我想与您分享我在恢复Postgres数据库的全部功能方面的第一个成功经验。 半年前,我遇到了Postgres DBMS,在那之前我完全没有数据库管理经验。

我在一家大型IT公司中担任半DevOps工程师。 我们公司正在开发用于高负载服务的软件,但我负责性能,维护和部署。 他们为我设置了一个标准任务:在一台服务器上更新应用程序。 该应用程序是用Django编写的,在升级期间,将执行迁移(更改数据库结构),在此过程之前,我们将通过标准pg_dump程序删除完整的数据库转储,以防万一。
删除转储时发生意外错误(Postgres版本为9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
错误
“块中的无效页面”指示文件系统级别的问题,这非常糟糕。 在各种论坛上,他们建议使用
zero_damaged_pages选项进行
全 真空来解决此问题。 好吧,popprobeum ...
恢复准备
注意! 在尝试还原数据库之前,请确保备份Postgres。 如果您有虚拟机,请停止数据库并拍摄快照。 如果无法拍摄快照,请停止数据库并将Postgres目录的内容(包括wal文件)复制到安全的地方。 我们业务的主要目的不是使事情变得更糟。 阅读
此 。
由于数据库整体上对我有用,因此我将自己限制在通常的数据库转储中,但排除了数据损坏的
表 (pg_dump中的
-T,--exclude-table = TABLE )。
该服务器是物理服务器,无法拍摄快照。 备份已删除,请继续。
文件系统检查
在尝试还原数据库之前,您需要确保文件系统本身的所有顺序都正确无误。 如果出现错误,请更正它们,因为否则只会使情况变得更糟。
在我的情况下,带有数据库的文件系统安装在
“ / srv”中 ,类型为ext4。
我们停止数据库:
systemctl stop postgresql@9.5-main.service,并检查文件系统是否未被任何人使用,并使用
lsof命令将其卸载:
lsof + D / srv我仍然不得不停止redis数据库,因为它也使用了
“ / srv” 。 接下来,我卸载
/ srv (umount)。
使用带有-f选项的
e2fsck实用程序来检查文件系统(
即使将文件系统标记为clean,也强制检查 ):
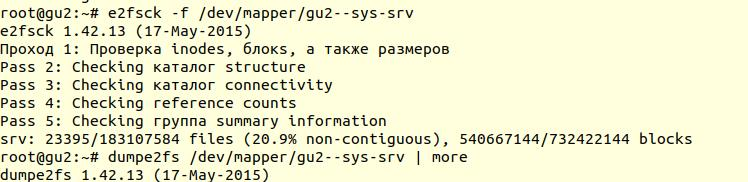
接下来,使用
dumpe2fs实用程序(
sudo dumpe2fs / dev / mapper / gu2-sys-srv | grepchecked ),可以验证是否确实执行了检查:
 e2fsck
e2fsck表示在ext4文件系统级别没有发现任何问题,这意味着您可以继续尝试还原数据库,或者返回
真空状态满满 (当然,您需要将文件系统挂载回去并启动数据库)。
如果您的服务器是物理服务器,请确保检查磁盘的状态(通过
smartctl -a / dev / XXX )或RAID控制器,以确保问题不在硬件级别。 以我为例,RAID原来是“铁”,所以我要求本地管理员检查RAID的状态(服务器距离我几百公里)。 他说没有任何错误,这意味着我们绝对可以开始恢复。
尝试1:zero_damaged_pages
我们通过具有超级用户权限的psql帐户连接到数据库。 我们正好需要超级用户,因为 只有他可以更改
zero_damaged_pages选项。 就我而言,这是postgres:
psql -h 127.0.0.1 -U postgres -s [数据库名称]需要
zero_damaged_pages选项来忽略读取错误(来自postgrespro网站):
当检测到损坏的页面标题时,Postgres Pro通常会报告错误并中止当前事务。 如果启用了zero_damaged_pages参数,则系统将发出警告,清除内存中损坏的页面,然后继续处理。 此行为将破坏数据,即损坏页面中的所有行。
打开该选项并尝试制作完整的真空表:
VACUUM FULL VERBOSE
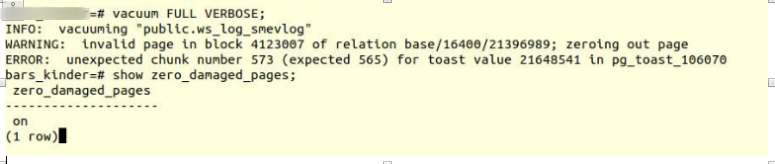
不幸的是失败。
我们遇到了类似的错误:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast-在Postgres中存储“长数据”的机制,如果它们不适合在同一页面上(默认为8kb)。
尝试2:重新编制索引
谷歌的第一个提示没有帮助。 经过几分钟的搜索,我发现了第二个技巧-使
索引重新编制为损坏的表。 我在很多地方都接受了这个建议,但是并没有激发信心。 重新编制索引:
reindex table ws_log_smevlog
 重新索引
重新索引完成没有问题。
但是,这无济于事,
VACUUM FULL崩溃了,并出现类似的错误。 由于我已经习惯于失败,所以我开始在Internet上进一步寻求建议,并遇到了
一篇相当有趣的
文章 。
尝试3:SELECT,LIMIT,OFFSET
上面的文章建议逐行查看表并删除有问题的数据。 首先,有必要查看所有内容:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
就我而言,该表包含
1,628,991行! 以一种好的方式,有必要注意
数据的
分区 ,但这是单独讨论的主题。 是星期六,我在tmux中运行了此命令,然后入睡:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
到了早上,我决定检查一下情况。 令我惊讶的是,我发现在2小时内仅扫描了2%的数据! 我不想等待50天。 另一个完全失败。
但是我没有放弃。 我想知道为什么扫描需要这么长时间。 从文档(同样在postgrespro上),我发现:
OFFSET表示在开始生产线之前跳过指定的行数。
如果同时指定了OFFSET和LIMIT,则系统首先跳过OFFSET行,然后开始计数行以限制LIMIT。
使用LIMIT时,使用ORDER BY子句也很重要,以便按特定顺序返回结果行。 否则,将返回不可预测的字符串子集。
显然,以上命令是错误的:首先,没有
by命令 ,结果可能是错误的。 其次,Postgres首先必须扫描和跳过OFFSET行,并且随着
OFFSET的增加
,性能将进一步下降。
尝试4:以文本形式删除转储
此外,我想到了一个看似很棒的主意:以文本形式删除转储并分析最后记录的行。
但首先,
让我们看一下
ws_log_smevlog表
结构 :

在我们的例子中,我们有一列
“ id” ,其中包含该行的唯一标识符(计数器)。 计划是这样的:
- 我们开始以文本形式(以sql命令的形式)删除转储
- 在某个时间点,转储将由于错误而中断,但文本文件仍将保存在磁盘上
- 我们查看文本文件的末尾,从而找到成功拍摄的最后一行的标识符(id)
我开始以文本形式删除转储:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
如预期的那样,转储转储被相同的错误中断:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
此外,通过
tail,我查看了转储的结尾(
tail -5 ./my_dump.dump ),发现转储在ID
186 525的行上被中断。 “所以,问题出在ID 186 526的行中,它已损坏,需要删除!”我想。 但是通过向数据库发出请求:
“
从ws_log_smevlog中选择*,其中id = 186529 ”表明,此行一切正常。带有索引186
530-186 540的行也可以正常工作。 另一个“聪明的主意”失败了。 后来,我意识到了发生这种情况的原因:从表中删除/更改数据时,并没有物理删除它们,而是将它们标记为“死元组”,然后
autovacuum出现并将这些行标记为已删除,并允许再次使用这些行。 要理解的是,如果表中的数据已更改并且自动真空已打开,则它们不会顺序存储。
尝试5:SELECT,FROM,ID =
失败使我们变得更强大。 您不应该放弃,您需要走到最后,相信自己和自己的能力。 因此,我决定尝试另一种选择:一次只查看数据库中的所有条目。 知道我的表的结构(见上文),我们有一个唯一的id字段(主键)。 在表中,我们有1,628,991行,并且
id按顺序进行,这意味着我们可以一次简单地遍历它们:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
如果有人不理解,则该命令的工作方式如下:它逐行扫描表并将stdout发送到
/ dev / null ,但是如果SELECT命令失败,则会显示错误文本(将stderr发送到控制台),并输出包含错误的行(感谢||)。表示select出现问题(命令返回码不为0)。
我很幸运,我在
id字段上创建了索引:

这意味着查找具有所需ID的行不会花费太多时间。 从理论上讲,它应该起作用。 好吧,在
tmux中运行命令并进入睡眠状态。
到了早上,我发现已查看了约90,000条记录,仅超过5%。 与以前的方法相比,效果极好(2%)! 但是我不想等待20天...
尝试6:SELECT,FROM,WHERE id> =和id <
在数据库下为客户分配了一个出色的服务器:双处理器
Intel Xeon E5-2697 v2 ,在我们的位置上有多达48个线程! 服务器负载是平均水平,我们可以花费大约20个线程而不会出现任何问题。 RAM也足够:高达384 GB!
因此,该命令需要并行化:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
在这里可以编写漂亮而优雅的脚本,但是我选择了最快的并行化方法:将0-1628991范围手动分为100,000条记录的间隔,并分别运行16个格式的命令:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
但这还不是全部。 从理论上讲,连接到数据库也需要一些时间和系统资源。 同意,连接1,628,991并不是很合理。 因此,让我们在一个连接而不是一个连接中提取1000行。 结果,团队变成了:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
在tmux会话中打开16个窗口,然后运行以下命令:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
一天后,我得到了第一个结果! 即(值XXX和ZZZ尚未保留):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
这意味着我们有三行包含错误。 第一个和第二个问题记录的id在829,000和830,000之间,第三个问题记录的id在146,000和147,000之间。接下来,我们只需要查找问题记录的确切id值即可。 为此,请在步骤1中浏览我们的问题记录范围并标识id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
大结局
我们找到了有问题的台词。 我们通过psql进入数据库并尝试删除它们:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
令我惊讶的是,即使没有
zero_damaged_pages选项,也可以毫无问题地删除条目。
然后,我连接到数据库,将其设置为
VACUUM FULL (我认为没有必要这样做),最后使用
pg_dump成功删除了备份。 转储已加注星标,没有任何错误! 解决问题的方法如此愚蠢。 在经历了如此多的失败之后,我们成功找到了解决方案!
致谢和结论
这是我还原真实Postgres数据库的第一次经验。 我会记得很长一段时间的经验。
最后,我要感谢PostgresPro将文档翻译成俄语,以及
完全免费的在线课程 ,这些
课程在分析问题时大有帮助。