
几年前,
已经在GitHub官方博客上
讨论了 Kubernetes。 从那时起,它已成为部署服务的标准技术。 Kubernetes现在管理内部和公共服务的很大一部分。 随着集群的增长和对性能的要求越来越严格,我们开始注意到Kubernetes上的某些服务偶尔会显示延迟,这些延迟无法用应用程序本身的负载来解释。
实际上,在应用中,会出现长达100 ms或更长的随机网络延迟,这会导致超时或重试。 预计服务将能够以比100毫秒更快的速度响应请求。 但是,如果连接本身需要花费大量时间,则这是不可能的。 另外,我们观察到了非常快的MySQL查询,该查询原本需要花费毫秒,而MySQL的确以毫秒为单位进行管理,但是从请求应用程序的角度来看,响应花费了100毫秒或更长时间。
立即清楚地知道,即使呼叫来自外部Kubernetes,也仅在连接到Kubernetes主机时才会出现问题。 重现此问题的最简单方法是在
Vegeta测试中进行,该测试可从任何内部主机运行,在特定端口上测试Kubernetes服务,并偶尔记录一个大延迟。 在本文中,我们将探讨如何设法找到导致此问题的原因。
消除故障链中不必要的复杂性
重现了相同的示例后,我们希望缩小问题的范围并消除额外的复杂性。 最初,Vegeta和Kubernetes上的pod之间的流中有太多元素。 要确定更深层的网络问题,您需要排除其中的一些问题。
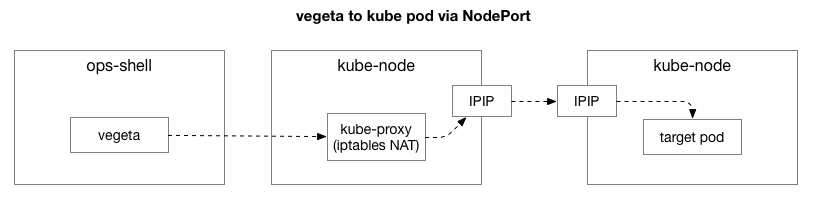
客户端(Vegeta)与群集中的任何节点创建TCP连接。 Kubernetes充当使用
IPIP的覆盖网络(在现有数据中心网络之上),也就是说,将覆盖网络的IP数据包封装在数据中心的IP数据包之内。 连接到第一个节点时,将使用状态监视执行
网络地址转换 (NAT)网络地址转换,以将Kubernetes主机的IP地址和端口转换为覆盖网络(特别是具有应用程序的Pod)上的IP地址和端口。 对于接收到的数据包,执行相反的顺序。 这是一个复杂的系统,具有许多状态和许多元素,这些元素会随着服务的部署和移动而不断更新和更改。
Vegeta测试中的
tcpdump实用程序在TCP握手期间(在SYN和SYN-ACK之间)提供了一个延迟。 为了消除这种不必要的复杂性,您可以对SYN软件包使用
hping3进行简单的“ ping”操作。 检查响应数据包中是否存在延迟,然后重置连接。 我们可以通过仅包含超过100毫秒的数据包来过滤数据,并获得比Vegeta中的完整网络级别7测试更简单的选项来重现问题。 以下是在服务的主机“端口”(30927)上使用TCP SYN / SYN-ACK的Kubernetes主机的“ ping”,间隔为10毫秒,由最慢的响应过滤:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms马上可以做第一眼观察。 序列号和时间表明这些不是一次性拥塞。 延迟通常会累积并最终得到处理。
接下来,我们想找出哪些组件可能与拥塞现象有关。 也许这些是NAT中数百个iptables规则中的一些? 还是网络上IPIP隧道出现问题? 一种验证方式是通过排除系统来验证系统的每个步骤。 如果删除NAT和防火墙逻辑,仅保留IPIP的一部分,将会发生什么:
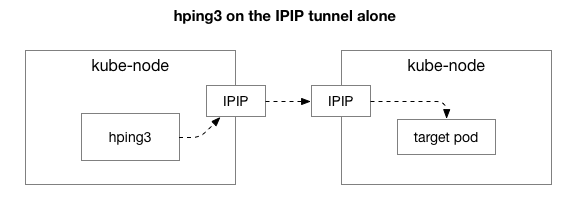
幸运的是,如果机器在同一网络上,Linux使得直接访问IP覆盖层变得容易:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms从结果来看,问题仍然存在! 这不包括iptables和NAT。 那么问题出在TCP中吗? 让我们看看常规的ICMP ping如何进行:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms结果表明问题尚未消失。 也许这是IPIP隧道? 让我们简化测试:
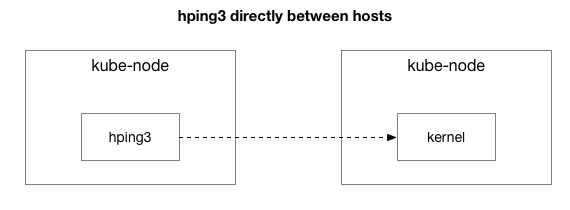
在这两个主机之间是否发送了所有数据包?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms我们将情况简化为两个Kubernetes主机相互发送任何数据包,甚至是ICMP ping。 如果目标主机“不好”(有些情况比其他情况差),他们仍然会看到延迟。
现在是最后一个问题:为什么延迟仅发生在kube节点服务器上? 当kube-node是发送者还是接收者时,会发生这种情况吗? 幸运的是,通过从Kubernetes外部的主机发送一个数据包,但使用相同的“已知错误”接收者,也很容易弄清楚这一点。 如您所见,问题并未消失:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms然后,我们从先前的源kube-node向外部主机(不包括原始主机,因为ping包括RX和TX组件)执行相同的请求:
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms在检查了延迟的数据包捕获之后,我们获得了一些其他信息。 特别是,发送者(以下)看到此超时,但接收者(上方)没有看到此超时-请参见“增量”列(以秒为单位):

另外,如果您查看接收方TCP和ICMP数据包顺序的差异(按序列号),则ICMP数据包始终以发送时的相同顺序到达,但时序不同。 同时,TCP数据包有时会交替出现,其中一些会被卡住。 特别是,如果我们检查SYN数据包的端口,则在发送方,它们按顺序排列,但在接收方,则不排列。
现代服务器(如我们的数据中心)的
网卡在处理包含TCP或ICMP的数据包方面存在细微的差异。 当数据包到达时,网络适配器“通过连接对其进行哈希处理”,也就是说,它尝试依次断开连接并将每个队列发送到单独的处理器核心。 对于TCP,此哈希同时包含源IP地址和目标IP地址以及端口。 换句话说,每个连接的散列(可能)都不同。 对于ICMP,由于没有端口,因此仅对IP地址进行哈希处理。
另一个新发现:在此期间,我们看到两台主机之间所有通信的ICMP延迟,但TCP没有。 这告诉我们原因可能是由于RX队列的散列:几乎可以确定,拥塞发生在RX数据包的处理中,而不是在发送响应中。
这从可能原因列表中排除发送数据包。 现在我们知道在某些kube节点服务器上,数据包处理的问题是在接收方。
了解Linux内核中的软件包处理
为了了解为什么问题在某些kube节点服务器上的接收者发生,让我们看看Linux内核如何处理软件包。
返回到最简单的传统实现,网卡接收数据包并将
中断发送到Linux内核,这是需要处理的数据包。 内核停止另一个操作,将上下文切换到中断处理程序,处理程序包,然后返回到当前任务。

这种上下文切换很慢:1990年代在10 MB的网络卡上可能没有注意到它,但是在最大吞吐量为每秒1500万个数据包的现代10G卡上,小型八核服务器的每个核心每秒可以中断数百万次。
为了不经常处理中断处理,很多年前,Linux添加了
NAPI :一种网络API,所有现代驱动程序都使用该API来提高性能。 在低速下,内核仍旧以旧方式接受来自网卡的中断。 一旦到达足够数量的超过阈值的数据包,内核便禁用中断,而是开始轮询网络适配器并分批接收数据包。 处理在softirq中执行,即在系统调用后
发生软件中断和内核(与用户空间不同)已运行时硬件中断的
情况下进行 。
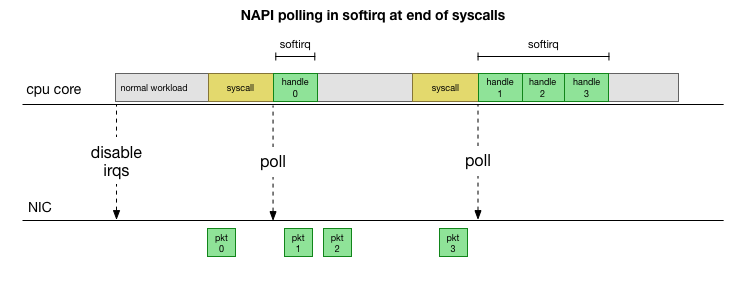
这要快得多,但是会导致另一个问题。 如果数据包太多,则将花费所有时间来处理来自网卡的数据包,并且用户空间进程没有时间实际清空这些队列(从TCP连接等读取数据)。 最后,队列填满,我们开始丢弃数据包。 为了找到平衡,内核为softirq上下文中处理的最大数据包数设置了预算。 一旦超出此预算,就会
ksoftirqd一个单独的
ksoftirqd线程(您将在每个内核的
ps看到其中一个),该线程将在正常的系统调用/中断路径之外处理这些softirq。 使用尝试公平分配资源的标准流程调度程序来计划此线程。
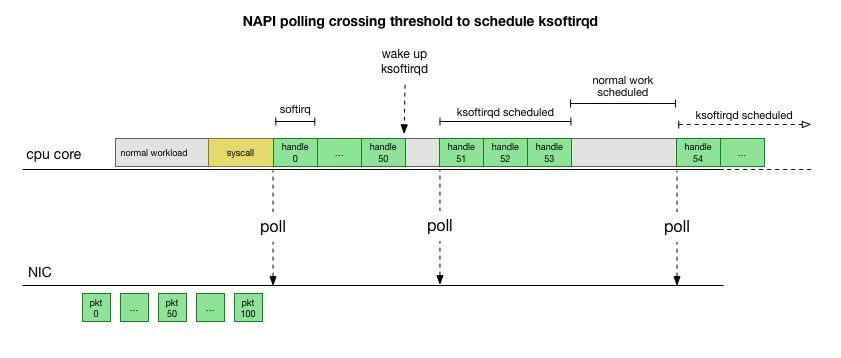
在检查了内核如何处理数据包之后,您可以看到存在一定的拥塞可能性。 如果softirq呼叫的接收频率较低,则数据包将需要等待一段时间才能在网卡的RX队列中进行处理。 可能是由于某些任务阻塞了处理器内核,或者其他原因导致内核无法启动softirq。
我们将处理范围缩小到内核或方法
Softirq延迟只是一个假设。 但这是有道理的,而且我们知道我们看到的情况非常相似。 因此,下一步就是确认这一理论。 如果已确认,则找出造成延误的原因。
回到我们的慢速包:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms如前所述,这些ICMP数据包被散列到单个NIC RX队列中,并由单个CPU内核进行处理。 如果我们想了解Linux的工作原理,了解这些软件包的处理位置(在哪个CPU内核上)和如何处理(softirq,ksoftirqd)很有用,以跟踪进程。
现在该使用允许实时监视Linux内核的工具了。 在这里,我们使用了
bcc 。 这套工具允许您编写小型C程序,这些程序可拦截内核中的任意函数并将事件缓冲到用户空间的Python程序中,该程序可以对其进行处理并返回结果。 内核中用于任意功能的钩子很复杂,但是该实用程序旨在提供最大的安全性,并且旨在精确跟踪在测试或开发环境中不容易重现的此类生产问题。
这里的计划很简单:我们知道内核会处理这些ICMP ping,因此我们在
icmp_echo内核
函数上添加了一个钩子,该
函数接收传入的ICMP数据包“ echo request”并启动ICMP响应“ echo response”的发送。 我们可以通过增加icmp_seq编号来识别软件包,该编号在上面显示了hping3。
bcc脚本代码看起来很复杂,但并不像看起来那样可怕。
icmp_echo函数传递
struct sk_buff *skb :这是带有“ echo request”请求的数据包。 我们可以跟踪它,拉出
echo.sequence序列(从
icmp_seq映射到
icmp_seq ),并将其发送到用户空间。 捕获当前进程名称/标识符也很方便。 以下是我们在内核处理软件包期间直接看到的结果:
TGID PID过程名称ICMP_SEQ
0 0交换器/ 11,770
0 0交换器/ 11,771
0 0交换器/ 11772
0 0交换器/ 11773
0 0交换器/ 11,774
20041 20086普罗米修斯775
0 0交换器/ 11,776
0 0交换器/ 11,777
0 0交换器/ 11778
4512 4542辐条报告779
这里应该注意的是,在
softirq的上下文中,进行系统调用的进程显示为“进程”,尽管实际上,此内核在内核的上下文中安全地处理数据包。
使用此工具,我们可以建立特定进程与特定软件包的连接,这些软件包在
hping3中显示出延迟。 我们针对此捕获针对特定的
icmp_seq值进行了一个简单的
grep 。 与上面的icmp_seq值相对应的数据包用我们在上面观察到的RTT进行了标记(括号中是由于RTT值小于50毫秒而被过滤的数据包的预期RTT值):
TGID PID过程名称ICMP_SEQ ** RTT
--
10137 10436 cadvisor 1951
10137 10436主管1952
76 76 ksoftirqd / 11953年** 99ms
76 76 ksoftirqd / 1954年** 89ms
76 76 ksoftirqd / 1955年** 79ms
76 76 ksoftirqd / 1956年** 69ms
76 76 ksoftirqd / 1957年** 59ms
76 76 ksoftirqd / 1958年**(49ms)
76 76 ksoftirqd / 1959年**(39ms)
76 76 ksoftirqd / 1960年**(29ms)
76 76 ksoftirqd / 11 1961 **(19ms)
76 76 ksoftirqd / 11 1962 **(9ms)
--
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55ms
76 76 ksoftirqd / 11 2073 **(45ms)
76 76 ksoftirqd / 11 2074 **(35ms)
76 76 ksoftirqd / 11 2075 **(25ms)
76 76 ksoftirqd / 11 2076 **(15ms)
76 76 ksoftirqd / 11 2077 **(5毫秒)
结果告诉我们一些事情。 首先,
ksoftirqd/11上下文处理所有这些包。 这意味着对于这对特定的机器,ICMP数据包在接收端的11个核心上进行了哈希处理。 我们还看到,在每次流量阻塞时,都有在
cadvisor系统调用的上下文中处理的数据包。 然后,
ksoftirqd承担任务并完成累积的队列:恰好是
cadvisor之后累积的数据包数量。
cadvisor总是在此之前立即工作的事实表明他参与了这个问题。 具有讽刺意味的是,
cadvisor的目的是“分析正在运行的容器的资源利用率和性能特征”,而不是引起此性能问题。
与容器处理的其他方面一样,这些都是非常先进的工具,在某些不可预见的情况下,可能会遇到性能问题。
cadvisor会做什么来减慢数据包队列?
现在,我们对故障的发生方式,导致故障的进程以及在哪个CPU上有了很好的了解。 我们看到由于硬锁定,Linux内核没有时间按时调度
ksoftirqd 。 而且我们看到软件包是在
cadvisor上下文中
cadvisor 。 逻辑上是假设
cadvisor启动了缓慢的syscall,然后处理了此时累积的所有数据包:
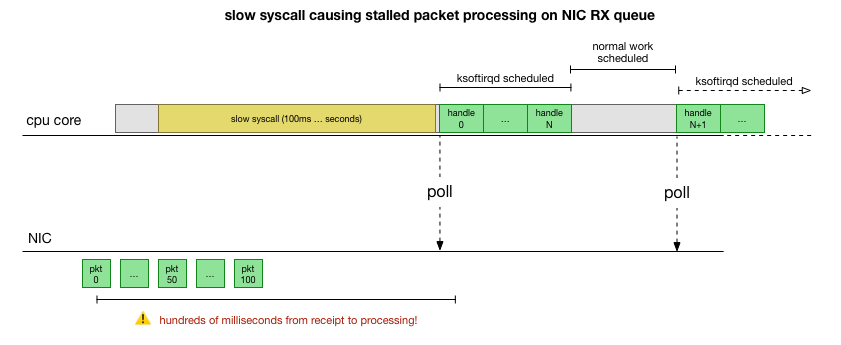
这是一个理论,但是如何检验呢? 我们可以做的是跟踪整个过程中CPU内核的运行情况,找到超出预算的数据包数量并调用ksoftirqd,然后再早一点看-在那之前在CPU内核上真正起作用的是什么。 就像每隔几毫秒对CPU进行一次X射线检查一样。 它看起来像这样:
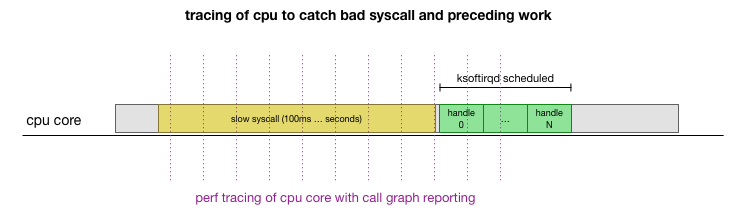
方便地,所有这些都可以使用现有工具来完成。 例如,性能
记录以指定的频率检查指定的CPU内核,并可以生成正在运行的系统的调用计划,包括用户空间和Linux内核。 您可以使用Brendan Gregg的
FlameGraph程序的一个小分支获取此记录并对其进行处理,该程序保留了堆栈跟踪顺序。 我们可以每1毫秒保存一次单行堆栈跟踪,然后在
ksoftirqd进入跟踪之前选择并保存样本100毫秒:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100结果如下:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run这里有很多东西,但是主要的是我们找到了我们在ICMP跟踪器中前面看到的“ ksoftirqd之前的cadvisor”模板。 这是什么意思?
每行都是特定时间点上的CPU轨迹。 一行中的每个调用都以分号分隔。 在各行的中间,我们看到syscall称为:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... 因此,cadvisor在与
mem_cgroup_*函数(调用堆栈的顶部/行尾)相关的
read()系统调用上花费了大量时间。
在呼叫跟踪中,查看要读取的内容并不方便,因此请运行
strace并查看cadvisor的工作,并查找超过100毫秒的系统调用:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>如您所料,这里我们看到了慢速
read()调用。 从读取操作的内容和
mem_cgroup上下文中可以看出,这些
read()调用引用了
memory.stat文件,该文件显示了内存使用情况和cgroup限制(Docker资源隔离技术)。 cadvisor工具轮询此文件以获取容器的资源使用信息。 让我们检查一下此核心或cadvisor是否做了意外的事情:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $现在我们可以重现该错误,并了解Linux内核正面临病理。
是什么让阅读如此缓慢?
此时,查找来自其他用户的有关类似问题的消息要容易得多。 事实证明,在cadvisor跟踪器中,此错误被报告为
CPU使用率过高的
问题 ,只是没有人注意到延迟也随机反映在网络堆栈中。 确实,已经注意到cadvisor消耗的处理器时间比预期的要多,但是并没有给予太多重视,因为我们的服务器具有大量的处理器资源,因此我们没有仔细研究此问题。
问题是控制组(cgroups)考虑了名称空间(容器)内部的内存使用情况。 当该cgroup中的所有进程终止时,Docker释放了一个内存控制组。 但是,“内存”不仅仅是过程内存。 尽管不再使用进程内存,但事实证明,内核还分配了缓存的内容,例如牙科和索引节点(目录和文件元数据),这些内容缓存在内存cgroup中。 从问题的描述:
cgroups僵尸:控制组,其中没有进程,它们被删除,但仍为其分配了内存(在我的情况下,是从dentry缓存中分配的,但也可以从页面缓存或tmpfs分配它们)。
释放cgroup时,内核检查高速缓存中的所有页面的速度可能非常慢,因此选择了延迟过程:等待直到再次请求这些页面,甚至在确实需要内存时,最后清除cgroup。 到目前为止,在收集统计信息时仍会考虑cgroup。
在性能方面,他们为性能而牺牲了内存:由于保留了一些缓存的内存,因此加快了初始清理的速度。 这很正常。 当内核使用缓存内存的最后一部分时,cgroup最终将被清除,因此不能将其称为“泄漏”。 不幸的是,此内核版本(4.9)中
memory.stat搜索机制的特定实现,再加上我们服务器上的大量内存,导致以下事实:恢复最新的缓存数据和清除cgroup僵尸需要更多的时间。
事实证明,我们某些节点上的cgroup僵尸数量如此之多,以至于读取和延迟都超过了一秒钟。
解决cadvisor问题的方法是立即清除整个系统中的dentries / inode缓存,这将立即消除主机上的读取延迟以及网络延迟,因为删除缓存包括cgroup僵尸缓存的页面,并且它们也被释放。 这不是解决方案,但可以确定问题的原因。
事实证明,较新版本的内核(4.19+)改进了
memory.stat调用的性能,因此切换到该内核解决了该问题。 同时,我们拥有用于检测Kubernetes集群中的问题节点,优雅地耗尽它们并重新启动的工具。 我们梳理了所有群集,找到了延迟足够高的节点,然后重新启动了它们。 这给了我们时间来更新其余服务器上的操作系统。
总结一下
由于此错误使NIC RX队列的处理停止了数百毫秒,因此,它同时在短连接和中间连接(例如MySQL查询和响应数据包)之间造成了很大的延迟。
, Kubernetes, . Kubernetes .