
设计流分析和流数据处理系统具有其自身的细微差别,其自身的问题和其自己的技术堆栈。 我们在
数据工程师课程启动前夕的下一堂
公开课中谈到了这一点。
在网络研讨会上讨论了:
- 需要流处理时;
- SPOD中包含哪些元素,我们可以使用哪些工具来实现这些元素;
- 如何构建自己的点击流分析系统。
讲师
-MaximaTelecom的高级数据工程师
Yegor Mateshuk。
什么时候需要流式传输? 流与批处理
首先,我们需要弄清楚何时需要流处理以及何时进行批处理。 让我们解释一下这些方法的优点和缺点。
因此,批处理的缺点:- 数据延迟交付。 由于我们有一定的计算时间,因此在此期间我们总是落后于实时。 迭代次数越多,我们越落后。 因此,我们得到了时间延迟,这在某些情况下很关键。
- 在铁上产生峰值负载。 如果我们以批处理模式进行大量计算,则在周期结束时(天,周,月),我们将出现峰值负载,因为您需要计算很多事情。 这会导致什么? 首先,我们开始反对限制,正如您所知,这些限制不是无限的。 结果,系统会定期运行到极限,这通常会导致故障。 其次,由于所有这些工作都是同时开始的,因此它们竞争激烈且计算速度很慢,也就是说,您不能指望获得快速的结果。
但是批处理有其优点:- 高效率。 我们不会更深入,因为效率与压缩,框架,列格式的使用等有关。事实是,批处理(如果您取每单位时间的处理记录数会更有效);
- 易于开发和支持。 您可以根据需要通过测试和重新计数来处理数据的任何部分。
流数据处理(流)的优点:- 实时产生。 我们不等待任何时期的结束:一旦数据(即使是很小的数量)传给我们,我们可以立即对其进行处理并将其传递。 也就是说,根据定义,结果是实时的。
- 铁上的均匀负载。 显然存在每日周期等,但是,负载仍然全天分布,并且结果更加均匀和可预测。
流处理的主要缺点:- 开发和支持的复杂性。 首先,与批处理相比,测试,管理和检索数据要困难一些。 第二个困难(实际上,这是最基本的问题)与回滚有关。 如果工作无效,并且出现故障,则很难准确地捕获一切破裂的那一刻。 与批处理相比,解决问题将需要您更多的精力和资源。
因此,如果您在考虑
是否需要流 ,请自己回答以下问题:
- 您真的需要实时吗?
- 流媒体有很多吗?
- 失去一项记录至关重要吗?
让我们看
两个例子 :
例子1.零售库存分析:- 货物显示不实时更改;
- 数据通常以批处理方式交付;
- 信息丢失至关重要。
在此示例中,最好使用批处理。
示例2. Web门户的分析:- 分析速度决定了对问题的响应时间;
- 数据是实时的;
- 少量用户活动信息的丢失是可以接受的。
想象一下,分析反映了门户网站访问者使用您的产品的感觉。 例如,您推出了一个新版本,则需要在10-30分钟内了解是否一切正常,如果任何自定义功能已损坏。 假设“订单”按钮中的文本不见了-分析将使您能够快速响应订单数量的急剧下降,并且您会立即意识到需要回滚。
因此,在第二个示例中,最好使用流。
SPOD元素
数据处理工程师捕获,移动,交付,转换和存储这些数据(是的,数据存储也是一个活跃的过程!)。
因此,为了构建流数据处理系统(SPOD),我们将需要以下元素:
- 数据加载器 (将数据传输到存储设备的手段);
- 数据交换总线 (并非总是需要,但由于需要一个实时交换数据的系统,因此无法进行流传输);
- 数据存储 (没有它);
- ETL引擎 (需要进行各种过滤,排序和其他操作);
- BI (显示结果);
- 协调器 (将整个过程链接在一起,组织多阶段数据处理)。
在我们的案例中,我们将考虑最简单的情况,仅关注前三个要素。
数据流处理工具
对于
数据加载器,我们有几个“候选人”:
阿帕奇水槽
我们将讨论的第一个是
Apache Flume ,它是一种在不同源和存储库之间传输数据的工具。

优点:
缺点:
至于它的配置,它看起来像这样:

上面,我们创建了一个简单的通道,该通道位于端口上,从那里获取数据并简单地记录下来。 原则上来说,描述一个进程仍然很正常,但是当您拥有数十个这样的进程时,配置文件就会变成地狱。 有人添加了一些可视配置器,但是如果有一些使之开箱即用的工具,为什么还要麻烦呢? 例如,相同的NiFi和StreamSet。
Apache Nifi
实际上,它的作用与Flume相同,但具有可视界面,这是一个很大的优点,尤其是在有很多流程的情况下。
关于NiFi的一些事实
- 最初由国家安全局开发;
- 现在支持和开发Hortonworks。
- Hortonworks的HDF的一部分;
- 具有用于从设备收集数据的特殊版本的MiNiFi。
系统看起来像这样:
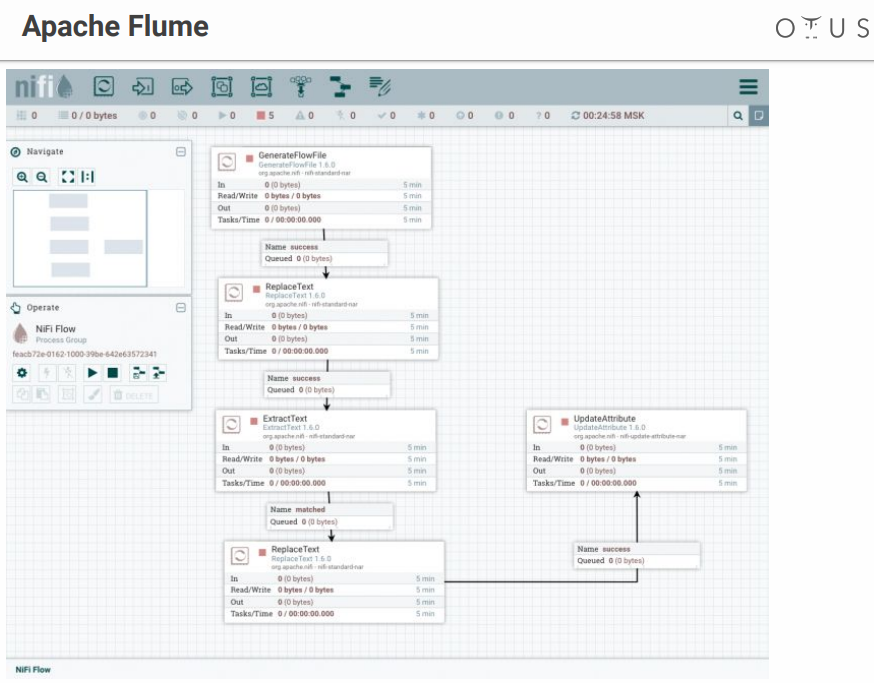
我们有一个创造力和数据处理阶段的领域。 所有可能的系统都有许多连接器,等等。
流集
它也是具有可视界面的数据流控制系统。 它是由Cloudera的人开发的,可以很容易地作为Parcel安装在CDH上,它具有SDC Edge的特殊版本,可以从设备中收集数据。
由两个部分组成:
- SDC-执行直接数据处理的系统(免费);
- StreamSets控制中心-用于多个SDC的控制中心,具有用于开发支付线(付费)的其他功能。
看起来像这样:

令人不快的时刻-StreamSet包含免费和付费部分。
数据总线
现在让我们弄清楚我们将在哪里上传这些数据。 申请者:
Apache Kafka是最好的选择,但是如果您的公司中有RabbitMQ或NATS,并且您需要添加一些分析功能,那么从头开始部署Kafka不会很赚钱。
在所有其他情况下,Kafka是一个不错的选择。 实际上,它是具有水平扩展和巨大带宽的消息代理。 它完美地集成到用于处理数据的整个工具生态系统中,并且可以承受沉重的负担。 它具有通用接口,是我们数据处理的循环系统。
在内部,Kafka被划分为Topic(主题)-来自具有相同方案或至少具有相同用途的消息的某个单独的数据流。
要讨论下一个细微差别,您需要记住数据源可能会略有不同。 数据格式非常重要:

Apache Avro数据序列化格式值得特别提及。 系统使用JSON确定序列化为
紧凑二进制格式的数据结构(模式)。 因此,我们节省了大量数据,并且序列化/反序列化更便宜。
一切似乎都很好,但是由于我们需要在不同系统之间交换文件,因此存在带有电路的单独文件会带来问题。 看起来很简单,但是当您在不同部门工作时,另一端的人可能会有所改变并保持冷静,一切都会为您带来麻烦。
为了不将所有这些文件传输到闪存驱动器,软盘和洞穴画中,有一项特殊服务-架构注册表。 这是一项用于在从Kafka写入和读取的服务之间同步Avro方案的服务。

就卡夫卡而言,生产者是写数据的人,消费者是消耗(读取)数据的人。
数据仓库
挑战者(事实上,还有更多选择,但只有少数选择):
- HDFS +蜂巢
- Kudu +黑斑羚
- Clickhouse
在选择存储库之前,请记住什么是
幂等 。 维基百科说,幂等(拉丁幂同义+能力)-当对象或操作再次应用于对象时,其特性与第一个对象相同。 在我们的案例中,应该构建流处理的过程,以便在重新填充源数据时,结果保持正确。
如何在流媒体系统中
实现这一目标 :
- 标识唯一的ID(可以是复合ID)
- 使用此ID重复数据删除
HDFS + Hive存储
不提供 “开箱即用”流记录的
幂等性 ,因此我们具有:
Kudu是适用于分析查询的存储库,但具有主键用于重复数据删除。
Impala是此存储库(和其他几个存储库)的SQL接口。
至于ClickHouse,这是Yandex的分析数据库。 它的主要目的是在填充有大量原始数据的表上进行分析。 优点-有一个用于密钥重复数据删除的ReplacingMergeTree引擎(重复数据删除旨在节省空间,在某些情况下可以保留重复项,您需要考虑到
细微差别 )。
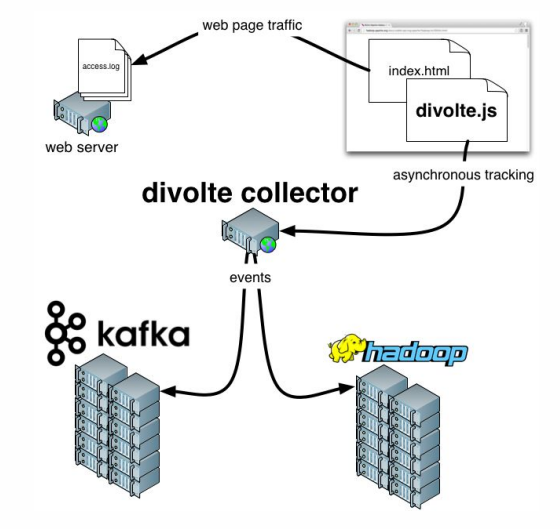
还有关于
Divolte的几句话。 如果您还记得的话,我们谈到了需要捕获一些数据的事实。 如果您需要快速,轻松地组织门户分析,那么Divolte是一项出色的服务,可通过JavaScript捕获网页上的用户事件。
实际例子
我们要做什么?
让我们尝试建立一个管道来实时收集Clickstream数据。
Clickstream是用户在您的网站上留下的虚拟足迹。 我们将使用Divolte捕获数据,并将其写入Kafka。

您需要Docker才能工作,还需要克隆
以下存储库 。 发生的所有事情都将在容器中启动。 为了一次一致地运行多个容器,将使用
docker-compose.yml 。 此外,还有一个
Dockerfile编译具有某些依赖项的StreamSet。
还有三个文件夹:
- clickhouse数据将被写入clickhouse数据
- 与StreamSet完全相同的爸爸( sdc-data ),系统可以在其中存储配置
- 第三个文件夹( 示例 )包括StreamSet的请求文件和管道配置文件

要开始,请输入以下命令:
docker-compose up
而且我们喜欢容器启动的缓慢但可靠的过程。 启动后,我们可以转到地址
http://本地主机:18630 /,然后立即触摸Divolte:

因此,我们拥有Divolte,该公司已经收到一些事件并将其记录在Kafka中。 让我们尝试使用StreamSets计算它们:
http://本地主机:18630 / (密码/登录名-admin / admin)。

为了不受影响,最好
导入 Pipeline并将其命名,例如
clickstream_pipeline 。 然后从示例文件夹中导入
clickstream.json 。 如果一切正常,
我们将看到以下图片 :

因此,我们创建了与Kafka的连接,注册了我们需要的Kafka,注册了我们感兴趣的主题,然后选择了我们感兴趣的字段,然后浪费了Kafka,注册了哪个Kafka和哪个主题。 区别在于,在一种情况下,数据格式为Avro,在第二种情况下仅为JSON。
让我们继续前进。 例如,我们可以
进行预览 ,以实时捕获来自Kafka的某些记录。 然后,我们将所有内容记下来。
启动后,我们会看到一系列事件飞向Kafka,并且实时发生:

现在,您可以在ClickHouse中为此数据创建存储库。 要使用ClickHouse,可以通过运行以下命令来使用简单的本机客户端:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
请注意,该行表示您要连接的网络。 并且,根据您使用存储库命名文件夹的方式,您的网络名称可能会有所不同。 通常,命令如下:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
可以使用以下命令查看网络列表:
docker network ls
好了,什么都没有了:
1.
首先,将我们的ClickHouse“签名”到Kafka ,“向他解释”我们在那里需要的数据格式:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
现在,我们将创建一个实际表 ,在其中放置最终数据:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
然后,我们将提供这两个表之间的关系 :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
现在,我们将选择必填字段 :
SELECT * FROM clickstream;
结果,从目标表中进行选择将为我们提供所需的结果。
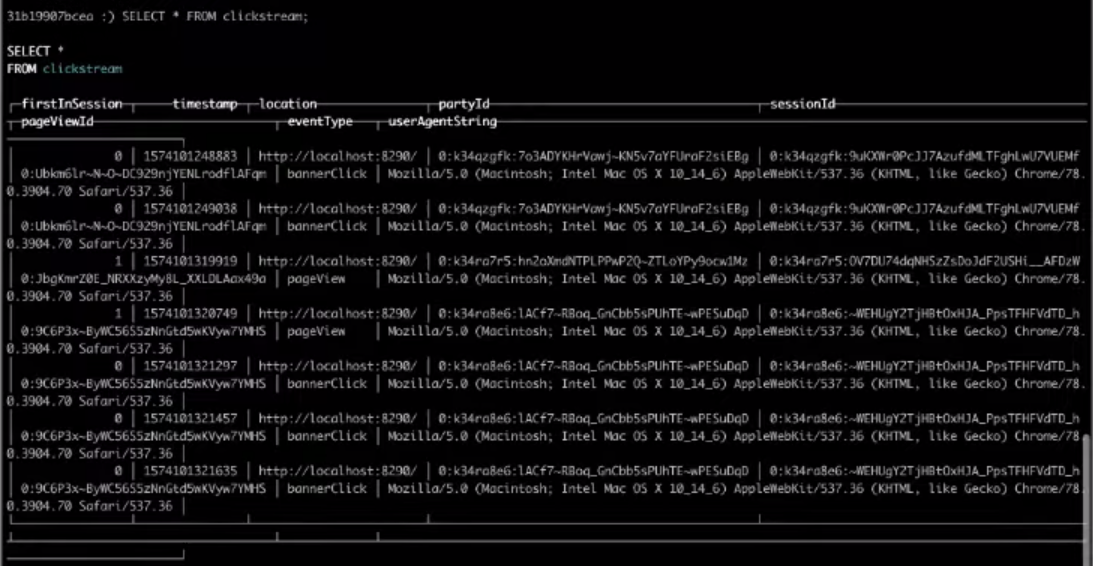
就是这样,这是您可以构建的最简单的Clickstream。 如果您想自己完成上述步骤,请
观看整个
视频 。