序的行为并判断其执行情况。 其次,我们需要允许我们影响排列和效果的语言工具-它们可以来自硬件,编译器等。我想对特定处理器的工作方式,编译器可以进行的优化以及使用缩写的了解较少来自Java世界。 一次编写,可在任何地方运行-一次编写正确的多线程代码,以便它可在所有平台上运行。

我们列出的这些问题和要求,已经在很长一段时间的开发人员以及理论家和实践者的脑海中浮现。 像任何具有高度复杂性的复杂任务一样,它是通过引入一些抽象机器的概念来解决的。 我们所有人都是高级编程语言的开发人员,他们不是为任何特定的硬件,不是为这样的处理器模型编写的,而是为某种抽象机器编写的。 语言的规范旨在以协调这三个世界的方式描述其行为。 一方面,让编译器和处理器的开发人员进行优化,并让我们已经用特定语言编写的程序员大吃一惊。
内存模型在此抽象机中占据中心位置。 她应该回答一个问题:如果我在某个流中读取了变量X,那么我根本看不到最后哪个条目的结果? 第一次尝试使用Java语言来规范化内存模型,后来出现了所有其他内存模型。 假设C ++ 11几乎是Java内存模型的复制粘贴,但有一些更改。
Java中有几种内存模型。 最初,这种所谓的“钟形”内存模型被认为是不成功的,因为它阻碍了用Java编写程序的程序员的工作,并禁止了一些对自己非常合适的编译器优化。 因此,作为社区流程JSR-133的一部分,编写了现代内存模型。
由于我们有规范形式的经文,因此让我们尝试对其进行研究,并了解其中真正发生的事情。

有问题。 举起手,谁打开了语言的规范,然后阅读那里发生的事情。 你们当中有多少人已经阅读了17.4段中的记忆模型? 一个小惊喜正等着您。 语言规范基本上是以一种相当容易理解的语言来描述的。 但是,内存模型充满了一些数学上的铁杆。 希腊文中有内含物,包括一系列可及闭式,两个阶的并集等许多数学术语。
不幸的是,没有其他办法。 编写多线程程序时唯一可以依靠的就是规范。 她将不得不阅读和理解。 我强烈推荐你。 而且,当我第一次阅读规范时,我对这种印象很深。
为什么这么复杂? 我走错了路,我非常警告你要像我一样行事。
我拿着它,在互联网上搜索了什么是内存模型。 找到一本名为《 JSR-133编译器食谱》的书。 她描述了编译器开发人员如何以简单的方式实现此内存模型。 问题在于这是一个特定的实现,一般来说,它不能用于判断整个内存模型。
无论如何,让我们尝试一些可以从Java内存模型理解的主要结论。

您的多线程程序可能执行很多。 我们自己之前在我们程序的示例中看到了这一点。 在最简单的示例中,我们已经获得了四个实施结果。 Java内存模型的任务是说这些执行中的哪些是正确的,哪些应该被禁止。 并假设三件事。 第一个是在一个线程的框架内,您的任务是伪顺序执行的。 这意味着编译器可以交换操作,处理器也可以并行执行指令,将它们交换。 但是他们必须这样做,以使程序执行时的可见效果与直接按顺序执行一样。
其次,该语言禁止从任何地方获取所谓的凭空表达的意思。 不幸的是,我们没有时间证明这一点,但是在某些情况下,编译器确实可以进行这样的转换,以至于单线程程序中的所有内容都将是正确的,并且您可能在多线程程序中有一条您没有做过的记录。
因此,内存模型表示读取任何变量将返回默认值,或者返回曾经由另一个命令完成的某些记录结果。 如果其余动作之间通过偏序关系连接,则可以将它们解释为顺序动作。 现在,这是我们唯一需要数学的地方。 部分关系,这是因为并非所有变量的读,写操作都是通过关系连接的。 它具有反射性,传递性和反对称性。

让我们在发生之前更详细地讨论发生的事情。 第一条规则是它链接单个线程内的所有操作。 如果在一个线程内编写的X等于1,则Y等于1; 有人说,X中的写操作与发生在Y之前有关。也就是说,X发生在Y之前。并且它还绑定了一些特殊操作,即所谓的同步操作。 在规范中阅读更多内容。 例如,这是在易失性变量中进行写入和读取,在一台监视器上进行锁定/解锁,进入同步块并退出同步块。 非常重要的一点是,程序中的所有同步操作都以完全相同的顺序看到线程,就好像它们是一个接一个地执行一样。
并且在链接这些动作对之前发生。 哪个线程进行同步操作都无关紧要。 重要的是,例如,将它们传递给一个volatile变量。 规范说,写volatile变量发生在任何其他后续操作之前。 这恰好是指我们执行同步操作的方式。
最重要的是规则在一致性之前发生,它只是回答了有关内存模型的最重要的问题。 可以解释如下。 如果变量中有一连串的读/写操作,并且它们由一连串的事前关联关系相连,那么读操作肯定会看到该链中的最后一条记录。 如果不存在,则可以看到任何其他值,任何其他记录或默认值。 现在,您可以完成基本定义,然后呼气。
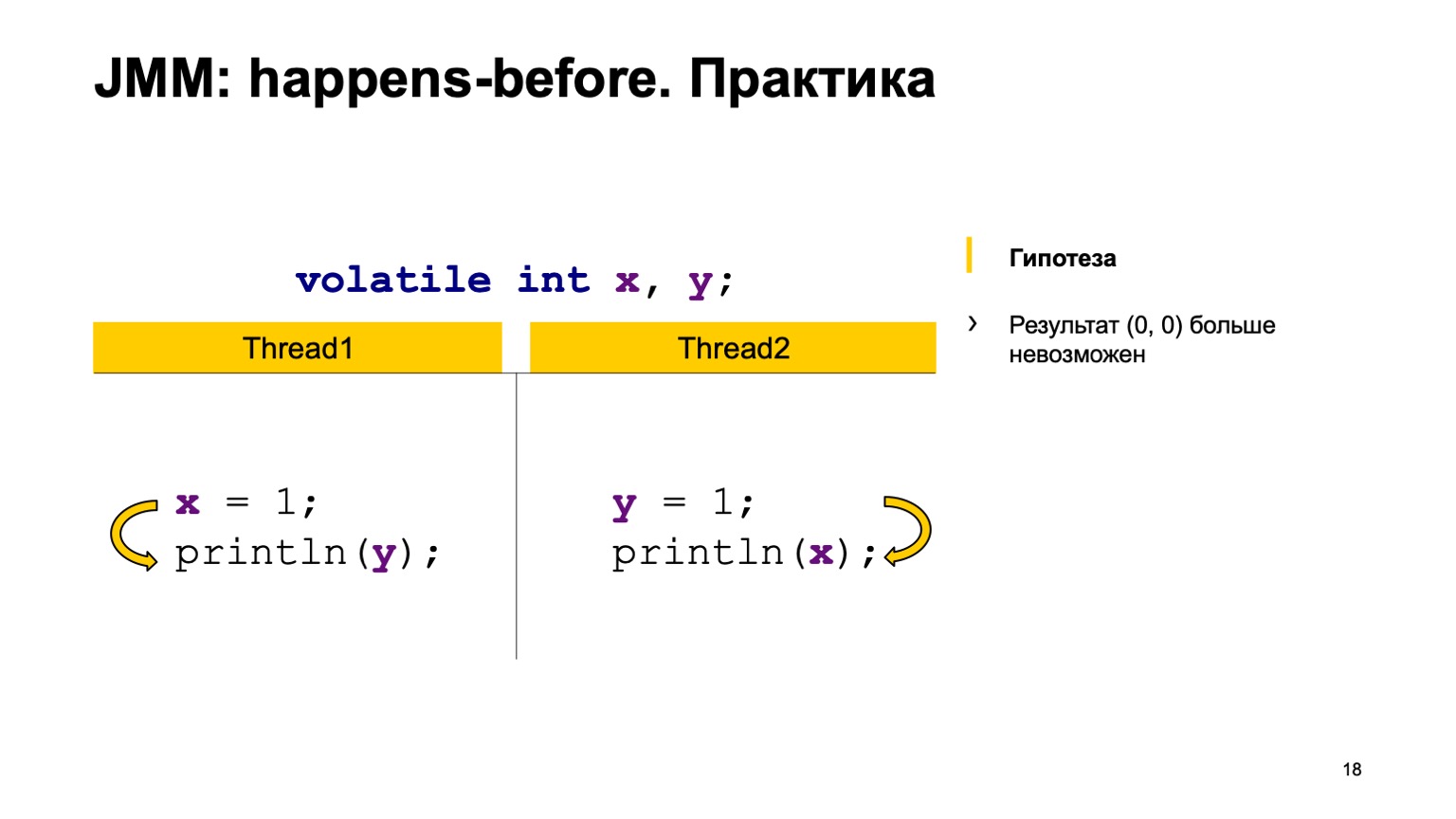
让我们尝试在实践中检验该理论吗? 让我们以记录的交叉读取为例,仅将volatile修饰符添加到变量X和Y。让我们尝试证明以下假设:我们将不再看到零至零的值。 为此,只需使用我上面所说的规则即可。
我们将在一个线程中安排事前。 写入X的操作发生在从Y读取和第二个线程读取之前。 在从X读取之前,先写入Y。
然后,我们有四个同步操作:写X,写Y,读X,读Y。它们可以按一定顺序出现,而在两种情况下可以成对出现。
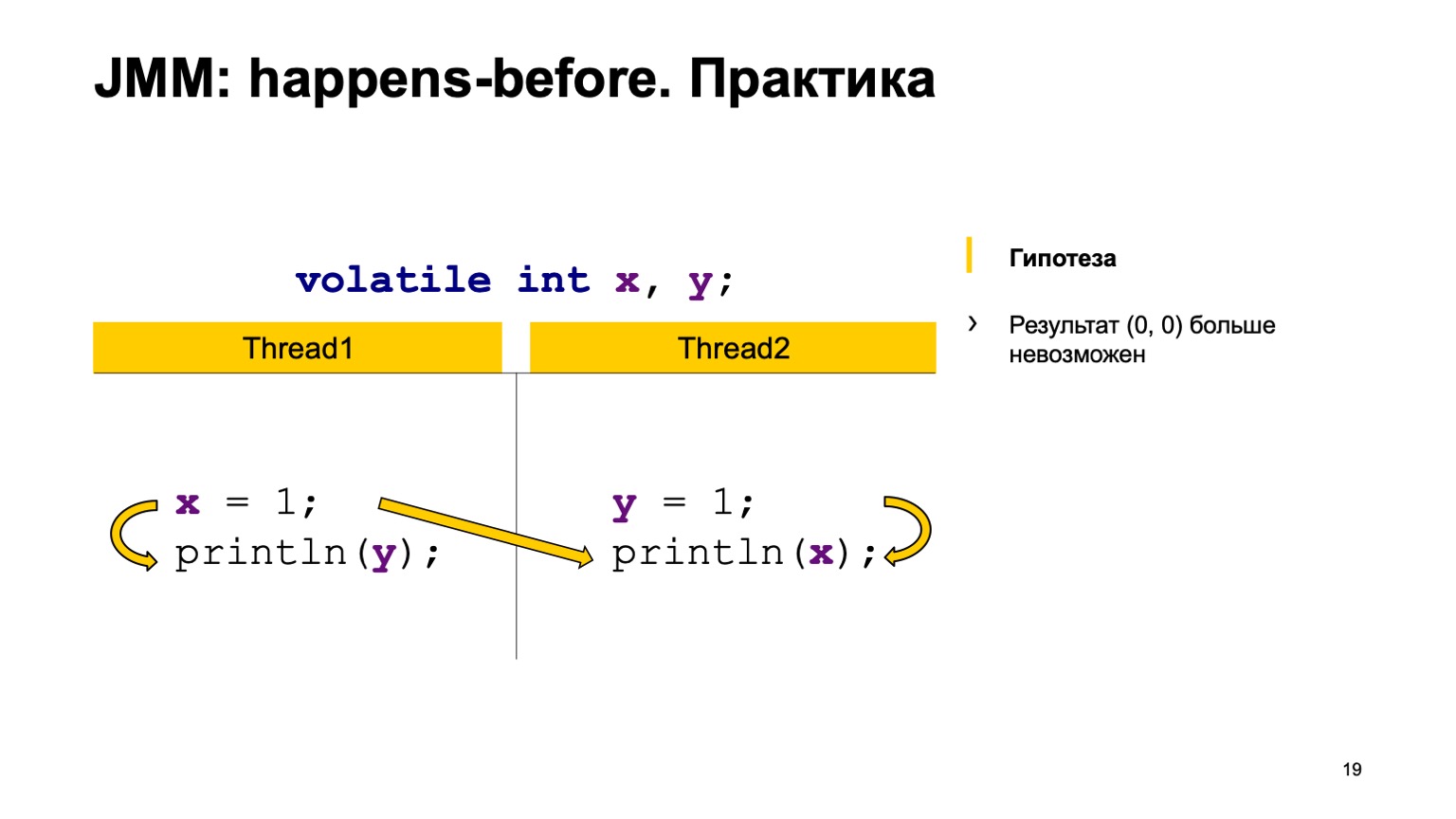
例如,向流1中的X写入要比从流2中的X读取(发生在发生之前)早。 正如您在此处看到的,该关系与Y无关。从Y读取的结果可以将默认值或第二个流记录的值返回给我们。 X的读数必须始终看到一个单位。 因此,我们的选项可以是零一,一。
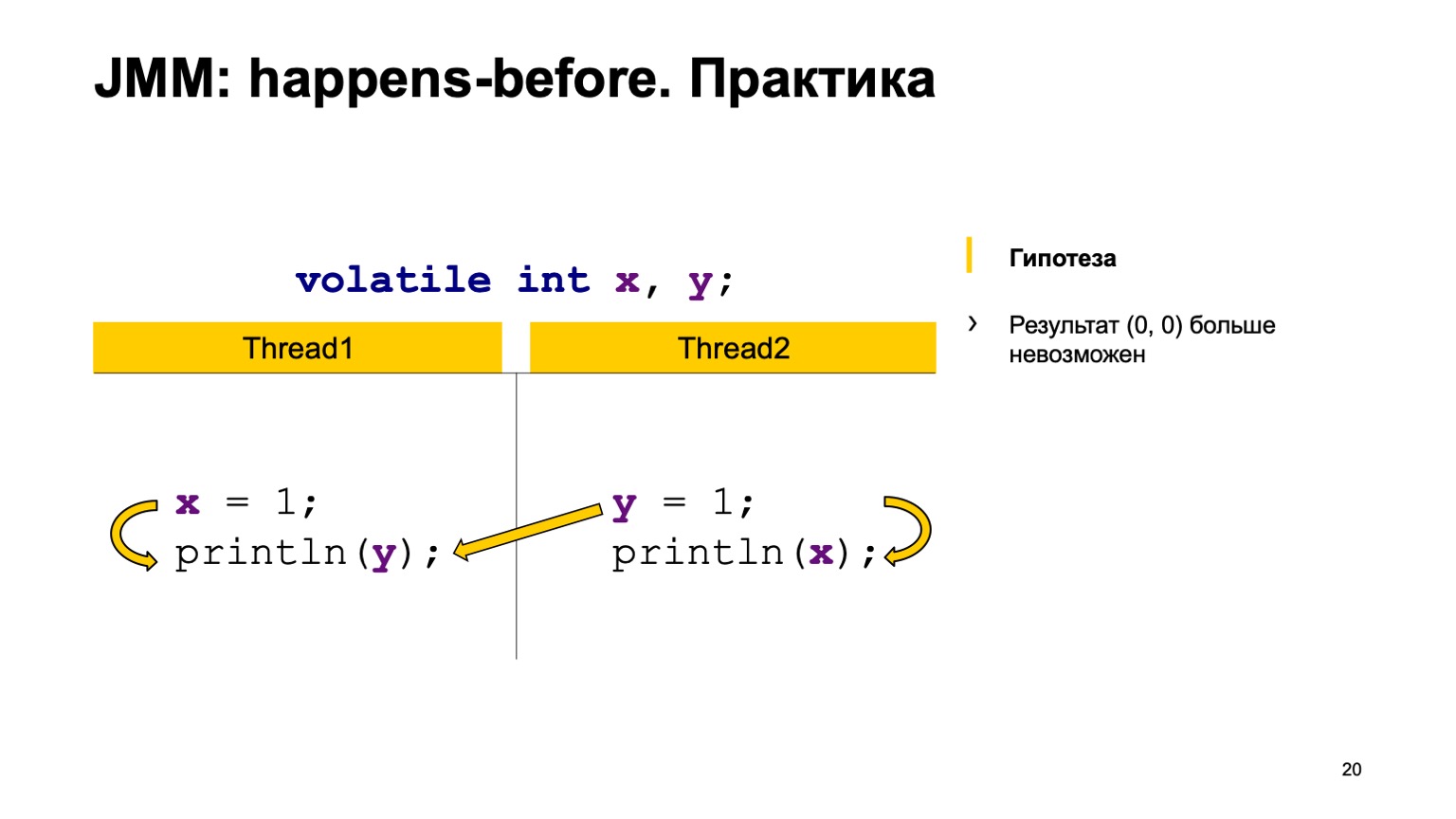
第二种情况是建立连接时。 这是同一件事-在从Y读取之前发生写入Y的操作。X之间也没有连接。因此,结果是相同的,只有在这里您得到一零,零一。 从理论上讲,我们可以证明我们的新程序行为。

您可以在实践中检查它。 在我们的测试中添加volatile关键字。 奔跑吧,看看,确实,在我们国家,这种价值永远不会被复制。 happens-before — . .

, . volatile Z volatile, . , Z; , , , Z. happens-before . , Z , . .
, , — put value. — get value . happens-before , , put value happens-before get value. , happens-before , volatile, . , , — put happens-before get.

, . -, . , , . , . , , . , . , , , , .
-, , jcstress. : , JVM . , .
, . — «The Art of Multiprocessor Programming» . , happens-before, , . . — «Java Concurrency in Practice» . , . , , . . .
, performance- Oracle, Red Hat. , Java- , . JMM.
. , -, . , , YouTube. , , . .