可能在白俄罗斯每个有无轨电车的城市中,都有Telegram上的VK组或聊天室,人们可以在其中跟踪控制器的位置。 这样做主要是为了不支付旅行费用和免费旅行,尽管对团体的描述几乎总是包含“旅行费用”的附言。
在VC中,通常如下所示:
一个典型的注释如下:
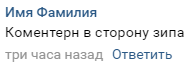
结构非常简单。 在注释中,有当前正在注意到控制器的站点的名称,还有它们站着的方向:
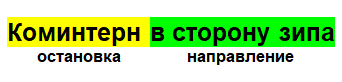
结果,注释是一个带有停止,时间和日期以及唯一标识的对象,通过它我们可以识别它。 这样,您可以计算出控制器现在最有可能的位置。
准备工作
首先,您需要确定目标公众,我们将从中解析数据。 该小组的评论中应该有很多活动,否则我们可能会获得太少的数据
就我而言,这是“ Control Gomel”组。
我们将使用官方的VKontakte API(适用于Python)解析注释
我们会使用用户的访问密钥进行身份验证,因为某些组可能已关闭,并且只有在您被接受到该组后才能访问他们的评论。
之后,您可以开始提取注释:
接收评论
首先,我们获得组中最后一个可用的帖子,以通过vk.wall.getComments提取注释,并初始化DataFrame,将数据保存到其中。
每个评论文章都有题词:“祝您有美好的一天,付钱,不要受到控制”,因此请下载评论,检查文章内容并获取评论数组,您可以从中获取数据。
考虑到每天发布1个帖子(现在是11月底,学年从9月开始,并且主管很可能考虑到这一点并更改了他们的普通位置),所以我在过去3个月中对这些帖子进行了评论。 原则上,可以考虑其他符号,例如一年中的时间。
一些评论被诸如“在Barykin上有人吗?”之类的消息所阻塞。 如果您查看这些(不必要的)注释,则可以突出显示一些标志:
- 案文包含“干净”,“左”,“没人”等字样。
- “告诉我”,“谁”,“什么”,“如何”
- 诸如表情符号之类的符号
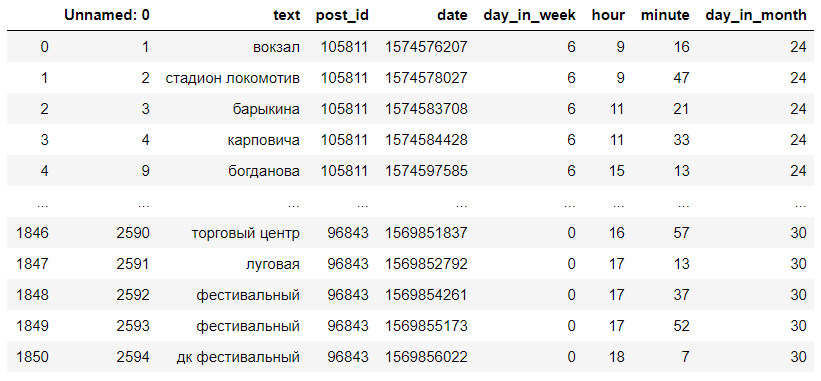
之后,我们将通过一系列注释并从中提取唯一的ID,文本,时间,日期和星期几,并将它们放入已创建的DataFrame中。
接收评论import re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
因此,我们收到了一个带有注释文本,其ID,星期几,小时和分钟的DataFrame,该注释是在其中编写的。 我们只需要星期几,写作时间和文字。 看起来像这样:
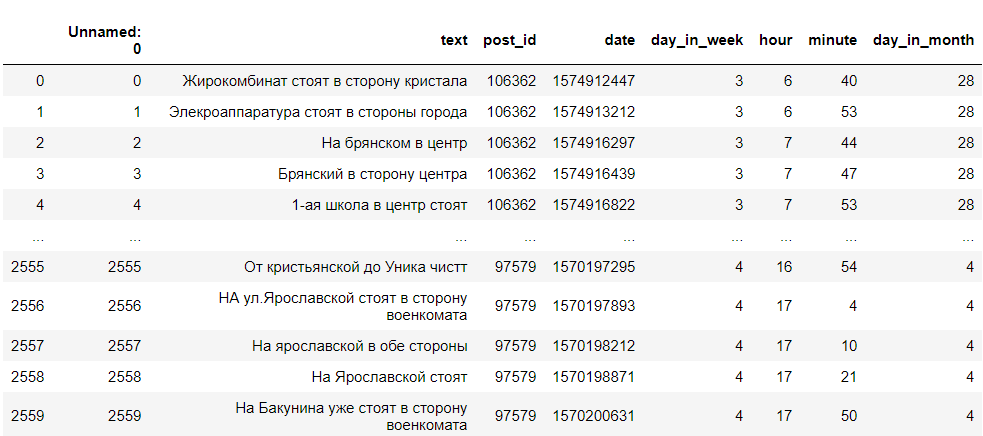
数据清理
现在我们需要清除数据。 在搜索Levenshtein距离时,有必要从注释中删除方向,以减少错误。 我们找到“在旁边”,“去”,“如何”,“附近”的表达方式,因为它们通常后面跟第二个停靠点的名称,我们将其删除以及后面的内容,并用常用的行距替换一些行话名称。
清除资料 from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
使用Levenshtein距离进行转换
我们直接进行到Levenshane距离。 有一点帮助:Levenshtein距离-插入一个字符,删除一个字符并用另一个替换一个字符的最少操作数,这是将一行变成另一行所必需的。
我们将使用
Fuzzywuzzy库找到它。 它可以帮助您快速轻松地计算Levenshtein距离。 为了加快工作速度,该库的作者还建议安装python-Levenshtein库。
为了获得评论的停止,我们需要一个停止列表。 GoTrans应用程序的开发人员Alexander Kozlov向我提供了它。
必须扩展列表,在其中添加一些不存在的站点,并更改部分名称,以便更好地定位它们。
停止Stops = ['supermarket','meadow','remybtekhnika','Leningrad','Yaroslavl','Polesskaya',
'Yaroslavl','timofeenko','March 8',
“ Rechitsky交易所”,“ Rechitsky大街”,“马戏团”,“百货商店”,“ Chongarskaya”,
'chongarka','ggu','skorina','university','appliance','1000个小东西','maya','station',
“大学园区”,“贸易与经济”,“周年纪念”,“微区18”,“机场”,“即将来临”,
'gomelgeodezcentr','crystal','lake lyubenskoye','davydovsky市场','davydovka',
'河流sozh','gomeldrev',
'Sevruki','gmu 1号','Rechitsky等','服装','传染病医院','鸥营',
沃洛托娃,珊瑚,戈梅尔特格马什,戈梅罗普里克特,温斯戈梅斯特罗伊,报纸,
“ Kalenikova”,“ Eremino”,“蒸馏”,“特殊工业自动化”,“第二学校”,“ Barykina”,
“机器单元”,“青年”,“铸造体”,“化学家”,“ golovatsky”,“ budenny”,
'spu67','35th','gagarin','Gomselmash工厂50年','hill','radio factory',
“祖母”,“玻璃厂”,“栗子”,“启动引擎”,“宇航员”,
'rtsrm initial','bykhovskaya','紧急情况部研究所','dk gomselmash','store','rechitsky',
'Sevruks','Osovtsy','游客','肉类工厂','Holy Trinity','medical town','October',
“油库”,“ gomelloblavtotrans”,“ milkavita”,“ bakunin”,“ zip”,“ oma”,“树脂”,
“建筑市场ksk”,“道路建设者”,“现场”,“ kamenetskaya”,“ bolshevik”,“ jakubovka”,
“ Borodina”,“河马大型超市”,“地下英雄”,“ 5月9日”,“栗子”,“假肢”,
“ iput站”,“共产国际”,“音乐教育学院”,“农业公司”,“旁路”,“胜利”,
“西方”,“珍珠”,“弗拉基米尔”,“干”,“药房”,“伊凡诺娃”,
“机械制造”,“桦木”,“ 60年”,“动力工程师”,“中心石”,
“肿瘤诊所”,“射击场”,“ golovintsy”,“珊瑚”,“南方”,“春天”,
埃夫雷莫娃(Efremova),边境,贝尔古特(Belgut),戈梅斯特罗伊(Gomelstroy),鲍里森科(Borisenko),田径宫,
'Michurinsky','solar','gastello','military','auto center','plumbing','uza',
“医学院”,“幼儿园11”,“布尔什维克”,“幼犬”,“达维多夫斯基”,“海洋”,“进步”,
'Dobrushskaya','白色','GSK','davydovka','电气设备','友谊',
“ 70年”,“汽车维修”,“瑞典山”,“赛道”,“水渠”,“机器戈梅利”,
沃洛托娃,先锋,皇家骑警,希姆托尔,第二草地巷,博希纳纳,浴场,
“肿瘤诊所”,“广场”,“列宁”,“第一学校”,“南店”,
“ gomelagrotrans”,“ millers”,“ lyubensky”,“军事征募办公室”,“医院”,“ uza”,“ rtsrm”,
'lysyukovyh','shop iput','raton','gas station','randovsky','farmhouse','chestnut','ropovsky',
“ Romanovichi”,“ Ilyich”,“ rowing”,“建筑业”,“传染性”,
“胖工厂”,“汽车服务”,“农业服务”,“粘性”,“ Nikolskaya”,
“自走式收割机”,“泥瓦匠”,“建材”,“维修机械”,“管理”,
“十月”,“森林童话”,“塔蒂亚娜”,“鲍里斯·察里科夫”,“扎尔科夫斯基”,“扎伊塞娃”,
“搬迁”,“ Karpovich”,“房屋建筑工厂”,“城市电力运输”,“ zlin”,
“体育场gomselmash”,“ ap 6”,“液压驱动”,“机务段”,“汽车市场osovtsy”,
“新生活”,“朱科娃”,“军事部队”,“第三学校”,“森林”,“红色灯塔”,
“区域”,“达维多夫斯卡亚”,“卡尔比雪娃”,“世界卫星”,“青年”,“体育场机车”,
'太阳能','Ladaservice','μR21','Aresa','国际主义者','Kosareva',
“ Bogdanova”,“ Gomel铁混凝土”,“μr20a”,“μrRechitsky”,“医疗设备”,“ Juraeva”,
“手工艺品学院”,“冰”,“ dk艺术节”,“购物中心”,
'Kuibyshevsky','festival','garage koop 27','地震工程','milcha','tube医院',
“ ptu179”,“化工产品”,“消防部门”,“医院”,“公交仓库”,
'报纸大楼','胜利','klenkovsky','钻石','引擎维修','mkr 19']
使用.map和Fuzzywuzzy.process.extractOne,我们在列表中找到最小Levenshtein距离的停靠点,然后用停靠点的名称替换注释文本,这使我们可以获取停靠点名称的数据集。
结果数据集如下所示:
评论变成停止 def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
数据输出
现在我们可以假设控制器在给定的时间最有可能在哪里。
我们正在查找一周中特定时间和日期的结果数据记录。 例如,在星期二上午9点:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
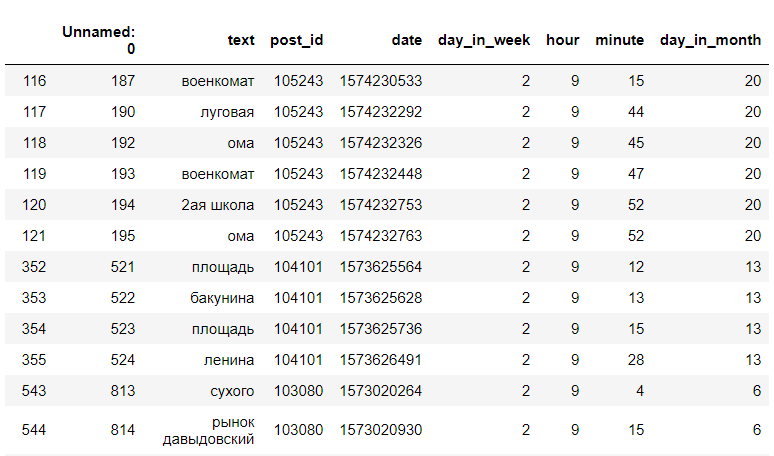 (这不是全部数据)
(这不是全部数据)之后,我们找到唯一停靠点的数量,并仅显示停靠点及其数量:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

现在我们可以说,在星期二早上9点,管制人员很可能会在ul Myasokombinat的车站被发现。 Lugovaya,BelGUT,TD“奥马”。
这种方法的主要缺陷是缺乏数据。 并非每天都在高峰时段提供注释,因为人们使用公共交通的次数多于不那么受欢迎的时间,但是如果您添加数据(例如,不仅来自一组注释的数据,还会添加数据)来自替代组或电报聊天,以及条目的数量,一切将变得更加容易。
使用VK LongPoll API进行Bot
为了有机会根据时间在不依赖计算机的情况下接收控制器位置的数据,我为VKontakte上的一个小组制作了一个机器人,该机器人通过发送记录中的停靠点数(给定当前时间和星期几)来响应任何消息。
机器人代码 from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
结论
在实践中,我多次验证了这些假设的质量,并且一切正常。 事实证明,尽管无法给出绝对正确的预测,并且控制成功的可能性不是100%,但控制员基本上处于相同的停止位置。 Levenshtein距离具有许多不同的应用,从纠正单词错误到比较基因,染色体和蛋白质,但它在此类应用问题中也具有潜力。
祝您有美好的一天,并支付车费。
所有的bot代码和数据操作均
在此处发布。