开发人员问他的DBA或企业所有者(一个PostgreSQL顾问)的经典问题几乎总是一样:
“为什么查询在数据库上运行这么长时间?”传统原因集:
- 低效算法
当您决定加入几条CTE进行几万条记录时 - 不相关的统计
如果表中数据的实际分配与上次ANALYZE收集的数据已经有很大不同 - 按资源分类
而且已经没有足够的CPU专用计算能力,不断抽取GB的内存,或者磁盘无法满足所有数据库“愿望清单”的要求 - 阻止竞争过程
而且,如果锁很难捕获和分析,那么对于其他所有情况,我们都需要
一个查询计划 ,可以使用
EXPLAIN运算符 (
当然,更好的是立即使用EXPLAIN(ANALYZE,BUFFERS)... )或
auto_explain模块来获取
查询计划 。
但是,正如同一文档中所述,
“了解计划是一门艺术,要掌握它,您需要一些经验,...”
但是,如果使用正确的工具,您可以不用它!
查询计划通常是什么样的? 像这样:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
或像这样:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
但是要阅读带有“从工作表中”的文本的计划是非常困难和心爱的:
- 节点显示子树资源的总和
也就是说,要了解执行特定节点所花费的时间,或者确切地说是从表中读取的数据从磁盘中获取了多少数据,您需要以某种方式从另一个磁盘中减去一个磁盘 - 节点时间必须乘以循环
是的,减法并不是需要“脑子里”进行的最困难的操作-毕竟,指示的运行时间是一个节点执行的平均值,并且可能有数百个 - 好吧,所有这些加在一起使得很难回答主要问题-那么谁是“最薄弱的环节” ?
当我们试图向数百名开发人员解释所有这些内容时,我们意识到从外部看起来像这样:

这意味着我们需要...
仪器仪表
在其中,我们试图收集所有根据计划提供帮助的关键机制,并要求他们理解“谁应该受到指责和做什么”。 好吧,与社区分享您的一些经验。
见面并使用
-explain.tensor.ru明确计划
看起来像这样的计划容易理解吗?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
不完全是
但是像这样,
以缩写形式 ,当关键指标分开时-它已经更加清楚了:
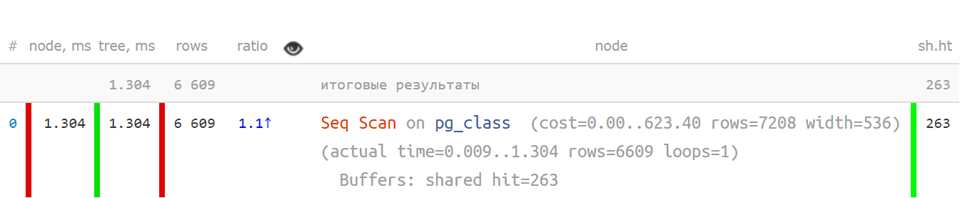
但是,如果计划更加复杂,那么按节点
分配饼图时间将可以解决:
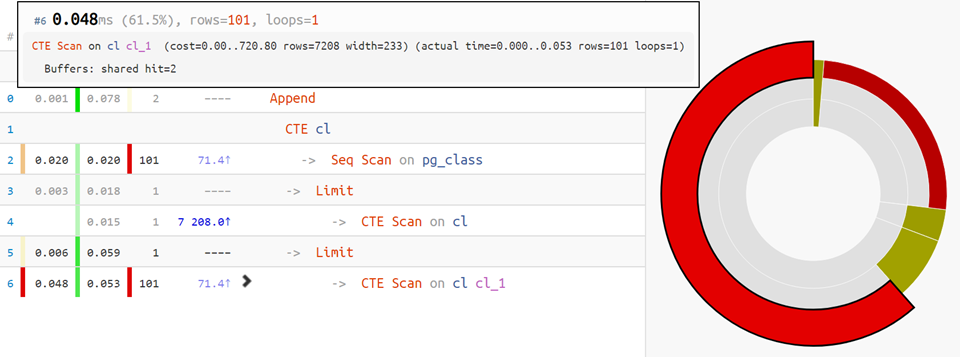
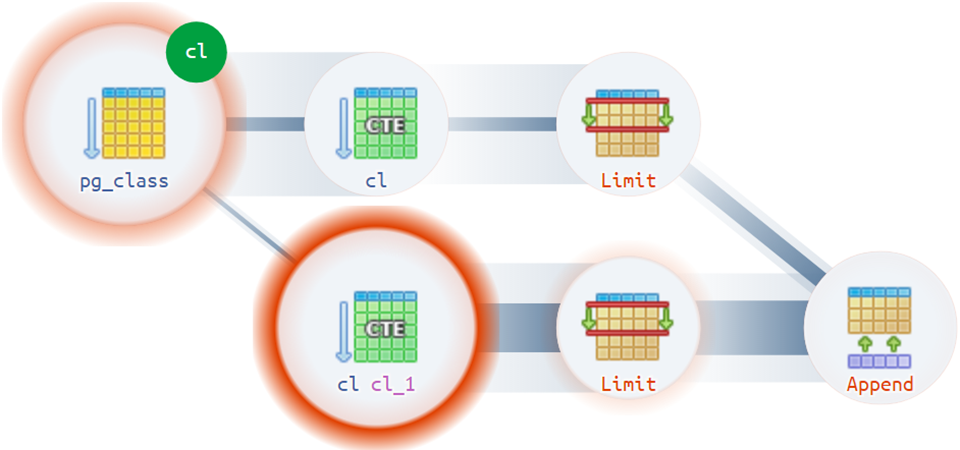
好吧,对于最困难的选择,
执行图急于提供帮助:
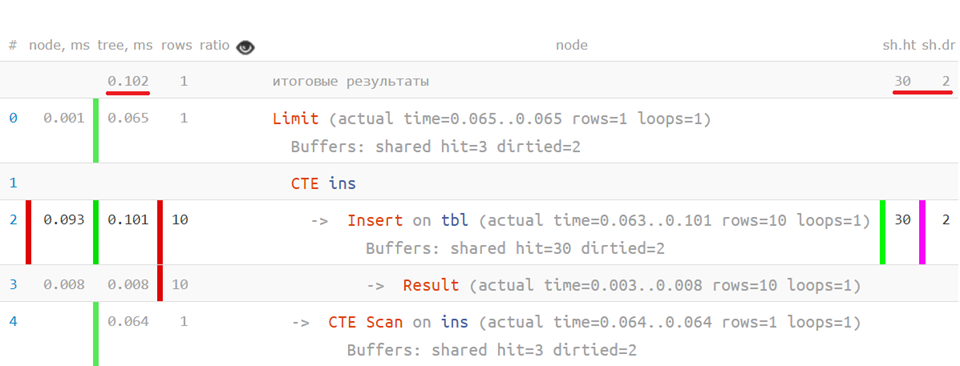
例如,在一个计划可以具有多个实际根的情况下,存在非常平凡的情况:
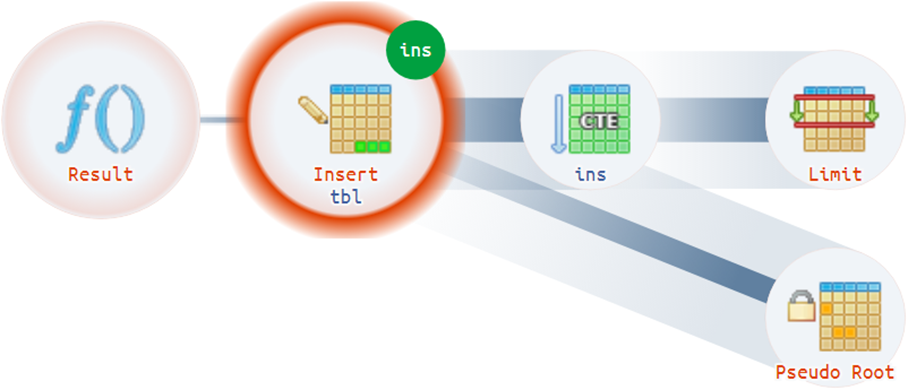
结构技巧
好吧,如果计划的整个结构及其痛点已经摆好并可以看到,为什么不向开发人员突出显示并用“俄语”进行解释?

我们已经收集了几十个这样的推荐模板。
查询分析器
现在,如果将原始查询放在经过分析的计划上,则可以看到每个操作员花费了多少时间-像这样:
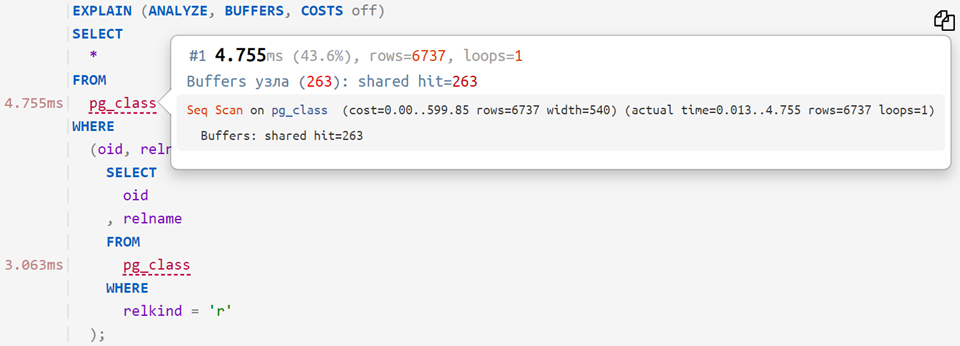
...甚至是这样:

请求中的参数替换
如果您不仅将请求附加到计划,还将其参数“附加”到日志的DETAIL行,则可以在以下选项之一中另外复制它:
- 用请求中的值替换
在其基础上直接执行和进一步分析
SELECT 'const', 'param'::text;
- 通过PREPARE / EXECUTE进行值替换
当参数部分可以忽略时(例如,在分区表上工作时)模拟调度程序的工作
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
计划存档
插入,分析并与同事共享! 这些计划将保留在存档中,您以后可以返回它们:
explain.tensor.ru/archive但是,如果您不希望其他人看到您的计划,请不要忘记选中“不要在存档中发布”复选框。
在以下文章中,我将讨论在计划分析中出现的困难和解决方案。