Spring是功能强大的开源Java框架。 我决定告诉您Spring后端对哪些任务有用,以及与其他库相比的优缺点:Guice和Dagger2。考虑依赖注入和控件倒置-您将发现从哪里开始学习这些原理。
大家好,我叫西里尔 今天,我将讨论依赖注入。
我们将从所谓的报告开始。 “在一个特定的王国中,而不是在一个“迅速发展的”状态中。 我们当然会谈论Spring,但我也想看看他之外的一切。 我们将具体谈论什么?

我将进行一点题外话-告诉您我在做什么,我的项目是什么,为什么我们使用依赖注入。 然后,我将告诉您所有内容,比较控制反转和依赖注入,并讨论在三个最著名的库中的实现。
我在Yandex.Tracker团队中工作。 我们制作了Jira或Trello的杂货店类似物。 [...]我们决定制造自己的产品,这是第一款内部产品。 现在我们卖光了。 你们每个人都可以进入,创建自己的Tracker并执行任务-例如,教育或商务。
让我们看一下界面。 在示例中,我将使用我所在地区的一些术语。 我们将尝试创建票证,并查看其他同事在其中留下的评论。
首先,依赖注入通常是什么? 这是一种编程模式,符合美国古老的好莱坞原则:“不要打电话给我们,我们会自己打电话给您。” 依赖关系本身来找我们。 这主要是一种模式,而不是库。 因此,原则上,这种模式几乎在任何地方都是常见的。 您甚至可以说所有应用程序都以一种或另一种方式使用依赖注入。

让我们看看如果我们从头开始,如何自己提出依赖注入。 假设我决定开发一个小类,在其中我将通过我们的API创建票证。 例如,创建TrackerApi类的实例。 它具有createTicket方法,我们将在其中发送我的电子邮件。 我们将从我的帐户下创建一个票证,名称为:“为Java Meetup准备报告”。

让我们看看TrackerApi的实现。 例如,在这里,我们可以执行以下操作:创建一个httpClient实例。 简单来说,我们将创建一个对象,通过该对象将进入API。 通过该对象,我们将在其上调用execute方法。

例如,一个自定义的。 我从这些类编写了外部代码,它将使用类似的代码。 我创建一个新的TicketCreator并在其上调用createTicket方法。

这里有一个问题-每次我们创建票证时,我们都会重新创建并重新创建httpClient,尽管通常来说并不需要这样做。 httpClient创建非常认真。

让我们尝试做到这一点。 在这里,您可以在我们的代码中看到依赖注入的第一个示例。 注意我们所做的事情。 我们在字段中取出变量,并将其填充到构造函数中。 我们将其填充到构造函数中的事实意味着依赖关系已经存在。 这是第一次依赖注入。

我们将责任转移给了代码用户,因此现在我们必须创建一个httpClient,例如将其传递给TicketCreator。
这在这里也不是很好,因为现在通过调用此方法,我们将每次都再次创建httpClient。

因此,我们再次将其带到现场。 顺便说一下,这里有一个非显而易见的依赖关系注入示例。 可以说,我们总是在我下面(或其他人下面)创建票证。 我们将根据不同的用户创建每个单独的TicketCreator对象。
例如,当我们创建它时,它将在我下面创建。 我们传递给构造函数的那行也是依赖注入。

我们现在将如何做? 创建一个TrackerTicketCreator的新实例并调用该方法。 现在,我们甚至可以创建某种自定义方法,该方法将为我们创建带有自定义文本的票证。 例如,创建一个票“雇用新学员”。

现在,让我们尝试看看如果我想以同样的方式从我下面读取此票证中的注释,我们的代码将是什么样。 这大约是相同的代码。 我们将在此票证上调用getComments方法。
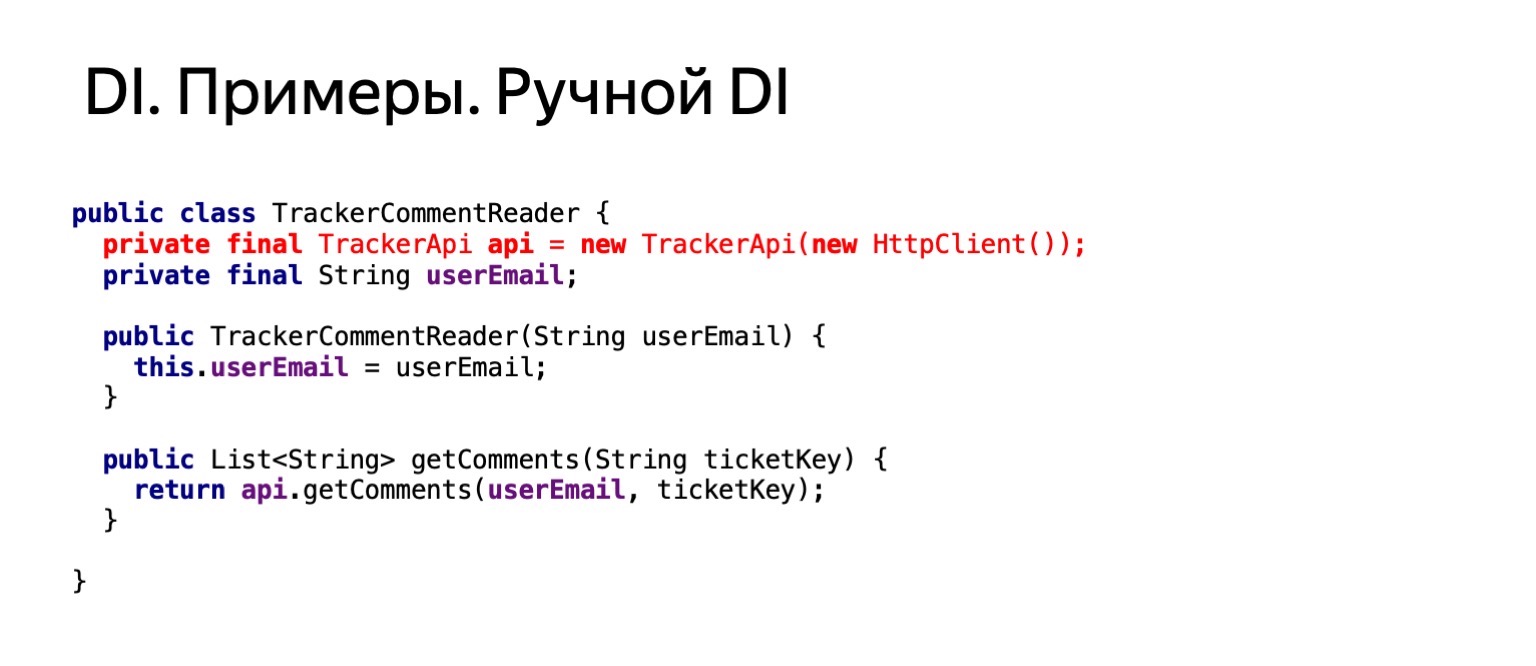
他长什么样? 如果我们在注释阅读器中使用并复制了此功能,则将复制httpClient的创建。 这不适合我们。 我们要摆脱它。

好啊 现在,让我们将所有这些参数作为依赖项注入,作为构造函数参数。

这是什么问题? 我们跳过了所有内容,但是现在在用户代码中编写了“样板”。 这是用户通常需要编写的某种不必要的代码,以便在逻辑方面采取相对较小的动作。 在这里,我们将不得不不断创建httpClient(它的API)并选择用户电子邮件。 每个TicketCreator用户将必须自己执行此操作。 不好 现在,我们将尝试查看在避免使用它时在库中的外观。
现在,让我们稍微偏离一下,看看什么是控制反转,因为许多控制反转都与之相关。

控制反转是一种编程原则,其中我们使用的对象不是由我们创建的。 我们根本不影响他们的生命周期。 通常,创建这些对象的实体称为IoC容器。 你们当中许多人都听说过Spring。 Spring文档说IoC也称为依赖注入。 他们认为这是一回事。

基本原则是什么? 对象不是由应用程序代码创建的,而是由某些IoC容器创建的。 作为图书馆的用户,我们什么也不做,一切都取决于我们自己。 当然,IoC是相对的。 IoC容器本身会创建这些对象,这不再适用于它。 您可能会认为IoC不仅实现了DI库。 著名的Java库Servlets和Akka Actors,现在已在Scala和Java代码中使用。

让我们谈谈图书馆。 一般来说,已经为Java和Kotlin编写了很多库。 我将列出主要的:
-春天,一个很棒的框架。 它的主要部分是依赖注入或他们所说的控制反转。
-Guice是一个库,大约在Spring从XML转移到代码描述时在第二和第三Spring之间编写。 也就是说,当春天还不那么美丽的时候。
-Dagger是Android上人们通常使用的工具。
让我们尝试在Spring上重写我们的示例。

我们有我们的TrackerApi。 我没有在短时间内包括该用户。 假设我们尝试在Dependency Injection中为httpClient做。 为此,我们需要使用注释进行声明。 使用
Autowired批注声明
Component ,整个类,尤其是构造函数。 这对Spring意味着什么?

我们在代码中有这样的配置,它由
组件扫描注释指示。 这意味着我们将尝试遍历包含它的包中类的整个树。 再往内陆,我们将尝试查找在
Component批注中标记的所有类。
这些组件将落入IoC容器中。 对我们来说重要的是,一切都应归于我们。 我们只标记我们要宣布的内容。 为了使我们能够使用某些东西,我们必须使用构造函数中的
Autowired注释对其进行声明。

TicketCreator我们以完全相同的方式标记。

还有CommentReader。
现在,让我们回顾一下配置。 如前所述,组件扫描会将所有内容放入IoC容器中。 但是有一点,即所谓的工厂方法。 我们有httpClient方法,我们不会将其作为类创建,因为httpClient来自库。 他不了解Spring是什么,等等,我们将直接在配置中创建它。 为此,我们编写了一个通常一次构建一次的方法,并使用Bean批注对其进行标记。

优点和缺点是什么? 主要优点-春天在世界上非常普遍。 下一个加号和减号是自动扫描。 除了对类本身的注释之外,我们不应明确声明要向IoC添加容器的任何地方。 足够的注释。 减号是完全一样的:相反,如果我们想要控制它,那么Spring不会为我们提供此功能。 除非我们能在团队中说:“不,我们不会那样做。 我们必须在某处清楚地开一些东西。 仅在配置中,就像我们对bean所做的那样。
另外,因此,启动缓慢。 当应用程序启动时,Spring必须遍历所有这些类并弄清楚要放入IoC容器中的内容。 它使他慢下来。 在我看来,Spring的最大缺点是依赖关系树。 在编译阶段不检查它。 当Spring从某个时刻开始时,它需要了解我内部是否具有这种依赖性。 如果以后发现它不在依赖关系树中,那么您将在运行时收到错误消息。 而且我们在Java中不希望出现运行时错误。 我们希望为我们编译代码。 这意味着它有效。

让我们来看看Guice。 正如我所说,这是第二个Spring和第三个Spring之间建立的一个库。 我们看到的美丽不是。 有XML。 为了解决这个问题,由Guice撰写。 在这里您可以看到,与配置不同,我们正在编写一个模块。 在其中,我们明确声明要在该模块中放置哪些类:TrackerAPI,TrackerTicketCreator和所有其他容器。
Provides是Bean注释的类似物,它以相同的方式创建httpClient。

我们需要声明每个这些bean。 我们将以
Singleton为例。 但具体来说,
辛格尔顿说这样的bean将只创建一次。 我们不会不断地重新创建它。 和
Inject分别是
Autowired的类似物。

属于的小型平板电脑。

优点和缺点是什么? 优点:在我看来,它比Spring的XML版本更简单并且可以理解。 启动更快。 弊端在于:它需要显式声明所用的bean。 我们应该写Bean。 但另一方面,正如我们已经说过的,这是一个加号。 这是Spring的镜像。 当然,它不如Spring常见。 这是他的自然减法。 而且存在完全相同的问题-在编译阶段不检查依赖关系树。
当他们开始将Guice用于Android时,他们意识到他们仍然缺乏启动速度。 因此,他们决定编写一个更简单,更原始的Dependency Injection框架,使他们能够快速启动应用程序,因为对于Android而言,它非常重要。

这里的术语是相同的。 Dagger与Guice具有完全相同的模块。 但是它们已经被标记了注释,而不是从类继承的情况下。 因此,该原理得以维持。
唯一的不足是,我们必须始终在模块中明确指示如何创建bean。 在Guice中,我们可以在bean本身内部创建bean。 我们不必说要转发给什么样的依赖项。 在这里,我们需要明确地说出这一点。

在Dagger中,由于您不想进行手动输入,因此存在组件的概念。 当我们要从一个模块声明一个bin以便可以将其带入另一个模块时,组件就是绑定模块的东西。 这是一个不同的概念。 一个模块中的bean可以使用组件“注入”另一个模块中的bean。

这是关于同一摘要板的内容-在Inject或模块的情况下已更改或未更改的内容。

有什么优势? 它甚至比Guice更简单。 发射比Guice还要快。 而且它可能不会再变得更快了,因为Dagger完全放弃了反射。 这正是Java库中负责查看对象,其类和方法的状态的部分。 也就是说,在运行时获取状态。 因此,它不使用反射。 他不走,也不扫描任何人有什么依赖关系。 但是正因为如此,他起步非常快。
他是怎么做到的? 使用代码生成。
如果回头看,我们将看到接口组件。 我们没有实现此接口的任何实现,Dagger为我们做了。 并且有可能在应用程序中进一步使用该接口。
自然,由于这种速度,它在Android世界中非常普遍。 在编译时将立即检查依赖关系树,因为在运行时我们不会延迟检查任何内容。
不利之处是什么? 他机会更少。 它比Guice和Spring更冗长。

在这些库中,Java中提出了一项计划-所谓的JSR-330。 JSR是对语言规范进行更改或添加一些其他库的请求。 此类标准是基于Guice提出的,并且
Inject注释已添加到该库中。 因此,Spring和Guice支持它。
可以得出什么结论? Java有很多不同的DI库。 您需要了解为什么我们选择其中一个特定的。 如果我们使用Android,那么已经没有选择,我们使用Dagger。 如果我们进入后端世界,那么我们已经在寻找最适合我们的东西。 对于依赖注入的第一个研究,在我看来,Guice比Spring好。 里面没有多余的东西。 您可以了解它的工作原理。
为了进一步研究,我建议您熟悉所有这些库的文档以及JSR的组成:
-
春天-
吉斯-
匕首2-JSR-330谢谢你