
我工作的公司编写了自己的流量过滤系统,并用它来保护企业免受DDoS攻击,僵尸程序,解析器等的侵害。 该产品基于
反向代理这样的过程,借助该过程,我们可以实时分析大量流量,最后只允许合法的用户请求通过,从而过滤掉所有恶意请求。
其主要特点是我们的服务可以处理无限量的传入流量,因此,尽可能高效地使用工作站的所有资源非常重要。 现代C ++的大量开发经验为我们提供了帮助,包括最新标准和一组称为Boost的库。
反向代理
让我们回到反向代理,看看如何在C ++和boost.asio中实现它。 首先,我们需要两个对象,分别称为服务器会话和客户端会话。 服务器会话建立并维持与浏览器的连接;客户端会话建立并维持与服务的连接。 您还将需要一个流缓冲区,其中将工作与内部的内存封装在一起,服务器会话从套接字读取该流,客户端会话将其写入该套接字。 服务器和客户端会话的示例可以在boost.asio的文档中找到。 在那里可以找到如何使用流缓冲区。
在从示例中收集了反向代理原型之后,将很清楚,这样的应用程序可能不会提供无限的传入流量。 然后,我们将开始增加代码的复杂性。 让我们考虑一下io上下文的多线程,wokers和pool,以及更多内容。 特别是有关在服务器和客户端会话之间复制内存的过早优化。
我们在谈论什么样的内存复制? 事实是,在进行过滤时,流量并不总是不变地传输。 看下面的示例:在其中删除一个标头,然后添加两个标头。 随着服务内部逻辑的复杂性,执行类似操作的用户查询的数量也会增加。 在任何情况下,您都不能盲目复制数据! 如果总请求中只有1%发生更改,而99%保持不变,则应仅为此1%分配新的内存。 它可以帮助您实现boost :: asio :: const_buffer和boost :: asio :: mutable_buffer,通过它们您可以用一个实体表示几个连续的内存块。
用户要求:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
问题
结果,我们得到了一个现成的应用程序,该应用程序可以很好地扩展并具有各种优化功能。 通过将其投入生产,我们很高兴它能够稳定好地运行多长时间。
随着时间的流逝,随着流量的出现,我们开始拥有越来越多的客户。 在某些时候,我们面临着在拒绝大型攻击时性能不足的问题。 在使用
perf实用程序分析服务之后,我们注意到所有加载了堆的操作都位于顶部。 然后,我们使用
yandex-tank和根据实际流量生成的墨盒在测试电路上重新创建了类似的情况。 通过
放大器连接服务
,我们看到了以下图片...
放大器(woslab)的屏幕截图:
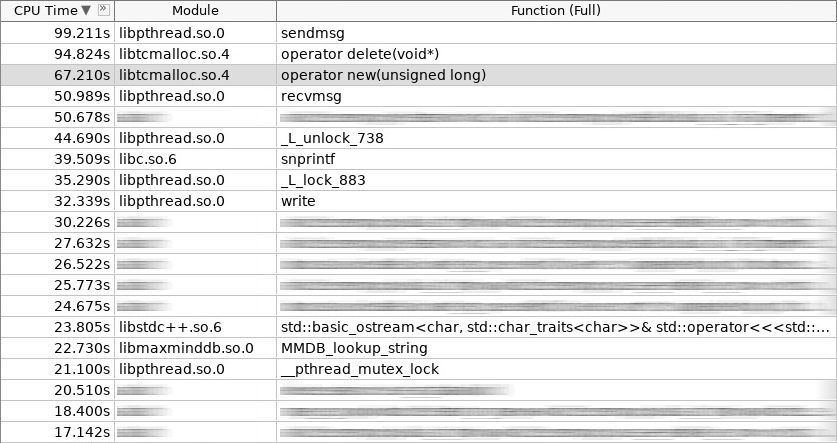
在屏幕截图中,新操作员的工作时间为67秒,而操作员删除的时间甚至更多-97秒。
这种情况使我们感到不安。 如何减少运算符new和operator delete中的应用程序停留时间? 可以通过放弃对堆上频繁创建和删除的对象进行恒定分配来做到这一点,这是合乎逻辑的。 我们选择了三种方法。 其中两个是标准的:
对象池和
堆栈分配 。 在应用程序启动阶段在池中组织的客户端会话很适合第一种方法。 第二种方法用于在同一堆栈中换句话说在同一io上下文处理程序中从头到尾处理用户请求的任何地方。 我们将不作更详细的介绍。 我们最好谈论第三种方法,因为它是最复杂和有趣的。 这称为
平板分配或平板分配。
平板分布的想法并不新鲜。 它是在Solaris中发明和实现的,后来又移植到Linux内核,其原因在于,经常使用的相同类型的对象更易于存储在池中。 我们只是在需要时才从池中取出对象,完成工作后我们会将其返回。 无需致电操作员new和操作员delete! 而且,最少的初始化。 在平板核心中,分发用于信号量,文件描述符,进程和线程。 在我们的案例中,它完全适用于服务器和客户端会话以及其中的所有会话。
图表(平板分布):

除了平板分配器位于内核中之外,它们的实现还存在于用户空间中。 它们很少,而正在积极开发的通常很少。 我们选择了一个名为
libsmall的库,该库是
tarantool的一部分。 它具有您需要的一切。
- 小::分配器
- 小:: slab_cache(本地线程)
- 小::平板
- 小::竞技场
- 小::配额
::平板小结构是具有特定对象类型的池。 small :: slab_cache结构是一种高速缓存,其中包含具有特定对象类型的各种池列表。 small :: allocator结构是一种代码,用于选择必要的缓存,在其中查找合适的池,在该池中分发所请求的对象。 从以下示例中可以清楚看出小::竞技场和小::配额对象的作用。
包装纸
libsmall库是用C而不是C ++编写的,因此我们必须开发一些包装程序以透明地集成到标准C ++库中。
- 变量:: slab_allocator
- variti ::平板
- 变量:: thread_local_slab
- 变量:: slab_allocate_shared
variti :: slab_allocator类实现了在编写其自己的分配器时由标准提出的最低要求。 在variti :: slab类中,所有与libsmall库一起使用的模块均被封装。 为什么需要variti :: thread_local_slab? 事实是,分发平板缓存是线程本地对象。 这意味着每个线程都有自己的一组缓存。 这样做是为了在分发新对象时将阻塞操作的数量减少到零。 因此,在每个线程的内存中,我们放置了variti :: slab类的实例,并使用variti :: thread_local_slab包装器来调节对它的访问。 稍后我将向您介绍模板函数variti :: slab_allocate_shared。
在vari :: :: slab_allocator类中,一切都非常简单。 他有能力从一种类型重新绑定到另一种类型,例如从void到char。 有趣的是,在内存用尽分配板的情况下,您可以注意nullptr在std :: bad_alloc异常中的流行。 其余的是在variti :: thread_local_slab包装器中转发呼叫。
片段(slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
让我们看看如何实现构造函数和析构函数variti :: slab。 在构造函数中,我们为所有对象总共分配不超过1 GiB的内存。 在我们的案例中,每个池的大小不超过1 MiB。 我们可以分配的最小对象大小为2个字节(实际上,libsmall会将其增加到所需的最小数量-8个字节)。 通过平板分布可用的其余对象将是2的倍数(由常量2.f设置)。 总计,您可以分发大小为8、16、32等的对象。 如果所请求的对象的大小为24个字节,则将从内存中产生开销。 分发将把该对象返回给您,但是它将被放置在一个与32个字节大小的对象相对应的池中。 其余8个字节将处于空闲状态。
片段(slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
所有这些限制都适用于variti :: slab类的特定实例。 由于每个线程都有自己的线程(认为是本地线程),因此进程的总限制将不是1 GiB,而是与使用slab分布的线程数成正比。
图表(std ::线程:: id):
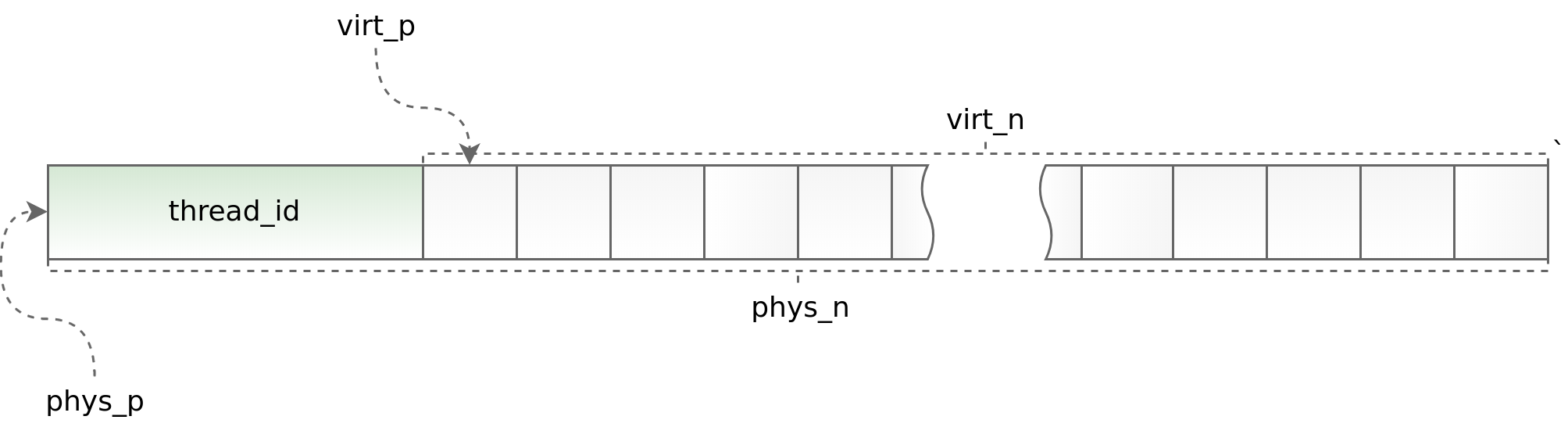
一方面,使用线程本地可以加快多线程应用程序中的slab分发工作,另一方面,它对异步应用程序的体系结构施加了严格的限制。 您必须在同一流中请求并返回一个对象。 作为boost.asio的一部分进行此操作有时会出现问题。 为了跟踪明显错误的情况,在每个对象的开头,我们放置了其中调用了allocate方法的流的标识符。 然后,该标识符在deallocate方法中进行验证。 助手phys_to_virt_p和virt_to_phys_p对此提供了帮助。
片段(thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
片段(thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
当失去对流的控制时(在不同的io上下文之间传输对象时),智能指针允许正确释放对象。 他所做的全部工作就是分发对象,记住其io上下文,然后使用自定义分隔符将其包装在std :: shared_ptr中,该分隔符不会立即将对象返回到分发中,而是在先前保存的io上下文中进行处理。 当每个io上下文在单个线程上运行时,此方法效果很好。 否则,不幸的是,此方法不适用。
片段(slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
解决方案
libsmall包装工作完成后,我们首先将chun分配器移到了流缓冲区中的平板上。 这很容易做到。 收到了积极的结果后,我们继续将平板分配器首先应用于流缓冲区本身,然后应用于服务器和客户端会话中的所有对象。
- 变量::块
- vari :: :: streambuf
- 变量:: server_session
- 变量:: client_session
同时,有必要解决其他问题,即:将简单对象,复合对象和集合转移到平板分配器。 而且如果前两类对象没有遇到严重的困难(复合对象简化为简单的对象),那么在翻译集合时,我们会遇到严重的困难。
- std ::列表
- 性病:: deque
- 性病::矢量
- std ::字符串
- std ::地图
- std ::无序地图
使用平板分布时的主要限制之一是不同类型的对象的数量不应太大(它越小越好)。 在这种情况下,某些集合很可能属于平板分配器的概念,而有些则可能没有。
对于std :: list slab,分配器工作得很好。 该集合是使用链表在内部实现的,链表的每个元素都有固定的大小。 因此,将新数据添加到平板分布中的std :: list时,不会出现新类型的对象。 满足上述条件! std :: map的布置与此类似。 唯一的区别是,它内部不是链接列表,而是树。
在std :: deque的情况下,情况变得更加复杂。 该集合是通过包含块的指针的连续内存块实现的。 尽管这些块非常准确,但std :: deque的行为与std :: list相同,但是当它们结束时,将重新分配此相同的内存块。 从平板分配器的角度来看,每个内存重新分配都是一个具有新类型的对象。 添加到集合中的对象数量直接取决于用户,并且可能无法控制地增长。 这种情况是不可接受的,因此我们在可能的地方初步限制了std :: deque的大小,或者首选了std :: list。
如果我们采用std :: vector和std :: string,那么它们仍然更加复杂。 这些集合的实现与std :: deque有点类似,不同之处在于它们的连续内存块增长得更快。 我们将std :: vector和std :: string替换为std :: deque,最坏的情况下替换为std :: list。 是的,我们在功能上甚至在性能上都失去了一些东西,但这对最终画面的影响远不及针对所有一切进行的优化。
我们对std :: unordered_map做了完全相同的事情,放弃了它,转而通过std :: deque实现的自写的variti :: flat_map。 同时,我们只是将常用的键缓存在单独的变量中,例如,与nginx中的http请求标头一样。
结论
完成了将服务器会话和客户端会话完全转移到平板分配器后,我们将处理一组事务所花费的时间减少了一半以上。
放大器(coldslab)的屏幕截图:
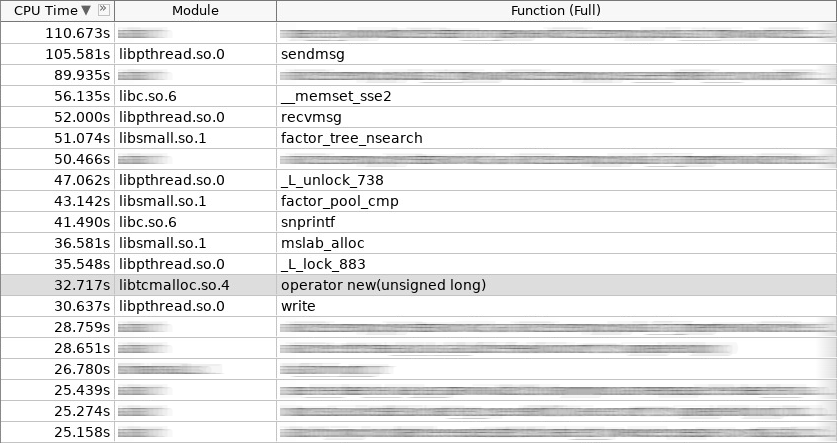
在屏幕截图中,new操作员需要32秒,而delete操作员需要24秒。 到这个时候,添加了其他处理堆的功能:smalloc-21秒,mslab_alloc-37秒,smfree-8秒,mslab_free-21秒。 总计143秒和161秒。
但是,这些测量是在启动服务后立即进行的,而没有初始化slab分发中的缓存。 从yandex坦克反复射击后,整体情况有所改善。
放大器(hotslab)的屏幕截图:
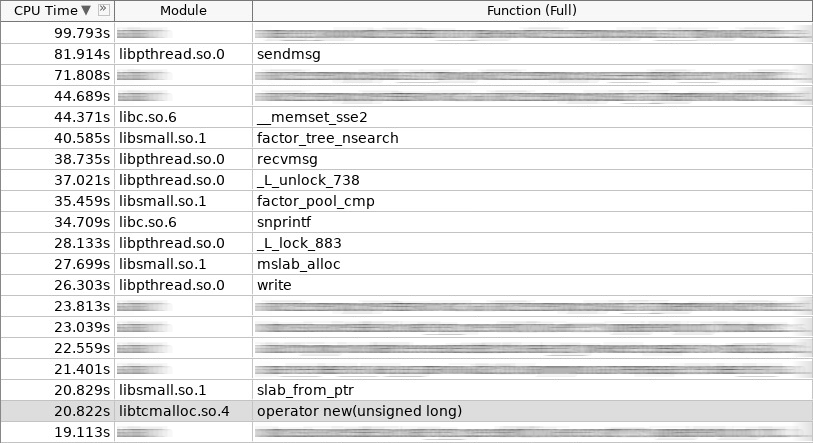
在屏幕快照中,新操作员工作20秒,smalloc-16秒,mslab_alloc-27秒,操作员删除-16秒,smfree-7秒,mslab_free-17秒。 总计103秒对161秒。
测量表:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
在现实生活中,结果应该更好,因为平板分配器不仅解决了长内存分配和释放的问题,而且还减少了碎片。 如果没有平板,随着时间的推移,new操作员和delete操作员的操作只会减慢速度。 对于平板-它将始终保持在同一水平。
如我们所见,平板分配器成功解决了常用对象的内存分配问题。 如果频繁创建和删除对象的问题与您有关,请注意这些问题。 但是不要忘记它们对应用程序体系结构的限制! 并非所有复杂对象都可以简单地放置在平板分布中。 有时候你不得不放弃很多! 嗯,应用程序的体系结构越复杂,就越有必要在多线程方面更加频繁地将对象返回到正确的缓存。 考虑到平板分配器的使用,立即制定应用程序体系结构可能很简单,但是当您决定在后期集成它们时,肯定会造成困难。
应用程式
在此处查看源代码!