2016年,在聊天机器人普及的顶峰时期,我们的团队为业务提供了按钮助手。 直到一个有趣的想法浮出水面:“如果我们使用神经网络来自动化客户支持该怎么办?” 我们希望聊天机器人最终学会理解自然语言并变得舒适。
它花费了四位数学家,六个月的辛勤工作,一种新的编程语言和许多错误-我们创建了一个构造函数,每个人都可以使用AI组装虚拟助手。
在材料中我们将告诉
- 虚拟助手与常规聊天机器人有何不同
- 虚拟助手理解语言是否正确
- 我们如何教机器人理解上下文并编写lialang语言
- 案例测试:我们如何自动为三家银行提供支持
- 创建用于接口的Lia平台和引擎
- 三个步骤:组装虚拟助手的平台如何工作(任何人,甚至非程序员都可以组装机器人)
聊天机器人与虚拟助手
先进的聊天机器人能够突出显示关键字并模仿60年代的人类对话。 嬉皮士迷上了LSD,披头士乐队聚集了体育场,约瑟夫·魏曾鲍姆(Joseph Weizenbaum)创立了对话者-心理治疗师艾丽莎(Eliza),他会给许多现代机器人甚至心理学家带来麻烦。
例如,在“我的父亲恨我”一句中,伊丽莎回答了关键字“父亲”,并问:“还有谁讨厌你的家人?” 但是机器人心理治疗师并不了解这些问题的实质。 现代的聊天机器人也可以工作:关键字,线性脚本和现场对话的模仿。
但是自60年代以来,情况发生了变化:现在,借助机器学习和NLP技术,我们可以教聊天机器人理解自然语言和上下文。 这仍然是一个模仿,但更有意义。
要了解差异,让我们比较一下聊天机器人和助手-假设我们需要制作一个
虚拟侍酒师 ,以帮助客户选择葡萄酒。
第一阶段
聊天机器人和虚拟助手的第一阶段是一个阶段:我们找出用户请求并提出他们可以编写的短语。 然后,我们规定了机器人如何响应。
基本要求很明确-拿起葡萄酒。 但是此请求可以具有许多参数:原因,价格,国家/地区,颜色,葡萄品种。 也许用户会立即写下要查找的葡萄酒的名称。 或者他将澄清细节:“它是在哪里制造的?” 也许出于好奇,他将开始向机器人扔一个问题:“哪个瓶子是世界上最昂贵的?”等等。 此外,除了案件中的要求外,还有“你好”,“再见”,“你好吗”以及其他一些闲话。
您可以无限幻想,但是仍然无法预测所有用户问题。 当我们认为所描述的情况足以满足98%的请求时,我们会停止(尽管随后残酷的现实开始了,我们发现最多可以满足80%的要求)。
然后,我们分散了有关用户对特定请求的需求的假设-意图。 意图表明用户想要什么,但是丢弃有关他如何写的信息。 对于聊天机器人和助手,此阶段相同。
意向清单
意图1-我要酒短语:
-帮我选酒
-您会推荐什么酒?
-我想要最好的酒
-...
怎么做:随机选择最受欢迎的葡萄酒之一并告知用户。
意图2-便宜的葡萄酒短语:
-有没有上等的葡萄酒,只要1000卢布?
-但是没有便宜吗?
-对我来说太贵了
-...
怎么做:在请求中添加价格过滤器,然后选择最受欢迎的葡萄酒之一。
意图3-我要用酒做肉短语:
-建议将葡萄酒推荐给牛排
“我晚饭要炖牛肉。” 喝什么
-...
怎么办:按“去肉”标准向数据库请求,选择最受欢迎的葡萄酒之一并告知用户。
...(等等数百种不同的意图)
意向290-我们不了解用户短语:其他
怎么做:打上一个短句:“我不知道你的意思,但是Pinista在一年中的任何时候都很令人愉快。”
第二阶段
在此阶段,我们开始创建一种算法,机器人将通过该算法工作。 聊天机器人和虚拟助手的相似性到此结束。
在编写聊天机器人时,程序员会为每种意图手动确定关键字,并且当用户编写时,机器人会在短语中寻找这些关键字。
在开发助理时,程序员会教一种算法,根据词汇含义比较用户副本。 这使您可以找到最接近的意图。
虚拟助手能听懂语言吗?
算法可以将某些短语与其他短语区分开-但是我们可以说机器人真正理解该语言吗?
为了回答这个问题,让我们回到短语的词义比较。 计算机的含义是可以理解的数据类型:字符串,数字及其组合。 因此,程序员面临着将源文本转换成适合比较数学运算的形式(向量)的任务。
vectorize(" ") = (0.004, 17.43, -0.021, ..., 18.68) vectorize(" ") = (0.004, 19.73, -0.001, ..., 25.28) vectorize(" ") = (-8.203, 15.22, -9.253, ..., 10.11) vectorize(" ") = (89.23, -68.99, -10.62, ..., -0.982)
对于我们的任务,词汇上接近的短语的向量在数学上应彼此接近,词汇上相距遥远的短语的向量应相距较远,另一个歌剧的短语向量应相距很远。 例如,“我想要酒”比“我不想要酒”更接近“我想要白酒”。 远非“火星袭击”。经过适当训练的神经网络将能够在这些向量中得出词汇含义。 事实证明,为了比较两个短语的含义,您需要比较它们的向量。
因此,“机器人懂语言吗?”这个问题的答案将是这样的:他们不了解一个人的状态,他们只是可以比较词汇的含义,而不会将温暖与柔和相混淆。 但是,当算法可以提供建议性的改进并得出结论时,我们诚实地说:是的,理解已经到来。 同时,“了解语言”只是一个漂亮的营销用语。
实际上,该机器人只能像三岁的孩子一样进行类比。 但是,如果您给孩子足够的例子,他将能够假装自己是一个知识分子并主持讨论。 第一线支持人员的“实时”操作员以相同的方式工作-他们概述了一系列情况并告诉他们如何在其中表现。 因此,虚拟助手非常适合支持自动化。
我们如何教机器人理解上下文:lialang
对于正常的支持,机器人几乎不需要自然语言的“理解”-重要的是,他们可以回答问题并留在上下文中。 为此,我们编写了lialang(一种对话标记语言),可以在其中描述脚本并将其传递给机器人。
对话编程人员的主要任务是描述人与机器之间的对话中可能发生的所有情况。 为此,可以使用我们的语言来关联意图和动作的名称。
考虑一个简单的例子-问候:
if intent() { reaction(_) }
看起来像常规代码,但是神经网格在intent(...)构造后面起作用-lialang使用常规的编程构造以一般模式(“如果您需要某些东西”)描述对话。 当然,为了使它起作用,您需要应用机器学习和NLU技术,因为用户可以根据自己的意愿编写请求。
这是描述上下文情况的方法。我们引入了“ was”结构,以在对话中的任何地方捕捉不适当的问候:
if intent() { if was_reaction(_) { reaction(___) } else { reaction(_) } }
它说:利亚,如果他们向您问好,请打招呼。 如果在那之后他们再次说“你好”,那就说你已经打了招呼。
反应是Lia响应意图必须执行的动作。 在95%的情况下,这只是文字。 而且机器人也可以调用代码中的功能,将通信切换到操作员或执行其他复杂的动作。
发送文本和功能的代码与语言分开存在-该语言尽可能简单地描述情况。
现在,让我们尝试写一个更复杂的东西-在与银行聊天时,客户经常询问他们的详细信息。 让我们学习如何使用lialang向他们发送聊天和邮件。
if intent(_) or intent(___) { reaction(___) { if intent(__) { reaction(___) } } } if intent(___) { reaction(___) }
这里描述了两种情况:
- 莉亚,如果要求您发送详细信息,请将其发送至聊天。 如果在他们询问“有必要去邮局”之后,则将其发送到邮局。
- 说谎,如果您立即被要求将详细信息发送到邮件-将详细信息发送到邮件。
因此,lialang会尽其职责-在上下文中工作。 即使有人写“请通过邮件”,机器人也会理解我们在谈论细节。
Lia已经学会了支持复杂的场景-在用户需要的时候,她将从CRM中获取数据/将数据存储到CRM中,发送短信,进行付款帮助或谈论生活。
逐渐地,我们改进了语言:我们添加了变量,函数,实体(日期,地址,电话号码,名称等),状态和其他有用的构造。 因此,编写它变得更加方便。
案例测试:我们如何自动为三家银行提供支持
一旦开发出该技术,就必须立即对其进行最终确定-我们有了第一个客户。 VTB需要自动化在新的互联网银行中为企业家提供的支持。
我们的启动非常成功-尤其是对于四个月内创建的产品。 我们的VTB混合机器人基于神经网络,并立即有效:它回答了800多个问题,支持几种复杂的情况(声明,费率变化,用户设置)并且像人一样说话。 结果,在两个月内,我们的Lia将支持负担减少了74%。 很明显:支持自动化的想法起作用了。
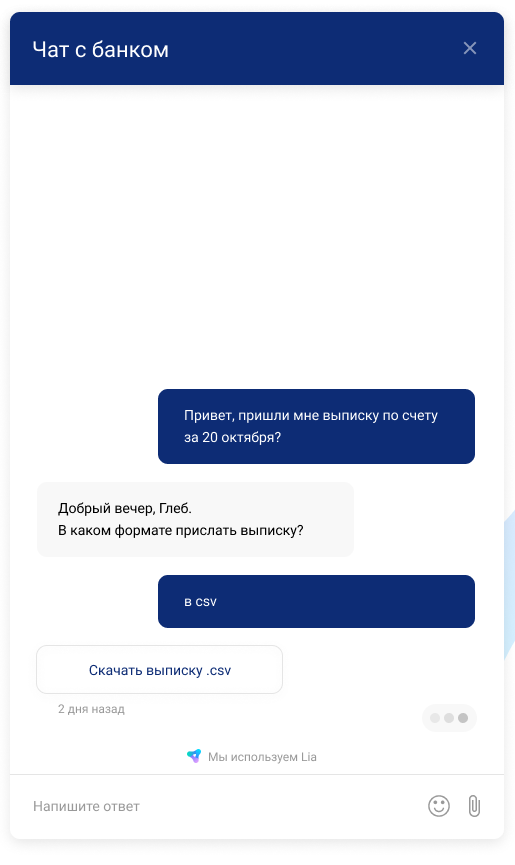
此外,基于Lia,我们在Rocketbank和DeloBank上使FAQ自动化-在两周内,他们关闭了没有运营商的32%的申请。
看来男孩们成功了。 但是,在第一个客户之后,很明显需要更改概念。 真是糟糕透顶-我们不得不手动修改脚本,进行编辑,开发分支。 简单的机器人也一样,只是更难,而且需要更多的力量。 在这种情况下,很难扩展。
然后,我们决定制作一个工具,使客户自己甚至可以组装一个复杂的助手。 而且,我们将仅提供教程帮助和教育用户。
Lia平台和接口引擎
因此,我们决定为不了解其发展的人们
搭建一个
平台 。 尽管lialang包含的设计少于十种,但并不是每个经理都会教它创建自己的机器人。 管理人员喜欢鼠标。
因此,我们开始考虑这样一个接口,它将能够完成lialang可以做的所有事情。 他不会遇到嵌套分支,从一个脚本过渡到另一个脚本的问题,而且最重要的是-不仅是我们的程序员,而且每个想要创建脚本的人都可以。
查看外观: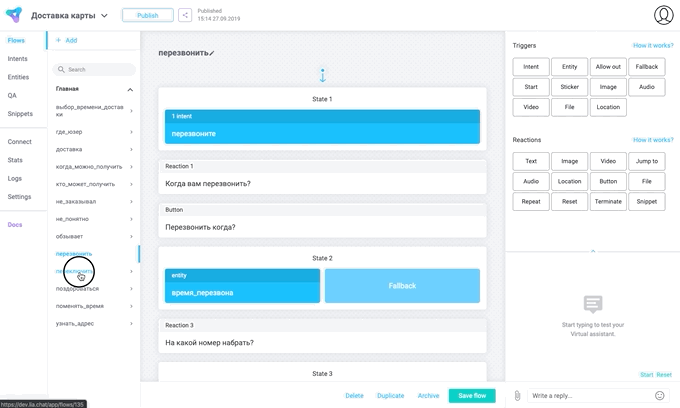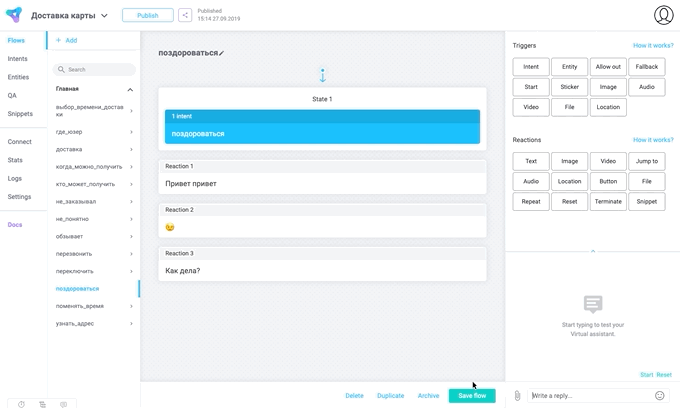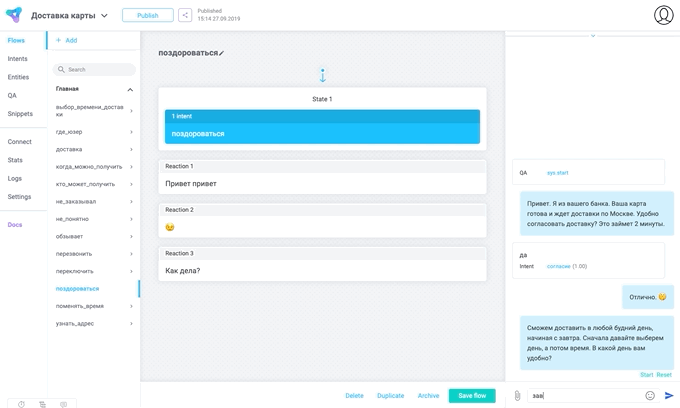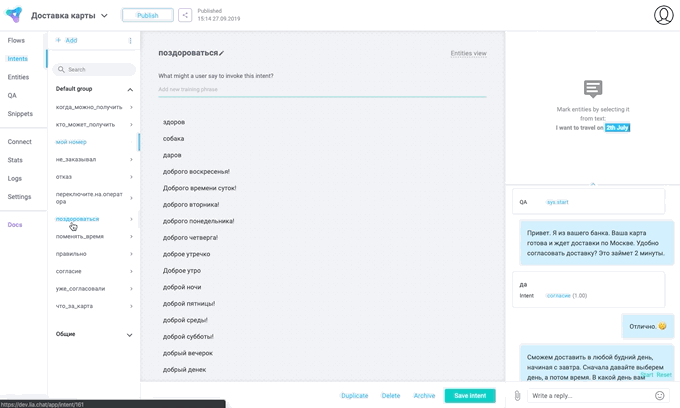 对话框是非线性的,为各种对话方案编写通用引擎非常困难。 但是在考虑这些方案之前,我们已经有了lialang-它成为了引擎。
对话框是非线性的,为各种对话方案编写通用引擎非常困难。 但是在考虑这些方案之前,我们已经有了lialang-它成为了引擎。无论接口设计人员想出了什么,我们都不会为此动脑筋,而只会编写从接口到lialang代码的小标记转换器。 如果重做了接口,我们只需要更改翻译器-由于这两个接口命令和core命令可以分开存在。
创建虚拟助手的平台如何工作?
要在Lia中组装自己的虚拟助手,用户需要经历三个阶段。
步骤1.下载与用户的聊天记录,以便机器人理解并突出显示主要场景
如果客户端具有与用户对话的历史记录,则可以将其上传到系统并从最受欢迎的查询中获取集群。 从中创建意图将非常方便。
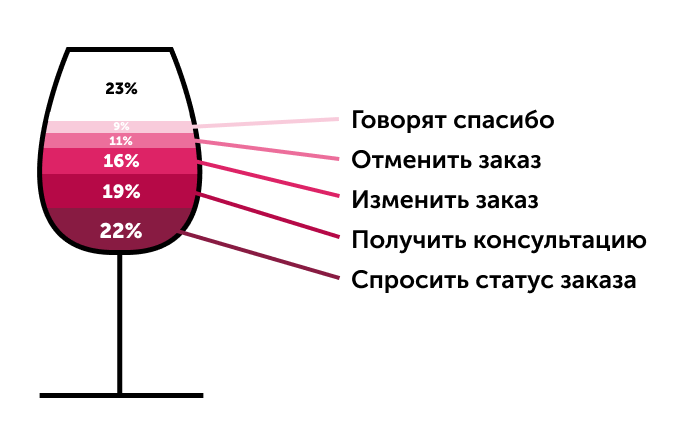
随着时间的流逝,Lia的有效性将会提高。 机器人无法回答的消息又被分成几类:例如,“您是谁?”,“您是谁?”,“您的名字是什么?”和“您是机器人?”将分为一组。 因此,该平台可以半自动进行自我学习:用户可以看到差距并缩小差距,并添加新的方案-结果,六个月内,涵盖请求的百分比从30%增加到70%。
如果没有对应的历史记录,我们将跳过此步骤,并立即从第二步开始:我们预测用户将向助手求助的内容。
步骤2.我们记下意图:针对最频繁的用户请求的10-20个选项
在第二阶段,我们根据10-20个最流行的查询来规定意图:由于神经网络的缘故,这种选择数量就足够了。 因此,类似“我要点酒”这样的短语可以使机器人识别类似的用户请求:例如,“取酒”或“点酒”。

另一位助手理解并提取了本质:城市名称,电话号码,地址,时间戳,时间段,日期和诅咒-即使您说“累了,明天带一箱酒”。
此外,用户可以添加自己的对象并手动标记训练短语,以便助手学习更快。 这是该平台最强大的功能之一,因此,它可以创建不比人类操作者更糟的机器人。
步骤3.创建方案:规定几个答案或行动
用户必须在此处提出用户请求的答案。 普通项目的95%通常采用简单的问题解答方案-常见问题的答案。

顺便说一句,助手可以提供图片,视频和音频文件作为响应,并在必要时发送地理位置信息。
构造过渡特别有用-有了它,Lia可以从一种情况切换到另一种情况,然后再返回,解决了几个问题。 如果您需要退出对话,然后返回正确的轨道,这将很有用:例如,提出一个澄清的问题。
示例对话框跳转到:助手:我们需要弄清楚收货地址,因为收件人没有回应。
客户:那又如何? 哪个命令? (JumpTo用于订单说明)
助理:8月21日命令安提加尔,“乌诺”马尔贝克。
助手:那么我们可以澄清当前的收货地址吗? (返回主脚本)
当创建者希望他的助手不仅要回复文本,而且要采取行动时,他将能够呼叫程序员为专家编写JS代码片段。 我们允许您在脚本期间直接运行JavaScript:访问外部API,发送电子邮件或执行其他复杂操作。
4.总结
助理可以与任何事物集成:通过电话,即时通讯程序或客户端将在网站上发布的小部件与人交谈。
在平台上组装智能助手需要几个小时到一个月的时间。 然后,机器人学会了切合实际的理解请求并识别模式-大约需要六个月的时间(所有这一切都由一个活着的人监督)。 企业可以为Lia机器人女孩完成大部分常规任务:从协调送货,叫出租车到咨询客户。

顺便说一下,我们已经将与银行的项目转移到了平台上。 它们的工作原理也一样,但是它们的审核更加方便。
在不久的将来,我们计划添加提取器,这将使我们的用户能够提取更复杂的数据(例如,机器人将理解“午餐后的第二天”一词)。 我们还将最终确定版本控制,以便客户端可以快速回滚和回滚项目的版本。 此外,我们还将释放组织的角色系统。
我们预计Gartner的
预测是正确的-到2022年,所有客户互动中将有多达70%将通过某种AI进行。 根据我们的想法,像Lia这样的设计师将帮助更快地将客户服务转移到机器人。