在
上一篇文章中,我们讨论了预测时间序列。 逻辑上的延续将是有关识别异常的文章。
申请书
异常检测用于以下领域:
1)设备故障的预测
因此,在2010年,伊朗的离心机受到了Stuxnet病毒的攻击,该病毒将设备设置为最佳模式,并由于加速磨损而使部分设备瘫痪。
如果在设备上使用异常搜索算法,则可以避免出现故障情况。

在设备运行中寻找异常不仅用于核工业,而且还用于冶金和飞机涡轮的运行。 在无法预测故障的情况下,使用预测诊断比可能造成的损失便宜的其他地区。
2)预测欺诈
如果您在波多利斯克使用的卡在阿尔巴尼亚已被提取,则可能需要进一步检查交易。
3)识别异常的消费者模式
如果某些客户表现出异常行为,则可能是您没有意识到的问题。
4)识别异常需求和负载
如果快速消费品商店的销售额已降至预测置信区间的边界以下,则应查找发生这种情况的原因。
异常检测方法
1)一类一类支持向量机的支持向量的方法
当训练集中的数据服从正态分布,而测试集中包含异常时,则适用。
单类支持向量法在原点周围构造一个非线性曲面。 可以设置截止边界,该边界被认为是异常数据。
根据我们DATA4团队的经验,一类SVM是解决异常搜索问题的最常用算法。

2)隔离林方法-隔离林
采用“随机”方法建造树木时,排放会在早期(在树木的浅深度)落入树叶。 排放更容易“隔离”。 在算法的第一次迭代中提取异常值。

3)椭圆包络和统计方法
在数据正常分发时使用。 测量值越接近混合分布的尾部,该值越反常。
其他统计方法可以归于此类。

 图片来自dyakonov.org
图片来自dyakonov.org4)公制方法
方法包括算法,例如k个最近邻居,第k个最近邻居,ABOD(基于角度的离群值检测)或LOF(局部离群值因子)。
如果符号中的值之间的距离相等或已标准化(以免测量鹦鹉的蟒蛇),则适用。
k个最近邻的算法表明,正常值位于多维空间的某个区域中,到异常的距离将大于到分离的超平面的距离。
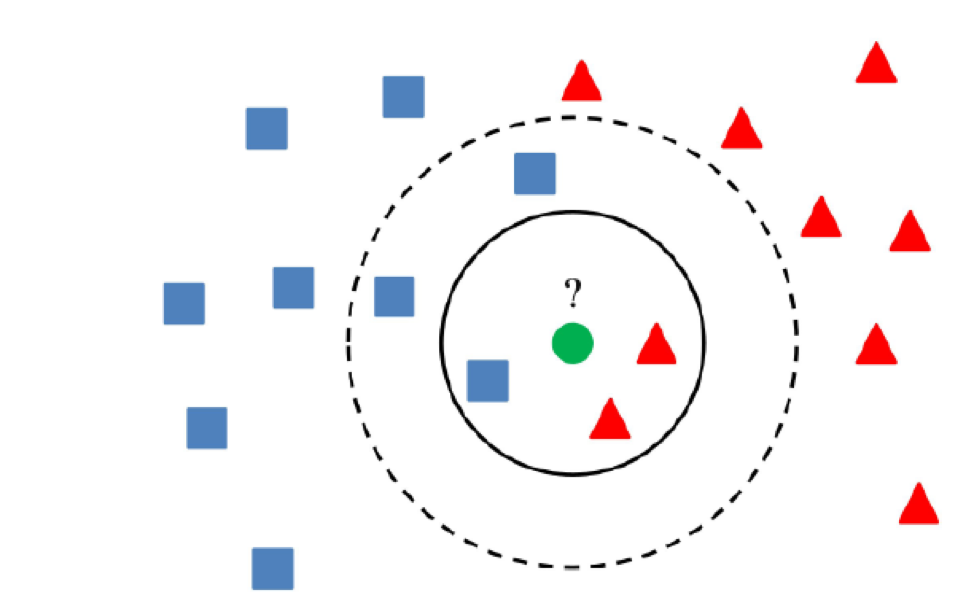
5)聚类方法
聚类方法的本质是,如果该值与聚类中心的距离大于某个距离,则该值可以视为异常。
最主要的是使用一种可以正确聚类数据的算法,具体取决于特定任务。
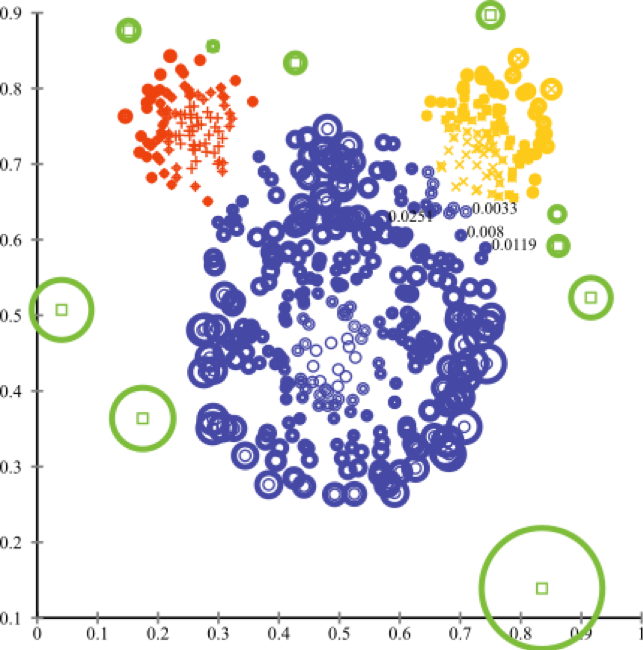
6)主成分法
适用于突出显示方差变化最大的区域。
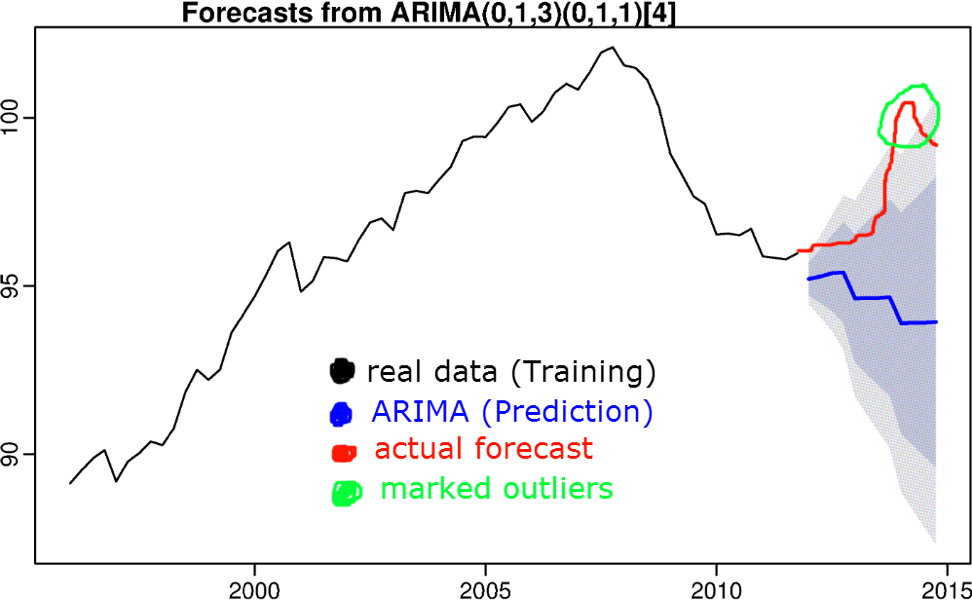
7)基于时间序列预测的算法
想法是,如果将某个值从预测置信区间中剔除,则该值被视为异常。 三重抗锯齿,S(ARIMA),增强等算法可用于预测时间序列。
时间序列预测算法在上一篇文章中进行了讨论。
8)与老师一起训练(回归,分类)
如果数据允许,我们使用从线性回归到递归网络的算法。 我们测量预测值与实际值之间的差异,并得出多少数据超出标准的结论。 该算法必须具有足够的泛化能力,并且训练样本不得包含异常值,这一点很重要。
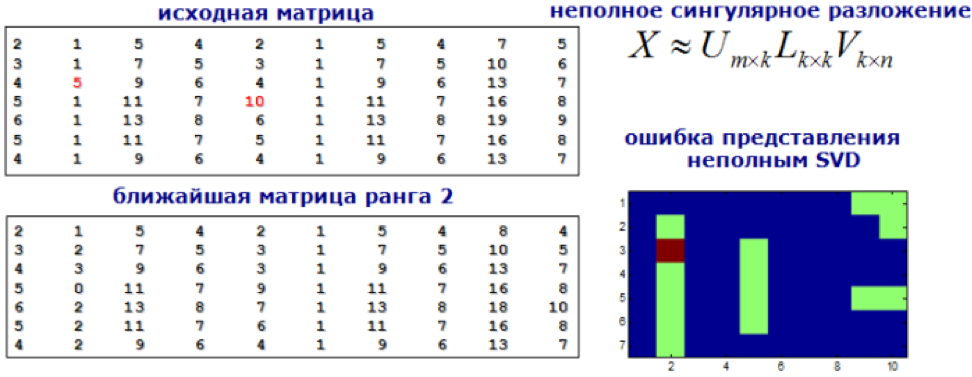
9)模型测试
我们将搜索异常问题作为搜索建议的任务。 我们使用SVD或因子分解机分解特征矩阵,并且新矩阵中的值与原始值明显不同,这被认为是异常的。
 图片来自dyakonov.org
图片来自dyakonov.org结论
在本文中,我们研究了检测异常的基本方法。
寻找异常可以在许多方面称为艺术。 没有理想的算法或方法可以解决所有问题。 大多数情况下,使用一组方法来解决特定情况。 使用支持向量的单类方法,隔离森林,度量和聚类方法以及主要成分和预测时间序列来搜索异常。
如果您知道其他方法,请在本文的评论部分中撰写有关它们的文章。