你好
碰巧您正在看电影,而在您的脑海中只有一个问题-“我再次获得点击诱饵吗?” 我们将解决此问题,并且仅观看合适的电影。 我建议稍微试验一下数据并编写一个简单的神经网络来评估影片。
我们的实验基于情感分析技术来确定受众对产品的喜好。 作为数据,我们获取了有关IMDb电影的用户评论数据集。 Google Colab开发环境通过免费访问GPU(NVidia Tesla K80),使您可以快速训练神经网络。
我使用Keras库,在该库的帮助下,我将建立一个通用模型来解决类似的机器学习问题。 我将需要后端TensorFlow(Colab 1.15.0中的默认版本),因此只需升级到2.0.0。
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
接下来,我们导入用于数据预处理和模型构建的所有必要模块。 在先前的文章中,重点是库,您可以在此处查看。
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
解析IMDb数据
IMDb数据集包含来自标记为肯定(1)和否定(0)的用户的50,000条电影评论。
- 评论是经过预处理的,每个评论都由一系列以整数形式的单词索引编码
- 评论中的单词根据其在数据集中的总频率进行索引。 例如,整数“ 2”编码第二个最常用的单词
- 50,000条评论分为两组:用于培训的25,000条和用于测试的25,000条。
下载Keras内置的数据集。 由于数据按50-50的比例分为训练和测试,因此我将它们组合起来,以便以后可以将它们除以80-20。
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
数据探索
让我们看看我们正在使用什么。
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

您会看到所有数据都属于两类:0或1,代表了评论的气氛。 整个数据集包含9998个唯一词,平均评论大小为234个词,标准差为173。
让我们看一下该数据集中的第一个评论,该评论被标记为肯定。
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

资料准备
现在该准备数据了。 我们需要对每个调查进行矢量化处理,并用零填充,以使矢量正好包含10,000个数字。 这意味着每个少于10,000个单词的评论都用零填充。 我这样做是因为最大的概观几乎是相同的大小,并且神经网络的每个输入元素都应具有相同的大小。 您还需要将变量转换为浮点类型。
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
接下来,我按照约定4将数据集分为训练和测试数据:1。
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
创建和训练模型
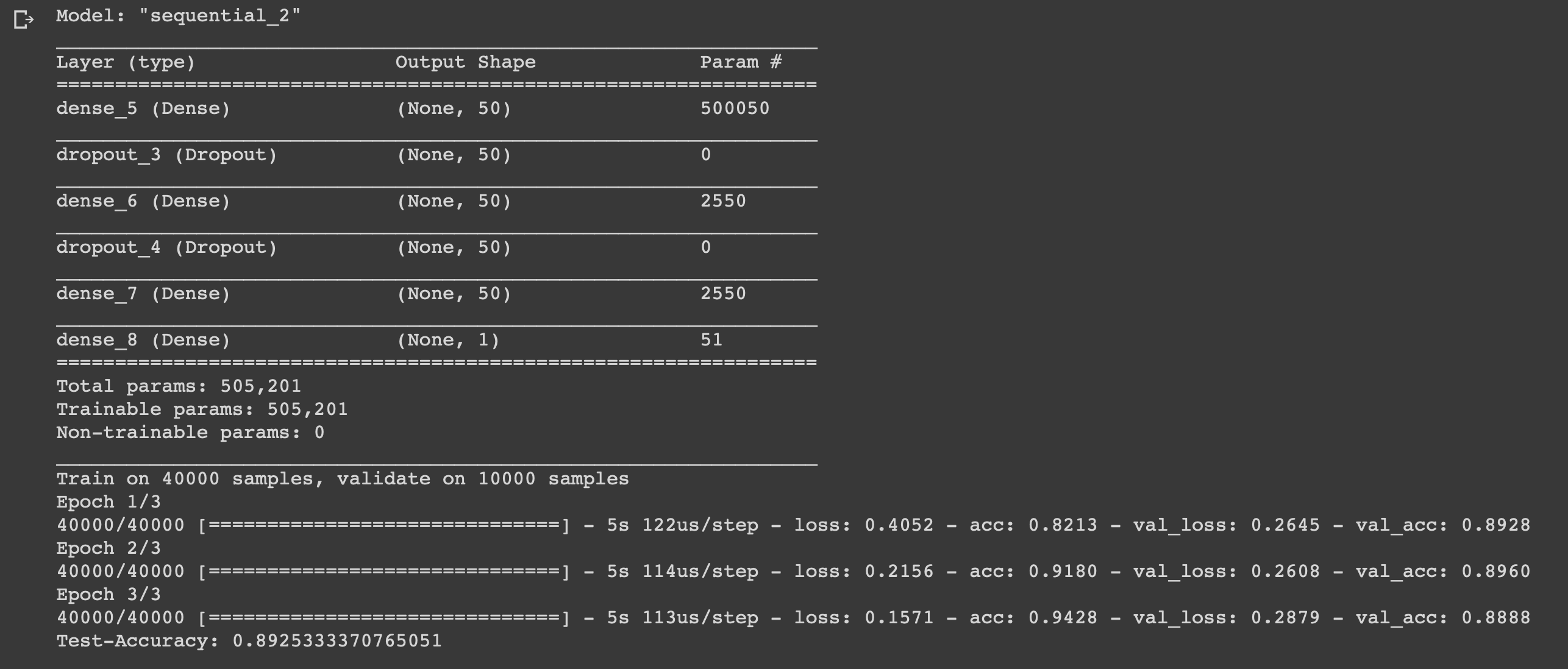
事情很小,只剩下编写模型并对其进行训练。 首先选择一种类型。 Keras中提供了两种类型的模型:顺序模型和功能性API。 然后,您需要添加输入,隐藏和输出层。
为了防止过度拟合,我们将在它们之间使用一个“ dropout”,在每一层上,我们都使用“ dense”功能将各层之间完全连接起来。 在隐藏层中,我们将使用“ relu”激活功能,这几乎总是会产生令人满意的结果。 在输出层上,我们使用S型函数来对0到1范围内的值进行重新规范化。
我使用亚当优化程序,它将在训练过程中改变权重。
我们使用二进制交叉熵作为损失函数,并使用准确性作为度量标准。
现在您可以训练我们的模型了。 我们将以500个批次的规模进行此操作,并且只有三个时代,因为据透露,如果模型训练时间更长,模型就会开始进行训练。
model = models.Sequential()
结论
我们创建了一个简单的六层神经网络,该网络可以以0.89的精度计算电影制作人的情绪。 当然,观看很酷的电影根本不需要编写神经网络,但这只是如何使用数据并从中受益的另一个示例,因为您需要它。 由于神经网络的结构简单,更改某些参数,因此神经网络是通用的,您可以将其适应于完全不同的任务。
随时在评论中写下您的想法。