大家好,我叫Alexander,我是CIAN的一名工程师,从事系统管理和基础架构流程的自动化。 在对前一篇文章的评论中,我们被要求告诉我们每天从哪里获得4 TB的日志以及我们如何处理它们。 是的,我们有很多日志,并且已经创建了一个单独的基础结构集群来处理它们,这使我们能够快速解决问题。 在本文中,我将讨论在过去的一年中我们如何对其进行调整以适应不断增长的数据流。
我们从哪里开始
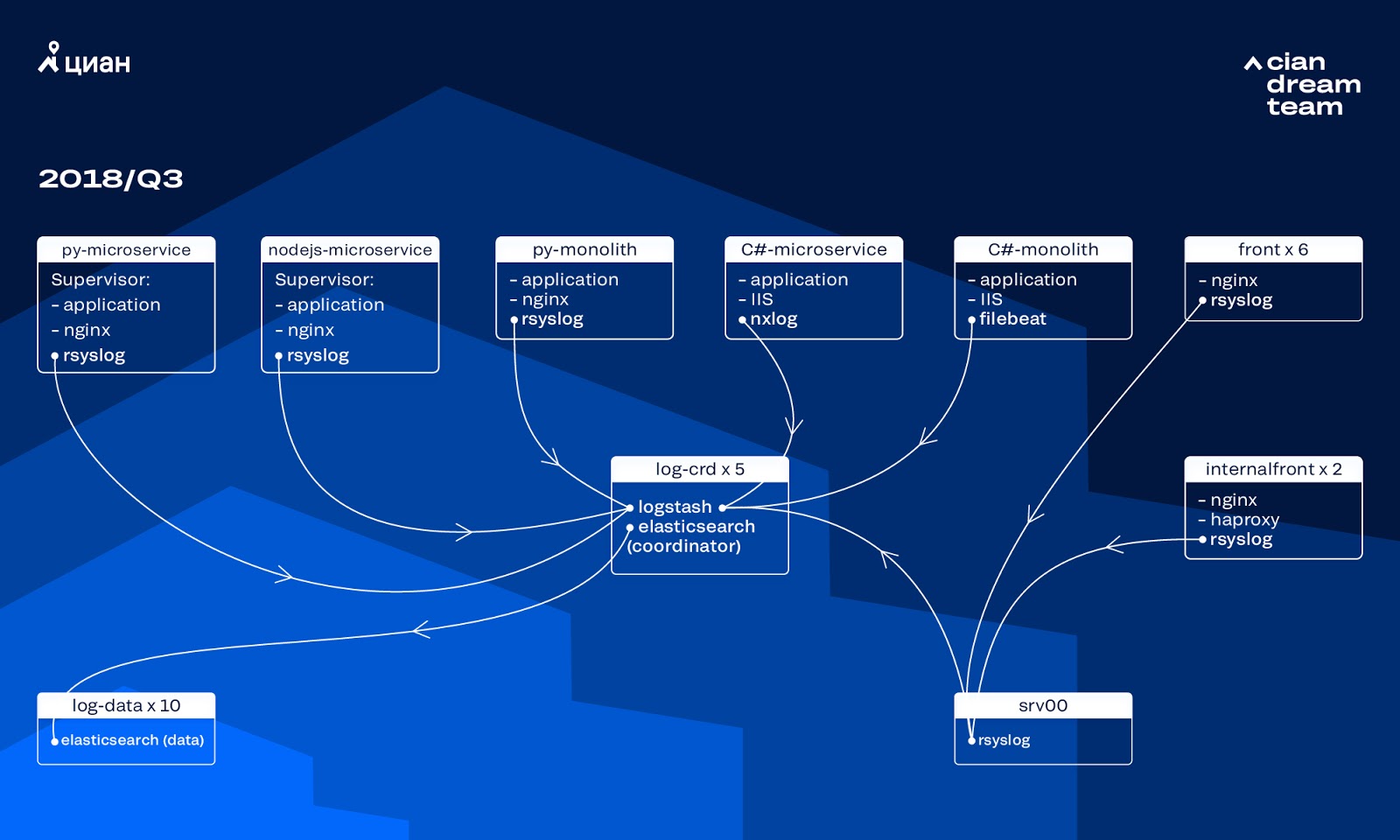
在过去的几年中,cian.ru的负载增长非常迅速,到2018年第三季度,资源流量达到每月1,120万唯一用户。 那时,在关键时刻,我们丢失了多达40%的日志,因此我们无法快速处理事件,因此花费了大量时间和精力来解决它们。 我们经常找不到问题的原因,并且在一段时间后再次发生。 这是您必须要做的事情的地狱。
当时,我们使用了由10个数据节点组成的集群,这些集群的ElasticSearch版本为5.5.2,具有典型的索引设置来存储日志。 它是一年多以前引入的,是一种流行且负担得起的解决方案:当时日志流不是很大,提出非标准配置没有任何意义。
不同端口上的Logstash提供了在五个ElasticSearch协调器上处理传入日志的功能。 一个索引,无论大小,都由五个碎片组成。 每小时进行一次每日轮换,结果每小时集群中出现约100个新碎片。 尽管日志不是很多,但是集群是托管的,没有人提请注意其设置。
成长问题
由于两个进程相互重叠,因此生成的日志的数量增长很快。 一方面,该服务的用户越来越多。 另一方面,我们开始积极地转向微服务体系结构,将我们的旧式单片锯切成C#和Python。 数十个新的微服务替换了整体组件的一部分,为基础架构集群生成了更多日志。
规模的扩大导致我们发现集群实际上变得不可控。 当日志开始以每秒2万条消息的速度到达时,频繁的无用轮换将分片的数量增加到6000个,一个节点占600多个分片。
这导致了RAM分配的问题,并且当一个节点崩溃时,所有分片开始同时移动,从而增加了流量并加载了其余节点,这使得几乎不可能将数据写入集群。 在此期间,我们没有日志。 由于服务器问题,原则上我们丢失了1/10的集群。 大量的小索引增加了复杂性。
没有日志,我们不了解事件的原因,可能迟早要再次踩到同一把耙子,但是在我们团队的意识形态上,这是不可接受的,因为我们对所有工作机制都采取了完全相反的态度-绝不会重复相同的问题。 为此,我们需要大量的日志及其几乎实时的交付,因为值班工程师团队不仅从度量标准而且还从日志监控警报。 为了了解问题的严重程度-当时每天的日志总量约为2 TB。
我们设定了一个目标-完全消除日志损失,并在不可抗力期间将日志传送到ELK集群的时间最多减少到15分钟(我们将来将这个数字作为内部KPI来依靠)。
新的旋转机制和热暖节点
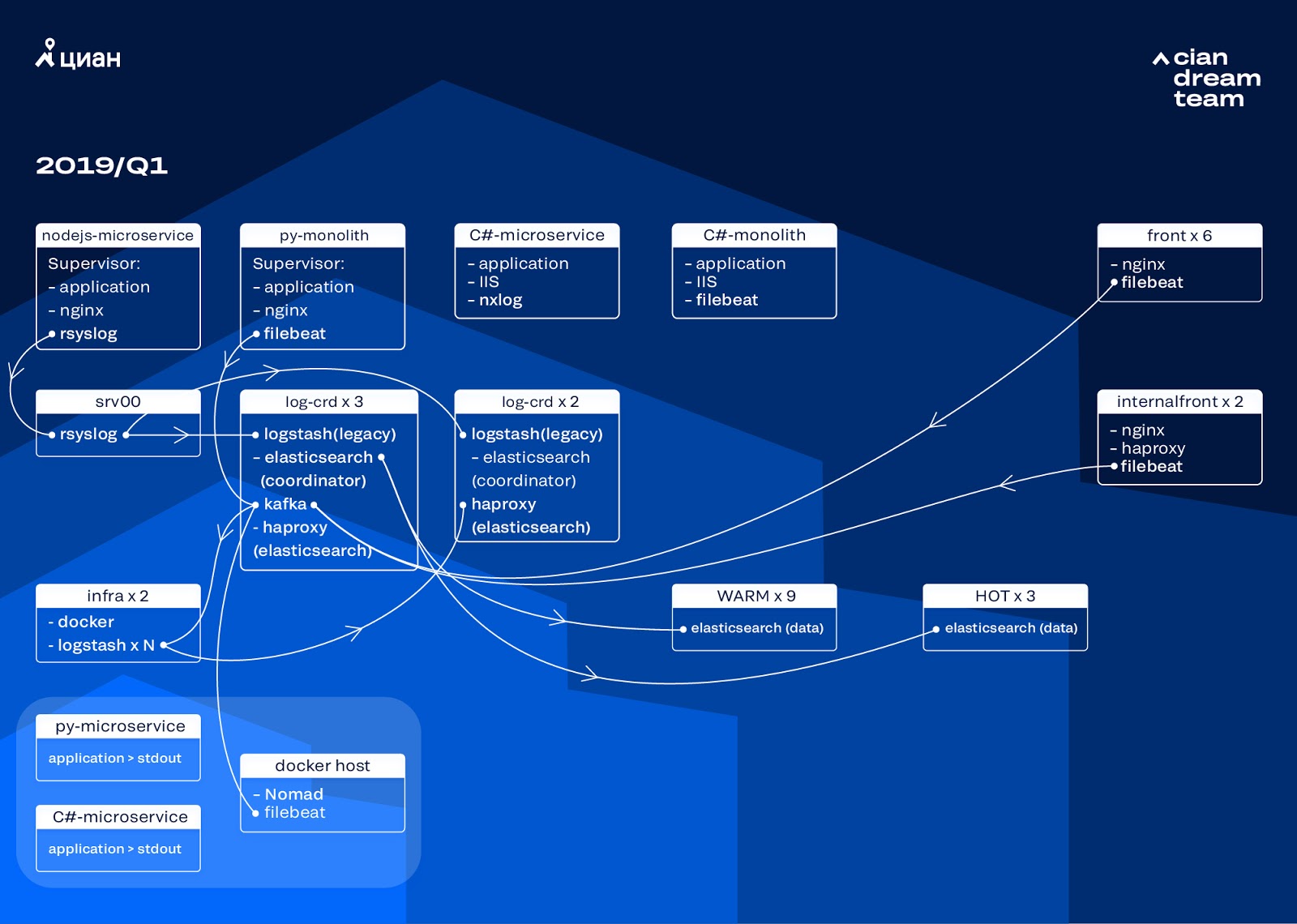
我们通过将ElasticSearch的版本从5.5.2更新到6.4.3开始了集群转换。 再一次,我们收到了版本5的集群,我们决定偿还并完全更新-仍然没有日志。 因此,我们仅用了几个小时就完成了此过渡。
此阶段最雄心勃勃的转换是引入三个节点,并使用协调器作为中间缓冲区Apache Kafka。 消息代理使我们免于在ElasticSearch问题期间丢失日志。 同时,我们在群集中添加了2个节点,并切换到热-热架构,其中三个“热”节点布置在数据中心的不同机架中。 我们将日志重定向到了无论什么情况下都不会丢失的日志-nginx以及应用程序错误日志。 次要日志(调试,警告等)转到其他节点,并且在24小时后,“重要”日志也从“热”节点转移到其他节点。
为了不增加小索引的数量,我们从时间旋转切换到了翻转机制。 论坛上有很多信息表明,按索引大小进行轮换非常不可靠,因此我们决定使用按索引中的文档数进行轮换。 我们分析了每个索引,并记录了轮换后应该执行的文档数。 因此,我们已达到分片的最佳大小-不超过50 GB。
集群优化
但是,我们并没有完全摆脱这些问题。 不幸的是,小的索引看起来都是一样的:它们没有达到设定的数量,没有旋转,并且由于对三天以上的索引进行了全局清理而被删除,因为我们按日期删除了旋转。 由于来自集群的索引完全消失,并且写入不存在的索引的尝试破坏了我们用于控制的策展人逻辑,因此导致数据丢失。 用于记录的别名已转换为索引,并且破坏了过渡的逻辑,导致某些索引的不受控制的增长到600 GB。
例如,配置旋转:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
在没有过渡别名的情况下,发生错误:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
我们将这个问题的解决方案留给下一个迭代,然后提出另一个问题:我们切换为拉出Logstash的逻辑,该逻辑处理传入的日志(删除不必要的信息并丰富信息)。 我们将其放置在我们通过docker-compose运行的docker中,并将logstash-exporter放置在同一位置,这将度量标准提供给Prometheus以进行日志流的操作监视。 因此,我们给了自己一个机会,以平滑地更改负责处理每种类型日志的logstash实例的数量。
在改善群集的同时,cian.ru流量每月增加到1,280万唯一用户。 结果,事实证明,我们的转换跟不上生产中的更改,并且我们面临这样一个事实,即“热”节点无法应付负载并减慢了整个日志的交付速度。 我们收到了“热”数据而没有失败,但是我们必须干预其余数据的传递,并进行手动滚动以平均分配索引。
同时,由于集群是本地docker-compose的事实,因此扩展和更改集群中logstash实例的设置变得很复杂,并且所有操作都是手动执行的(要添加新端,您必须动手遍历所有服务器并在各处进行docker-compose up -d)。
日志重新分配
在今年的9月,我们仍然继续看到整体,集群上的负载增加了,日志流每秒接近3万条消息。
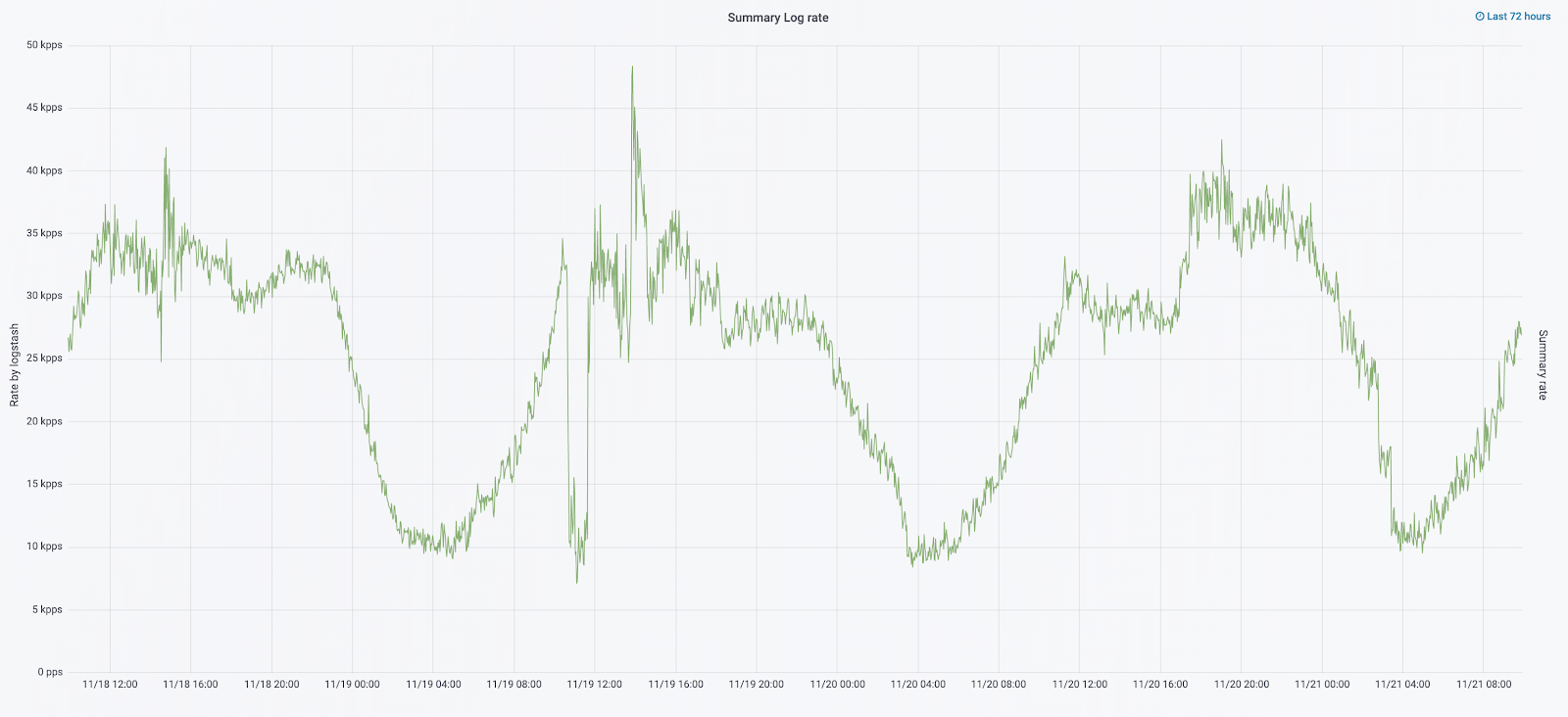
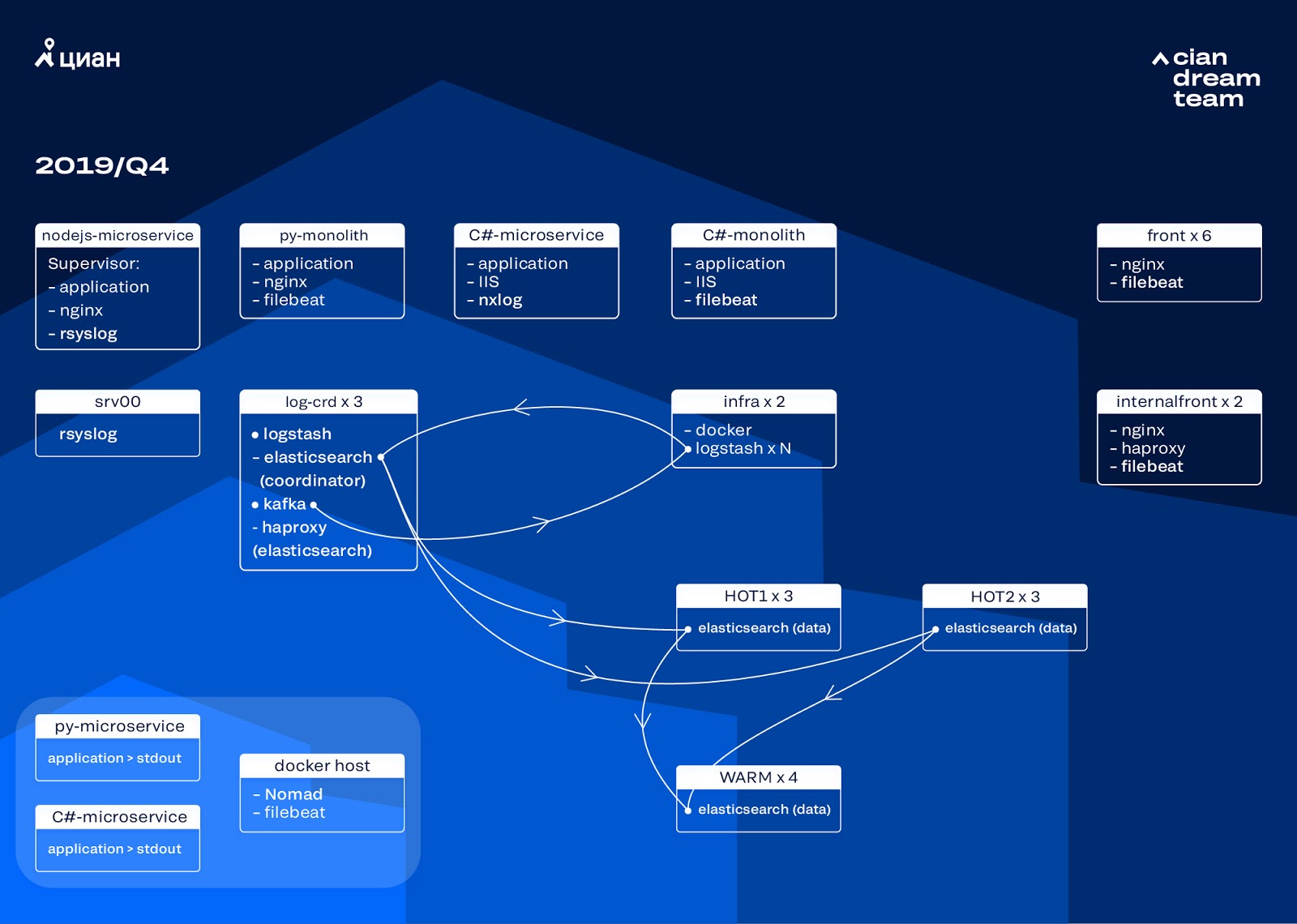
我们通过更新熨斗开始了下一个迭代。 我们从五个协调员切换到三个,替换了数据节点,并在资金和存储量方面获胜。 对于节点,我们使用两种配置:
- 对于热节点:E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2(对于Hot1是3,对于Hot2是3)。
- 对于热节点:E3-1230 v6 / 4Tb SSD / 32 Gb x 4。
在这次迭代中,我们将包含微服务访问日志的索引取出到第二组三个热节点中,该索引所占用的空间与前端nginx日志一样多。 现在,我们将数据在热节点上存储20小时,然后将它们转移到其他日志中。
我们通过重新配置小索引的旋转来解决小索引消失的问题。 索引现在每23小时轮换一次,即使数据很少也是如此。 这稍微增加了分片的数量(大约为800),但是从集群性能的角度来看,这是可以容忍的。
结果,集群中出现了六个“热”节点和只有四个“热”节点。 这会导致较长时间间隔内的请求稍有延迟,但是将来增加节点数将解决此问题。
在此迭代中,还修复了缺少半自动缩放的问题。 为此,我们部署了基础设施Nomad群集-与我们已经部署用于生产的群集相似。 虽然Logstash的数量不会根据负载自动更改,但是我们将介绍这一点。
未来计划
实施的配置可以很好地扩展,现在我们存储了13.3 TB的数据-所有日志在4天之内,这对于紧急分析警报是必需的。 我们将部分日志转换为指标,然后将其添加到Graphite。 为了方便工程师的工作,我们提供了基础结构集群的指标和用于半自动修复典型问题的脚本。 在计划了明年计划增加数据节点数量之后,我们将从4天切换到7天。 这对于操作工作就足够了,因为我们始终尝试尽快调查事件,并且遥测数据可用于长期调查。
在2019年10月,cian.ru流量每月增加到1530万唯一用户。 这是对用于交付日志的体系结构解决方案的一项严格测试。
现在,我们准备将ElasticSearch升级到版本7。但是,为此,我们将必须更新ElasticSearch中的许多索引的映射,因为它们已从5.5版本移出,并在版本6中被声明为已弃用(它们在版本7中根本不存在)。 这意味着在更新过程中肯定会出现一些不可抗力,暂时使我们无法获得日志。 在这7个版本中,我们最期待Kibana具有改进的界面和新的过滤器。
我们实现了主要目标:我们不再丢失日志,并将基础架构集群的停机时间从每周2-3次减少到每月几个小时的服务工作。 生产上的所有这些工作几乎是看不见的。 但是,现在我们可以准确地确定我们的服务正在发生什么,我们可以在安静模式下快速进行操作,而不必担心日志会丢失。 总的来说,我们很满意,很高兴并且正在为新的漏洞做准备,我们将在后面讨论。