
机器学习的历史始于上世纪中叶。 那时,该技术更多地是科学研究和实验领域,强大的计算机为ML的实际应用提供了动力。
如今,机器学习已成为IT市场不可否认的趋势。 越来越多的来自不同行业的公司正在创建数据科学部门,以便利用机器学习在积累的数据中找到新的机会来增长和提高业务效率。 但是,尽管这些举措没有得到应有的回报。 据统计,每10例确诊病例中有8例未进入商业运作。
你们中的大多数人最有可能听到了这个笑话,“使机器学习更具生产力的最有效方法是PowerPoint幻灯片。” 不幸的是,这不是一个玩笑。 通常,整个过程看起来像这样:一个企业传输数据,并从商业系统下载一个商业案例。 数据科学家正在Jupiter Notebook中开发一种机器学习模型,将图形的屏幕快照放置在PowerPoint幻灯片上,然后发送给业务客户。 是否可以在管理决策中使用生成的幻灯片? 很有可能不是这样,因为预测数据很快就过时了,这段时间业务状况可能会发生严重变化。
为了克服所有障碍并将机器学习推向潮流,大多数公司投资于收集,存储和处理大量数据的基础架构-Data Lake。 当然,这是必要的步骤。 但是,从业务角度来看,这会发生什么变化? 是否有可能基于机器学习做出决策? 不可以,因为Data Lake与业务之间存在差距。 显然,为什么有86%的受访公司认为下一代业务应用程序应该配备机器学习功能。
我们SAP决定撰写一系列文章,介绍如何使用新的SAP Data Intelligence平台克服现有困难,并将诸如机器学习之类的强大工具应用于企业服务。 而且,如果您对此主题感兴趣,请继续阅读:)
首先,我将向您介绍任何业务案例“数据搜索和准备”的开发的第一个非常重要的阶段。 在随后的文章中,我们将考虑以下阶段:模型的开发和培训,详细与SAP和非SAP本地和云数据源集成,创建使用模型的服务,将业务案例转化为生产性,监控以及业务案例的运作”等等。
基于机器学习的业务案例开发。 搜索和准备数据。让我们看一下创建业务案例的过程(图1)。
最初,创意通常是由企业制定的。 通常,他很乐意这样做,因为他的明确目标是在整个企业的数字化转型中将职能数字化。 为了收集,评估和确定想法的优先级,您可以使用例如SAP创新管理。
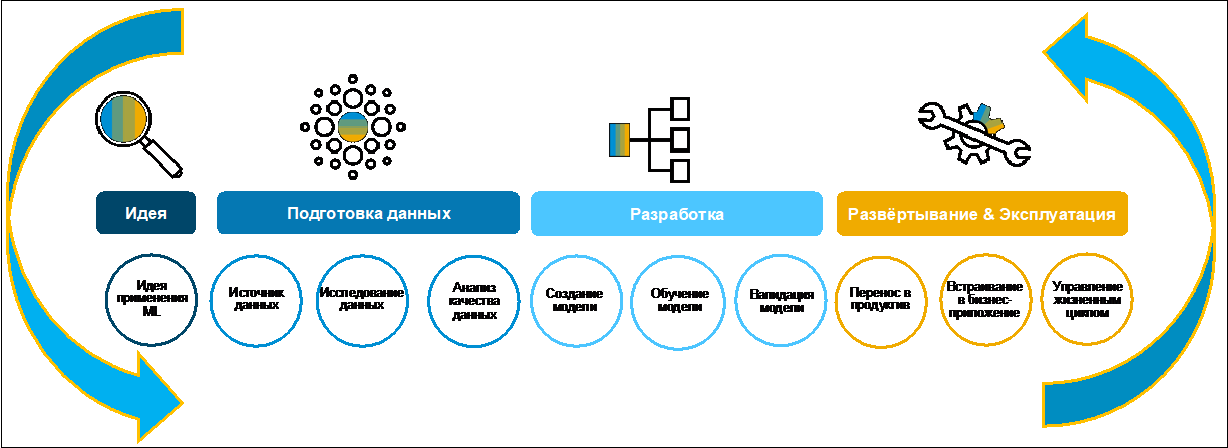 图1
图1在数据搜索和准备的第一阶段,有必要了解它们是否完全存在于业务案例的开发中,它们的存储位置,它们的格式和质量。 现代典型景观包括许多异构系统。 数据可以在不同的应用程序中复制。 找到正确的信息可能需要很多时间。 为此,在SAP Data Intelligence中,使用元数据目录已大大简化了此任务。 让我们看看它是什么以及如何使用它。
元数据目录要使用元数据目录,必须将源系统连接到Data Intelligence。 数据智能的数据源可以是本地系统SAP ERP,BW,Marketing ...和非SAP MES,Oracle,MS SQL,DB2,Hadoop和许多其他资源,以及云服务Amazon,Azzure,Google SCP。 要连接到数据源,您需要有关系统位置以及在这些系统中创建的专门用于与SAP Data Intelligence集成的技术用户的信息。 图2显示了SAP Data Intelligence中定制数据环境的示例。
 图2
图2
在SAP Data Intelligence元数据目录中配置后,就可以查看存储在连接的系统上的信息。 图3显示了连接到SAP Data Intelligence的Hadoop的DAT263文件夹中的文件列表。
 图3
图3如果找到实现业务案例所必需的数据,那么让我们使用发布功能将数据对象添加到目录中。 我将使用autos_history.csv文件,其中包含二手车销售统计信息。 在图4中,您将看到如何将数据对象及其元数据发布到目录,以便将来快速访问。
 图4
图4您可以根据业务案例需求自定义目录结构和层次结构级别。 例如,在我的Habr_demo文件夹中,将收集有关本文需要的对象的所有元数据。
生成的元数据目录是对业务案例数据的快速访问。 我将在SAP Data Intelligence元数据目录中的文件夹对象上进行性能分析和质量分析。 元数据目录的初始屏幕如图2所示。 5,
 图5
图5这是我在Habr_demo文件夹中发布的数据对象(图6)
 图6
图6另外,为了改善和加快搜索速度,我们可以在数据对象的目录中分配标签或标签,如图2所示。 7
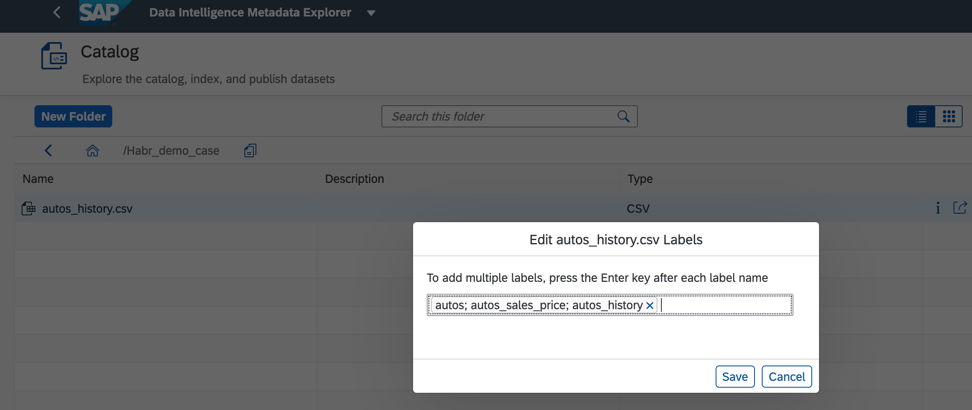 图7
图7元数据目录使您可以按对象的名称,字段和标签搜索对象。 单个数据对象可以具有多个标签。 如果多个开发人员一起使用,这将很方便,每个人都可以为其业务案例分配标签,并从中快速找到所需的一切。 同样,标签可以突出显示个人和机密数据,应严格限制对其的访问。
在所考虑的数据集中,通过标签和字段名称进行搜索可以快速得出结果(图8)。 同意,这非常方便!
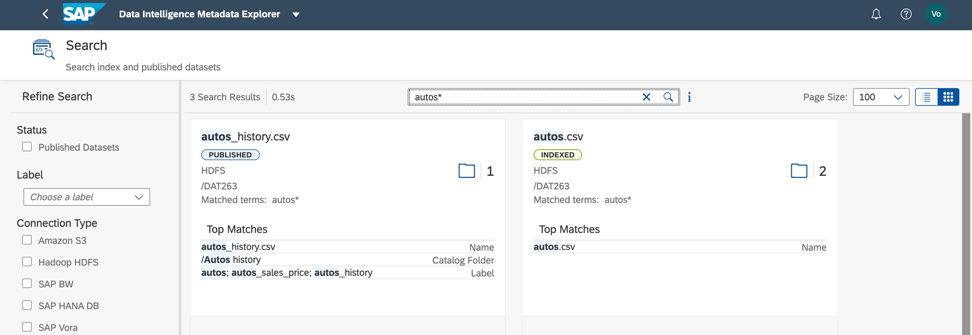 图8
图8接下来,我们需要了解如何填充文件。 为此,我们可以分析数据。 我们还从元数据目录和数据对象的上下文菜单开始该过程(图9)。
 图9
图9在配置过程中,元数据目录将读取文件的内容,分析其结构并填充。 可在情况说明书中找到结果(图10)。
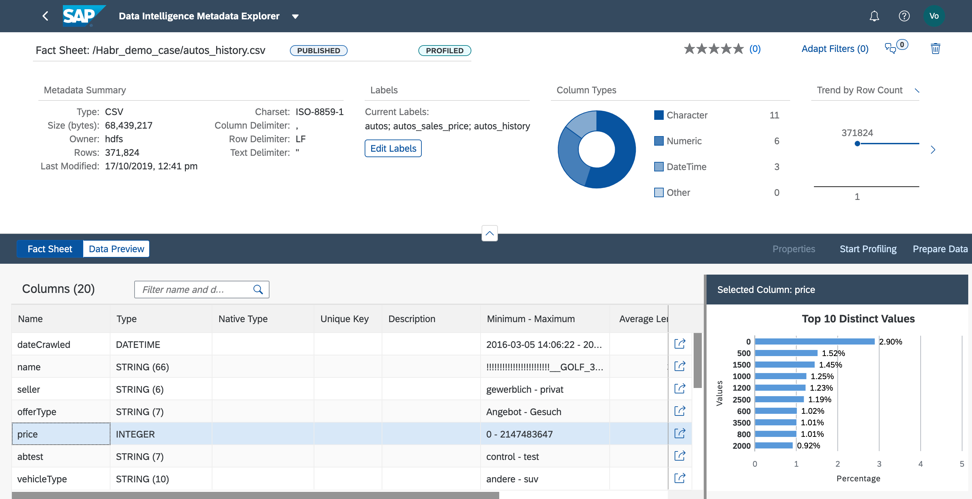 图10
图10
在情况说明书中,我们看到文件结构和有关填写字段的信息。
1.作为分析的结果,在选定的文件中,我们显示:卖方字段在所有行中都有一个值I。 这意味着我们可以从数据集中删除该字段,以免在构建模型时不使用机器学习,因为它不会影响预测结果(图11)。
 图11。2.
图11。2.通过分析价格列,我们了解到我们拥有的数据中几乎有3%包含零价格。 为了在我们的业务案例中使用该文件,我们必须使用该产品的实际值或平均值填写价格,或者必须从文件中删除价格为零的行(图12)。
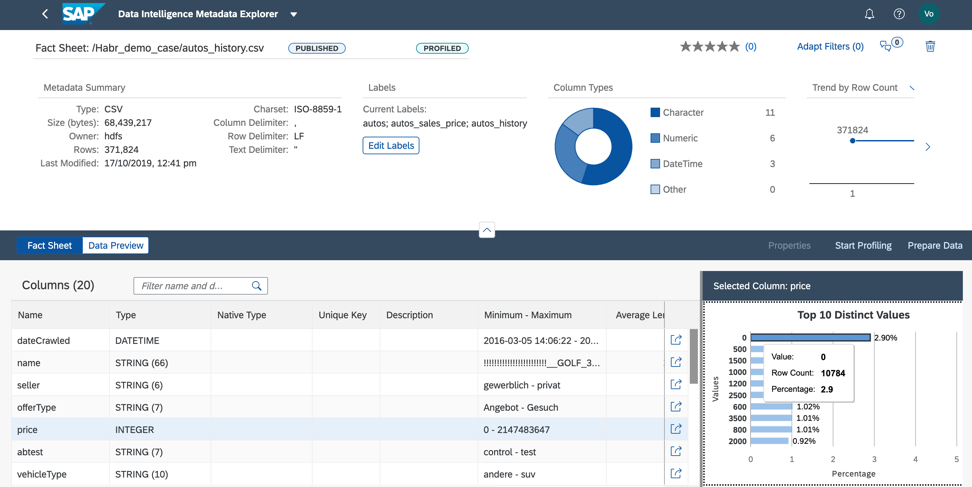 图12。
图12。我们可以通过两种方式进行数据预处理:在元数据目录中或直接在Jupiter Notebook中。 工具的选择取决于谁负责业务案例数据的预处理。 如果是分析师,那么我建议使用可视数据准备界面,该界面在元数据目录中可用。 如果数据科学家从事数据准备工作,那么选择肯定应该选择Jupiter Notebook,它也已集成到Data Intelligence中。
3.模型字段的值分布均匀,这将使我们能够定性地训练模型,如图13所示。
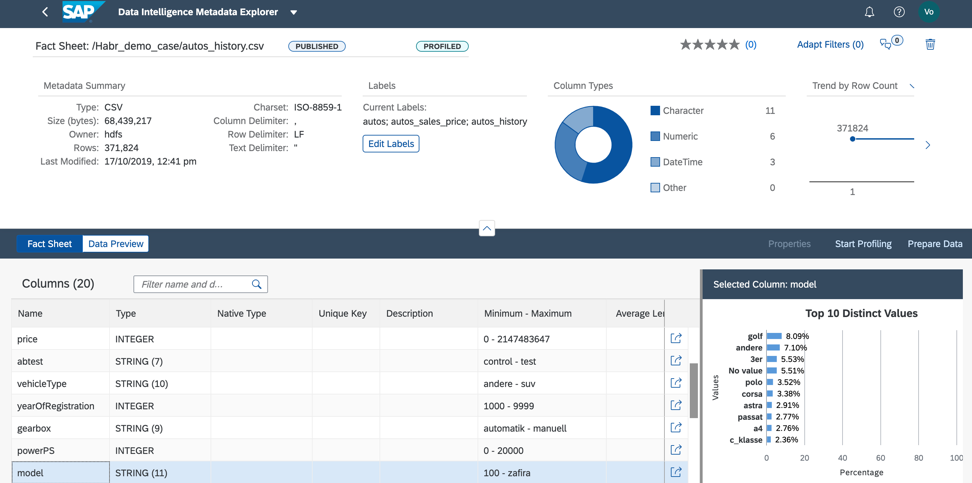 图13。
图13。
现在,我们了解了实现业务案例所需的数据对象,填充了哪些数据对象,使用该数据实现,训练和测试模型必须执行的预处理。 但是在开始预处理之前,您需要检查数据的质量。 为此,可在“元数据目录”中使用业务规则。 我马上注意到,目前业务规则的功能有很多严重的限制。 因此,我建议在Jupiter Notebook中或多或少地进行复杂的数据预处理,该处理器已集成到SAP Data Intelligence中。
因此,让我们回到我们的数据集,并验证价格字段中的最小和最大阈值是否符合要求,以便我们可以粗略估计数据是异常还是错误值。 正如您已经了解的那样,业务规则也在Metadata Catalog中进行配置,如图2所示。 14a,c。 规则和数据的关系在规则簿(Rulebook)中进行配置。 这使您可以使用相同的规则来验证不同的数据。
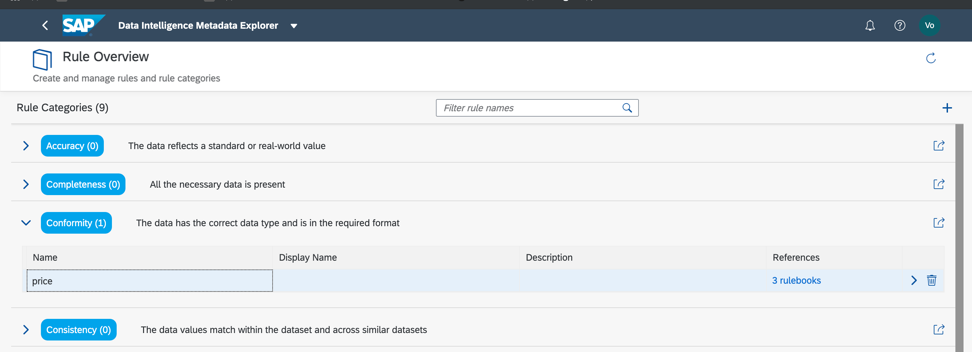 图14 a。
图14 a。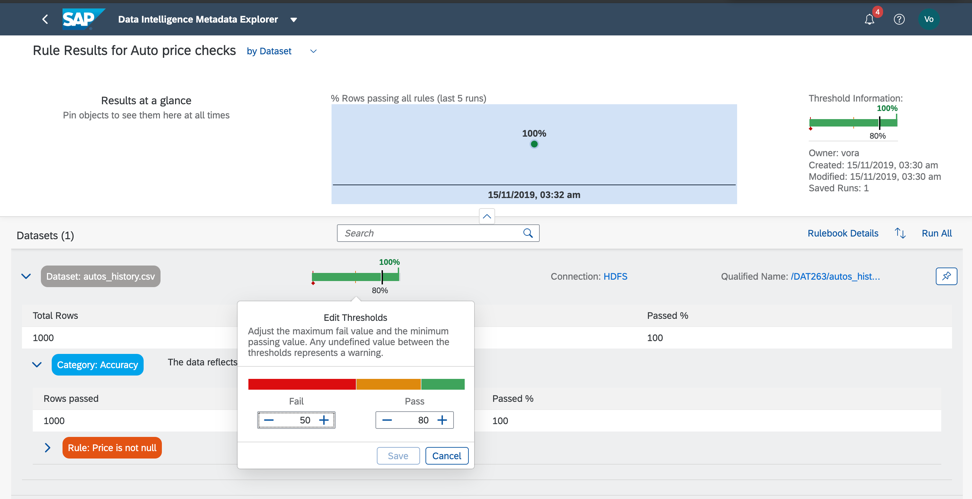 图14 c。
图14 c。因此,正如我们所看到的,我们的数据是100%正确的。
但这并不总是会发生。 如果75%的记录满足规则中指定的条件,则可以认为数据是正确的。
可以提高数据质量,最重要的是,这可以在会计系统中完成。 为此,公司组织了数据管理过程。 另一个可能的原因是数据质量标准定义不正确。
总而言之,我想谈一谈元数据目录的优缺点。
我认为它具有3个主要优点:
- 简化数据访问。
- 加快数据检索。
- 方便,直观的界面,不仅适用于IT或数据科学专家的高级人员,而且还适用于实施和进一步支持业务案例的业务。
当然,还有缺陷。 它们很明显。 当前,SAP Data Intelligence中元数据目录的功能处于基本级别。 开始使用可能就足够了,但是该功能不能完全满足数据管理解决方案的所有要求。
这是SAP Data Intelligence的新颖性和复杂性的结果。 SAP投入了大量资源来改进此解决方案。 这激发了人们的信心,即在不久的将来,元数据目录将成为强大的数据管理工具。 无需编程即可创建复杂的业务规则的机会。 也可以集成SAP Information Steward和SAP Data Hub,以全面覆盖数据管理主题。
在下一篇文章中,我们将讨论“在SAP Data Intelligence中开发和训练模型”阶段。 一切最有趣!
由SAP CIS专家Elena Ganchenko发布